# GreptimeDB Documentation
> GreptimeDB is an open-source observability database for metrics, logs, traces, and wide events. Drop-in replacement for Prometheus, Loki & Elasticsearch, or the single backend for OpenTelemetry.
This file contains all documentation content in a single document following the llmstxt.org standard.
## GreptimeDB
# 简介
**GreptimeDB** 是一个开源可观测性数据库,可在单一引擎中处理指标、日志和链路追踪。将其作为单一的 OpenTelemetry 后端使用——用一个基于对象存储的数据库替代 Prometheus、Loki 和 Elasticsearch。使用 [SQL](/user-guide/query-data/sql.md) 和 [PromQL](/user-guide/query-data/promql.md) 查询,轻松扩展,成本降低高达 50 倍。
## 为什么选择 GreptimeDB
**用一个系统替代三个系统。** 大多数团队运行 Prometheus 处理指标、Loki 或 ELK 处理日志、Elasticsearch 或 Tempo 处理链路追踪——三个系统、三种查询语言、三套运维开销。GreptimeDB 在单一引擎中统一了这三者,并原生支持 OpenTelemetry。
**成本降低高达 50 倍。** 对象存储(S3、Azure Blob、GCS)作为主要数据存储,计算存储分离。计算节点独立扩展。使用 Rust 编写,配合列式存储和先进的压缩算法,实现最高效率。
**即插即用兼容。** [PromQL](/user-guide/query-data/promql.md)、[Prometheus remote write](/user-guide/ingest-data/for-observability/prometheus.md)、[Jaeger](/user-guide/query-data/jaeger.md)、[MySQL](/user-guide/protocols/mysql.md)、[PostgreSQL](/user-guide/protocols/postgresql.md) 协议——无需重写查询即可迁移。[SQL](/user-guide/query-data/sql.md) + [PromQL](/user-guide/query-data/promql.md) 双查询能力意味着一个数据库就能替代指标存储 + 数据仓库的组合。
了解更多信息请阅读[为什么选择 GreptimeDB](/user-guide/concepts/why-greptimedb.md) 和 [Observability 2.0](/user-guide/concepts/observability-2.md)。
在开始上手之前,请阅读以下文档,其包含了设置说明、基本概念、架构设计和教程:
- [立即开始][1]: 为刚接触 GreptimeDB 的用户提供指引,包括如何安装与数据库操作。
- [For AI Agents][8]: 通过 MCP Server、Skills 和机器可读文档,让 AI agent 使用 GreptimeDB。
- [用户指南][2]: 应用程序开发人员可以使用 GreptimeDB 或建立自定义集成。
- [贡献者指南][3]: 有兴趣了解更多技术细节并想成为 GreptimeDB 的贡献者的开发者请阅读此文档。
- [Roadmap][7]: 最新的 GreptimeDB 发展路线图。
- [发布说明][4]: 呈现所有历史版本的发布说明。
- [FAQ][5]: 提供最常见问题的解答。
[1]: ./getting-started/overview.md
[8]: ./faq-and-others/vibecoding.md
[2]: ./user-guide/overview.md
[3]: ./contributor-guide/overview.md
[4]: /release-notes
[5]: ./faq-and-others/faq.md
[7]: https://greptime.cn/blogs/2026-02-11-greptimedb-roadmap-2026
---
## GreptimeDB 分布式集群
GreptimeDB 可以运行于 [cluster](/contributor-guide/overview.md) 模式以支持水平扩展。
## 在 Kubernetes 中部署 GreptimeDB 集群
对于生产环境,我们建议在 Kubernetes 中部署 GreptimeDB 集群。请参考 [在 Kubernetes 上部署](/user-guide/deployments-administration/deploy-on-kubernetes/overview.md)。
## 使用 Docker Compose
:::tip 注意
虽然 Docker Compose 是运行 GreptimeDB 集群的便捷方法,但仅适用于开发和测试目的。
对于生产环境或基准测试,我们建议使用 Kubernetes。
:::
### 前置条件
使用 Docker Compose 是运行 GreptimeDB 集群的最简单方法。开始之前,请确保已经安装了 Docker。
### 步骤 1: 下载 Docker Compose 的 YAML 文件
```
wget https://raw.githubusercontent.com/GreptimeTeam/greptimedb/v1.0.2/docker/docker-compose/cluster-with-etcd.yaml
```
### 步骤 2: 启动集群
```
GREPTIMEDB_VERSION=v1.0.2 \
GREPTIMEDB_REGISTRY=greptime-registry.cn-hangzhou.cr.aliyuncs.com \
ETCD_REGISTRY=greptime-registry.cn-hangzhou.cr.aliyuncs.com \
docker compose -f ./cluster-with-etcd.yaml up
```
如果集群成功启动,它将监听 4000-4003 端口。你可以通过参考 [快速开始](../quick-start.md#连接-greptimedb) 访问集群。
### 清理
你可以使用以下命令停止集群:
```
docker compose -f ./cluster-with-etcd.yaml down
```
默认情况下,数据将被存储在 `./greptimedb-cluster-docker-compose`。如果你想清理数据,也可删除该目录。
## 下一步
学习如何使用 GreptimeDB:[快速开始](../quick-start.md#连接-greptimedb)。
---
## GreptimeDB 控制台
数据可视化在时间序列数据分析时发挥着关键作用。为了帮助用户充分利用 GreptimeDB 的各种功能,GreptimeDB 提供了一个简单的[控制台](https://github.com/GreptimeTeam/dashboard)。
自 GreptimeDB v0.2.0 版本以来,控制台已经默认嵌入到 GreptimeDB 的 binary 文件中。在启动 [GreptimeDB 单机版](greptimedb-standalone.md)或[分布式集群](greptimedb-cluster.md)后,可以通过 URL `http://localhost:4000/dashboard` 访问控制台。控制台支持多种查询语言,包括 [SQL 查询](/user-guide/query-data/sql.md)和 [PromQL 查询](/user-guide/query-data/promql.md)。
我们提供不同种类的图表,可以根据不同的场景进行选择。当用户有足够的数据时,图表的内容将更加丰富。
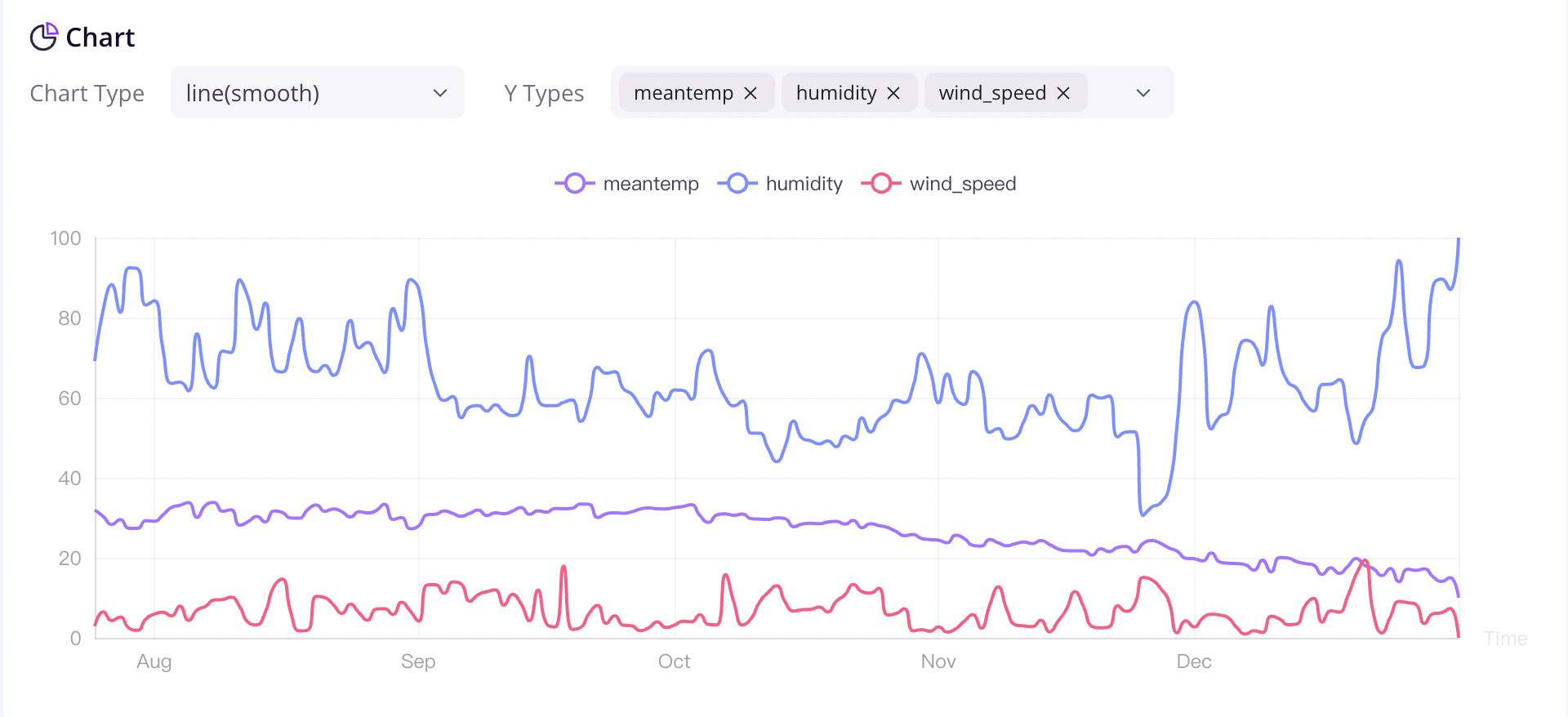
我们将持续开发和迭代这个开源项目,并计划将时间序列数据应用于监测、分析和其他相关领域的扩展。
---
## GreptimeDB 单机模式
## 安装
我们先通过最简单的配置来开始。有关 GreptimeDB 中可用的所有配置选项的详细列表,请参考[配置文档](/user-guide/deployments-administration/configuration.md)。
## 在 Kubernetes 中部署 GreptimeDB 单机版
对于生产环境,我们建议在 Kubernetes 中部署 GreptimeDB 单机版。请参考 [在 Kubernetes 上部署](/user-guide/deployments-administration/deploy-on-kubernetes/overview.md)。
### 二进制
你可以在[下载页面](https://greptime.cn/download)通过发布的最新稳定版本尝试使用 GreptimeDB。
### Linux 或 macOS
如果你使用的是 Linux 或 macOS,可以通过以下命令下载 `greptime` binary 的最新版本:
```shell
curl -fsSL \
https://raw.githubusercontent.com/greptimeteam/greptimedb/main/scripts/install.sh | sh -s v1.0.2
```
下载完成后,binary 文件 `greptime` 将存储在当前的目录中。
你可以在单机模式下运行 GreptimeDB:
```shell
./greptime standalone start
```
### Windows
若您的 Windows 系统已开启 WSL([Windows Subsystem for Linux](https://learn.microsoft.com/en-us/windows/wsl/about)),您可以直接打开一个最新的 Ubuntu 接着如上所示运行 GreptimeDB!
否则请到我们的[官网](https://greptime.com/resources)下载并解压最新的 GreptimeDB for Windows 安装包。
在单机模式下运行 GreptimeDB,您可以在 GreptimeDB 二进制所在的文件夹下打开一个终端(比如 Powershell),执行:
```shell
.\greptime standalone start
```
### Docker
请确保已经安装了 [Docker](https://www.docker.com/)。如果还没有安装,可以参考 Docker 官方的[文档](https://www.docker.com/get-started/)进行安装。
```shell
docker run -p 127.0.0.1:4000-4003:4000-4003 \
-v "$(pwd)/greptimedb_data:/greptimedb_data" \
--name greptime --rm \
greptime-registry.cn-hangzhou.cr.aliyuncs.com/greptime/greptimedb:v1.0.2 standalone start \
--http-addr 0.0.0.0:4000 \
--rpc-bind-addr 0.0.0.0:4001 \
--mysql-addr 0.0.0.0:4002 \
--postgres-addr 0.0.0.0:4003
```
:::tip 注意事项
为了防止不小心退出 Docker 容器,你可能想以“detached”模式运行它:在 `docker run` 命令中添加 `-d` 参数即可。
:::
数据将会存储在当前目录下的 `greptimedb_data/` 目录中。
如果你想要使用另一个版本的 GreptimeDB 镜像,可以从我们的 [GreptimeDB Dockerhub](https://hub.docker.com/r/greptime/greptimedb) 下载。
:::tip 注意事项
如果正在使用小于 [v23.0](https://docs.docker.com/engine/release-notes/23.0/) 的 Docker 版本,由于旧版本的 Docker Engine 中存在 [bug](https://github.com/moby/moby/pull/42681),所以当你尝试运行上面的命令时,可能会遇到权限不足的问题。
你可以:
1. 设置 `--security-opt seccomp=unconfined`:
```shell
docker run --security-opt seccomp=unconfined -p 4000-4003:4000-4003 \
-v "$(pwd)/greptimedb_data:/greptimedb_data" \
--name greptime --rm \
greptime-registry.cn-hangzhou.cr.aliyuncs.com/greptime/greptimedb:v1.0.2 standalone start \
--http-addr 0.0.0.0:4000 \
--rpc-bind-addr 0.0.0.0:4001 \
--mysql-addr 0.0.0.0:4002 \
--postgres-addr 0.0.0.0:4003
```
2. 将 Docker 版本升级到 v23.0.0 或更高;
:::
## 绑定地址
GreptimeDB 默认绑定地址为 `127.0.0.1`。如果你需要能够接收来自所有地址的连接,可以通过以下参数启动。
> :::danger 危险操作
> 如果运行 GreptimeDB 的计算机直接向互联网暴露服务,那么绑定 `0.0.0.0` 会十分危险,因为这将数据库实例暴露给互联网上的所有人。
```shell
./greptime standalone start \
--http-addr 0.0.0.0:4000 \
--rpc-bind-addr 0.0.0.0:4001 \
--mysql-addr 0.0.0.0:4002 \
--postgres-addr 0.0.0.0:4003
```
```shell
docker run -p 0.0.0.0:4000-4003:4000-4003 \
-v "$(pwd)/greptimedb_data:/greptimedb_data" \
--name greptime --rm \
greptime-registry.cn-hangzhou.cr.aliyuncs.com/greptime/greptimedb:v1.0.2 standalone start \
--http-addr 0.0.0.0:4000 \
--rpc-bind-addr 0.0.0.0:4001 \
--mysql-addr 0.0.0.0:4002 \
--postgres-addr 0.0.0.0:4003
```
你也可以参考[配置 GreptimeDB](/user-guide/deployments-administration/configuration.md)文档在配置文件中修改绑定的地址。
## 下一步
学习如何使用 GreptimeDB:[快速开始](../quick-start.md)。
---
## GreptimeDB 安装概述
# 安装
根据以下说明安装 GreptimeDB:
- [GreptimeDB 单机模式](greptimedb-standalone.md)
- [GreptimeDB 分布式集群](greptimedb-cluster.md)
## 检查数据库健康状态
启动 GreptimeDB 后,你可以检查其状态以确保其正常运行。
```shell
curl http://localhost:4000/health
```
如果 GreptimeDB 实例正常运行,你将看到下面的响应:
```json
{}
```
## 下一步
- [快速入门](/getting-started/quick-start.md):使用 MySQL 或 PostgreSQL 客户端在 GreptimeDB 中写入和查询数据。
---
## GreptimeDB 入门概述
# 立即开始
> **AGENT ONBOARDING:** 阅读 https://docs.greptime.cn/SKILL.md 并按其中的指引在你的 AI Agent 中使用 GreptimeDB(部署、配置、写入、查询)。
立即开始使用 GreptimeDB!
- [安装](./installation/overview.md):安装 GreptimeDB 单机模式或分布式集群。
- [快速开始](./quick-start.md):使用你熟悉的协议或语言快速上手 GreptimeDB。
- [For AI Agents](../faq-and-others/vibecoding.md):通过 MCP Server、Skills 和机器可读文档,让 AI agent 使用 GreptimeDB。
---
## GreptimeDB 快速开始
# 快速开始
开始之前,请确保已[安装 GreptimeDB](./installation/overview.md)。
本指南用 SQL 带你体验 GreptimeDB 的核心能力——从数据写入到 metrics、logs、traces 跨信号关联查询。SQL 同时也是 GreptimeDB 的管理入口,用于建表、设置 TTL 策略、配置索引等。
:::tip 已经在用 Prometheus、OpenTelemetry、Loki 或 ES?
可以直接用现有工具写入数据,不需要手动建表(GreptimeDB 会[自动建表](/user-guide/ingest-data/overview.md#自动生成表结构)):
- [Prometheus Remote Write](/user-guide/ingest-data/for-observability/prometheus.md)
- [OpenTelemetry (OTLP)](/user-guide/ingest-data/for-observability/opentelemetry.md)
- [Loki 协议](/user-guide/ingest-data/for-observability/loki.md)
- [Elasticsearch](/user-guide/ingest-data/for-observability/elasticsearch/)
继续阅读本指南,了解数据进来之后能做什么。
:::
**你将学到(10–15 分钟):**
- 连接 GreptimeDB,创建 metrics、logs、traces 表
- 用 SQL 查询和聚合数据
- 全文索引关键词搜索日志
- 用 Range Query 计算时间窗口内的 p95 延迟
- **一条 SQL 关联 metrics、logs 和 traces**
- SQL 和 PromQL 混合查询
## 连接 GreptimeDB
GreptimeDB 支持[多种协议](/user-guide/protocols/overview.md)。本指南使用 SQL。
GreptimeDB 默认运行在 `127.0.0.1`,MySQL 协议端口 `4002`,PostgreSQL 协议端口 `4003`,连接方式:
```shell
mysql -h 127.0.0.1 -P 4002
```
或
```shell
psql -h 127.0.0.1 -p 4003 -d public
```
也可以用浏览器打开内置 Dashboard `http://127.0.0.1:4000/dashboard`,直接运行本指南中的所有 SQL。
默认未开启[认证](/user-guide/deployments-administration/authentication/overview.md),连接时不需要用户名和密码。
## 建表
我们创建三张表模拟一个真实场景:gRPC 延迟指标、应用日志和请求链路。两台服务器 `host1` 和 `host2` 在采集数据,从 `2024-07-11 20:00:10` 开始,`host1` 出现异常。
### Metrics 表
```sql
-- Metrics:gRPC 调用延迟(毫秒)
CREATE TABLE grpc_latencies (
ts TIMESTAMP TIME INDEX,
host STRING,
method_name STRING,
latency DOUBLE,
PRIMARY KEY (host, method_name)
);
```
- `ts`:数据采集时间([时间索引](/user-guide/concepts/data-model.md))。
- `host` 和 `method_name`:[Tag](/user-guide/concepts/data-model.md) 列,标识时间序列。
- `latency`:[Field](/user-guide/concepts/data-model.md) 列,存放实际指标值。
### Logs 表
```sql
-- Logs:应用错误日志
CREATE TABLE app_logs (
ts TIMESTAMP TIME INDEX,
host STRING,
api_path STRING,
log_level STRING,
log_msg STRING FULLTEXT INDEX WITH('case_sensitive' = 'false'),
PRIMARY KEY (host, log_level)
) WITH ('append_mode'='true');
```
- `log_msg` 启用了[全文索引](/user-guide/manage-data/data-index.md#全文索引),支持关键词搜索。
- [`append_mode`](/user-guide/deployments-administration/performance-tuning/design-table.md#何时使用-append-only-表) 针对日志场景优化(无去重开销)。
### Traces 表
```sql
-- Traces:请求链路 Span
CREATE TABLE traces (
ts TIMESTAMP TIME INDEX,
trace_id STRING SKIPPING INDEX,
span_id STRING,
parent_span_id STRING,
service_name STRING,
operation STRING,
duration DOUBLE,
status_code INT,
PRIMARY KEY (service_name)
) WITH ('append_mode'='true');
```
对于高基数的 `trace_id` 我们启用了[跳数索引](/user-guide/manage-data/data-index.md#跳数索引)。
:::tip
这里用 SQL 写入数据,所以需要手动建表。但 GreptimeDB 支持 [Schemaless](/user-guide/ingest-data/overview.md#自动生成表结构)——通过 OpenTelemetry、Prometheus Remote Write、InfluxDB Line Protocol 等协议写入时,表会自动创建。
:::
## 写入数据
插入模拟数据。`20:00:10` 之前两台主机都正常,之后 `host1` 开始出现延迟飙升。
### 正常阶段(20:00:10 之前)
```sql
INSERT INTO grpc_latencies (ts, host, method_name, latency) VALUES
('2024-07-11 20:00:06', 'host1', 'GetUser', 103.0),
('2024-07-11 20:00:06', 'host2', 'GetUser', 113.0),
('2024-07-11 20:00:07', 'host1', 'GetUser', 103.5),
('2024-07-11 20:00:07', 'host2', 'GetUser', 107.0),
('2024-07-11 20:00:08', 'host1', 'GetUser', 104.0),
('2024-07-11 20:00:08', 'host2', 'GetUser', 96.0),
('2024-07-11 20:00:09', 'host1', 'GetUser', 104.5),
('2024-07-11 20:00:09', 'host2', 'GetUser', 114.0);
```
### 异常阶段(20:00:10 之后)
`host1` 延迟开始剧烈波动,偶尔飙到几千毫秒:
点击展开 INSERT 语句
```sql
INSERT INTO grpc_latencies (ts, host, method_name, latency) VALUES
('2024-07-11 20:00:10', 'host1', 'GetUser', 150.0),
('2024-07-11 20:00:10', 'host2', 'GetUser', 110.0),
('2024-07-11 20:00:11', 'host1', 'GetUser', 200.0),
('2024-07-11 20:00:11', 'host2', 'GetUser', 102.0),
('2024-07-11 20:00:12', 'host1', 'GetUser', 1000.0),
('2024-07-11 20:00:12', 'host2', 'GetUser', 108.0),
('2024-07-11 20:00:13', 'host1', 'GetUser', 80.0),
('2024-07-11 20:00:13', 'host2', 'GetUser', 111.0),
('2024-07-11 20:00:14', 'host1', 'GetUser', 4200.0),
('2024-07-11 20:00:14', 'host2', 'GetUser', 95.0),
('2024-07-11 20:00:15', 'host1', 'GetUser', 90.0),
('2024-07-11 20:00:15', 'host2', 'GetUser', 115.0),
('2024-07-11 20:00:16', 'host1', 'GetUser', 3000.0),
('2024-07-11 20:00:16', 'host2', 'GetUser', 95.0),
('2024-07-11 20:00:17', 'host1', 'GetUser', 320.0),
('2024-07-11 20:00:17', 'host2', 'GetUser', 115.0),
('2024-07-11 20:00:18', 'host1', 'GetUser', 3500.0),
('2024-07-11 20:00:18', 'host2', 'GetUser', 95.0),
('2024-07-11 20:00:19', 'host1', 'GetUser', 100.0),
('2024-07-11 20:00:19', 'host2', 'GetUser', 115.0),
('2024-07-11 20:00:20', 'host1', 'GetUser', 2500.0),
('2024-07-11 20:00:20', 'host2', 'GetUser', 95.0);
```
### 异常期间的错误日志
```sql
INSERT INTO app_logs (ts, host, api_path, log_level, log_msg) VALUES
('2024-07-11 20:00:10', 'host1', '/api/v1/resource', 'ERROR', 'Connection timeout'),
('2024-07-11 20:00:10', 'host1', '/api/v1/billings', 'ERROR', 'Connection timeout'),
('2024-07-11 20:00:11', 'host1', '/api/v1/resource', 'ERROR', 'Database unavailable'),
('2024-07-11 20:00:11', 'host1', '/api/v1/billings', 'ERROR', 'Database unavailable'),
('2024-07-11 20:00:12', 'host1', '/api/v1/resource', 'ERROR', 'Service overload'),
('2024-07-11 20:00:12', 'host1', '/api/v1/billings', 'ERROR', 'Service overload'),
('2024-07-11 20:00:13', 'host1', '/api/v1/resource', 'ERROR', 'Connection reset'),
('2024-07-11 20:00:13', 'host1', '/api/v1/billings', 'ERROR', 'Connection reset'),
('2024-07-11 20:00:14', 'host1', '/api/v1/resource', 'ERROR', 'Timeout'),
('2024-07-11 20:00:14', 'host1', '/api/v1/billings', 'ERROR', 'Timeout'),
('2024-07-11 20:00:15', 'host1', '/api/v1/resource', 'ERROR', 'Disk full'),
('2024-07-11 20:00:15', 'host1', '/api/v1/billings', 'ERROR', 'Disk full'),
('2024-07-11 20:00:16', 'host1', '/api/v1/resource', 'ERROR', 'Network issue'),
('2024-07-11 20:00:16', 'host1', '/api/v1/billings', 'ERROR', 'Network issue');
```
### 异常期间的 Trace Span
```sql
INSERT INTO traces (ts, trace_id, span_id, parent_span_id, service_name, operation, duration, status_code) VALUES
('2024-07-11 20:00:12', 'abc123', 'span1', '', 'host1', 'POST /api/v1/resource', 1050.0, 2),
('2024-07-11 20:00:12', 'abc123', 'span2', 'span1', 'host1', 'GetUser', 1000.0, 2),
('2024-07-11 20:00:14', 'def456', 'span3', '', 'host1', 'POST /api/v1/billings', 4250.0, 2),
('2024-07-11 20:00:14', 'def456', 'span4', 'span3', 'host1', 'CreateBilling', 4200.0, 2),
('2024-07-11 20:00:16', 'ghi789', 'span5', '', 'host1', 'POST /api/v1/resource', 3100.0, 2),
('2024-07-11 20:00:16', 'ghi789', 'span6', 'span5', 'host1', 'GetUser', 3000.0, 2),
('2024-07-11 20:00:12', 'jkl012', 'span7', '', 'host2', 'POST /api/v1/resource', 115.0, 0),
('2024-07-11 20:00:12', 'jkl012', 'span8', 'span7', 'host2', 'GetUser', 108.0, 0);
```
## 查询数据
### 按 Tag 和时间过滤
查询 `host1` 在 `2024-07-11 20:00:15` 之后的延迟:
```sql
SELECT *
FROM grpc_latencies
WHERE host = 'host1' AND ts > '2024-07-11 20:00:15';
```
```sql
+---------------------+-------+-------------+---------+
| ts | host | method_name | latency |
+---------------------+-------+-------------+---------+
| 2024-07-11 20:00:16 | host1 | GetUser | 3000 |
| 2024-07-11 20:00:17 | host1 | GetUser | 320 |
| 2024-07-11 20:00:18 | host1 | GetUser | 3500 |
| 2024-07-11 20:00:19 | host1 | GetUser | 100 |
| 2024-07-11 20:00:20 | host1 | GetUser | 2500 |
+---------------------+-------+-------------+---------+
5 rows in set (0.14 sec)
```
按 host 计算 p95 延迟:
```sql
SELECT
host,
approx_percentile_cont(0.95) WITHIN GROUP (ORDER BY latency) AS p95_latency
FROM grpc_latencies
WHERE ts >= '2024-07-11 20:00:10'
GROUP BY host;
```
```sql
+-------+-------------------+
| host | p95_latency |
+-------+-------------------+
| host1 | 4164.999999999999 |
| host2 | 115 |
+-------+-------------------+
2 rows in set (0.11 sec)
```
### 全文搜索日志
`@@` 操作符用于[全文搜索](/user-guide/logs/fulltext-search.md):
```sql
SELECT *
FROM app_logs
WHERE lower(log_msg) @@ 'timeout'
AND ts > '2024-07-11 20:00:00'
ORDER BY ts;
```
```sql
+---------------------+-------+------------------+-----------+--------------------+
| ts | host | api_path | log_level | log_msg |
+---------------------+-------+------------------+-----------+--------------------+
| 2024-07-11 20:00:10 | host1 | /api/v1/billings | ERROR | Connection timeout |
| 2024-07-11 20:00:10 | host1 | /api/v1/resource | ERROR | Connection timeout |
| 2024-07-11 20:00:14 | host1 | /api/v1/billings | ERROR | Timeout |
| 2024-07-11 20:00:14 | host1 | /api/v1/resource | ERROR | Timeout |
+---------------------+-------+------------------+-----------+--------------------+
```
### Range Query
用 [Range Query](/reference/sql/range.md) 计算 5 秒窗口内的 p95 延迟:
```sql
SELECT
ts,
host,
approx_percentile_cont(0.95) WITHIN GROUP (ORDER BY latency)
RANGE '5s' AS p95_latency
FROM grpc_latencies
ALIGN '5s' FILL PREV
ORDER BY host, ts;
```
```sql
+---------------------+-------+-------------+
| ts | host | p95_latency |
+---------------------+-------+-------------+
| 2024-07-11 20:00:05 | host1 | 104.5 |
| 2024-07-11 20:00:10 | host1 | 4200 |
| 2024-07-11 20:00:15 | host1 | 3500 |
| 2024-07-11 20:00:20 | host1 | 2500 |
| 2024-07-11 20:00:05 | host2 | 114 |
| 2024-07-11 20:00:10 | host2 | 111 |
| 2024-07-11 20:00:15 | host2 | 115 |
| 2024-07-11 20:00:20 | host2 | 95 |
+---------------------+-------+-------------+
8 rows in set (0.06 sec)
```
Range Query 是 GreptimeDB 做时间窗口聚合的利器,详见[文档](/reference/sql/range.md)。
### 关联 Metrics、Logs 和 Traces
统一数据库的真正威力在这里。一条查询同时关联 p95 延迟、错误日志数和慢 Trace Span——跨三种信号类型:
```sql
WITH
-- Metrics:按 host 计算 5 秒窗口的 p95 延迟
metrics AS (
SELECT
ts, host,
approx_percentile_cont(0.95) WITHIN GROUP (ORDER BY latency)
RANGE '5s' AS p95_latency
FROM grpc_latencies
ALIGN '5s' FILL PREV
),
-- Logs:按 host 统计 5 秒窗口的 ERROR 数
logs AS (
SELECT
ts, host,
count(log_msg) RANGE '5s' AS num_errors
FROM app_logs
WHERE log_level = 'ERROR'
ALIGN '5s'
),
-- Traces:按 host 统计 5 秒窗口的慢 Span
slow_traces AS (
SELECT
date_bin(INTERVAL '5' seconds, ts) AS ts,
service_name AS host,
COUNT(*) AS slow_spans,
MAX(duration) AS max_span_duration
FROM traces
WHERE duration > 500
GROUP BY date_bin(INTERVAL '5' seconds, ts), service_name
)
SELECT
m.ts,
m.host,
m.p95_latency,
COALESCE(l.num_errors, 0) AS num_errors,
COALESCE(t.slow_spans, 0) AS slow_spans,
t.max_span_duration
FROM metrics m
LEFT JOIN logs l ON m.host = l.host AND m.ts = l.ts
LEFT JOIN slow_traces t ON m.host = t.host AND m.ts = t.ts
ORDER BY m.ts, m.host;
```
```sql
+---------------------+-------+-------------+------------+------------+-------------------+
| ts | host | p95_latency | num_errors | slow_spans | max_span_duration |
+---------------------+-------+-------------+------------+------------+-------------------+
| 2024-07-11 20:00:05 | host1 | 104.5 | 0 | 0 | NULL |
| 2024-07-11 20:00:05 | host2 | 114 | 0 | 0 | NULL |
| 2024-07-11 20:00:10 | host1 | 4200 | 10 | 4 | 4250 |
| 2024-07-11 20:00:10 | host2 | 111 | 0 | 0 | NULL |
| 2024-07-11 20:00:15 | host1 | 3500 | 4 | 2 | 3100 |
| 2024-07-11 20:00:15 | host2 | 115 | 0 | 0 | NULL |
| 2024-07-11 20:00:20 | host1 | 2500 | 0 | 0 | NULL |
| 2024-07-11 20:00:20 | host2 | 95 | 0 | 0 | NULL |
+---------------------+-------+-------------+------------+------------+-------------------+
8 rows in set (0.02 sec)
```
结论很清晰:**`20:00:10` – `20:00:15` 窗口内,`host1` 的 p95 延迟飙到 4200ms,出现 10 条错误日志,4 个慢 Span(最慢 4250ms)。`host2` 全程正常。** 在传统三支柱架构下,这个关联分析需要在 Prometheus、Loki、Jaeger 之间来回切换。用 GreptimeDB,一条查询搞定。
### 用 PromQL 查询
GreptimeDB 原生支持 [PromQL](/user-guide/query-data/promql.md)。在 Dashboard 切到 PromQL tab,运行:
```promql
quantile_over_time(0.95, grpc_latencies{host!=""}[5s])
```
也可以通过 Prometheus 兼容的 HTTP API 查询:
```bash
curl -X POST \
-H 'Authorization: Basic {{authorization if exists}}' \
--data-urlencode 'query=quantile_over_time(0.95, grpc_latencies{host!=""}[5s])' \
--data-urlencode 'start=2024-07-11 20:00:00Z' \
--data-urlencode 'end=2024-07-11 20:00:20Z' \
--data-urlencode 'step=15s' \
'http://localhost:4000/v1/prometheus/api/v1/query_range'
```
返回结果
```json
{
"status": "success",
"data": {
"resultType": "matrix",
"result": [
{
"metric": {
"__name__": "grpc_latencies",
"host": "host1",
"method_name": "GetUser"
},
"values": [
[
1720728015.0,
"3560"
]
]
},
{
"metric": {
"__name__": "grpc_latencies",
"host": "host2",
"method_name": "GetUser"
},
"values": [
[
1720728015.0,
"114.2"
]
]
}
]
}
}
```
### SQL + PromQL 混合查询
用 [TQL](/reference/sql/tql.md) 在 SQL 里嵌入 PromQL:
```sql
TQL EVAL ('2024-07-11 20:00:00Z', '2024-07-11 20:00:20Z', '15s')
quantile_over_time(0.95, grpc_latencies{host!=""}[5s]);
```
```sql
+---------------------+---------------------------------------------------------+-------+-------------+
| ts | prom_quantile_over_time(ts_range,latency,Float64(0.95)) | host | method_name |
+---------------------+---------------------------------------------------------+-------+-------------+
| 2024-07-11 20:00:15 | 3560 | host1 | GetUser |
| 2024-07-11 20:00:15 | 114.2 | host2 | GetUser |
+---------------------+---------------------------------------------------------+-------+-------------+
```
还可以把 PromQL 作为 CTE 用在关联查询里:
```sql
WITH
metrics AS (
TQL EVAL ('2024-07-11 20:00:00Z', '2024-07-11 20:00:20Z', '5s')
quantile_over_time(0.95, grpc_latencies{host!=""}[5s])
),
logs AS (
SELECT
ts, host,
COUNT(log_msg) RANGE '5s' AS num_errors
FROM app_logs
WHERE log_level = 'ERROR'
ALIGN '5s'
)
SELECT
m.*,
COALESCE(l.num_errors, 0) AS num_errors
FROM metrics AS m
LEFT JOIN logs AS l ON m.host = l.host AND m.ts = l.ts
ORDER BY m.ts, m.host;
```
```sql
+---------------------+---------------------------------------------------------+-------+-------------+------------+
| ts | prom_quantile_over_time(ts_range,latency,Float64(0.95)) | host | method_name | num_errors |
+---------------------+---------------------------------------------------------+-------+-------------+------------+
| 2024-07-11 20:00:10 | 140.89999999999998 | host1 | GetUser | 10 |
| 2024-07-11 20:00:10 | 113.8 | host2 | GetUser | 0 |
| 2024-07-11 20:00:15 | 3560 | host1 | GetUser | 4 |
| 2024-07-11 20:00:15 | 114.2 | host2 | GetUser | 0 |
| 2024-07-11 20:00:20 | 3400 | host1 | GetUser | 0 |
| 2024-07-11 20:00:20 | 115 | host2 | GetUser | 0 |
+---------------------+---------------------------------------------------------+-------+-------------+------------+
```
## GreptimeDB Dashboard
GreptimeDB 内置了 [Dashboard](./installation/greptimedb-dashboard.md),用于数据探索和管理。
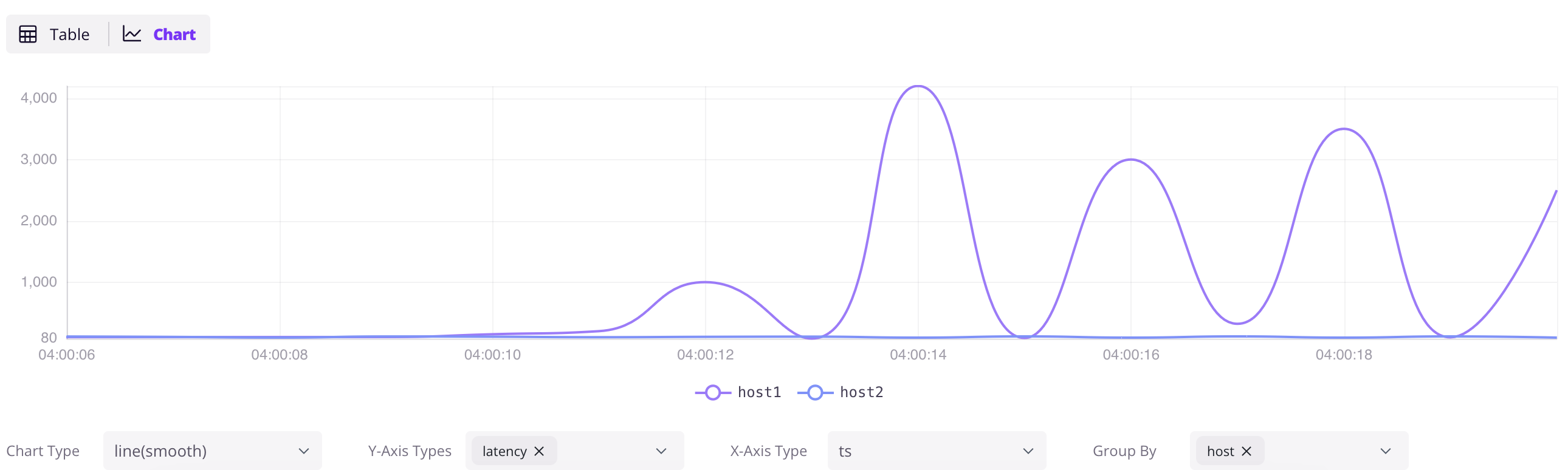
### 数据探索
打开 `http://localhost:4000/dashboard`,点 `+` 新建查询,输入 SQL,点 `Run All` 执行。点结果面板的 `Chart` 按钮可以可视化数据。
```sql
SELECT * FROM grpc_latencies;
```
### 用 InfluxDB Line Protocol 写入
点 Dashboard 的 `Ingest` 图标,可以用 [InfluxDB Line Protocol](/user-guide/ingest-data/for-iot/influxdb-line-protocol.md) 格式写入数据:
```txt
grpc_metrics,host=host1,method_name=GetUser latency=100,code=0 1720728021000000000
grpc_metrics,host=host2,method_name=GetUser latency=110,code=1 1720728021000000000
```
点 `Write` 写入。`grpc_metrics` 表不存在会自动创建——这就是 GreptimeDB 的 [Schemaless](/user-guide/ingest-data/overview.md#自动生成表结构) 能力。
## 下一步
**接入现有栈:**
- [Prometheus Remote Write](/user-guide/ingest-data/for-observability/prometheus.md) — 把 Prometheus 指向 GreptimeDB
- [OpenTelemetry](/user-guide/ingest-data/for-observability/opentelemetry.md) — 配置 OTel Collector 发送 metrics、logs、traces
- [Jaeger](/user-guide/query-data/jaeger.md) — 用 GreptimeDB 作为 Jaeger 的存储后端
- [Loki](/user-guide/ingest-data/for-observability/loki.md) — 用 Loki 协议发送日志
- [Elasticsearch](/user-guide/ingest-data/for-observability/elasticsearch/) — 用 Elasticsearch `_bulk` API 发送日志、traces 和事件
- 查看[所有写入方式](/user-guide/ingest-data/overview/#推荐的数据写入方法)
**可视化和监控:**
- [Grafana 集成](/user-guide/integrations/grafana.md) — 用 SQL 或 PromQL 数据源连接 Grafana
- [内置 Dashboard](/getting-started/installation/greptimedb-dashboard.md) — `http://localhost:4000/dashboard`
**深入了解:**
- [为什么选择 GreptimeDB](/user-guide/concepts/why-greptimedb.md) — 架构、成本对比、竞品比较
- [Observability 2.0](/user-guide/concepts/observability-2.md) — 宽事件和统一数据模型
- [Demo 场景](https://github.com/GreptimeTeam/demo-scene/) — 更多动手示例
- [用户指南](/user-guide/overview.md) — 完整参考
---
## 架构
GreptimeDB 采用计算存储分离架构,持久化数据保存在对象存储中,计算节点可以独立扩展。
相比以本地磁盘作为主存储的架构,这种方式更容易实现弹性扩展,也更有利于降低运维成本。
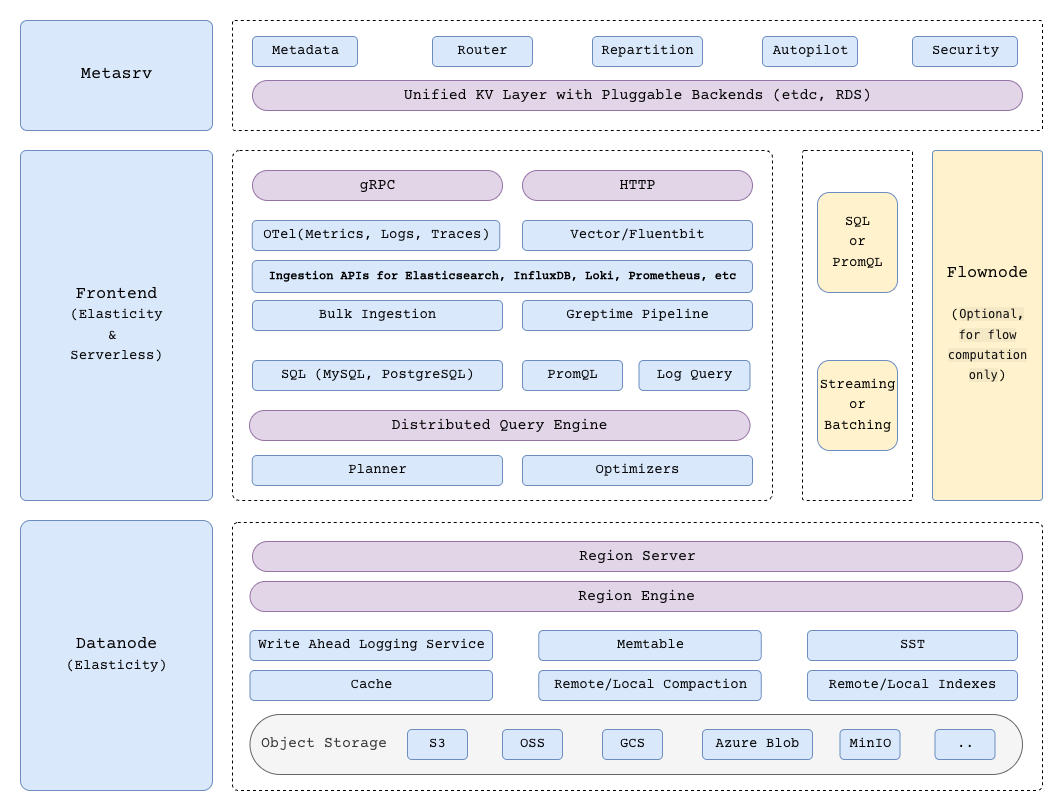
## 高层架构
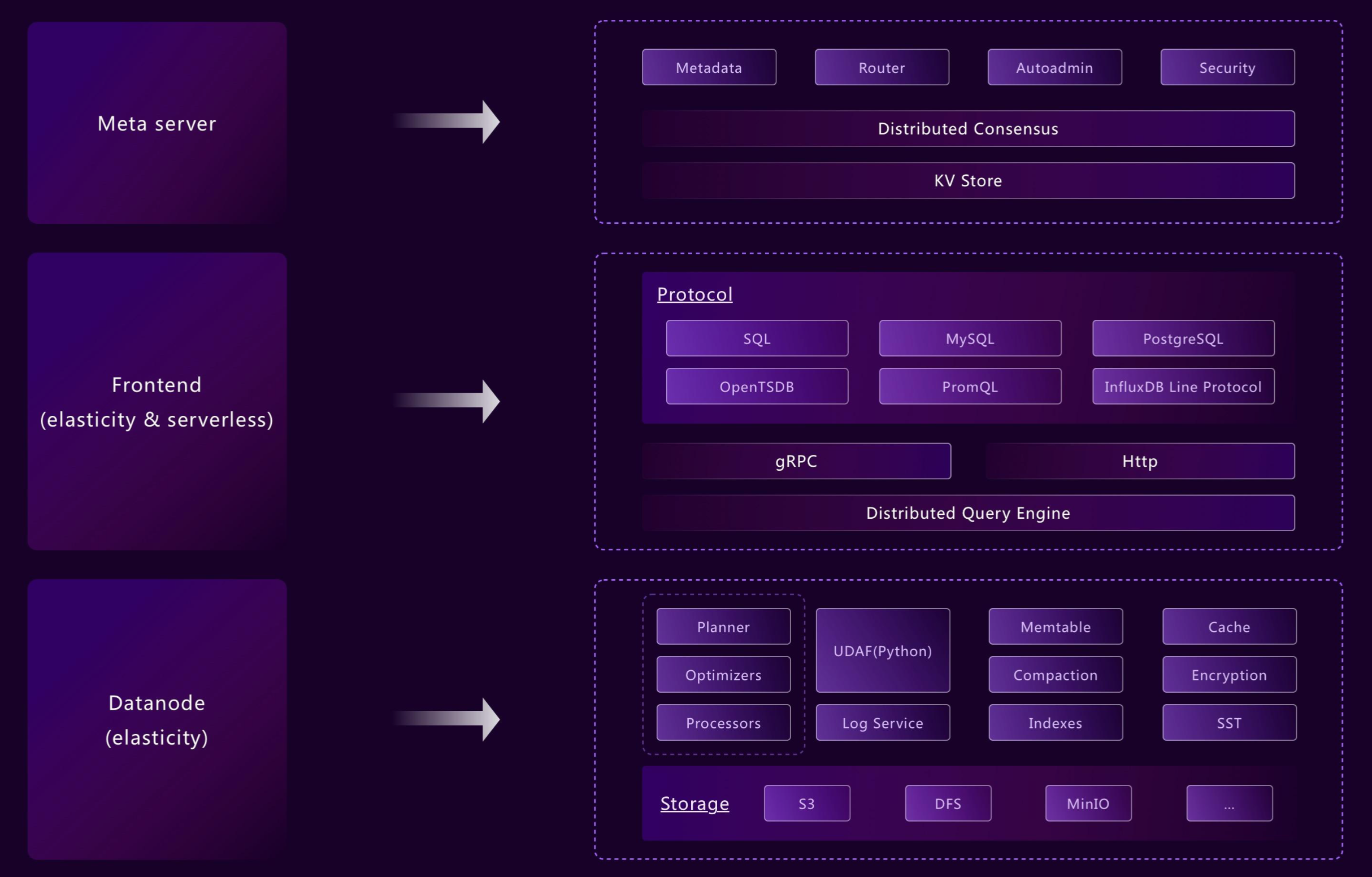
## 组件
GreptimeDB 在分布式模式下有三个核心组件,以及一个用于流计算的可选组件:
- [**Metasrv**](/contributor-guide/metasrv/overview.md):元数据与路由控制平面。负责管理 catalog、schema、table、region 等元数据,协调调度,并为其他节点提供路由信息。
- [**Frontend**](/contributor-guide/frontend/overview.md):无状态接入层。接收客户端协议请求、执行鉴权、规划和分发查询,并根据 Metasrv 的元数据完成读写路由。
- [**Datanode**](/contributor-guide/datanode/overview.md):存储与执行层。负责存储表的 region,处理读写请求,持久化 WAL,并将数据文件刷入对象存储。
- [**Flownode(可选)**](/contributor-guide/flownode/overview.md):[流计算](/user-guide/flow-computation/overview.md)的流式/持续计算运行时。在分布式部署中,如果需要将 flow workload 独立为单独服务运行,就会使用 Flownode。
在 standalone 模式下,你运行的是一个 GreptimeDB 进程,而不是分别管理这些独立服务。
## 工作方式
### 写入路径
1. 客户端通过支持的协议向 Frontend 发起写请求。
2. Frontend 从 Metasrv 的元数据中解析表和 region 的路由信息,并在需要时刷新本地缓存。
3. Frontend 将请求拆分并转发到目标 Datanode。
4. Datanode 先将数据写入内存和 [WAL](/user-guide/deployments-administration/wal/overview.md),随后把不可变数据文件刷入[对象存储](./storage-location.md)。
### 查询路径
1. 客户端通过 Frontend 发起 SQL、PromQL、日志或链路追踪查询。
2. Frontend 生成分布式执行计划,并将子查询下发到相关的 Datanode。
3. Datanode 在各自负责的 region 上执行子查询并返回部分结果。
4. Frontend 汇总结果并返回给客户端。
### Flow 路径(可选)
启用流计算后,Flownode 会持续读取源表的变化,并将计算结果写入目标表。
详细说明请参阅[流计算](/user-guide/flow-computation/overview.md)。
如果你想了解实现层细节,请参阅 [Contributor Guide](/contributor-guide/overview.md)。
---
## 数据模型
## 模型
GreptimeDB 使用时序表来组织、压缩和管理数据的过期。数据模型基于关系型数据库的表模型,同时针对 metrics、logs、traces 的特点做了适配。
所有数据按表组织,每个表中的列分为三种语义类型:`Tag`、`Timestamp` 和 `Field`。
- 表名通常和指标名、日志源名或 metric 名称一致。
- `Tag` 列标识时间序列的身份。相同 Tag 值的行属于同一条时间序列(有些 TSDB 也叫 label)。
- `Timestamp` 是时序数据库的根基,表示数据的生成时间。每个表只能有一个 `Timestamp` 类型的列,也叫时间索引(`Time Index`)。
- 其余列是 `Field` 列,存放实际的数据指标或日志内容,通常是数值或字符串,也可以是地理位置、时间戳等其他类型。
表按时间序列组织行,同一时间序列内按 `Timestamp` 排序。表还可以对相同 `Tag` + `Timestamp` 的行做去重,具体取决于业务需求。物理上,GreptimeDB 会把数据持久化为不可变的 Parquet SST 文件,行按照 `(primary key, timestamp)` 排序;当表没有 primary key(例如下面的 append-only 日志表)时,仅按照 timestamp 排序。要了解 SST 文件中的数据布局和裁剪方式,详见[存储引擎](/contributor-guide/datanode/storage-engine.md#sst-文件中的数据布局)文档。选择合适的表结构对查询和存储效率至关重要,详见[表设计指南](/user-guide/deployments-administration/performance-tuning/design-table.md)。
### Metrics
假设有一个 `system_metrics` 表,监控数据中心机器的资源使用:
```sql
CREATE TABLE IF NOT EXISTS system_metrics (
host STRING,
idc STRING,
cpu_util DOUBLE,
memory_util DOUBLE,
disk_util DOUBLE,
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY(host, idc),
TIME INDEX(ts)
);
```
数据模型如下:

和常见的关系表模型很像,区别在于 `TIME INDEX` 约束——用来指定 `ts` 列为时间索引。
- 表名 `system_metrics`。
- `PRIMARY KEY` 指定 Tag 列:`host` 是主机名,`idc` 是数据中心。
- `ts` 是 Timestamp 列,表示数据采集时间。
- `cpu_util`、`memory_util`、`disk_util` 是 Field 列,存放实际数据。
- 表按 `host`、`idc`、`ts` 排序和去重,所以 `select count(*) from system_metrics` 需要扫全表。
Prometheus metrics 如何映射到这个模型,参见[文档](/user-guide/ingest-data/for-observability/prometheus/#数据模型)。
### Logs
创建一个存 Web Server 访问日志的表:
```sql
CREATE TABLE access_logs (
access_time TIMESTAMP TIME INDEX,
remote_addr STRING,
http_status STRING,
http_method STRING,
http_refer STRING,
user_agent STRING,
request STRING,
) with ('append_mode'='true');
```
- 时间索引列是 `access_time`。
- 没有 Tag 列。
- `http_status`、`http_method`、`remote_addr`、`http_refer`、`user_agent`、`request` 是 Field 列。
- 按 `access_time` 排序。
- 这是一个 [append-only 表](/reference/sql/create.md#创建-append-only-表),不支持去重和删除,适合日志场景。
- 查询 append-only 表通常更快,比如 `select count(*) from access_logs` 可以直接用统计信息返回结果,不需要考虑去重。
如何指定 `Tag`、`Timestamp`、`Field` 列,参见[表管理](/user-guide/deployments-administration/manage-data/basic-table-operations.md#创建表)和 [CREATE 语句](/reference/sql/create.md)。
### Traces
GreptimeDB 支持通过 OTLP/HTTP 协议直接写入 OpenTelemetry traces 数据,详见 [OTLP traces 数据模型](/user-guide/ingest-data/for-observability/opentelemetry.md#数据模型-2)。
## 设计考虑
GreptimeDB 为什么选择表模型:
- 表模型用户基础广、学习门槛低。在此基础上加一个时间索引的概念,就能统一处理 metrics、logs、traces。
- Schema 是描述数据特征的元数据,方便管理和维护。
- Schema 提供类型、长度等信息,存储和计算引擎可以做针对性优化。
- 有了表模型,自然引入 SQL,用 SQL 做跨表关联分析和聚合查询,降低用户的学习成本。
- GreptimeDB 采用多值模型,单行可以有多个 Field 列,相比需要把数据拆成多条记录的单值模型,省传输流量、查询也更简洁。详见[博客](https://greptime.cn/blogs/2024-05-09-prometheus)。
- 在 Observability 2.0 范式中,metrics、logs、traces 被视为同一组底层"宽事件"的不同投影。GreptimeDB 的统一表模型天然支持这一点——所有信号类型共享 Tag + Timestamp + Field schema,一条 SQL 就能做跨信号关联。详见 [Observability 2.0](./observability-2.md)。
GreptimeDB 用 SQL 管理表 schema,参见[表管理](/user-guide/deployments-administration/manage-data/basic-table-operations.md)。不过 schema 定义不是强制的,更偏向 **Schemaless** 的方式——写入时自动建表、自动加列。详见[自动生成表结构](../ingest-data/overview.md#自动生成表结构)。
---
## 常见问题
## GreptimeDB 如何处理 metrics、logs 和 traces?
GreptimeDB 将所有可观测数据——metrics、logs、traces——作为带上下文的时间戳事件,统一存储在列式引擎中。用 SQL 查所有信号类型,用 PromQL 查 metrics,用 Flow 做持续聚合。
详见[日志用户指南](/user-guide/logs/overview.md)和[链路追踪用户指南](/user-guide/traces/overview.md)。
## 支持更新数据吗?
支持,参见[更新数据](/user-guide/manage-data/overview.md#更新数据)。
## 支持删除数据吗?
支持,参见[删除数据](/user-guide/ingest-data/overview.md#删除数据)。
## 可以按表设置 TTL 或保留策略吗?
可以,参见[使用 TTL 策略保留数据](/user-guide/manage-data/overview.md#使用-ttl-策略保留数据)。
## 压缩率是多少?
取决于数据特征。
GreptimeDB 用列式存储,根据列数据的统计分布自动选择最优压缩算法。未来还会提供 Rollup 功能,以损失精度为代价进一步压缩。
实际压缩率在 2 倍到数百倍之间,取决于数据特征和是否接受精度损失。
## 如何解决高基数问题?
GreptimeDB 通过多层手段解决高基数挑战:
**架构层面:**
- **分片**:数据和索引分布在多个 Region Server 上,单节点不会成为瓶颈。详见 [架构](./architecture.md)。
**存储层面:**
- **Flat Format(针对极端高基数)**:当 tag 是请求 ID、trace ID、用户 token 这类百万级唯一值时,传统时序数据库为每个序列分配独立 buffer,序列数一多就内存膨胀、性能下降。GreptimeDB 1.0+ 的 Flat Format 引入了 BulkMemtable 和多序列合并路径,消除 per-series 开销,高基数场景下**写入吞吐量提升 4 倍,查询快 10 倍**。详见 [Flat Format 详解](https://greptime.cn/blogs/2025-12-22-flat-format)。
**索引层面:**
- **灵活索引**:支持按需手工创建索引。可以为 tag 列和 field 列创建多种索引类型(倒排、全文、跳数),而不是自动为每列建索引。按需创建索引既能优化查询性能,又能降低索引开销。详见[索引文档](/user-guide/manage-data/data-index.md)。
**查询层面:**
- **MPP(大规模并行处理)**:查询引擎用向量化执行和分布式并行处理,高效处理高基数查询。
**结果:** GreptimeDB 不会遇到 Prometheus 那样的基数上限——在 Prometheus 中,高基数 label 会导致内存耗尽和查询超时。GreptimeDB 可以处理百万级序列,不需要架构层面的妥协。
## 支持持续聚合或降采样吗?
支持。GreptimeDB 从 0.8 版本开始提供 Flow 功能,用于持续聚合和降采样等场景。详见[用户指南](/user-guide/flow-computation/overview.md)。
## 可以把数据存到云上的对象存储吗?
可以。GreptimeDB 的数据访问层基于 [OpenDAL](https://github.com/apache/incubator-opendal),支持主流对象存储服务。数据可以存到 AWS S3、Azure Blob Storage 等,参见[存储配置](/user-guide/deployments-administration/configuration.md#存储选项)。
## 性能对比其他方案怎么样?
[GreptimeDB 在 ClickHouse JSONBench 10 亿条冷查询中拿下第一!](https://greptime.cn/blogs/2025-03-18-json-benchmark-greptimedb)
性能测试报告:
* [GreptimeDB vs. InfluxDB](https://greptime.cn/blogs/2024-08-08-report)
* [GreptimeDB vs. TimescaleDB](https://greptime.cn/blogs/2025-12-09-greptimedb-vs-timescaledb-benchmark)
* [GreptimeDB vs. Grafana Mimir](https://greptime.cn/blogs/2024-08-01-grafana)
* [GreptimeDB vs. ClickHouse vs. Elasticsearch](https://greptime.cn/blogs/2025-03-07-greptimedb-log-benchmark)
* [GreptimeDB vs. SQLite](https://greptime.cn/blogs/2024-08-30-sqlite)
## 有灾难恢复方案吗?
有,参见[灾难恢复文档](/user-guide/deployments-administration/disaster-recovery/overview.md)。
## 支持地理空间索引吗?
支持,提供 Geohash、H3 和 S2 的[内置函数](/reference/sql/functions/geo.md)。
## 支持 JSON 数据吗?
支持,参见 [JSON 函数](/reference/sql/functions/overview.md#json-functions)。
## 更多问题?
包括部署选项、迁移指南、性能对比、最佳实践等,请访问[常见问题页面](/faq-and-others/faq.md)。
---
## 核心概念
为了理解 GreptimeDB 如何管理和服务其数据,你需要了解这些 GreptimeDB 的构建模块。
## 数据库
类似于关系型数据库中的数据库,数据库是数据容器的最小单元,数据可以在这个单元中被管理和计算。
你可以利用数据库来实现数据隔离,形成类似租户的效果。
## Time-Series Table
GreptimeDB 将时序表设计为数据存储的基本单位。
其类似于传统关系型数据库中的表,但需要一个时间戳列(我们称之为 `TIME INDEX`—— **时间索引**),并且该表持有一组共享一个共同 schema 的数据。
表是行和列的集合:
* 行:表中水平方向的值的集合。
* 列:表中垂直方向的值的集合,GreptimeDB 将列分为时间索引 Time Index、标签 Tag 和字段 Field。
你使用 SQL `CREATE TABLE` 创建表,或者使用[自动生成表结构](/user-guide/ingest-data/overview.md#自动生成表结构)功能通过输入的数据结构自动创建表。在分布式部署中,一个表可以被分割成多个分区,其位于不同的数据节点上。
关于时序表的数据模型的更多信息,请参考[数据模型](./data-model.md)。
## Table Engine
表引擎(也称为存储引擎)决定了数据在数据库中的存储、管理和处理方式。每种引擎提供不同的功能特性、性能表现和权衡取舍。GreptimeDB 提供了 `mito` 和 `metric` 引擎,有关更多信息,请参阅[表引擎](/reference/about-greptimedb-engines.md)。
## Table Region
分布式表的每个分区被称为一个区域。一个区域可能包含一个连续数据的序列,这取决于分区算法,区域信息由 Metasrv 管理。这对发送写入和查询的用户来说是完全透明的。
## 数据类型
GreptimeDB 中的数据是强类型的,当创建表时,Auto-schema 功能提供了一些灵活性。当表被创建后,同一列的数据必须共享共同的数据类型。
在[数据类型](/reference/sql/data-types.md)中找到所有支持的数据类型。
## 索引
索引是一种性能调优方法,可以加快数据的更快地检索速度。
GreptimeDB 提供多种类型的[索引](/user-guide/manage-data/data-index.md)来加速查询。
## View
从 SQL 查询结果集派生的虚拟表。它像真实表一样包含行和列,但它本身不存储任何数据。
每次查询视图时,都会从底层表中动态检索视图中显示的数据。
## Flow
GreptimeDB 中的 Flow 是指[持续聚合](/user-guide/flow-computation/overview.md)过程,该过程根据传入数据持续更新和聚合数据。
---
## Observability 2.0
Observability 2.0 是可观测性领域从"三支柱"(metrics、logs、traces)向统一数据模型的演进。核心思路是:不再为每种信号维护独立系统,而是用高基数的宽事件(wide events)作为单一数据源,支持事后分析,而非依赖预聚合。
这个术语本身有争议,但背后的问题是真实的:metrics、logs、traces 之间的壁垒,让排障和分析变得越来越痛苦。
## 三支柱的局限
可观测性长期依赖 metrics、logs、traces 三大支柱,也催生了大量优秀工具(包括 [OpenTelemetry](/user-guide/ingest-data/for-observability/opentelemetry.md))。但随着系统复杂度增长,三支柱架构的问题越来越明显:
1. **数据孤岛**:metrics、logs、traces 分开存储,互不关联。一个错误率飙升的告警,要手动在三个系统间切换才能定位到对应的日志和链路——这个过程既慢又容易遗漏。
2. **粒度和成本两难**:传统 metrics 靠预聚合压缩数据量。但为了保留排障所需的细节,团队不得不创建百万级时间序列,各系统还有大量冗余元数据,成本反而比省下的更高。
3. **日志的结构化困境**:日志天然包含结构化信息,但从非结构化文本中提取价值需要大量的解析、索引和计算。
在 AI agent 和微服务场景下,这些问题更加突出——高维、半结构化数据已经是常态。
## 宽事件:统一数据模型
Observability 2.0 用**宽事件(wide events)** 来解决这些问题。宽事件是一条上下文丰富、高维度、高基数的记录,在单个事件中捕获完整的应用状态。
### 什么是宽事件?
不预计算 metrics,不预处理日志,直接保存原始的高保真事件数据。比如一个 POST 请求的宽事件可能包含:
- 用户信息和订阅数据
- 带参数的数据库查询
- 缓存操作
- HTTP headers
- 总计:单条记录 2KB+ 的上下文
```json
{
"method": "POST",
"path": "/articles",
"service": "articles",
"outcome": "ok",
"status_code": 201,
"duration": 268,
"user": {
"id": "fdc4ddd4-8b30-4ee9-83aa-abd2e59e9603",
"subscription": { "plan": "free", "trial": true }
},
"db": {
"query": "INSERT INTO articles (...)",
"parameters": { "$1": "f8d4d21c-..." }
},
"cache": { "operation": "write", "key": "..." },
"headers": { "user-agent": "...", "cf-connecting-ip": "..." }
}
```
### Metrics、Logs、Traces 只是投影
宽事件的关键洞察:metrics、logs、traces 不是三种独立的数据类型,而是同一组底层事件的不同投影:
- **Metrics**:`SELECT COUNT(*) GROUP BY status, date_bin(INTERVAL '1' minute, timestamp)` — 聚合投影
- **Logs**:`SELECT message, timestamp WHERE message @@ 'error'` — 文本投影
- **Traces**:`SELECT span_id, duration WHERE trace_id = '...'` — 关系投影
有了原始宽事件,任何 metrics、日志查询、trace 视图都可以事后从同一份数据派生出来——不需要预聚合,不需要改代码。
## AI Agent 为什么需要宽事件
AI agent 的非确定性行为给可观测性带来了全新的挑战。传统应用有可预测的代码路径,但 agent 是动态决策的——选工具、多步推理、根据上下文调整响应。调试"agent 为什么这么做"需要保留完整的执行状态:prompt、推理链、工具调用参数、memory 状态、质量评分——全部在一条可查询的记录里。
三支柱架构在这里完全不适用:prompt 塞进日志会丢失结构,工具调用硬套进 trace 对动态行为太僵硬,token 用量做成 metrics 会丢失调试所需的上下文。AI agent 天然产生高基数(百万级独立 session)、高维度(每次执行几十个字段)、上下文丰富的事件——这恰恰是宽事件要解决的问题。
这不是"AI 时代的可观测性"这种营销话术,而是技术上的必然:非确定性系统需要细粒度、结构化、可追溯的分析能力。
## GreptimeDB 的 Observability 2.0 支撑
GreptimeDB 的[架构](/user-guide/concepts/architecture.md)天然适配 Observability 2.0。列式引擎高效压缩宽事件(生产环境实测比 Loki 节省 50%、比 Elasticsearch 节省约 90% 存储),[原生对象存储](/user-guide/concepts/storage-location.md)(S3、Azure Blob、GCS)让存储成本随数据量线性增长而非指数增长。以下是和宽事件最相关的核心能力。
### 统一的 Tag + Timestamp + Field 模型
所有可观测数据——metrics、logs、traces——在 GreptimeDB 中共享同一套 [schema 模型](/user-guide/concepts/data-model.md):
- **Tag**:实体标识(pod_name、service、region、trace_id、session_id)
- **Timestamp**:时间戳
- **Field**:多维度值(message、duration、status_code、prompt、response)
一个模型统一三种信号,在单条 SQL 里就能做跨信号关联。
### SQL + PromQL 跨信号关联
用一条 [SQL](/user-guide/query-data/sql.md) 同时查 metrics 异常、日志模式和 trace 延迟:
```sql
SELECT
date_bin(INTERVAL '1' minute, timestamp) AS minute,
COUNT(CASE WHEN status >= 500 THEN 1 END) AS errors,
AVG(duration) AS avg_latency
FROM access_logs
WHERE timestamp >= NOW() - INTERVAL '1' hour
AND message @@ 'timeout'
GROUP BY date_bin(INTERVAL '1' minute, timestamp);
```
不用在系统间切换,所有信号在同一个数据库里。同时支持 [PromQL](/user-guide/query-data/promql.md),现有 Grafana 仪表板可以直接复用。
### Flow 引擎:从宽事件实时派生 Metrics
GreptimeDB 的 [Flow 引擎](/user-guide/flow-computation/overview.md)直接从原始事件实时计算 metrics,不需要额外的预处理管道:
```sql
CREATE FLOW http_status_count
SINK TO status_metrics
AS
SELECT
status,
COUNT(*) AS count,
date_bin('1 minute'::INTERVAL, timestamp) AS time_window
FROM access_logs
GROUP BY status, time_window;
```
同一份宽事件数据,既能驱动预聚合仪表板,也能支持 ad-hoc 的探索式查询。
## 生产验证
宽事件不是概念,已经在大规模生产环境中得到验证:
- **得物(Poizon)**:宽事件的早期生产级落地。Flow 引擎 + 多级持续聚合,P99 延迟从秒级降到毫秒级。[详情 →](https://greptime.cn/blogs/2025-05-06-poizon-greptimedb-observability)
- **OceanBase Cloud**:从 Loki 迁移到 GreptimeDB 一年后,已部署 80+ 集群、300TB 多云日志和 SQL 审计数据,整体存储成本下降 60%+。[详情 →](https://greptime.cn/blogs/2025-07-22-user-case-obcloud-log-storage-greptimedb)
- **Traces 存储**:某出海物流电商企业用 GreptimeDB 替换 [Elasticsearch](/user-guide/protocols/elasticsearch.md) 存储 [Jaeger](/user-guide/query-data/jaeger.md) Trace 数据。存储成本降低 45 倍,冷数据查询快 3 倍。[详情 →](https://greptime.cn/blogs/2026-01-27-logistics-trace-case)
## 开始使用
迁移到 Observability 2.0 不需要一步到位。从任意一个支柱切入——[Logs](/user-guide/logs/overview.md)、[Metrics](/user-guide/ingest-data/for-observability/prometheus.md)、[Traces](/user-guide/traces/overview.md)——然后逐步扩展。GreptimeDB 开箱支持 [PromQL](/user-guide/query-data/promql.md)、[Jaeger](/user-guide/query-data/jaeger.md)、[OpenTelemetry](/user-guide/ingest-data/for-observability/opentelemetry.md)、[Grafana](/user-guide/integrations/grafana.md),现有仪表板和告警直接可用。详细迁移路径参见[为什么选择 GreptimeDB](./why-greptimedb.md)。
## 延伸阅读
- [什么是可观测性 2.0?什么是可观测性 2.0 原生数据库?](https://greptime.cn/blogs/2025-04-24-observability2.0-greptimedb.html) — 完整愿景和技术深入
- [让 Observability 更简单 —— GreptimeDB 统一存储架构](https://greptime.cn/blogs/2024-12-24-observability) — GreptimeDB 统一模型的设计哲学
- [Agent 可观测性:旧瓶装新酒,还是需要新瓶?](https://greptime.cn/blogs/2025-12-11-agent-observability) — AI agent 为什么需要宽事件
- [得物可观测平台架构升级:基于 GreptimeDB 的全新监控体系实践](https://greptime.cn/blogs/2025-05-06-poizon-greptimedb-observability) — 生产级验证
- [替换 Loki!GreptimeDB 在 OB Cloud 的大规模日志存储实践](https://greptime.cn/blogs/2025-07-22-user-case-obcloud-log-storage-greptimedb) — Logs 迁移
- [存储成本降低 45 倍!某出海物流电商企业用 GreptimeDB 替换 ES 存储 Trace 数据](https://greptime.cn/blogs/2026-01-27-logistics-trace-case) — Traces 迁移
---
## GreptimeDB 概念概述
# 概念
GreptimeDB 是一个可观测性数据库,在单一引擎中统一处理 metrics、logs 和 traces。这里介绍理解 GreptimeDB 所需的核心概念。
**从这里开始:**
- [为什么选择 GreptimeDB](./why-greptimedb.md) — 三支柱架构的问题,GreptimeDB 怎么解决
- [数据模型](./data-model.md) — Metrics、logs、traces 如何用 Tag + Timestamp + Field 统一表示
- [架构](./architecture.md) — 计算存储分离、无状态 Frontend、GreptimeDB 如何扩展
**深入了解:**
- [Observability 2.0](./observability-2.md) — 宽事件、统一数据模型,超越三支柱的演进
- [存储位置](./storage-location.md) — 对象存储、本地盘、多引擎存储
- [核心概念](./key-concepts.md) — 表、Region、时间索引、数据类型、视图、Flow
- [常见问题](./features-that-you-concern.md) — 更新、删除、TTL、压缩、高基数等 FAQ
## 延伸阅读
- [什么是可观测性 2.0?什么是可观测性 2.0 原生数据库?](https://greptime.cn/blogs/2025-04-24-observability2.0-greptimedb.html) — 下一代可观测性的愿景
- [事件管理革命:监控系统中统一日志和指标](https://greptime.cn/blogs/2024-06-25-logs-and-metrics)
- [GreptimeDB 存储引擎设计内幕](https://greptime.cn/blogs/2022-12-21-storage-engine-design)
---
## 存储位置
GreptimeDB 支持将数据存储在本地文件系统、AWS S3 及其兼容服务(包括 minio、digitalocean space、腾讯云对象存储 (COS)、百度云对象存储 (BOS) 等)、Azure Blob Storage 和阿里云 OSS 中。
## 本地文件结构
GreptimeDB 的存储文件结构包括以下内容:
```cmd
├── metadata
├── raftlog
├── rewrite
└── LOCK
├── data
│ ├── greptime
│ └── public
├── cache
├── logs
├── index_intermediate
│ └── staging
└── wal
├── raftlog
├── rewrite
└── LOCK
```
- `metadata`: 内部元数据目录,保存 catalog、数据库以及表的元信息、procedure 状态等内部状态。在集群模式下,此目录不存在,因为所有这些状态(包括区域路由信息)都保存在 `Metasrv` 中。
- `data`: 存储 GreptimeDB 的实际的时间序列数据和索引文件。如果要自定义此路径,请参阅 [存储选项](/user-guide/deployments-administration/configuration.md#storage-options)。该目录按照 catalog 和 schema 的两级结构组织。
- `cache`: 内部的数据缓存目录,比如对象存储的本地缓存等。
- `logs`: GreptimeDB 日志文件目录。
- `wal`: 预写日志文件目录。
- `index_intermediate`: 索引构建和查询相关的临时中间数据目录。
## 云存储
文件结构中的 `data` 目录可以存储在云存储中。请参考[存储选项](/user-guide/deployments-administration/configuration.md#storage-options)了解更多细节。
请注意,仅将 `data` 目录存储在对象存储中不足以确保数据可靠性和灾难恢复,`wal` 和 `metadata` 也需要考虑灾难恢复,更详细地请参阅[灾难恢复文档](/user-guide/deployments-administration/disaster-recovery/overview.md)。
## 多存储引擎支持
GreptimeDB 的另一个强大功能是可以为每张表单独选择存储引擎。例如,您可以将一些表存储在本地磁盘上,将另一些表存储在 Amazon S3 或 Google Cloud Storage 中,请参考 [create table](/reference/sql/create.md#create-table)。
---
## 为什么选择 GreptimeDB
## 问题:三种信号,三套系统
大多数团队的可观测性栈长这样:[Prometheus](/user-guide/ingest-data/for-observability/prometheus.md)(或 Thanos/Mimir)跑 metrics,[Grafana Loki](/user-guide/ingest-data/for-observability/loki.md)(或 ELK)跑日志,[Elasticsearch](/user-guide/protocols/elasticsearch.md)(或 Tempo)跑 traces。每套系统各有一套查询语言、存储方案、扩展方式,运维各管各的。
"三支柱"架构在这些关注点各自独立时是合理的。但实际跑起来就是:
- **3 倍运维量** — 三套系统要分别部署、监控、升级、排障
- **数据孤岛** — 错误率飙升和日志里的异常模式要手动在系统间切换才能关联
- **成本失控** — 每套系统存一份冗余元数据,各自独立扩展导致资源浪费
GreptimeDB 的思路不同:一个引擎处理三种信号,数据放对象存储,计算存储分离。
## 统一处理可观测数据
GreptimeDB 通过以下方式统一处理 metrics、logs 和 traces:
- 一致的[数据模型](./data-model.md),将所有可观测数据视为带上下文的时间戳宽事件
- 原生支持 [SQL](/user-guide/query-data/sql.md) 和 [PromQL](/user-guide/query-data/promql.md) 双查询
- 内置流计算能力([Flow](/user-guide/flow-computation/overview.md))做实时聚合和分析
- 跨信号无缝关联分析(参见 [SQL 示例](/getting-started/quick-start.md#关联-metricslogs-和-traces))
一套系统替代原来的多组件栈。
具体来说:用一个数据库替代 [Prometheus](/user-guide/ingest-data/for-observability/prometheus.md) + [Loki](/user-guide/ingest-data/for-observability/loki.md) + [Elasticsearch](/user-guide/protocols/elasticsearch.md),用 SQL 在一条查询里关联 metrics 异常、日志模式和 trace 延迟——不用在系统间来回切换。
## 对象存储,成本低一个数量级
GreptimeDB 以[云对象存储](/user-guide/concepts/storage-location.md)(S3、Azure Blob Storage 等)为主存储层,配合列式压缩,存储成本最高可降低 50 倍。支持灵活扩展到各类云存储,管理简单,**无厂商锁定**。
生产环境实测:
- **Logs**:OceanBase Cloud 生产环境存储成本下降 60%+(从 [Loki](/user-guide/ingest-data/for-observability/loki.md) 迁移到 GreptimeDB,80+ 集群、300TB 多云日志和 SQL 审计数据)
- **Traces**:存储成本降低 45 倍,查询快 3 倍(替换 [Elasticsearch](/user-guide/protocols/elasticsearch.md) 作为 [Jaeger](/user-guide/query-data/jaeger.md) 后端,一周完成迁移)
- **Metrics**:用原生计算存储分离替代 Thanos,运维复杂度大幅下降
## 高性能
写入端,GreptimeDB 用 LSM Tree、数据分片、灵活的 WAL 配置(本地盘或 Kafka)等手段处理大规模可观测数据的写入负载。
查询端,GreptimeDB 用纯 Rust 编写,查询引擎基于 [Apache DataFusion](https://datafusion.apache.org/) 做向量化执行和分布式并行处理,结合[多种索引](/user-guide/manage-data/data-index.md)(倒排索引、跳数索引、全文索引)做智能裁剪和过滤。
[GreptimeDB 在 JSONBench 10 亿条记录冷查询中拿下第一!](https://greptime.cn/blogs/2025-03-18-json-benchmark-greptimedb) 更多[性能测试报告](https://greptime.cn/blogs/2024-09-09-report-summary)。
## 基于 Kubernetes 的弹性扩展
GreptimeDB 从底层就为 [Kubernetes](/user-guide/deployments-administration/deploy-on-kubernetes/overview.md) 设计,采用计算存储分离[架构](/user-guide/concepts/architecture.md),实现真正的弹性扩展:
- 存储和计算资源独立伸缩
- 通过 Kubernetes 水平扩展,无上限
- 写入、查询、压缩等不同负载之间做资源隔离
- 自动故障转移和高可用
Thanos 和 Mimir 要靠多个有状态组件(ingester 需要持久盘、store-gateway、compactor)才能扩展。GreptimeDB 从架构层面就是计算存储分离——数据持久化在对象存储,计算节点独立扩展,本地盘只做缓冲和缓存。扩容加节点,缩容不丢数据。
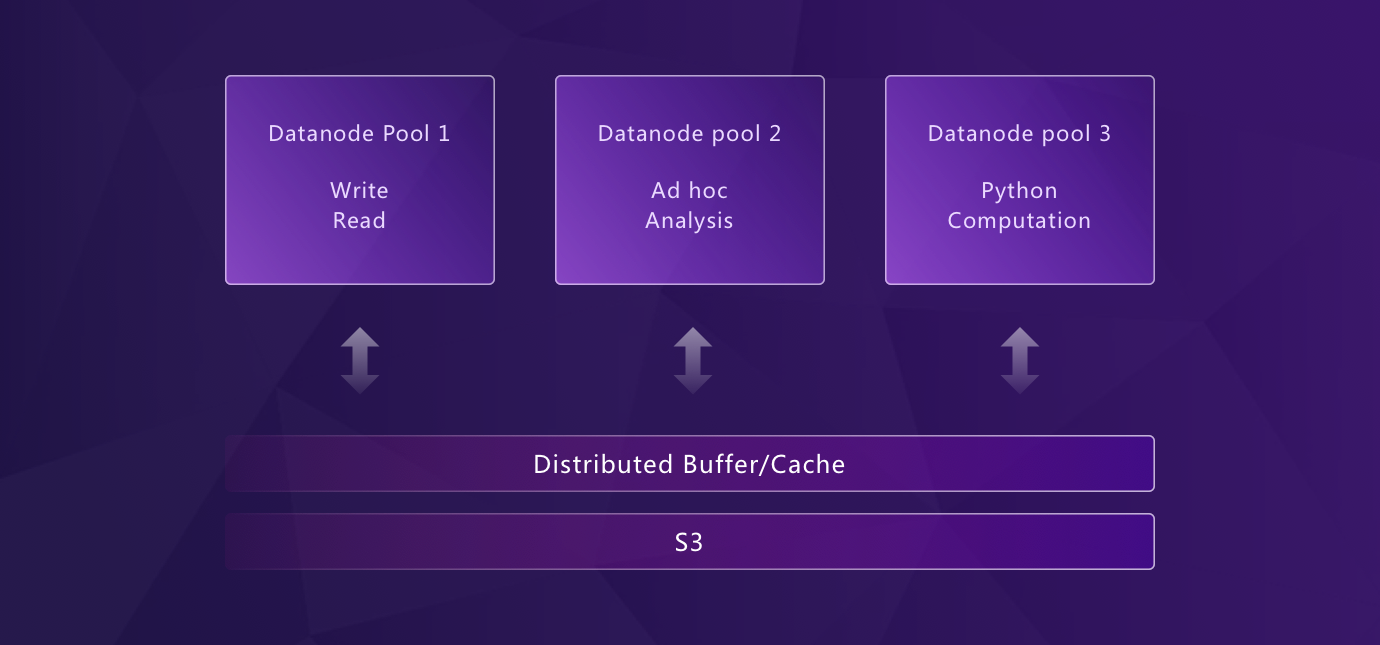
## 灵活部署:从边缘到云
GreptimeDB 的模块化[架构](/user-guide/concepts/architecture.md)让各组件既能独立运行,也能协同部署。从边缘设备到云环境,都用同一套 API。比如:
- Frontend、Datanode 和 Metasrv 可以合并成单一二进制(standalone 模式)
- WAL、索引等组件可以按表级别启用或关闭
这种灵活性让 GreptimeDB 能覆盖从边缘到云的完整场景,比如[边云一体化解决方案](https://greptime.cn/carcloud)。
从嵌入式单机部署到云原生集群,GreptimeDB 都能适配。
## 易于集成
GreptimeDB 支持 [PromQL](/user-guide/query-data/promql.md)、[Prometheus remote write](/user-guide/ingest-data/for-observability/prometheus.md)、[OpenTelemetry](/user-guide/ingest-data/for-observability/opentelemetry.md)、[Jaeger](/user-guide/query-data/jaeger.md)、[Loki](/user-guide/ingest-data/for-observability/loki.md)、[Elasticsearch](/user-guide/protocols/elasticsearch.md)、[MySQL](/user-guide/protocols/mysql.md)、[PostgreSQL](/user-guide/protocols/postgresql.md) 协议——从现有栈迁移不用改查询、不用改 pipeline。查询用 [SQL](/user-guide/query-data/sql.md) 或 PromQL,可视化接 [Grafana](/user-guide/integrations/grafana.md)。
SQL + PromQL 双引擎意味着 GreptimeDB 可以替代"Prometheus + 数据仓库"的经典组合——PromQL 做实时监控告警,SQL 做深度分析、JOIN、聚合,全在一个系统里。GreptimeDB 还支持[多值模型](/user-guide/concepts/data-model.md),单行可以有多个字段列,比单值模型省流量、查询也更简洁。
SQL 不只是查询语言,也是 GreptimeDB 的管理入口——[建表](/user-guide/deployments-administration/manage-data/basic-table-operations.md)、[管理 schema](/reference/sql/alter.md)、设置 [TTL 策略](/user-guide/manage-data/overview.md#使用-ttl-策略保留数据)、配置[索引](/user-guide/manage-data/data-index.md),全部用标准 SQL 完成。不需要专有配置文件,不需要自定义 API,不需要 YAML 驱动的控制面。这是和 Prometheus(YAML 配置 + relabeling rules)、Loki(YAML 配置 + LogQL)、Elasticsearch(REST API + JSON mappings)在运维层面的关键区别。团队只要会 SQL,就能管理 GreptimeDB,不用学新工具。
## GreptimeDB 对比
| | GreptimeDB | Prometheus / Thanos / Mimir | Grafana Loki | Elasticsearch |
|---|---|---|---|---|
| 数据类型 | Metrics、Logs、Traces | 仅 Metrics | 仅 Logs | Logs、Traces |
| 查询语言 | SQL + PromQL | PromQL | LogQL | Query DSL |
| 存储 | 原生对象存储(S3 等) | 本地盘 + 对象存储(Thanos/Mimir),ingester 需要持久盘 | 对象存储(chunks) | 本地盘 |
| 扩展 | 计算存储分离,计算节点独立扩展 | Federation / Thanos / Mimir — 多组件,运维重 | 无状态 + 对象存储 | 基于分片,运维重 |
| 成本 | 存储成本最高降低 50 倍 | 大规模下成本高 | 中等 | 高(倒排索引开销) |
| OpenTelemetry | 原生支持(Metrics + Logs + Traces) | 部分(仅 Metrics) | 部分(仅 Logs) | 通过 instrumentation |
| 管理方式 | 标准 SQL(DDL、TTL、索引) | YAML 配置 + relabeling rules | YAML 配置 + LogQL | REST API + JSON mappings |
了解更多:
- [Observability 2.0](./observability-2.md) — 宽事件、统一数据模型,GreptimeDB 面向下一代可观测性的架构
- [可观测性统一存储](https://greptime.cn/blogs/2024-12-24-observability) — GreptimeDB 的统一存储设计
- [替换 Loki!GreptimeDB 在 OB Cloud 的大规模日志存储实践](https://greptime.cn/blogs/2025-07-22-user-case-obcloud-log-storage-greptimedb)
---
## 鉴权
当客户端尝试连接到数据库时,将会进行身份验证。GreptimeDB 通过“user provider”进行身份验证。GreptimeDB 中有多种 user
provider 实现:
- [Static User Provider](./static.md):一个简单的内置 user provider 实现,从静态文件中查找用户。
- [LDAP User Provider](/enterprise/deployments-administration/authentication.md):**企业版功能**,使用外部 LDAP 服务进行用户身份验证。
---
## Static User Provider
GreptimeDB 提供了简单的内置身份验证机制,允许你配置一个固定的帐户以方便使用,或者配置一个帐户文件以支持多个用户帐户。通过传入文件,GreptimeDB 会加载其中的所有用户。
## 单机模式
GreptimeDB 从配置文件中读取用户配置,每行定义一个用户及其密码和可选的权限模式。
### 基本配置
基本格式使用 `=` 作为用户名和密码之间的分隔符:
```
greptime_user=greptime_pwd
alice=aaa
bob=bbb
```
以这种方式配置的用户默认拥有完整的读写权限。
### 权限模式
你可以选择性地指定权限模式来控制用户的访问级别。格式为:
```
username:permission_mode=password
```
可用的权限模式:
- `rw` 或 `readwrite` - 完整的读写权限(未指定时的默认值)
- `ro` 或 `readonly` - 只读权限
- `wo` 或 `writeonly` - 只写权限
混合权限模式的配置示例:
```
admin=admin_pwd
alice:readonly=aaa
bob:writeonly=bbb
viewer:ro=viewer_pwd
editor:rw=editor_pwd
```
在此配置中:
- `admin` 拥有完整的读写权限(默认)
- `alice` 拥有只读权限
- `bob` 拥有只写权限
- `viewer` 拥有只读权限
- `editor` 明确设置了读写权限
### 启动服务器
在启动服务端时,需添加 `--user-provider` 参数,并将其设置为 `static_user_provider:file:`(请将 `` 替换为你的用户配置文件路径):
```shell
./greptime standalone start --user-provider=static_user_provider:file:
```
用户及其权限将被载入 GreptimeDB 的内存。使用这些用户账户连接至 GreptimeDB 时,系统会严格执行相应的访问权限控制。
:::tip 注意
`static_user_provider:file` 模式下,文件的内容只会在启动时被加载到数据库中,在数据库运行时修改或追加的内容不会生效。
:::
### 动态文件重载
如果你需要在不重启服务器的情况下更新用户凭证,可以使用 `watch_file_user_provider` 替代 `static_user_provider:file`。该 provider 会监控凭证文件的变化并自动重新加载:
```shell
./greptime standalone start --user-provider=watch_file_user_provider:
```
`watch_file_user_provider`的特点:
- 使用与 `static_user_provider:file` 相同的文件格式
- 自动检测文件修改并重新加载凭证
- 允许在不重启服务器的情况下添加、删除或修改用户
- 如果文件临时不可用或无效,会保持上次有效的配置
这在需要动态管理用户访问的生产环境中特别有用。
## Kubernetes 集群
你可以在 `values.yaml` 文件中配置鉴权用户。
更多详情,请参考 [Helm Chart 配置](/user-guide/deployments-administration/deploy-on-kubernetes/common-helm-chart-configurations.md#鉴权配置)。
---
## 容量规划
本指南提供了关于 GreptimeDB 的 CPU、内存和存储需求的一般建议。
GreptimeDB 具备超轻量级的启动基准,
这使数据库能以最少的服务器资源启动。
然而当为生产环境配置服务器容量时,
以下关键因素需要被考虑:
- 每秒处理的数据点数
- 每秒查询请求
- 数据量
- 数据保留策略
- 硬件成本
要监控 GreptimeDB 的各种指标,请参阅[监控](/user-guide/deployments-administration/monitoring/overview.md)。
## CPU
一般来说,大量并发查询、处理大量数据或执行其他计算密集型操作的应用需要更多的 CPU 核数。
以下是一些关于 CPU 资源使用的建议,
但实际使用的 CPU 核数取决于你实际的工作负载。
你可以考虑将 30% 的 CPU 资源用于数据写入,
剩余 70% 用于查询和分析。
一般推荐 CPU 到内存的比例为 1:4(例如,8 核 32 GB),
如果你的主要工作负载是数据写入且查询请求较少,
1:2 的比例(8 核 16 GB)也是可以接受的。
## 内存
一般来说,内存越大,查询速度越快。
对于基本工作负载,建议至少有 8 GB 的内存,对于更高级的工作负载,建议至少有 32 GB 的内存。
## 存储空间
GreptimeDB 具有高效的数据压缩机制,可将原始数据大小减少到其初始大小的约 1/8 到 1/10。
这使得 GreptimeDB 以更小的空间存储大量数据。
数据可以存储在本地文件系统或云存储中,例如 AWS S3。
有关存储选项的更多信息,
请参阅[存储配置](/user-guide/deployments-administration/configuration.md#存储选项)文档。
由于云存储在存储管理方面的简单性,强烈推荐使用云存储进行数据存储。
使用云存储时,本地存储空间只需要大约 200GB 用于查询相关的缓存和 Write-Ahead Log (WAL)。
无论你选择云存储还是本地存储,
建议设置[保留策略](/user-guide/concepts/features-that-you-concern.md#可以按表设置-ttl-或保留策略吗)以有效管理存储成本。
## 举例
假设你的数据库每秒处理约 200 个简单查询请求(QPS),每秒处理约 300k 数据点的写入请求,使用云存储存储数据。
在这种写入和查询速率下,
以下是你可能分配资源的示例:
- CPU:8 核
- 内存:32 GB
- 存储空间:200 GB
这样的分配旨在优化性能,
确保数据写入和查询处理的平稳进行,而不会导致系统过载。
然而,请记住这些只是建议,
实际需求可能会根据特定的工作负载特征和性能期望而有所不同。
---
## GreptimeDB 部署配置
# 配置 GreptimeDB
GreptimeDB 提供了层次化的配置能力,按照下列优先顺序来生效配置(每个项目都会覆盖下面的项目):
- Greptime 命令行选项
- 配置文件选项
- 环境变量
- 默认值
你只需要设置所需的配置项。
GreptimeDB 将为未配置的任何设置分配默认值。
## 如何设置配置项
### Greptime 命令行选项
你可以使用命令行参数指定多个配置项。
例如,以配置的 HTTP 地址启动 GreptimeDB 的独立模式:
```shell
greptime standalone start --http-addr 127.0.0.1:4000
```
有关 Greptime 命令行支持的所有选项,请参阅 [GreptimeDB 命令行界面](/reference/command-lines/overview.md)。
### 配置文件选项
你可以在 TOML 文件中指定配置项。
例如,创建一个名为 `standalone.example.toml` 的配置文件,如下所示:
```toml
[storage]
type = "File"
data_home = "./greptimedb_data/"
```
然后使用命令行参数 `-c [file_path]` 指定配置文件。
```sh
greptime [standalone | frontend | datanode | metasrv] start -c config/standalone.example.toml
```
例如以 standalone 模式启动 GreptimeDB:
```bash
greptime standalone start -c standalone.example.toml
```
#### 示例文件
以下是每个 GreptimeDB 组件的示例配置文件,包括所有可用配置项。
在实际场景中,你只需要配置所需的选项,不需要像示例文件中那样配置所有选项。
- [独立模式](https://github.com/GreptimeTeam/greptimedb/blob/v1.0.2/config/standalone.example.toml)
- [前端](https://github.com/GreptimeTeam/greptimedb/blob/v1.0.2/config/frontend.example.toml)
- [数据节点](https://github.com/GreptimeTeam/greptimedb/blob/v1.0.2/config/datanode.example.toml)
- [流节点](https://github.com/GreptimeTeam/greptimedb/blob/v1.0.2/config/flownode.example.toml)
- [元服务](https://github.com/GreptimeTeam/greptimedb/blob/v1.0.2/config/metasrv.example.toml)
### Helm 配置
当使用 Helm 在 Kubernetes 上部署 GreptimeDB 时,你可以直接在 Helm `values.yaml` 文件中做相应的设置。
请参阅 [Helm 配置项文档](/user-guide/deployments-administration/deploy-on-kubernetes/common-helm-chart-configurations.md)了解所有 Helm 支持的配置项。
对于仅在本篇文档中[可用的配置项](#配置项),你可以通过[注入 TOML 配置文件](/user-guide/deployments-administration/deploy-on-kubernetes/common-helm-chart-configurations.md#注入配置文件)来设置配置。
### 环境变量
配置文件中的每个项目都可以映射到环境变量。
例如,使用环境变量设置数据节点的 `data_home` 配置项:
```toml
# ...
[storage]
data_home = "/data/greptimedb"
# ...
```
使用以下 shell 命令以以下格式设置环境变量:
```
export GREPTIMEDB_DATANODE__STORAGE__DATA_HOME=/data/greptimedb
```
#### 环境变量规则
- 每个环境变量应具有组件前缀,例如:
- `GREPTIMEDB_FRONTEND`
- `GREPTIMEDB_METASRV`
- `GREPTIMEDB_DATANODE`
- `GREPTIMEDB_STANDALONE`
- 使用**双下划线 `__`**作为分隔符。例如,数据结构 `storage.data_home` 转换为 `STORAGE__DATA_HOME`。
环境变量还接受以逗号 `,` 分隔的列表,例如:
```
GREPTIMEDB_METASRV__META_CLIENT__METASRV_ADDRS=127.0.0.1:3001,127.0.0.1:3002,127.0.0.1:3003
```
## 配置项
本节将介绍主要的配置项,请前往 GitHub 查看[所有配置项](https://github.com/GreptimeTeam/greptimedb/blob/v1.0.2/config/config.md)。
### 写入内存限制选项
内存限制选项控制所有协议(HTTP、gRPC 和 Arrow Flight)并发写入请求使用的总内存。
这些选项适用于 `frontend` 和 `standalone` 子命令。
```toml
# 所有并发写入请求体和消息的最大总内存
# 设置为 0 表示禁用限制(默认为无限制)
max_in_flight_write_bytes = "1GB"
# 写入字节配额耗尽时的策略
# 可选值:`"wait"`(默认,10 秒超时)、`"wait()"`(例如 `"wait(30s)"`)、`"fail"`
write_bytes_exhausted_policy = "wait"
```
| 配置项 | 类型 | 默认值 | 描述 |
| ------------------------------- | ------ | --------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
| `max_in_flight_write_bytes` | 字符串 | `"0"` | 所有并发写入请求体和消息(HTTP、gRPC、Flight)的最大总内存。设置为 `"0"` 表示禁用限制(无限制)。支持的单位:`B`、`KB`、`MB`、`GB` 等。示例:`"1GB"` 将并发写入总量限制为 1GB。 |
| `write_bytes_exhausted_policy` | 字符串 | `"wait"` | 写入字节配额耗尽时的策略。可选值:`"wait"`(默认,等待最多 10 秒)、`"wait()"`(自定义超时时间,例如 `"wait(30s)"`)、`"fail"`(立即拒绝请求)。 |
### 协议选项
协议选项适用于 `frontend` 和 `standalone` 子命令,它指定了协议服务器地址和其他协议相关的选项。
:::tip 提示
HTTP 协议配置适用于所有 GreptimeDB 组件:`frontend`、`datanode`、`flownode` 和 `metasrv`。
:::
下面的示例配置包含了所有协议选项的默认值。
你可以在配置文件中更改这些值或禁用某些协议。
例如禁用 OpenTSDB 协议支持,可以将 `enable` 参数设置为 `false`。
请注意,为了保障数据库的正常工作,无法禁用 HTTP 和 gRPC 协议。
```toml
[http]
addr = "127.0.0.1:4000"
timeout = "0s"
body_limit = "64MB"
[grpc]
bind_addr = "127.0.0.1:4001"
runtime_size = 8
[mysql]
enable = true
addr = "127.0.0.1:4002"
runtime_size = 2
[mysql.tls]
mode = "disable"
cert_path = ""
key_path = ""
[postgres]
enable = true
addr = "127.0.0.1:4003"
runtime_size = 2
[postgres.tls]
mode = "disable"
cert_path = ""
key_path = ""
[opentsdb]
enable = true
[influxdb]
enable = true
[prom_store]
enable = true
```
下表描述了每个选项的详细信息:
| 选项 | 键 | 类型 | 描述 |
| ---------- | ------------------ | ------ | ------------------------------------------------------------ |
| http | | | HTTP 服务器选项 |
| | addr | 字符串 | 服务器地址,默认为 "127.0.0.1:4000" |
| | timeout | 字符串 | HTTP 请求超时时间。设为 "0s" 可禁用超时(默认值为 "0s")。 |
| | body_limit | 字符串 | HTTP 最大体积大小,默认为 "64MB" |
| | prom_validation_mode | 字符串 | 在 Prometheus Remote Write 协议中是否检查字符串是否为有效的 UTF-8 字符串。可用选项:`strict`(拒绝任何包含无效 UTF-8 字符串的请求),`lossy`(用 [UTF-8 REPLACEMENT CHARACTER](https://www.unicode.org/versions/Unicode16.0.0/core-spec/chapter-23/#G24272)(即 `�` ) 替换无效字符),`unchecked`(不验证字符串有效性)。 |
| grpc | | | gRPC 服务器选项 |
| | bind_addr | 字符串 | gRPC 服务绑定地址,默认为 "127.0.0.1:4001" |
| | runtime_size | 整数 | 服务器工作线程数量,默认为 8 |
| | max_connection_age | 字符串 | gRPC 连接在服务端保持的最长时间。参见 ["MAX_CONNECTION_AGE"](https://grpc.io/docs/guides/keepalive/)。默认不设置。示例:"1h" 表示 1 小时,"30m" 表示 30 分钟 |
| | flight_compression | 字符串 | Frontend 的 Arrow IPC 服务的压缩模式。可用选项:`none`:禁用所有压缩,`transport`:仅启用 gRPC 传输压缩(zstd),`arrow_ipc`:仅启用 Arrow IPC 压缩(lz4),`all`:启用所有压缩。默认值为 `none`。|
| mysql | | | MySQL 服务器选项 |
| | enable | 布尔值 | 是否启用 MySQL 协议,默认为 true |
| | addr | 字符串 | 服务器地址,默认为 "127.0.0.1:4002" |
| | runtime_size | 整数 | 服务器工作线程数量,默认为 2 |
| influxdb | | | InfluxDB 协议选项 |
| | enable | 布尔值 | 是否在 HTTP API 中启用 InfluxDB 协议,默认为 true |
| opentsdb | | | OpenTSDB 协议选项 |
| | enable | 布尔值 | 是否启用 OpenTSDB 协议,默认为 true |
| prom_store | | | Prometheus 远程存储选项 |
| | enable | 布尔值 | 是否在 HTTP API 中启用 Prometheus 远程读写,默认为 true |
| | with_metric_engine | 布尔值 | 是否在 Prometheus 远程写入中使用 Metric Engine,默认为 true |
| postgres | | | PostgresSQL 服务器选项 |
| | enable | 布尔值 | 是否启用 PostgresSQL 协议,默认为 true |
| | addr | 字符串 | 服务器地址,默认为 "127.0.0.1:4003" |
| | runtime_size | 整数 | 服务器工作线程数量,默认为 2 |
对 MySQL,Postgres 和 gRPC 接口,我们支持 TLS 配置
| Option | Key | Type | Description |
|------------------------------------------|-------------|---------|--------------------------------------------------|
| `mysql.tls`,`postgres.tls` 或 `grpc.tls` | | | MySQL 或 Postgres 的 TLS 配置 |
| | `mode` | String | TLS 模式,支持 `disable`, `prefer` and `require` |
| | `cert_path` | String | TLS 证书文件路径 |
| | `key_path` | String | TLS 私钥文件路径 |
| | `watch` | Boolean | 监控文件变化,自动重新加载证书或私钥 |
### 查询选项
`查询`选项在 standalone、datanode 和 frontend 模式下有效,用于控制查询引擎的行为。
下表详细描述了这些选项:
| 选项 | 键 | 类型 | 描述 |
| ----------- | ------------------ | ------ | -------------------------------------------------------------------- |
| parallelism | 整数 | `0` | 查询引擎的并行度。默认为 0,表示 CPU 核心数。 |
示例配置:
```toml
[query]
parallelism = 0
```
### 存储选项
`存储`选项在 `datanode` 和 `standalone` 模式下有效,它指定了数据库数据目录和其他存储相关的选项。
GreptimeDB 支持将数据保存在本地文件系统,AWS S3 以及其兼容服务(比如 MinIO、digitalocean space、腾讯 COS、百度对象存储(BOS)等),Azure Blob Storage 和阿里云 OSS。
| 选项 | 键 | 类型 | 描述 |
| ------- | ----------------- | ------ | --------------------------------------------------- |
| storage | | | 存储选项 |
| | type | 字符串 | 存储类型,支持 "File","S3" 和 "Oss" 等。 |
| File | | | 本地文件存储选项,当 type="File" 时有效 |
| | data_home | 字符串 | 数据库存储根目录,默认为 "./greptimedb_data" |
| S3 | | | AWS S3 存储选项,当 type="S3" 时有效 |
| | name | 字符串 | 存储提供商名字,默认为 `S3` |
| | bucket | 字符串 | S3 桶名称 |
| | root | 字符串 | S3 桶中的根路径 |
| | endpoint | 字符串 | S3 的 API 端点 |
| | region | 字符串 | S3 区域 |
| | access_key_id | 字符串 | S3 访问密钥 id |
| | secret_access_key | 字符串 | S3 秘密访问密钥 |
| | enable_virtual_host_style | 布尔值 | 使用 virtual-host-style 域名而不是 path-style 域名调用 API,默认为 false |
| Oss | | | 阿里云 OSS 存储选项,当 type="Oss" 时有效 |
| | name | 字符串 | 存储提供商名字,默认为 `Oss` |
| | bucket | 字符串 | OSS 桶名称 |
| | root | 字符串 | OSS 桶中的根路径 |
| | endpoint | 字符串 | OSS 的 API 端点 |
| | access_key_id | 字符串 | OSS 访问密钥 id |
| | access_key_secret | 字符串 | OSS 秘密访问密钥 |
| Azblob | | | Azure Blob 存储选项,当 type="Azblob" 时有效 |
| | name | 字符串 | 存储提供商名字,默认为 `Azblob` |
| | container | 字符串 | 容器名称 |
| | root | 字符串 | 容器中的根路径 |
| | endpoint | 字符串 | Azure Blob 存储的 API 端点 |
| | account_name | 字符串 | Azure Blob 存储的账户名 |
| | account_key | 字符串 | 访问密钥 |
| | sas_token | 字符串 | 共享访问签名 |
| Gsc | | | Google Cloud Storage 存储选项,当 type="Gsc" 时有效 |
| | name | 字符串 | 存储提供商名字,默认为 `Gsc` |
| | root | 字符串 | Gsc 桶中的根路径 |
| | bucket | 字符串 | Gsc 桶名称 |
| | scope | 字符串 | Gsc 权限 |
| | credential_path | 字符串 | Gsc 访问证书 |
| | endpoint | 字符串 | GSC 的 API 端点 |
文件存储配置范例:
```toml
[storage]
type = "File"
data_home = "./greptimedb_data/"
```
s3 配置范例:
```toml
[storage]
type = "S3"
bucket = "test_greptimedb"
root = "/greptimedb"
access_key_id = ""
secret_access_key = ""
```
### 存储服务的 http 客户端
`[storage.http_client]` 设置了向存储服务发送请求的 http 客户端的各种配置。
仅当存储服务类型是“S3”,“Oss”,“Azblob”或“Gcs”时生效。
| Key | 类型 | 默认值 | 含义 |
|--------------------------|-----|------------|-------------------------------------------------------------|
| `pool_max_idle_per_host` | 数字 | 1024 | http 连接池中对每个 host 的最大空闲连接数。 |
| `connect_timeout` | 字符串 | “30s”(30 秒) | http 客户端在进行连接时的超时 |
| `timeout` | 字符串 | “30s”(30 秒) | 总的 http 请求超时,包括了从建立连接到接收完返回值为止的时间。也可视为一个请求从开始到结束的一个完整的截止时间。 |
| `pool_idle_timeout` | 字符串 | “90s”(90 秒) | 对空闲连接进行保活( "keep-alive" )的超时。 |
### 存储引擎提供商
`[[storage.providers]]` 用来设置存储引擎的提供商列表。基于这个配置,你可以为每张表指定不同的存储引擎,具体请参考 [create table](/reference/sql/create.md#create-table):
```toml
# Allows using multiple storages
[[storage.providers]]
name = "S3"
type = "S3"
bucket = "test_greptimedb"
root = "/greptimedb"
access_key_id = ""
secret_access_key = ""
[[storage.providers]]
name = "Gcs"
type = "Gcs"
bucket = "test_greptimedb"
root = "/greptimedb"
credential_path = ""
```
所有配置的这些存储引擎提供商的 `name` 都可以在创建表时用作 `storage` 选项。
对于同样提供商的存储,比如你希望使用不同 S3 bucket 来作为不同表的存储引擎,你就可以设置不同的 `name`,并在创建表的时候指定 `storage` 选项。
### 对象存储缓存
在使用 AWS S3、阿里云 OSS 或 Azure Blob Storage 等远程存储服务时,查询过程中获取数据通常会很耗时,尤其在公有云环境。为了解决这个问题,GreptimeDB 提供了写入缓存机制来加速重复数据的访问。
你可以通过修改 mito 的配置调整缓存的大小和行为。
```toml
[[region_engine]]
[region_engine.mito]
write_cache_size = "10GiB"
# 在写入缓存未命中时从对象存储下载文件填充缓存
enable_refill_cache_on_read = true
```
默认情况下,当查询时发生缓存未命中,GreptimeDB 会自动从对象存储下载文件填充写入缓存(`enable_refill_cache_on_read = true`)。这可以提高后续查询性能,使频繁访问的数据保留在写入缓存中。如果你想减少网络流量或存储成本,可以通过设置 `enable_refill_cache_on_read = false` 来禁用此行为。
更详细的信息请参阅[性能调优技巧](/user-guide/deployments-administration/performance-tuning/performance-tuning-tips.md)。
### WAL 选项
GreptimeDB 支持三种 WAL 存储方式:本地 WAL、Remote WAL 和 Noop WAL。关于它们的对比,请参见 [WAL 概述](/user-guide/deployments-administration/wal/overview.md)。具体配置可参考 [本地 WAL](/user-guide/deployments-administration/wal/local-wal.md)、[Remote WAL](/user-guide/deployments-administration/wal/remote-wal/configuration.md) 和 [Noop WAL](/user-guide/deployments-administration/wal/noop-wal.md) 文档。
### Logging 选项
`frontend`、`metasrv`、`datanode` 和 `standalone` 都可以在 `[logging]` 部分配置 log、tracing 相关参数:
```toml
[logging]
dir = "./greptimedb_data/logs"
level = "info"
enable_otlp_tracing = false
otlp_endpoint = "localhost:4317"
append_stdout = true
[logging.tracing_sample_ratio]
default_ratio = 1.0
```
- `dir`: log 输出目录。
- `level`: log 输出的日志等级,日志等级有 `info`, `debug`, `error`, `warn`,默认等级为 `info`。
- `enable_otlp_tracing`:是否打开分布式追踪,默认不开启。
- `otlp_endpoint`:使用基于 gRPC 的 OTLP 协议导出 tracing 的目标端点,默认值为 `localhost:4317`。
- `append_stdout`:是否将日志打印到 stdout。默认是`true`。
- `tracing_sample_ratio`:该字段可以配置 tracing 的采样率,如何使用 `tracing_sample_ratio`,请参考 [如何配置 tracing 采样率](/user-guide/deployments-administration/monitoring/tracing.md#指南如何配置-tracing-采样率)。
如何使用分布式追踪,请参考 [Tracing](/user-guide/deployments-administration/monitoring/tracing.md#教程使用-jaeger-追踪-greptimedb-调用链路)
### Region 引擎选项
datanode 和 standalone 在 `[region_engine]` 部分可以配置不同存储引擎的对应参数。目前可以配置 `mito` 和 `metric` 存储引擎的选项。
部分常用的选项如下
```toml
[[region_engine]]
[region_engine.mito]
num_workers = 8
manifest_checkpoint_distance = 10
max_background_flushes = 4
max_background_compactions = 2
max_background_purges = 4
auto_flush_interval = "1h"
global_write_buffer_size = "1GB"
global_write_buffer_reject_size = "2GB"
sst_meta_cache_size = "128MB"
vector_cache_size = "512MB"
page_cache_size = "512MB"
write_cache_size = "5GB"
write_cache_ttl = "8h"
scan_memory_limit = "unlimited"
scan_memory_on_exhausted = "fail"
min_compaction_interval = "0m"
default_flat_format = true
sst_write_buffer_size = "8MB"
max_concurrent_scan_files = 384
[region_engine.mito.index]
aux_path = ""
staging_size = "2GB"
staging_ttl = "7d"
metadata_cache_size = "64MiB"
content_cache_size = "128MiB"
content_cache_page_size = "64KiB"
result_cache_size = "128MiB"
[region_engine.mito.inverted_index]
create_on_flush = "auto"
create_on_compaction = "auto"
apply_on_query = "auto"
mem_threshold_on_create = "64M"
intermediate_path = ""
[region_engine.mito.memtable]
type = "time_series"
```
此外,`mito` 也提供了一个实验性质的 memtable。该 memtable 主要优化大量时间序列下的写入性能和内存占用。其查询性能可能会不如默认的 `time_series` memtable。
```toml
[region_engine.mito.memtable]
type = "partition_tree"
index_max_keys_per_shard = 8192
data_freeze_threshold = 32768
fork_dictionary_bytes = "1GiB"
```
以下是可供使用的选项
| 键 | 类型 | 默认值 | 描述 |
| ---------------------------------------- | ------ | ------------- | ---------------------------------------------------------------------------------------------------------------------- |
| `num_workers` | 整数 | `8` | 写入线程数量 |
| `manifest_checkpoint_distance` | 整数 | `10` | 每写入 `manifest_checkpoint_distance` 个 manifest 文件创建一次 checkpoint |
| `compress_manifest` | 布尔值 | `false` | 是否使用 gzip 压缩 manifest 和 checkpoint 文件。 |
| `max_background_flushes` | 整数 | 自动 | 后台 flush 任务数(默认:1/2 CPU 核心数)。 |
| `max_background_compactions` | 整数 | 自动 | 后台 compaction 任务数(默认:1/4 CPU 核心数)。 |
| `max_background_purges` | 整数 | 自动 | 后台 purge 任务数(默认:CPU 核心数)。 |
| `auto_flush_interval` | 字符串 | `1h` | 自动 flush 超过 `auto_flush_interval` 没 flush 的 region |
| `global_write_buffer_size` | 字符串 | `1GB` | 写入缓冲区大小,默认值为内存总量的 1/8,但不会超过 1GB |
| `global_write_buffer_reject_size` | 字符串 | `2GB` | 写入缓冲区内数据的大小超过 `global_write_buffer_reject_size` 后拒绝写入请求,默认为 `global_write_buffer_size` 的 2 倍 |
| `sst_meta_cache_size` | 字符串 | `128MB` | SST 元数据缓存大小。设为 0 可关闭该缓存默认为内存的 1/32,不超过 128MB |
| `vector_cache_size` | 字符串 | `512MB` | 内存向量和 arrow array 的缓存大小。设为 0 可关闭该缓存默认为内存的 1/16,不超过 512MB |
| `page_cache_size` | 字符串 | `512MB` | SST 数据页的缓存。设为 0 可关闭该缓存默认为内存的 1/8 |
| `write_cache_size` | 字符串 | `5GiB` | 写入缓存容量。如果磁盘空间充足,建议设置更大的值。 |
| `write_cache_ttl` | 字符串 | `8h` | 写入缓存的 TTL。默认为 8 小时。 |
| `preload_index_cache` | 布尔值 | `true` | 在 region 打开时预加载索引(puffin)文件到缓存(默认:true)。启用时,索引文件会在 region 初始化期间加载到写入缓存中,这可以提高查询性能,但会延长启动时间。 |
| `index_cache_percent` | 整数 | `20` | 为索引(puffin)文件分配的写入缓存容量百分比(默认:20)。剩余容量用于数据(parquet)文件。必须在 0 到 100 之间(不包括边界)。例如,对于 5GiB 的写入缓存和 20% 的分配,1GiB 保留给索引文件,4GiB 用于数据文件。 |
| `enable_refill_cache_on_read` | 布尔值 | `true` | 启用读取操作时的缓存回填(默认:true)。禁用时,不会在读取时回填缓存。 |
| `manifest_cache_size` | 字符串 | `256MB` | Manifest 缓存容量(默认:256MB)。 |
| `selector_result_cache_size` | 字符串 | `512MB` | `last_value()` 等时间线检索结果的缓存。设为 0 可关闭该缓存默认为内存的 1/16,不超过 512MB |
| `sst_write_buffer_size` | 字符串 | `8MB` | SST 的写缓存大小 |
| `max_concurrent_scan_files` | 整数 | `384` | 最大并发扫描的 SST 文件数量。 |
| `allow_stale_entries` | 布尔值 | `false` | 是否允许 replay 时读取陈旧的 WAL 条目。 |
| `scan_memory_limit` | 字符串 | `unlimited` | 所有查询的表扫描内存限制。支持绝对大小(如 "2GB")或系统内存百分比(如 "20%")。设为 0 或 "unlimited" 可禁用限制。 |
| `scan_memory_on_exhausted` | 字符串 | `fail` | 扫描内存耗尽时的行为。选项:`fail`(快速失败),`wait` 或 `wait()`(等待内存)。 |
| `min_compaction_interval` | 字符串 | `0m` | 两次 compaction 之间的最小时间间隔。设为 "0m"(默认)允许 compactions 立即运行,无限制。 |
| `default_flat_format` | 布尔值 | `true` | 是否启用 Flat 格式作为默认 SST 格式。 |
| `scan_parallelism` | 整数 | `0` | (已弃用,请使用 `max_concurrent_scan_files`)旧版扫描并发度选项。 |
| `index` | -- | -- | Mito 引擎中索引的选项。 |
| `index.aux_path` | 字符串 | `""` | 文件系统中索引的辅助目录路径,用于存储创建索引的中间文件和搜索索引的暂存文件,默认为 `{data_home}/index_intermediate`。为了向后兼容,该目录的默认名称为 `index_intermediate`。此路径包含两个子目录:- `__intm`: 用于存储创建索引时使用的中间文件。- `staging`: 用于存储搜索索引时使用的暂存文件。 |
| `index.staging_size` | 字符串 | `2GB` | 暂存目录的最大容量。 |
| `index.staging_ttl` | 字符串 | `7d` | 暂存目录的 TTL。默认为 7 天。设为 "0s" 可禁用 TTL。 |
| `index.metadata_cache_size` | 字符串 | `64MiB` | 索引元数据的缓存大小。 |
| `index.content_cache_size` | 字符串 | `128MiB` | 索引内容的缓存大小。 |
| `index.content_cache_page_size` | 字符串 | `64KiB` | 倒排索引内容缓存的页大小。 |
| `index.result_cache_size` | 字符串 | `128MiB` | 索引查询结果的缓存大小。 |
| `inverted_index.create_on_flush` | 字符串 | `auto` | 是否在 flush 时构建索引- `auto`: 自动- `disable`: 从不 |
| `inverted_index.create_on_compaction` | 字符串 | `auto` | 是否在 compaction 时构建索引- `auto`: 自动- `disable`: 从不 |
| `inverted_index.apply_on_query` | 字符串 | `auto` | 是否在查询时使用索引- `auto`: 自动- `disable`: 从不 |
| `inverted_index.mem_threshold_on_create` | 字符串 | `64M` | 创建索引时如果超过该内存阈值则改为使用外部排序设置为空会关闭外排,在内存中完成所有排序 |
| `inverted_index.intermediate_path` | 字符串 | `""` | 存放外排临时文件的路径 (默认 `{data_home}/index_intermediate`). |
| `memtable.type` | 字符串 | `time_series` | Memtable type.- `time_series`: time-series memtable- `partition_tree`: partition tree memtable (实验性功能) |
| `memtable.index_max_keys_per_shard` | 整数 | `8192` | 一个 shard 内的主键数只对 `partition_tree` memtable 生效 |
| `memtable.data_freeze_threshold` | 整数 | `32768` | 一个 shard 内写缓存可容纳的最大行数只对 `partition_tree` memtable 生效 |
| `memtable.fork_dictionary_bytes` | 字符串 | `1GiB` | 主键字典的大小只对 `partition_tree` memtable 生效 |
`metric` 引擎针对包含大量小表的 metrics 数据进行了优化:
```toml
[[region_engine]]
[region_engine.metric]
sparse_primary_key_encoding = true
```
可用选项:
| 键 | 类型 | 默认值 | 描述 |
| --------------------------------- | ------ | ------- | ----------------------------------------------------------------------------------------------------------------- |
| `sparse_primary_key_encoding` | 布尔值 | `true` | 是否使用稀疏主键编码。此优化通过仅编码非空主键列来提高写入和查询性能。 |
### 设定 meta client
`meta_client` 选项适用于 `datanode` 和 `frontend` 模块,用于指定 Metasrv 的相关信息。
```toml
[meta_client]
metasrv_addrs = ["127.0.0.1:3002"]
timeout = "3s"
connect_timeout = "1s"
ddl_timeout = "10s"
tcp_nodelay = true
```
通过 `meta_client` 配置 metasrv 客户端,包括:
- `metasrv_addrs`,Metasrv 地址列表,对应 Metasrv 启动配置的 server address。
- `timeout`,操作超时时长,默认为 3 秒。
- `connect_timeout`,连接服务器超时时长,默认为 1 秒。
- `ddl_timeout`,DDL 执行的超时时间,默认 10 秒。
- `tcp_nodelay`,接受连接时的 `TCP_NODELAY` 选项,默认为 true。
### 心跳配置
在分布式模式下,心跳间隔由 Metasrv 的 `heartbeat_interval` 选项统一控制。
```toml
heartbeat_interval = "3s"
```
| 键 | 类型 | 默认值 | 描述 |
|----------------------|--------|--------|------|
| `heartbeat_interval` | 字符串 | `3s` | Metasrv 的基础心跳间隔。Frontend 的心跳间隔为该值的 6 倍,Datanode/Flownode 的心跳间隔与该值相同。心跳间隔会在握手阶段由 Metasrv 协商下发。 |
### 默认时区配置
`default_timezone` 选项适用于 `frontend` 模块和 `standalone` 模式,默认值为 `UTC`。
它指定了与 GreptimeDB 交互时的客户端默认时区。
如果在客户端中[指定了时区](/user-guide/timezone.md#在客户端中指定时区),此选项将在该客户端会话中被覆盖。
```toml
default_timezone = "UTC"
```
`default_timezone` 的值可以是任何时区名称,例如 `Europe/Berlin` 或 `Asia/Shanghai`。
有关客户端时区如何影响数据的写入和查询,请参阅[时区](/user-guide/timezone.md#时区对-sql-语句的影响)文档。
### 仅限于 Metasrv 的配置
```toml
# 工作主目录。
data_home = "./greptimedb_data"
# metasrv 存储后端服务器地址,默认为 etcd 实现。
# 对于 postgres 存储后端,格式为:
# "password=password dbname=postgres user=postgres host=localhost port=5432"
# 对于 mysql 存储后端,格式为:
# "mysql://user:password@ip:port/dbname"
# 对于 etcd 存储后端,格式为:
# "127.0.0.1:2379"
store_addrs = ["127.0.0.1:2379"]
# 如果不为空,metasrv 将使用此键前缀存储所有数据。
store_key_prefix = ""
# metasrv 的存储后端类型。
# 可选项:
# - `etcd_store`(默认值)
# - `memory_store`
# - `postgres_store`
# - `mysql_store`
backend = "etcd_store"
# 在 RDS 中存储元数据的表名。仅在使用 RDS kvbackend 时生效。
# **仅当后端为 RDS kvbackend 时使用。**
meta_table_name = "greptime_metakv"
## PostgreSQL 选举的咨询锁 ID。仅在使用 PostgreSQL 作为 kvbackend 时生效。
## 仅当后端为 `postgres_store` 时使用。
meta_election_lock_id = 1
# Datanode 选择器类型。
# - "lease_based" (默认值)
# - `lease_based`
# - "load_based"
# 详情请参阅 "https://docs.greptime.com/contributor-guide/meta/selector"
selector = "lease_based"
# 将数据存储在内存中,默认值为 false。
use_memory_store = false
# 是否启用 region failover。
# 该功能仅适用于以集群模式运行并使用共享存储(例如 s3)的 GreptimeDB,并且 WAL 需要满足以下条件之一:
# - Remote WAL
# - Local WAL 且设置 `allow_region_failover_on_local_wal = true`(故障转移期间可能导致数据丢失)
enable_region_failover = false
## 设置启动 region 故障检测的延迟时间。
## 该延迟有助于避免在所有 Datanode 尚未完全启动时,Metasrv 过早启动 region 故障检测,从而导致不必要的 region failover。
## 尤其适用于未通过 GreptimeDB Operator 部署的集群,此时可能未正确启用集群维护模式,提前检测可能会引发误判。
region_failure_detector_initialization_delay = "10m"
# 是否允许在本地 WAL 上进行 region failover。
# **此选项不建议设置为 true,
# 因为这可能会在故障转移期间导致数据丢失。**
allow_region_failover_on_local_wal = false
## 从 metasrv 内存中删除节点信息前允许的最大空闲时间。
node_max_idle_time = "24hours"
## 后端客户端选项。
## 目前仅适用于使用 etcd 作为元数据存储时。
[backend_client]
## 后端客户端的保持连接超时时间。
keep_alive_timeout = "3s"
## 后端客户端的保持连接间隔。
keep_alive_interval = "10s"
## 后端客户端的连接超时时间。
connect_timeout = "3s"
## gRPC 服务器选项。
[grpc]
bind_addr = "127.0.0.1:3002"
server_addr = "127.0.0.1:3002"
runtime_size = 8
## 服务器端 HTTP/2 保持连接间隔
http2_keep_alive_interval = "10s"
## 服务器端 HTTP/2 保持连接超时时间。
http2_keep_alive_timeout = "3s"
## Procedure 选项
[procedure]
## 最大重试次数
max_retry_times = 12
## 程序的初始重试延迟
retry_delay = "500ms"
## 最大运行程序数。
## 同一时间可以运行的程序最大数量。
## 如果运行的程序数量超过此限制,程序将被拒绝。
max_running_procedures = 128
# Failure detector 选项
# GreptimeDB 使用 Phi 累积故障检测器算法来检测数据节点故障。
[failure_detector]
## 判定节点故障前可接受的最大 φ 值。
## 较低的值反应更快但会产生更多误报。
threshold = 8.0
## 心跳间隔的最小标准差。
## 防止微小变化导致 φ 值激增。在心跳间隔变化很小时防止过度敏感。
min_std_deviation = "100ms"
## 心跳之间可接受的暂停时长。
## 在 φ 值上升前为学习到的平均间隔提供额外的宽限期,吸收临时网络故障或GC暂停。
acceptable_heartbeat_pause = "10000ms"
## Datanode 选项。
[datanode]
## Datanode 客户端配置。
[datanode.client]
## 操作超时时间
timeout = "10s"
## 连接服务器超时时间。
connect_timeout = "10s"
## 接受连接时的 `TCP_NODELAY` 选项,默认为 true。
tcp_nodelay = true
[wal]
# 可用的 WAL 提供者:
# - `raft_engine`(默认):由于 metasrv 目前仅涉及远程 WAL,因此没有 raft-engine WAL 配置。
# - `kafka`:在 datanode 中使用 kafka WAL 提供者时,metasrv **必须** 配置 kafka WAL 配置。
provider = "raft_engine"
# Kafka WAL 配置。
## Kafka 集群的代理端点。
broker_endpoints = ["127.0.0.1:9092"]
## 自动为 WAL 创建 topics
## 设置为 `true` 则自动为 WAL 创建 topics
## 否则,使用名为 `topic_name_prefix_[0..num_topics)` 的 topics
auto_create_topics = true
## Topic 数量。
num_topics = 64
## Topic selector 类型。
## 可用的 selector 类型:
## - `round_robin`(默认)
selector_type = "round_robin"
## Kafka topic 通过连接 `topic_name_prefix` 和 `topic_id` 构建。
topic_name_prefix = "greptimedb_wal_topic"
## 每个分区的预期副本数。
replication_factor = 1
## 超过此时间创建 topic 的操作将被取消。
create_topic_timeout = "30s"
## kafka 客户端的连接超时时间。
## **仅在 provider 为 `kafka` 时使用。**
connect_timeout = "3s"
## kafka 客户端的超时时间。
## **仅在 provider 为 `kafka` 时使用。**
timeout = "3s"
```
| 键 | 类型 | 默认值 | 描述 |
| --------------------------------------------- | ------- | -------------------- | ------------------------------------------------------------------------------------------------------------------------------------ |
| `data_home` | String | `./greptimedb_data/metasrv/` | 工作目录。 |
| `bind_addr` | String | `127.0.0.1:3002` | Metasrv 的绑定地址。 |
| `server_addr` | String | `127.0.0.1:3002` | frontend 和 datanode 连接到 Metasrv 的通信服务器地址,默认为本地主机的 `127.0.0.1:3002`。 |
| `store_addrs` | Array | `["127.0.0.1:2379"]` | 元数据服务地址,默认值为 `["127.0.0.1:2379"]`。支持配置多个服务地址,格式为 `["ip1:port1","ip2:port2",...]`。默认使用 Etcd 作为元数据后端。根据你的存储服务器类型配置地址,例如:- 使用 `"127.0.0.1:2379"` 连接到 etcd- 使用 `"password=password dbname=postgres user=postgres host=localhost port=5432"` 连接到 postgres- 使用 `"mysql://user:password@ip:port/dbname"` 连接到 mysql |
| `selector` | String | `lease_based` | 创建新表时选择 datanode 的负载均衡策略,详见 [选择器](/contributor-guide/metasrv/selector.md)。 |
| `use_memory_store` | Boolean | `false` | 仅用于在没有 etcd 集群时的测试,将数据存储在内存中,默认值为 `false`。 |
| `enable_region_failover` | Bool | `false` | 是否启用 region failover。该功能仅适用于以集群模式运行并使用共享存储(如 s3)的 GreptimeDB,并且 WAL 需要满足以下条件之一:- Remote WAL- Local WAL 且设置 `allow_region_failover_on_local_wal = true`(故障转移期间可能导致数据丢失)。 |
| `region_failure_detector_initialization_delay` | String | `10m` | 设置启动 region 故障检测的延迟时间。该延迟有助于避免在所有 Datanode 尚未完全启动时,Metasrv 过早启动 region 故障检测,从而导致不必要的 region failover。尤其适用于未通过 GreptimeDB Operator 部署的集群,此时可能未正确启用集群维护模式,提前检测可能会引发误判。 |
| `allow_region_failover_on_local_wal` | Bool | false | 是否允许在本地 WAL 上进行 region failover。**此选项不建议设置为 true,因为这可能会在故障转移期间导致数据丢失。** |
| `node_max_idle_time` | String | `24hours` | 从 metasrv 内存中删除节点信息前允许的最大空闲时间。超过该时间未发送心跳的节点将被视为不活跃并被删除。 |
| `backend_client` | -- | -- | 后端客户端选项。目前仅适用于使用 etcd 作为元数据存储时。 |
| `backend_client.keep_alive_timeout` | String | `3s` | 后端客户端的保持连接超时时间。 |
| `backend_client.keep_alive_interval` | String | `10s` | 后端客户端的保持连接间隔。 |
| `backend_client.connect_timeout` | String | `3s` | 后端客户端的连接超时时间。 |
| `grpc` | -- | -- | gRPC 服务器选项。 |
| `grpc.bind_addr` | String | `127.0.0.1:3002` | gRPC 服务器的绑定地址。 |
| `grpc.server_addr` | String | `127.0.0.1:3002` | frontend 和 datanode 连接到 metasrv 的通信服务器地址。 |
| `grpc.runtime_size` | Integer | `8` | 服务器工作线程数。 |
| `grpc.http2_keep_alive_interval` | String | `10s` | 服务器端 HTTP/2 保持连接间隔。 |
| `grpc.http2_keep_alive_timeout` | String | `3s` | 服务器端 HTTP/2 保持连接超时时间。 |
| `backend` | String | `etcd_store` | 元数据存储类型。- `etcd_store` (默认)- `memory_store` (纯内存存储 - 仅用于测试)- `postgres_store`- `mysql_store` |
| `meta_table_name` | String | `greptime_metakv` | 使用 RDS 存储元数据时的表名。**仅在 backend 为 postgre_store 和 mysql_store 时有效。** |
| `meta_schema_name` | String | -- | 可选的 PostgreSQL schema,用于元数据表和选举表名称限定。当 PostgreSQL public schema 不可写入时(例如 PostgreSQL 15+ 限制 public schema),可设置此参数为可写入的 schema。GreptimeDB 将使用 `meta_schema_name.meta_table_name`。**仅在 backend 为 postgres_store 时有效。** |
| `auto_create_schema` | Bool | `true` | 如果 PostgreSQL schema 不存在则自动创建。启用后,系统会在创建元数据表之前执行 `CREATE SCHEMA IF NOT EXISTS `。这在生产环境中可能受限于手动创建 schema 的情况下非常有用。注意:PostgreSQL 用户必须具有 CREATE SCHEMA 权限才能使此功能生效。**仅在 backend 为 postgres_store 时有效。** |
| `meta_election_lock_id` | Integer | `1` | 用于领导选举的 PostgreSQL 咨询锁 id。**仅在 backend 为 postgre_store 时有效。** |
| `procedure` | -- | -- | |
| `procedure.max_retry_times` | 整数 | `12` | Procedure 的最大重试次数。 |
| `procedure.retry_delay` | 字符串 | `500ms` | Procedure 初始重试延迟,延迟会指数增长。 |
| `procedure.max_running_procedures` | Integer | `128` | 同一时间可以运行的程序最大数量。如果运行的程序数量超过此限制,程序将被拒绝。 |
| `failure_detector` | -- | -- | 故障检测选项。 |
| `failure_detector.threshold` | 浮点数 | `8.0` | 判定节点故障前可接受的最大 φ 值。较低的值反应更快但会产生更多误报。 |
| `failure_detector.min_std_deviation` | 字符串 | `100ms` | 心跳间隔的最小标准差。防止微小变化导致 φ 值激增。在心跳间隔变化很小时防止过度敏感。 |
| `failure_detector.acceptable_heartbeat_pause` | 字符串 | `10000ms` | 心跳之间可接受的暂停时长。在 φ 值上升前为学习到的平均间隔提供额外的宽限期,吸收临时网络故障或GC暂停。 |
| `datanode` | -- | -- | |
| `datanode.client` | -- | -- | Datanode 客户端选项。 |
| `datanode.client.timeout` | 字符串 | `10s` | 操作超时。 |
| `datanode.client.connect_timeout` | 字符串 | `10s` | 连接服务器超时。 |
| `datanode.client.tcp_nodelay` | 布尔值 | `true` | 接受连接的 `TCP_NODELAY` 选项。 |
| wal | -- | -- | -- |
| wal.provider | String | raft_engine | -- |
| wal.broker_endpoints | Array | -- | Kafka 集群的端点 |
| `wal.auto_create_topics` | Bool | `true` | 自动为 WAL 创建 topics 设置为 `true` 则自动为 WAL 创建 topics 否则,使用名为 `topic_name_prefix_[0..num_topics)` 的 topics |
| `wal.auto_prune_interval` | String | `0s` | 定期自动裁剪远程 WAL 的时间间隔 设置为 `0s` 表示禁止自动裁剪 |
| `wal.trigger_flush_threshold` | Integer | `0` | 自动 WAL 裁剪中触发 region flush 操作的阈值 当满足以下条件时,metasrv 会对 region 发送 flush 请求:`trigger_flush_threshold` + `prunable_entry_id` < `max_prunable_entry_id`其中:- `prunable_entry_id` 是该 region 可裁剪的最大日志条目 ID,在该 ID 之前的日志都不被该 region 使用- `max_prunable_entry_id` 是使用与该 region 同一 kafka topic 的所有 region 可裁剪的最大日志条目 ID,在该 ID 之前的日志都不再被任一 region 使用 设置为 `0` 以禁止在自动 WAL 裁剪中触发 region flush 操作 |
| `wal.auto_prune_parallelism` | Integer | `10` | 自动 WAL 裁剪的最大并行任务限制,其中每个任务负责一个 kafka topic 的 WAL 裁剪 |
| `wal.num_topics` | Integer | `64` | Topic 数量 |
| wal.selector_type | String | round_robin | topic selector 类型 可用 selector 类型:- round_robin(默认) |
| wal.topic_name_prefix | String | greptimedb_wal_topic | 一个 Kafka topic 是通过连接 topic_name_prefix 和 topic_id 构建的 |
| wal.replication_factor | Integer | 1 | 每个分区的副本数 |
| wal.create_topic_timeout | String | 30s | 超过该时间后,topic 创建操作将被取消 |
| `wal.connect_timeout` | String | `3s` | kafka 客户端的连接超时时间。**仅在 provider 为 `kafka` 时使用。** |
| `wal.timeout` | String | `3s` | kafka 客户端的超时时间。**仅在 provider 为 `kafka` 时使用。** |
| `wal.sasl` | String | -- | Kafka 客户端 SASL 配置 |
| `wal.sasl.type` | String | -- | SASL 机制,可选值:`PLAIN`, `SCRAM-SHA-256`, `SCRAM-SHA-512` |
| `wal.sasl.username` | String | -- | SASL 鉴权用户名 |
| `wal.sasl.password` | String | -- | SASL 鉴权密码 |
| `wal.tls` | String | -- | Kafka 客户端 TLS 配置 |
| `wal.tls.server_ca_cert_path` | String | -- | 服务器 CA 证书地址 |
| `wal.tls.client_cert_path` | String | -- | 客户端证书地址(用于启用 mTLS) |
| `wal.tls.client_key_path` | String | -- | 客户端密钥地址(用于启用 mTLS) |
### 仅限于 `Datanode` 的配置
```toml
node_id = 42
[grpc]
bind_addr = "127.0.0.1:3001"
server_addr = "127.0.0.1:3001"
runtime_size = 8
```
| Key | Type | Description |
| ---------------- | ------ | ------------------------------------------- |
| node_id | 整数 | 该 `datanode` 的唯一标识符。 |
| grpc.bind_addr | 字符串 | gRPC 服务绑定地址,默认为`"127.0.0.1:3001"`。 |
| grpc.server_addr | 字符串 | 该地址用于来自主机外部的连接和通信。如果留空或未设置,服务器将自动使用主机上第一个网络接口的 IP 地址,其端口号与 `grpc.bind_addr` 中指定的相同。 |
| grpc.rpc_runtime_size | 整数 | gRPC 服务器工作线程数,默认为 8。 |
### 仅限于 `Frontend` 的配置
```toml
[datanode]
[datanode.client]
connect_timeout = "1s"
tcp_nodelay = true
```
| Key | Type | Default | Description |
|-----------------------------------|------|---------|-------------------------|
| `datanode` | -- | -- | |
| `datanode.client` | -- | -- | Datanode 客户端选项。 |
| `datanode.client.connect_timeout` | 字符串 | `1s` | 连接服务器超时。 |
| `datanode.client.tcp_nodelay` | 布尔值 | `true` | 接受连接的 `TCP_NODELAY` 选项。 |
---
## 常见 Helm Chart 配置项
对于每一个 Helm Chart,你都可以通过创建 `values.yaml` 来进行配置。当你需要应用配置时,你可以通过 `helm upgrade` 命令来应用配置:
```
helm upgrade --install ${release-name} ${chart-name} --namespace ${namespace} -f values.yaml
```
## GreptimeDB Cluster Chart
完整的配置项可参考 [GreptimeDB Cluster Chart](https://github.com/GreptimeTeam/helm-charts/tree/main/charts/greptimedb-cluster/README.md)。
### GreptimeDB 运行镜像配置
顶层变量 `image` 用于配置集群全局的运行镜像,如下所示:
```yaml
image:
# -- The image registry
registry: greptime-registry.cn-hangzhou.cr.aliyuncs.com
# -- The image repository
repository: greptime/greptimedb
# -- The image tag
tag: "v1.0.2"
# -- The image pull secrets
pullSecrets: []
```
如果你想为集群中的每个 Role 配置不同的镜像,可以使用 `${role}.podTemplate.main.image` 字段(其中 `role` 可以是 `meta`、`frontend`、`datanode` 和 `flownode`),该字段会**覆盖顶层**变量 `image` 的配置,如下所示:
```yaml
image:
# -- The image registry
registry: greptime-registry.cn-hangzhou.cr.aliyuncs.com
# -- The image repository
repository: greptime/greptimedb
# -- The image tag
tag: "v1.0.2"
# -- The image pull secrets
pullSecrets: []
frontend:
podTemplate:
main:
image: "greptime-registry.cn-hangzhou.cr.aliyuncs.com/greptime/greptimedb:latest"
```
此时 `frontend` 的镜像将会被设置为 `greptime-registry.cn-hangzhou.cr.aliyuncs.com/greptime/greptimedb:latest`,而其他组件的镜像将会使用顶层变量 `image` 的配置。
### 服务端口配置
你可以使用如下字段来配置服务端口,如下所示:
- `httpServicePort`:用于配置 HTTP 服务的端口,默认 4000;
- `grpcServicePort`:用于配置 gRPC 服务的端口,默认 4001;
- `mysqlServicePort`:用于配置 MySQL 服务的端口,默认 4002;
- `postgresServicePort`:用于配置 PostgreSQL 服务的端口,默认 4003;
- `frontend.internalPort`:用于配置内部服务的端口,默认 4010,此端口用于 GreptimeDB 组件之间的内部通信。
### Datanode 存储配置
你可以通过 `datanode.storage` 字段来配置 Datanode 的存储,如下所示:
```yaml
datanode:
storage:
# -- Storage class for datanode persistent volume
storageClassName: null
# -- Storage size for datanode persistent volume
storageSize: 20Gi
# -- Storage retain policy for datanode persistent volume
storageRetainPolicy: Retain
# -- The dataHome directory, default is "/data/greptimedb/"
dataHome: "/data/greptimedb"
```
- `storageClassName`:用于配置 StorageClass,默认使用 Kubernetes 当前默认的 StorageClass;
- `storageSize`:用于配置 Storage 的大小,默认 20Gi。你可以使用常用的容量单位,如 `50Gi` 等;
- `storageRetainPolicy`:用于配置 Storage 的保留策略,默认 `Retain`,如果设置为 `Delete`,则当集群被删除时,相应的 Storage 也会被删除;
- `dataHome`:用于配置数据目录,默认 `/data/greptimedb/`;
### 运行资源配置
顶层变量 `base.podTemplate.main.resources` 用于全局配置每个 Role 的资源,如下所示:
```yaml
base:
podTemplate:
main:
resources:
requests:
memory: "1Gi"
cpu: "1"
limits:
memory: "2Gi"
cpu: "2"
```
如果你想为集群中的每个 Role 配置不同的资源,可以使用 `${role}.podTemplate.main.resources` 字段(其中 `role` 可以是 `meta`、`frontend`、`datanode`、`flownode` 等),该字段会**覆盖顶层**变量 `base.podTemplate.main.resources` 的配置,如下所示:
```yaml
base:
podTemplate:
main:
resources:
requests:
memory: "1Gi"
cpu: "1"
limits:
memory: "2Gi"
cpu: "2"
frontend:
podTemplate:
main:
resources:
requests:
cpu: "2"
memory: "4Gi"
limits:
cpu: "4"
memory: "8Gi"
```
### 服务运行副本数配置
对于不同 Role 的副本数,可以通过 `${role}.replicas` 字段进行配置对应的副本数,如下所示:
```yaml
frontend:
replicas: 3
datanode:
replicas: 3
```
你可以通过配置其副本数来实现水平扩缩。
### 环境变量配置
你既可以通过 `base.podTemplate.main.env` 字段配置全局的环境变量,也可以通过 `${role}.podTemplate.main.env` 字段为每个 Role 配置不同的环境变量,如下所示:
```yaml
base:
podTemplate:
main:
env:
- name: GLOBAL_ENV
value: "global_value"
frontend:
podTemplate:
main:
env:
- name: FRONTEND_ENV
value: "frontend_value"
```
### 注入配置文件
对于不同 Role 的服务,你可以通过 `${role}.configData` 字段注入自定义的 TOML 配置文件,如下所示:
```yaml
datanode:
configData: |
[[region_engine]]
[region_engine.mito]
# Number of region workers
num_workers = 8
```
你可以通过 [config.md](https://github.com/GreptimeTeam/greptimedb/blob/main/config/config.md) 了解 GreptimeDB 的配置项。
除了使用 `${role}.configData` 字段注入配置文件,你还可以通过 `${role}.configFile` 来指定相应的文件,如下所示:
```yaml
frontend:
configFile: "configs/frontend.toml"
```
此时需要确保对应的配置文件路径与执行 `helm upgrade` 命令时所处的目录一致。
:::note
用户注入的配置文件默认优先级低于由 GreptimeDB Operator 所接管的配置项,某些配置项仅能通过 GreptimeDB Operator 进行配置,而这些配置项默认会暴露在 `values.yaml` 中。
如下默认配置将由 GreptimeDB Operator 管理:
- Logging 配置;
- Datanode 的 Node ID;
:::
### 鉴权配置
Helm Chart 默认不启用 User Provider 模式的鉴权,你可以通过 `auth.enabled` 字段启用 User Provider 模式的鉴权并配置相应的用户信息,如下所示:
```yaml
auth:
enabled: true
users:
- username: "admin"
password: "admin"
permission: "readwrite"
- username: "grafana"
password: "grafana_pwd"
permission: "readonly"
- username: "telegraf"
password: "telegraf_pwd"
permission: "writeonly"
```
GreptimeDB 支持三种权限模式:
| 模式 | 缩写 | 允许的操作 | 典型场景 |
|------|------|-----------|---------|
| `readwrite` | `rw` | 读取 + 写入 | 管理员、开发环境 |
| `readonly` | `ro` | 仅读取 | 仪表盘、报表系统、只读副本 |
| `writeonly` | `wo` | 仅写入 | 数据采集器、IoT 设备、日志收集 |
:::note
未指定权限模式的用户默认拥有 `readwrite` 权限,与此前版本行为一致。
### 日志配置
顶层变量 `logging` 用于配置全局日志级别,如下所示:
```yaml
# -- Global logging configuration
logging:
# -- The log level for greptimedb, only support "debug", "info", "warn", "debug"
level: "info"
# -- The log format for greptimedb, only support "json" and "text"
format: "text"
# -- The logs directory for greptimedb
logsDir: "/data/greptimedb/logs"
# -- Whether to log to stdout only
onlyLogToStdout: false
# -- indicates whether to persist the log with the datanode data storage. It **ONLY** works for the datanode component.
persistentWithData: false
# -- The log filters, use the syntax of `target[span\{field=value\}]=level` to filter the logs.
filters: []
```
其中:
- `logging.level`:用于配置全局日志级别,支持 `debug`、`info`、`warn`、`error` 四个级别;
- `logging.format`:用于配置全局日志格式,支持 `json` 和 `text` 两种格式;
- `logging.logsDir`:用于配置全局日志目录,默认位于 `/data/greptimedb/logs`;
- `logging.onlyLogToStdout`:用于配置是否仅输出到标准输出,默认不启用;
- `logging.persistentWithData`:用于配置是否将日志持久化到数据存储,仅适用于 `datanode` 组件,默认不启用;
- `logging.filters`:用于配置全局日志过滤器,支持 `target[span\{field=value\}]=level` 的语法,特步地,如果你希望对某些组件启动 `debug` 级别的日志,可以配置如下:
```yaml
logging:
level: "info"
format: "json"
filters:
- mito2=debug
```
每一个 Role 的日志配置都可以通过 `${role}.logging` 字段进行配置,其字段与顶层 `logging` 一致,并会**覆盖**顶层变量 `logging` 的配置,比如:
```yaml
frontend:
logging:
level: "debug"
```
### 启用 Flownode
Helm Chart 默认不启用 Flownode,你可以通过 `flownode.enabled` 字段启用 Flownode,如下所示:
```yaml
flownode:
enabled: true
```
`flownode` 的其他字段的配置与其他 Role 的配置一致,比如:
```yaml
flownode:
enabled: true
replicas: 1
podTemplate:
main:
resources:
requests:
memory: "1Gi"
cpu: "1"
limits:
memory: "2Gi"
cpu: "2"
```
### 对象存储配置
`objectStorage` 字段用于配置云对象存储(例如 AWS S3 和 Azure Blob Storage 等)作为 GreptimeDB 存储层。
#### AWS S3
```yaml
objectStorage:
credentials:
# AWS access key ID
accessKeyId: ""
# AWS secret access key
secretAccessKey: ""
s3:
# AWS S3 bucket name
bucket: ""
# AWS S3 region
region: ""
# The root path in bucket is 's3:////data/...'
root: ""
# The AWS S3 endpoint, see more detail: https://docs.aws.amazon.com/general/latest/gr/s3.html
endpoint: ""
```
#### 使用 AWS EKS Pod Identity 访问 S3
除了提供静态访问密钥外,你还可以使用 [AWS EKS Pod Identity](https://docs.aws.amazon.com/eks/latest/userguide/pod-identities.html)(IAM Roles for Service Accounts)来授予 GreptimeDB 访问 S3 的权限。这种方式更加安全,因为无需管理长期有效的凭证。
首先,为 datanode 的 Service Account 配置 IAM 角色注解。只有 datanode 会读写 S3:
```yaml
datanode:
podTemplate:
serviceAccount:
create: true
annotations:
eks.amazonaws.com/role-arn: ${YOUR_IAM_ROLE_ARN}
```
请确保 IAM 角色具有对目标 S3 存储桶的读写权限:
- `s3:PutObject`
- `s3:ListBucket`
- `s3:GetObject`
- `s3:DeleteObject`
然后,配置对象存储时无需填写凭证:
```yaml
objectStorage:
s3:
bucket: "${YOUR_S3_BUCKET}"
region: "${YOUR_S3_REGION}"
root: "greptimedb"
```
:::note
使用 EKS Pod Identity 时,请完全省略 `objectStorage.credentials` 部分。datanode Pod 将通过与 Service Account 关联的 IAM 角色自动获取临时凭证。
:::
#### Google Cloud Storage
```yaml
objectStorage:
credentials:
# GCP serviceAccountKey JSON-formatted base64 value
serviceAccountKey: ""
gcs:
# Google Cloud Storage bucket name
bucket: ""
# Google Cloud OAuth 2.0 Scopes, example: "https://www.googleapis.com/auth/devstorage.read_write"
scope: ""
# The root path in bucket is 'gcs:////data/...'
root: ""
# Google Cloud Storage endpoint, example: "https://storage.googleapis.com"
endpoint: ""
```
#### Azure Blob
```yaml
objectStorage:
credentials:
# Azure account name
accountName: ""
# Azure account key
accountKey: ""
azblob:
# Azure Blob container name
container: ""
# The root path in container is 'blob:////data/...'
root: ""
# Azure Blob endpoint, see: "https://learn.microsoft.com/en-us/azure/storage/blobs/storage-blob-query-endpoint-srp?tabs=dotnet#query-for-the-blob-storage-endpoint"
endpoint: ""
```
#### AliCloud OSS
```yaml
objectStorage:
credentials:
# AliCloud access key ID
accessKeyId: ""
# AliCloud access key secret
accessKeySecret: ""
oss:
# AliCloud OSS bucket name
bucket: ""
# AliCloud OSS region
region: ""
# The root path in bucket is 'oss:////data/...'
root: ""
# The AliCloud OSS endpoint
endpoint: ""
```
#### Volcengine TOS
TOS ([Torch Object Storage](https://www.volcengine.com/docs/6349)) 是[火山引擎](https://www.volcengine.com)提供的海量、安全、低成本、易用、高可靠、高可用的对象存储服务。
```yaml
objectStorage:
credentials:
# Volcengine access key ID
accessKeyId: ""
# Volcengine secret access key
secretAccessKey: ""
s3:
# Volcengine TOS bucket name
bucket: ""
# Volcengine TOS region
region: ""
# The root path in bucket is 'tos:////data/...'
root: ""
# The Volcengine TOS endpoint, see more detail: https://www.volcengine.com/docs/6349/107356
endpoint: ""
# Enable virtual host style so that OpenDAL will send API requests in virtual host style instead of path style.
enableVirtualHostStyle: true
```
### Prometheus 监控配置
如果你已经安装了 [prometheus-operator](https://github.com/prometheus-operator/prometheus-operator),你可以通过 `prometheusMonitor.enabled` 字段创建 Prometheus PodMonitor 来监控 GreptimeDB,如下所示:
```yaml
prometheusMonitor:
# -- Create PodMonitor resource for scraping metrics using PrometheusOperator
enabled: false
# -- Interval at which metrics should be scraped
interval: "30s"
# -- Add labels to the PodMonitor
labels:
release: prometheus
```
### Debug Pod 配置
debug pod 中安装了各种工具(例如 mysql-client、psql-client 等)。你可以 exec 进入调试 debug pod 进行调试。使用 `debugPod.enabled` 字段创建它,如下所示:
```yaml
debugPod:
# -- Enable debug pod
enabled: false
# -- The debug pod image
image:
registry: docker.io
repository: greptime/greptime-tool
tag: "20250606-04e3c7d"
# -- The debug pod resource
resources:
requests:
memory: 64Mi
cpu: 50m
limits:
memory: 256Mi
cpu: 200m
```
### 配置 Metasrv 后端存储
#### 使用 MySQL 和 PostgreSQL 作为后端存储
你可以通过 `meta.backendStorage` 字段配置 Metasrv 的后端存储。
以 MySQL 为例。
```yaml
meta:
backendStorage:
mysql:
# -- MySQL host
host: "mysql.default.svc.cluster.local"
# -- MySQL port
port: 3306
# -- MySQL database
database: "metasrv"
# -- MySQL table
table: "greptime_metakv"
# -- MySQL credentials
credentials:
# -- MySQL credentials secret name
secretName: "meta-mysql-credentials"
# -- MySQL credentials existing secret name
existingSecretName: ""
# -- MySQL credentials username
username: "root"
# -- MySQL credentials password
password: "test"
```
- `mysql.host`: MySQL 主机。
- `mysql.port`: MySQL 端口。
- `mysql.database`: MySQL 数据库。
- `mysql.table`: MySQL 表。
- `mysql.credentials.secretName`: MySQL 凭证 secret 名称。
- `mysql.credentials.existingSecretName`: MySQL 凭证 secret 名称。如果你希望使用已有的 secret,你需要确保该 secret 包含 `username` 和 `password` 两个 key。
- `mysql.credentials.username`: MySQL 凭证用户名。如果 `mysql.credentials.existingSecretName` 被设置,该字段将被忽略。`username` 将会被存储在 `username` key 中,该 key 的值为 `mysql.credentials.secretName`。
- `mysql.credentials.password`: MySQL 凭证密码。如果 `mysql.credentials.existingSecretName` 被设置,该字段将被忽略。`password` 将会被存储在 `password` key 中,该 key 的值为 `mysql.credentials.secretName`。
`meta.backendStorage.postgresql` 的大部分字段与 `meta.backendStorage.mysql` 的相同。例如:
```yaml
meta:
backendStorage:
postgresql:
# -- PostgreSQL host
host: "postgres.default.svc.cluster.local"
# -- PostgreSQL port
port: 5432
# -- PostgreSQL database
database: "metasrv"
# -- PostgreSQL table
table: "greptime_metakv"
# -- PostgreSQL Advisory lock id used for election, shouldn't be used in other clusters or applications.
electionLockID: 1
# -- PostgreSQL credentials
credentials:
# -- PostgreSQL credentials secret name
secretName: "meta-postgresql-credentials"
# -- PostgreSQL credentials existing secret name
existingSecretName: ""
# -- PostgreSQL credentials username
username: "root"
# -- PostgreSQL credentials password
password: "root"
```
- `postgresql.host`: PostgreSQL 主机。
- `postgresql.port`: PostgreSQL 端口。
- `postgresql.database`: PostgreSQL 数据库。
- `postgresql.table`: PostgreSQL 表。
- `postgresql.electionLockID`: PostgreSQL 中用于选举的锁 ID。
- `postgresql.credentials.secretName`: PostgreSQL 凭证 secret 名称。
- `postgresql.credentials.existingSecretName`: PostgreSQL 凭证 secret 名称。如果你希望使用已有的 secret,你需要确保该 secret 包含 `username` 和 `password` 两个 key。
- `postgresql.credentials.username`: PostgreSQL 凭证用户名。如果 `mysql.credentials.existingSecretName` 被设置,该字段将被忽略。`username` 将会被存储在 `username` key 中,该 key 的值为 `mysql.credentials.secretName`。
- `postgresql.credentials.password`: PostgreSQL 凭证密码。如果 `mysql.credentials.existingSecretName` 被设置,该字段将被忽略。`password` 将会被存储在 `password` key 中,该 key 的值为 `mysql.credentials.secretName`。
#### 使用 etcd 作为后端存储
:::tip NOTE
chart 版本之间的配置结构已发生变化:
- 旧版本: `meta.etcdEndpoints`
- 新版本: `meta.backendStorage.etcd.endpoints`
请参考 chart 仓库中配置 [values.yaml](https://github.com/GreptimeTeam/helm-charts/blob/main/charts/greptimedb-cluster/values.yaml) 以获取最新的结构。
:::
你可以通过 `meta.backendStorage.etcd` 字段配置 etcd 作为后端存储。
```yaml
meta:
backendStorage:
etcd:
# -- Etcd endpoints
endpoints: ["etcd.etcd-cluster.svc.cluster.local:2379"]
# -- Etcd store key prefix
storeKeyPrefix: ""
```
- `etcd.endpoints`: etcd 服务地址。
- `etcd.storeKeyPrefix`: etcd 存储 key 前缀。所有 key 都会被存储在这个前缀下。如果你希望使用一个 etcd 集群为多个 GreptimeDB 集群提供服务,你可以为每个 GreptimeDB 集群配置不同的存储 key 前缀。这仅用于测试和调试目的。
### 启用 Region Failover
你可以通过 `meta.enableRegionFailover` 字段启用 Region Failover。在启用 Region Failover 之前,请确保你的部署满足 [Region Failover](/user-guide/deployments-administration/manage-data/region-failover.md) 文档中的先决条件。如果你的配置不满足条件,**Operator 将无法部署集群组件**。
```yaml
meta:
enableRegionFailover: true
```
### 启用 IPv6
通过 `enableIPv6` 字段可开启 IPv6 网络协议支持。设置为 true 时,系统将启用 IPv6 地址分配与通信功能,默认为 false(不启用)。启用前请确保底层基础环境已配置支持 IPv6 网络。
```yaml
enableIPv6: true
```
### 启用 GC
重分区依赖共享对象存储和 GC。你可以通过下面的示例同时开启 metasrv 和 datanode 的 GC:
```yaml
meta:
configData: |
[gc]
enable = true
gc_cooldown_period = "5m"
datanode:
configData: |
[[region_engine]]
[region_engine.mito]
[region_engine.mito.gc]
enable = true
lingering_time = "10m"
unknown_file_lingering_time = "1h"
```
请确保 `datanode` 的 `lingering_time` 大于 `meta` 的 `gc_cooldown_period`,以避免正在使用的文件过早被删除。
#### 启用 Region Failover 在本地 WAL
在本地 WAL 上启用 Region Failover,你需要设置 `meta.enableRegionFailover: true` 和在 `meta.configData` 字段中添加 `allow_region_failover_on_local_wal = true`。
:::warning WARNING
在本地 WAL 启用 Region Failover 可能会导致数据丢失。另外,确保你的 Operator 版本大于或等于 v0.2.2。
:::
```yaml
meta:
enableRegionFailover: true
configData: |
allow_region_failover_on_local_wal = true
```
### 专用 WAL 卷
配置专用 WAL 卷时,可以为 GreptimeDB Datanode 的 WAL(预写日志)目录使用单独的磁盘,并指定自定义的 `StorageClass`。
```yaml
dedicatedWAL:
enabled: true
raftEngine:
fs:
storageClassName: io2 # 使用 AWS ebs io2 存储以获得更好的性能
name: wal
storageSize: 20Gi
mountPath: /wal
```
### 启用 Remote WAL
在启用前,请务必查阅 [Remote WAL 配置](/user-guide/deployments-administration/wal/remote-wal/configuration.md)文档,以了解完整的配置项说明及相关注意事项。
```yaml
remoteWal:
enabled: true
kafka:
brokerEndpoints: ["kafka.kafka-cluster.svc:9092"]
meta:
configData: |
[wal]
provider = "kafka"
replication_factor = 1
auto_prune_interval = "30m"
datanode:
configData: |
[wal]
provider = "kafka"
overwrite_entry_start_id = true
```
---
## 部署多个具有 frontend 组的 GreptimeDB 集群
在本指南中,你将学习如何在 Kubernetes 上部署具有多个 frontend 组的 GreptimeDB 集群。
## 先决条件
- [Docker](https://docs.docker.com/get-started/get-docker/) >= v23.0.0
- [kubectl](https://kubernetes.io/docs/tasks/tools/install-kubectl/) >= v1.18.0
- [Helm](https://helm.sh/docs/intro/install/) >= v3.0.0
- [GreptimeDB Operator](https://github.com/GrepTimeTeam/greptimedb-operator) >= v0.3.0
- [ETCD](https://github.com/bitnami/charts/tree/main/bitnami/etcd)
## 升级 operator
安装 GreptimeDB Operator,将镜像版本设置为大于或等于 `v0.3.0`。
请参考 GreptimeDB Operator 文档查看[如何升级 Operator](/user-guide/deployments-administration/deploy-on-kubernetes/greptimedb-operator-management.md#升级)。
## Frontend 组配置
:::tip NOTE
chart 版本之间的配置结构已发生变化:
- 旧版本: `meta.etcdEndpoints`
- 新版本: `meta.backendStorage.etcd.endpoints`
请参考 chart 仓库中配置 [values.yaml](https://github.com/GreptimeTeam/helm-charts/blob/main/charts/greptimedb-cluster/values.yaml) 以获取最新的结构。
:::
在配置 frontend 组时,确保每个组都包含 `name` 字段。以下 `values.yaml` 示例展示了如何为读写操作分别定义不同的 frontend 组:
```yaml
frontend:
enabled: false # 禁用默认 frontend 组
frontendGroups:
- name: read
replicas: 1
config: |
default_timezone = "UTC"
[http]
timeout = "60s"
template:
main:
resources:
limits:
cpu: 2000m
memory: 2048Mi
- name: write
replicas: 1
meta:
replicas: 1
backendStorage:
etcd:
endpoints:
- "etcd.etcd-cluster.svc.cluster.local:2379"
datanode:
replicas: 1
```
你可以使用以下命令应用上述配置:
```
helm upgrade --install greptimedb greptime/greptimedb-cluster --namespace default -f values.yaml
```
## 合规配置
设置 frontend 组时,必须设置名称。
```yaml
# 非法配置 !!!
frontendGroups:
# - name: read #<=========必须指定该字段=============>
- replicas: 1
```
## 校验安装
检查 Pod 的状态:
```bash
kubectl get pods -n default
NAME READY STATUS RESTARTS AGE
greptimedb-datanode-0 1/1 Running 0 32s
greptimedb-flownode-0 1/1 Running 0 17s
greptimedb-frontend-read-6d45bc9b89-hftqz 1/1 Running 0 23s
greptimedb-frontend-write-557b6585c6-jq874 1/1 Running 0 23s
greptimedb-meta-58cd4cff6c-zp7s9 1/1 Running 0 37s
```
检查 services 状态:
```bash
kubectl get service -n default
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
greptimedb-datanode ClusterIP None 4001/TCP,4000/TCP 102s
greptimedb-flownode ClusterIP None 4001/TCP 2m5s
greptimedb-frontend-read ClusterIP 10.96.174.200 4001/TCP,4000/TCP,4002/TCP,4003/TCP 42s
greptimedb-frontend-write ClusterIP 10.96.223.1 4001/TCP,4000/TCP,4002/TCP,4003/TCP 42s
greptimedb-meta ClusterIP 10.96.195.163 3002/TCP,4000/TCP 3m4s
```
## Conclusion
您已成功部署 GreptimeDB 集群,其 frontend 组由读写实例组成。您现在可以继续探索 GreptimeDB 集群的功能,或根据需要将其与其他工具集成。
---
## 部署启用 Remote WAL 的 GreptimeDB 集群
本指南将介绍如何在 Kubernetes 集群中部署启用了 Remote WAL(远程写前日志)的 GreptimeDB。在开始之前,建议先阅读 [部署 GreptimeDB 集群](/user-guide/deployments-administration/deploy-on-kubernetes/deploy-greptimedb-cluster.md) 文档。
## 前置条件
- [Docker](https://docs.docker.com/get-started/get-docker/) >= v23.0.0
- [kubectl](https://kubernetes.io/docs/tasks/tools/install-kubectl/) >= v1.18.0
- [Helm](https://helm.sh/docs/intro/install/) >= v3.0.0
## 所需依赖
在部署启用了 Remote WAL 的 GreptimeDB 之前,请确保元数据存储和 Kafka 集群已经部署完成,或者已准备好可用的实例:
- 元数据存储:请参考 [管理元数据概述](/user-guide/deployments-administration/manage-metadata/overview.md) 了解更多详情。在本示例中,我们使用 etcd 作为元数据存储。
- Kafka 集群:请参考 [管理 Kafka](/user-guide/deployments-administration/wal/remote-wal/manage-kafka.md) 了解更多详情。
## Remote WAL 配置
:::tip NOTE
chart 版本之间的配置结构已发生变化:
- 旧版本: `meta.etcdEndpoints`
- 新版本: `meta.backendStorage.etcd.endpoints`
请参考 chart 仓库中配置 [values.yaml](https://github.com/GreptimeTeam/helm-charts/blob/main/charts/greptimedb-cluster/values.yaml) 以获取最新的结构。
:::
本示例假设你已经部署了一个 Kafka 集群,运行在 `kafka-cluster` 命名空间中,并且一个 etcd 集群运行在 `etcd-cluster` 命名空间中。`values.yaml` 文件如下:
```yaml
meta:
backendStorage:
etcd:
endpoints: ["etcd.etcd-cluster.svc.cluster.local:2379"]
configData: |
[wal]
provider = "kafka"
replication_factor = 1
topic_name_prefix = "gtp_greptimedb_wal_topic"
auto_prune_interval = "30m"
datanode:
configData: |
[wal]
provider = "kafka"
overwrite_entry_start_id = true
remoteWal:
enabled: true
kafka:
brokerEndpoints: ["kafka.kafka-cluster.svc.cluster.local:9092"]
```
## 部署 GreptimeDB 集群
你可以使用以下命令部署 GreptimeDB 集群:
```bash
helm upgrade --install mycluster \
--values values.yaml \
greptime/greptimedb-cluster \
-n default
```
## 最佳实践
- **不要在已部署的集群中切换 WAL 存储类型**. 如果需要将 WAL 存储从本地更换为远程,必须 删除整个集群并重新部署,包括:
- 删除集群使用的所有 PersistentVolumeClaims(PVCs)
- 清空对象存储中的集群目录
- 删除或清理使用的元数据存储
- 建议先使用一个**最小可行部署**来验证集群是否运行正常,例如执行建表和插入数据等基本操作,确保数据库正常工作。
## 后续步骤
- 请参考 [部署 GreptimeDB 集群](/user-guide/deployments-administration/deploy-on-kubernetes/deploy-greptimedb-cluster.md) 指南访问你的 GreptimeDB 集群。
- 请参考 [快速开始](/getting-started/quick-start.md) 指南创建表并写入数据。
- 请参考 [Remote WAL 配置](/user-guide/deployments-administration/wal/remote-wal/configuration.md) 了解更多关于 Remote WAL 配置的信息。
---
## 部署 GreptimeDB 集群
在该指南中,你将学会如何使用 GreptimeDB Operator 在 Kubernetes 上部署 GreptimeDB 集群。
:::note
以下输出可能会因 Helm chart 版本和具体环境的不同而有细微差别。
:::
## 前置条件
- [Docker](https://docs.docker.com/get-started/get-docker/) >= v23.0.0
- [kubectl](https://kubernetes.io/docs/tasks/tools/install-kubectl/) >= v1.18.0
- [Helm](https://helm.sh/docs/intro/install/) >= v3.0.0
- [kind](https://kind.sigs.k8s.io/docs/user/quick-start/) >= v0.20.0
## 创建一个测试 Kubernetes 集群
:::warning
不建议在生产环境或性能测试中使用 `kind`。如有这类需求建议使用公有云托管的 Kubernetes 服务,如 [Amazon EKS](https://aws.amazon.com/eks/)、[Google GKE](https://cloud.google.com/kubernetes-engine/) 或 [Azure AKS](https://azure.microsoft.com/en-us/services/kubernetes-service/),或者自行搭建生产级 Kubernetes 集群。
:::
目前有很多方法可以创建一个用于测试的 Kubernetes 集群。在本指南中,我们将使用 [kind](https://kind.sigs.k8s.io/docs/user/quick-start/) 来创建一个本地 Kubernetes 集群。如果你想使用已有的 Kubernetes 集群,可以跳过这一步。
这里是一个使用 `kind` v0.20.0 的示例:
```bash
kind create cluster
```
预期输出
```bash
Creating cluster "kind" ...
✓ Ensuring node image (kindest/node:v1.27.3) 🖼
✓ Preparing nodes 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
Set kubectl context to "kind-kind"
You can now use your cluster with:
kubectl cluster-info --context kind-kind
Thanks for using kind! 😊
```
使用以下命令检查集群的状态:
```bash
kubectl cluster-info
```
预期输出
```bash
Kubernetes control plane is running at https://127.0.0.1:60495
CoreDNS is running at https://127.0.0.1:60495/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
```
:::note
中国大陆用户如有网络访问问题,可使用 Greptime 提供的位于阿里云镜像仓库的 `kindest/node:v1.27.3` 镜像:
```bash
kind create cluster --image greptime-registry.cn-hangzhou.cr.aliyuncs.com/kindest/node:v1.27.3
```
:::
## 添加 Greptime Helm 仓库
:::note
中国大陆用户如有网络访问问题,可跳过这一步骤并直接参考下一步中使用阿里云 OCI 镜像仓库的方式。采用这一方式将无需手动添加 Helm 仓库。
:::
我们提供了 GreptimeDB Operator 和 GreptimeDB 集群的[官方 Helm 仓库](https://github.com/GreptimeTeam/helm-charts)。你可以通过运行以下命令来添加仓库:
```bash
helm repo add greptime https://greptimeteam.github.io/helm-charts/
helm repo update
```
检查 Greptime Helm 仓库中的 charts:
```bash
helm search repo greptime
```
预期输出
```bash
NAME CHART VERSION APP VERSION DESCRIPTION
greptime/greptimedb-cluster 0.8.3 1.0.1 A Helm chart for deploying GreptimeDB cluster i...
greptime/greptimedb-enterprise-dashboard 0.1.0 0.1.0 The Helm chart for deploying GreptimeDB Enterpr...
greptime/greptimedb-infra-test 0.1.0 0.1.0 The Helm chart for deploying GreptimeDB infra t...
greptime/greptimedb-operator 0.5.9 0.5.5 The greptimedb-operator Helm chart for Kubernetes.
greptime/greptimedb-remote-compaction 0.1.1 0.1.0 Remote compaction components (scheduler, compac...
greptime/greptimedb-standalone 0.4.2 1.0.1 A Helm chart for deploying standalone greptimedb
```
## 安装和验证 GreptimeDB Operator
现在我们准备使用 Helm 在 Kubernetes 集群上安装 GreptimeDB Operator。
### 安装 GreptimeDB Operator
[GreptimeDB Operator](https://github.com/GrepTimeTeam/greptimedb-operator) 是一个用于管理 GreptimeDB 集群生命周期的 Kubernetes operator。
让我们在 `greptimedb-admin` 命名空间中安装最新版本的 GreptimeDB Operator:
```bash
helm install greptimedb-operator greptime/greptimedb-operator -n greptimedb-admin --create-namespace
```
预期输出
```bash
NAME: greptimedb-operator
LAST DEPLOYED: Sun Apr 26 20:43:58 2026
NAMESPACE: greptimedb-admin
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
***********************************************************************
Welcome to use greptimedb-operator
Chart version: 0.5.9
GreptimeDB Operator version: 0.5.5
***********************************************************************
Installed components:
* greptimedb-operator
The greptimedb-operator is starting, use `kubectl get deployment greptimedb-operator -n greptimedb-admin` to check its status.
```
:::note
中国大陆用户如有网络访问问题,可直接使用阿里云 OCI 镜像仓库的方式安装 GreptimeDB Operator:
```bash
helm install greptimedb-operator \
oci://greptime-registry.cn-hangzhou.cr.aliyuncs.com/charts/greptimedb-operator \
--set image.registry=greptime-registry.cn-hangzhou.cr.aliyuncs.com \
-n greptimedb-admin \
--create-namespace
```
此时我们也将镜像仓库设置为 Greptime 官方的阿里云镜像仓库。
:::
:::note
我们还可以直接使用 `kubectl` 和 `bundle.yaml` 来安装最新版本的 GreptimeDB Operator:
```bash
kubectl apply -f \
https://github.com/GreptimeTeam/greptimedb-operator/releases/latest/download/bundle.yaml \
--server-side
```
这种方式仅适用于在测试环境快速部署 GreptimeDB Operator,不建议在生产环境中使用。
:::
### 验证 GreptimeDB Operator 安装
检查 GreptimeDB Operator 的状态:
```bash
kubectl get pods -n greptimedb-admin -l app.kubernetes.io/instance=greptimedb-operator
```
预期输出
```bash
NAME READY STATUS RESTARTS AGE
greptimedb-operator-68d684c6cf-qr4q4 1/1 Running 0 4m8s
```
你也可以检查 CRD 的安装:
```bash
kubectl get crds | grep greptimedb
```
预期输出
```bash
greptimedbclusters.greptime.io 2026-04-26T12:43:58Z
greptimedbstandalones.greptime.io 2026-04-26T12:43:58Z
```
GreptimeDB Operator 将会使用 `greptimedbclusters.greptime.io` and `greptimedbstandalones.greptime.io` 这两个 CRD 来管理 GreptimeDB 集群和单机实例。
## 安装 etcd 集群
GreptimeDB 集群需要一个 etcd 集群来存储元数据。让我们使用 Bitnami 的 etcd Helm [chart](https://github.com/bitnami/charts/tree/main/bitnami/etcd) 来安装一个 etcd 集群。
```bash
helm install etcd \
oci://registry-1.docker.io/bitnamicharts/etcd \
--version 12.0.8 \
--set replicaCount=3 \
--set auth.rbac.create=false \
--set auth.rbac.token.enabled=false \
--create-namespace \
--set global.security.allowInsecureImages=true \
--set image.registry=docker.io \
--set image.repository=greptime/etcd \
--set image.tag=3.6.1-debian-12-r3 \
-n etcd-cluster
```
预期输出
```bash
NAME: etcd
LAST DEPLOYED: Sun Apr 26 20:49:03 2026
NAMESPACE: etcd-cluster
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: etcd
CHART VERSION: 12.0.8
APP VERSION: 3.6.1
** Please be patient while the chart is being deployed **
etcd can be accessed via port 2379 on the following DNS name from within your cluster:
etcd.etcd-cluster.svc.cluster.local
To create a pod that you can use as a etcd client run the following command:
kubectl run etcd-client --restart='Never' --image docker.io/greptime/etcd:3.6.1-debian-12-r3 --env ETCDCTL_ENDPOINTS="etcd.etcd-cluster.svc.cluster.local:2379" --namespace etcd-cluster --command -- sleep infinity
Then, you can set/get a key using the commands below:
kubectl exec --namespace etcd-cluster -it etcd-client -- bash
etcdctl put /message Hello
etcdctl get /message
To connect to your etcd server from outside the cluster execute the following commands:
kubectl port-forward --namespace etcd-cluster svc/etcd 2379:2379 &
echo "etcd URL: http://127.0.0.1:2379"
WARNING: There are "resources" sections in the chart not set. Using "resourcesPreset" is not recommended for production. For production installations, please set the following values according to your workload needs:
- resources
- preUpgradeJob.resources
- disasterRecovery.cronjob.resources
+info https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/
Substituted images detected:
- docker.io/greptime/etcd:3.6.1-debian-12-r3
```
当 etcd 集群准备好后,你可以使用以下命令检查 Pod 的状态:
```bash
kubectl get pods -n etcd-cluster -l app.kubernetes.io/instance=etcd
```
预期输出
```bash
NAME READY STATUS RESTARTS AGE
etcd-0 1/1 Running 0 2m8s
etcd-1 1/1 Running 0 2m8s
etcd-2 1/1 Running 0 2m8s
```
:::note
中国大陆用户如有网络访问问题,可直接使用阿里云 OCI 镜像仓库的方式安装 etcd 集群:
```bash
helm install etcd \
oci://greptime-registry.cn-hangzhou.cr.aliyuncs.com/charts/etcd \
--set image.registry=greptime-registry.cn-hangzhou.cr.aliyuncs.com \
--set global.security.allowInsecureImages=true \
--set image.repository=bitnami/etcd \
--set image.tag=3.6.1-debian-12-r3 \
--set replicaCount=3 \
--set auth.rbac.create=false \
--set auth.rbac.token.enabled=false \
--create-namespace \
-n etcd-cluster
```
:::
你可以通过运行以下命令来测试 etcd 集群:
```bash
kubectl -n etcd-cluster \
exec etcd-0 -- etcdctl endpoint health \
--endpoints=http://etcd-0.etcd-headless.etcd-cluster.svc.cluster.local:2379,http://etcd-1.etcd-headless.etcd-cluster.svc.cluster.local:2379,http://etcd-2.etcd-headless.etcd-cluster.svc.cluster.local:2379
```
预期输出
```bash
http://etcd-1.etcd-headless.etcd-cluster.svc.cluster.local:2379 is healthy: successfully committed proposal: took = 3.008575ms
http://etcd-0.etcd-headless.etcd-cluster.svc.cluster.local:2379 is healthy: successfully committed proposal: took = 3.136576ms
http://etcd-2.etcd-headless.etcd-cluster.svc.cluster.local:2379 is healthy: successfully committed proposal: took = 3.147702ms
```
## 配置 `values.yaml`
`values.yaml` 文件设置了 GreptimeDB 的一些参数和配置,是定义 helm chart 的关键。
例如一个最小规模 GreptimeDB 集群定义如下:
```yaml
image:
# 镜像仓库地址:
# OSS GreptimeDB 使用 `greptime-registry.cn-hangzhou.cr.aliyuncs.com`,
# Enterprise GreptimeDB 请咨询工作人员
registry:
# 镜像仓库:
# OSS GreptimeDB 使用 `greptime/greptimedb`,
# Enterprise GreptimeDB 请咨询工作人员
repository:
# 镜像标签:
# OSS GreptimeDB 使用数据库版本,例如 `v1.0.2`
# Enterprise GreptimeDB 请咨询工作人员
tag:
pullSecrets: []
initializer:
registry: greptime-registry.cn-hangzhou.cr.aliyuncs.com
repository: greptime/greptimedb-initializer
tag: "v0.6.0"
frontend:
replicas: 1
meta:
replicas: 1
backendStorage:
etcd:
endpoints: ["etcd.etcd-cluster.svc.cluster.local:2379"]
datanode:
replicas: 1
flownode:
replicas: 1
```
上述配置不适用于严肃的生产环境,请根据自己的需求调整配置。
可参考[配置文档](/user-guide/deployments-administration/deploy-on-kubernetes/common-helm-chart-configurations.md)获取完整的 `values.yaml` 的配置项。
## 安装 GreptimeDB 集群
在上述步骤中我们已经准备好了 GreptimeDB Operator,etcd 集群以及 GreptimeDB 集群相应的配置,
现在部署一个最小 GreptimeDB 集群:
```bash
helm upgrade --install mycluster \
greptime/greptimedb-cluster \
--values /path/to/values.yaml \
-n default
```
如果你使用了不同的集群名称和命名空间,请将 `mycluster` 和 `default` 替换为你的配置。
预期输出
```bash
Release "mycluster" does not exist. Installing it now.
NAME: mycluster
LAST DEPLOYED: Sun Apr 26 21:00:40 2026
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
***********************************************************************
Welcome to use greptimedb-cluster
Chart version: 0.8.3
GreptimeDB Cluster version: 1.0.1
***********************************************************************
Installed components:
* greptimedb-meta
* greptimedb-datanode
* greptimedb-frontend
* greptimedb-flownode
The greptimedb-cluster is starting, use `kubectl get pods -n default` to check its status.
```
当启动集群安装之后,我们可以用如下命令检查 GreptimeDB 集群的状态。若你使用了不同的集群名和命名空间,可将 `default` 和 `mycluster` 替换为你的配置:
```bash
kubectl -n default get greptimedbclusters.greptime.io mycluster
```
预期输出
```bash
NAME FRONTEND DATANODE META FLOWNODE PHASE VERSION AGE
mycluster 1 1 1 1 Running v1.0.1 111s
```
上面的命令将会显示 GreptimeDB 集群的状态。当 `PHASE` 为 `Running` 时,表示 GreptimeDB 集群已经成功启动。
你还可以检查 GreptimeDB 集群的 Pod 状态:
```bash
kubectl -n default get pods
```
预期输出
```bash
NAME READY STATUS RESTARTS AGE
mycluster-datanode-0 1/1 Running 0 2m51s
mycluster-flownode-0 1/1 Running 0 2m26s
mycluster-frontend-5894994974-w2cls 1/1 Running 0 2m32s
mycluster-meta-58cd4cff6c-ddbxq 1/1 Running 0 2m58s
```
正如你所看到的,我们默认创建了一个最小的 GreptimeDB 集群,包括 1 个 frontend、1 个 datanode、1 个 flownode 和 1 个 metasrv。关于一个完整的 GreptimeDB 集群的组成,你可以参考 [architecture](/user-guide/concepts/architecture.md)。
## 探索 GreptimeDB 集群
### 访问 GreptimeDB 集群
你可以通过使用 `kubectl port-forward` 命令转发 frontend 服务来访问 GreptimeDB 集群:
```bash
kubectl -n default port-forward svc/mycluster-frontend 4000:4000 4001:4001 4002:4002 4003:4003
```
预期输出
```bash
Forwarding from 127.0.0.1:4000 -> 4000
Forwarding from [::1]:4000 -> 4000
Forwarding from 127.0.0.1:4001 -> 4001
Forwarding from [::1]:4001 -> 4001
Forwarding from 127.0.0.1:4002 -> 4002
Forwarding from [::1]:4002 -> 4002
Forwarding from 127.0.0.1:4003 -> 4003
Forwarding from [::1]:4003 -> 4003
```
请注意,当你使用了其他集群名和命名空间时,你可以使用如下命令,并将 `${cluster}` 和 `${namespace}` 替换为你的配置:
```bash
kubectl -n ${namespace} port-forward svc/${cluster}-frontend 4000:4000 4001:4001 4002:4002 4003:4003
```
:::warning
如果你想将服务暴露给公网访问,可以使用带有 `--address` 选项的 `kubectl port-forward` 命令:
```bash
kubectl -n default port-forward --address 0.0.0.0 svc/mycluster-frontend 4000:4000 4001:4001 4002:4002 4003:4003
```
在将服务暴露给公网访问之前,请确保你已经配置了适当的安全设置。
:::
打开浏览器并访问 `http://localhost:4000/dashboard` 来访问 [GreptimeDB Dashboard](https://github.com/GrepTimeTeam/dashboard)。
如果你想使用其他工具如 `mysql` 或 `psql` 来连接 GreptimeDB 集群,你可以参考 [快速入门](/getting-started/quick-start.md)。
## 删除集群
:::danger
清理操作将会删除 GreptimeDB 集群的元数据和数据。请确保在继续操作之前已经备份了数据。
:::
### 停止端口转发
可以使用以下命令停止 GreptimeDB 集群的端口转发:
```bash
pkill -f kubectl port-forward
```
### 卸载 GreptimeDB 集群
可以使用以下命令卸载 GreptimeDB 集群:
```bash
helm -n default uninstall mycluster
```
### 删除 PVCs
为了安全起见,PVCs 默认不会被删除。如果你想删除 PV 数据,你可以使用以下命令:
```bash
kubectl -n default delete pvc -l app.greptime.io/component=mycluster-datanode
```
### 清理 etcd 数据
你可以使用以下命令清理 etcd 集群:
```bash
kubectl -n etcd-cluster exec etcd-0 -- etcdctl del "" --from-key=true
```
### 删除 Kubernetes 集群
如果你使用 `kind` 创建 Kubernetes 集群,你可以使用以下命令销毁集群:
```bash
kind delete cluster
```
---
## 部署 GreptimeDB 环境测试
在该指南中,你将学会如何在 Kubernetes 上部署 GreptimeDB 基础环境测试工具。
## 前置条件
- [Docker](https://docs.docker.com/get-started/get-docker/) >= v23.0.0
- [kubectl](https://kubernetes.io/docs/tasks/tools/install-kubectl/) >= v1.18.0
- [Helm](https://helm.sh/docs/intro/install/) >= v3.0.0
- [kind](https://kind.sigs.k8s.io/docs/user/quick-start/) >= v0.20.0
## 创建一个测试 Kubernetes 集群
:::warning
不建议在生产环境或性能测试中使用 `kind`。如有这类需求建议使用公有云托管的 Kubernetes 服务,如 [Amazon EKS](https://aws.amazon.com/eks/)、[Google GKE](https://cloud.google.com/kubernetes-engine/) 或 [Azure AKS](https://azure.microsoft.com/en-us/services/kubernetes-service/),或者自行搭建生产级 Kubernetes 集群。
:::
目前有很多方法可以创建一个用于测试的 Kubernetes 集群。在本指南中,我们将使用 [kind](https://kind.sigs.k8s.io/docs/user/quick-start/) 来创建一个本地 Kubernetes 集群。如果你想使用已有的 Kubernetes 集群,可以跳过这一步。
这里是一个使用 `kind` v0.20.0 的示例:
```bash
kind create cluster
```
预期输出
```bash
Creating cluster "kind" ...
✓ Ensuring node image (kindest/node:v1.27.3) 🖼
✓ Preparing nodes 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
Set kubectl context to "kind-kind"
You can now use your cluster with:
kubectl cluster-info --context kind-kind
Thanks for using kind! 😊
```
使用以下命令检查集群的状态:
```bash
kubectl cluster-info
```
预期输出
```bash
Kubernetes control plane is running at https://127.0.0.1:60495
CoreDNS is running at https://127.0.0.1:60495/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
```
:::note
中国大陆用户如有网络访问问题,可使用 Greptime 提供的位于阿里云镜像仓库的 `kindest/node:v1.27.3` 镜像:
```bash
kind create cluster --image greptime-registry.cn-hangzhou.cr.aliyuncs.com/kindest/node:v1.27.3
```
:::
## 添加 Greptime Helm 仓库
:::note
中国大陆用户如有网络访问问题,可跳过这一步骤并直接参考下一步中使用阿里云 OCI 镜像仓库的方式。采用这一方式将无需手动添加 Helm 仓库。
:::
我们提供了 GreptimeDB Operator 和 GreptimeDB 集群的[官方 Helm 仓库](https://github.com/GreptimeTeam/helm-charts)。你可以通过运行以下命令来添加仓库:
```bash
helm repo add greptime https://greptimeteam.github.io/helm-charts/
helm repo update
```
检查 Greptime Helm 仓库中的 charts:
```bash
helm search repo greptime
```
预期输出
```bash
NAME CHART VERSION APP VERSION DESCRIPTION
greptime/greptimedb-cluster 0.8.3 1.0.1 A Helm chart for deploying GreptimeDB cluster i...
greptime/greptimedb-enterprise-dashboard 0.1.0 0.1.0 The Helm chart for deploying GreptimeDB Enterpr...
greptime/greptimedb-infra-test 0.1.0 0.1.0 The Helm chart for deploying GreptimeDB infra t...
greptime/greptimedb-operator 0.5.9 0.5.5 The greptimedb-operator Helm chart for Kubernetes.
greptime/greptimedb-remote-compaction 0.1.1 0.1.0 Remote compaction components (scheduler, compac...
greptime/greptimedb-standalone 0.4.2 1.0.1 A Helm chart for deploying standalone greptimedb
```
## 配置
创建自定义配置文件 `infra-test-values.yaml`:
```yaml
image:
# -- The image registry
registry: greptime-registry.cn-hangzhou.cr.aliyuncs.com
# -- The image repository
repository: greptime/greptime-tool
# -- The image tag
tag: "20260521-c19a702"
# -- The image pull secrets
pullSecrets: []
# -- Configure to the tests
case:
disk:
enabled: true
storageClass: null
size: 20Gi
cpu:
enabled: true
rds:
enabled: true
host: "your-rds-host"
port: 3306
database: "test"
username: "your-rds-username"
password: "your-rds-password"
s3:
enabled: true
bucket: "bucket-name"
region: "s3-region"
accessKeyID: "your-access-key-id"
secretAccessKey: "your-secret-access-key"
kafka:
enabled: true
endpoint: "your-kafka-endpoint"
```
## 安装
使用自定义配置安装:
```bash
helm upgrade --install greptimedb-infra-test greptime/greptimedb-infra-test \
--values infra-test-values.yaml \
-n default
```
## 查看测试结果
测试工具以 kubernetes job 方式运行,结果输出在 pod 日志中:
```bash
kubectl get pod -n default
```
期望输出
```bash
NAMESPACE NAME READY STATUS RESTARTS AGE
default greptimedb-infra-test-n7z74 0/1 Completed 0 10m
```
```bash
kubectl logs greptimedb-infra-test-n7z74 -n default
```
期望输出
```bash
================== Starting testing... ==================
================== Fetching UUID for kube-system namespace ==================
Successfully got UUID: 419a9914-5f9c-4d47-af69-3d09789db7a3
================== Disk tests ==================
================== Running full I/O test ==================
seq-read: (g=0): rw=read, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=64
seq-write: (g=0): rw=write, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=64
rand-iops: (g=0): rw=randrw, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=256
...
fio-3.28
Starting 6 processes
seq-read: Laying out IO file (1 file / 1024MiB)
seq-read: (groupid=0, jobs=6): err= 0: pid=14: Thu May 21 19:01:15 2026
read: IOPS=48.2k, BW=188MiB/s (198MB/s)(11.1GiB/60436msec)
slat (nsec): min=625, max=615290k, avg=53392.68, stdev=2634423.19
clat (nsec): min=875, max=636646k, avg=7912987.95, stdev=30341131.85
lat (usec): min=52, max=636649, avg=7966.49, stdev=30463.52
clat percentiles (usec):
| 1.00th=[ 223], 5.00th=[ 375], 10.00th=[ 562], 20.00th=[ 979],
| 30.00th=[ 1303], 40.00th=[ 1680], 50.00th=[ 2311], 60.00th=[ 3490],
| 70.00th=[ 4752], 80.00th=[ 6128], 90.00th=[ 13042], 95.00th=[ 23725],
| 99.00th=[103285], 99.50th=[270533], 99.90th=[421528], 99.95th=[438305],
| 99.99th=[488637]
bw ( KiB/s): min= 9969, max=450583, per=99.87%, avg=192706.79, stdev=24021.38, samples=596
iops : min= 2490, max=112644, avg=48175.32, stdev=6005.33, samples=596
write: IOPS=34.0k, BW=133MiB/s (139MB/s)(8021MiB/60436msec); 0 zone resets
slat (nsec): min=708, max=615509k, avg=77566.35, stdev=3387406.46
clat (usec): min=241, max=640859, avg=22321.94, stdev=54921.92
lat (usec): min=281, max=640862, avg=22399.63, stdev=55019.71
clat percentiles (msec):
| 1.00th=[ 3], 5.00th=[ 5], 10.00th=[ 7], 20.00th=[ 8],
| 30.00th=[ 9], 40.00th=[ 10], 50.00th=[ 11], 60.00th=[ 12],
| 70.00th=[ 14], 80.00th=[ 16], 90.00th=[ 26], 95.00th=[ 54],
| 99.00th=[ 359], 99.50th=[ 414], 99.90th=[ 485], 99.95th=[ 502],
| 99.99th=[ 634]
bw ( KiB/s): min=15032, max=284142, per=99.98%, avg=135879.94, stdev=12430.31, samples=596
iops : min= 3757, max=71033, avg=33968.77, stdev=3107.56, samples=596
lat (nsec) : 1000=0.01%
lat (usec) : 20=0.01%, 50=0.01%, 100=0.01%, 250=0.95%, 500=3.99%
lat (usec) : 750=3.41%, 1000=3.77%
lat (msec) : 2=15.07%, 4=11.77%, 10=31.21%, 20=20.84%, 50=5.71%
lat (msec) : 100=1.14%, 250=0.99%, 500=1.12%, 750=0.02%
cpu : usr=1.88%, sys=8.37%, ctx=786665, majf=0, minf=263
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.1%, >=64=0.1%
issued rwts: total=2915521,2053386,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=256
Run status group 0 (all jobs):
READ: bw=188MiB/s (198MB/s), 188MiB/s-188MiB/s (198MB/s-198MB/s), io=11.1GiB (11.9GB), run=60436-60436msec
WRITE: bw=133MiB/s (139MB/s), 133MiB/s-133MiB/s (139MB/s-139MB/s), io=8021MiB (8411MB), run=60436-60436msec
Disk stats (read/write):
vda: ios=2915375/2054793, merge=4/1130, ticks=8259465/6477837, in_queue=14772291, util=82.28%
================== Running mixed read/write test ==================
fiotest: (g=0): rw=rw, bs=(R) 64.0KiB-64.0KiB, (W) 64.0KiB-64.0KiB, (T) 64.0KiB-64.0KiB, ioengine=libaio, iodepth=16
...
fio-3.28
Starting 8 processes
fiotest: Laying out IO file (1 file / 1024MiB)
fiotest: (groupid=0, jobs=8): err= 0: pid=22: Thu May 21 19:02:19 2026
read: IOPS=42.5k, BW=2657MiB/s (2786MB/s)(4092MiB/1540msec)
slat (nsec): min=1541, max=3755.0k, avg=6912.45, stdev=28881.60
clat (usec): min=30, max=52156, avg=1045.12, stdev=2441.43
lat (usec): min=45, max=52191, avg=1052.13, stdev=2441.68
clat percentiles (usec):
| 1.00th=[ 118], 5.00th=[ 188], 10.00th=[ 265], 20.00th=[ 392],
| 30.00th=[ 506], 40.00th=[ 635], 50.00th=[ 783], 60.00th=[ 922],
| 70.00th=[ 1074], 80.00th=[ 1254], 90.00th=[ 1680], 95.00th=[ 2311],
| 99.00th=[ 3949], 99.50th=[ 4948], 99.90th=[47973], 99.95th=[49546],
| 99.99th=[50070]
bw ( MiB/s): min= 2578, max= 2871, per=100.00%, avg=2697.33, stdev=16.88, samples=24
iops : min=41246, max=45946, avg=43154.67, stdev=270.28, samples=24
write: IOPS=42.6k, BW=2662MiB/s (2792MB/s)(4100MiB/1540msec); 0 zone resets
slat (usec): min=2, max=3271, avg= 8.33, stdev=25.30
clat (usec): min=95, max=52303, avg=1920.68, stdev=2554.97
lat (usec): min=138, max=52312, avg=1929.12, stdev=2555.52
clat percentiles (usec):
| 1.00th=[ 310], 5.00th=[ 498], 10.00th=[ 693], 20.00th=[ 988],
| 30.00th=[ 1254], 40.00th=[ 1516], 50.00th=[ 1762], 60.00th=[ 1975],
| 70.00th=[ 2212], 80.00th=[ 2474], 90.00th=[ 2835], 95.00th=[ 3294],
| 99.00th=[ 4817], 99.50th=[ 5800], 99.90th=[50594], 99.95th=[50594],
| 99.99th=[50594]
bw ( MiB/s): min= 2560, max= 2861, per=100.00%, avg=2701.42, stdev=15.97, samples=24
iops : min=40960, max=45780, avg=43219.67, stdev=255.59, samples=24
lat (usec) : 50=0.01%, 100=0.26%, 250=4.39%, 500=12.56%, 750=12.72%
lat (usec) : 1000=12.92%
lat (msec) : 2=34.10%, 4=21.45%, 10=1.28%, 20=0.01%, 50=0.23%
lat (msec) : 100=0.06%
cpu : usr=2.91%, sys=9.45%, ctx=35300, majf=0, minf=295
IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=99.9%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.1%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=65475,65597,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=16
Run status group 0 (all jobs):
READ: bw=2657MiB/s (2786MB/s), 2657MiB/s-2657MiB/s (2786MB/s-2786MB/s), io=4092MiB (4291MB), run=1540-1540msec
WRITE: bw=2662MiB/s (2792MB/s), 2662MiB/s-2662MiB/s (2792MB/s-2792MB/s), io=4100MiB (4299MB), run=1540-1540msec
Disk stats (read/write):
vda: ios=58387/58501, merge=35/82, ticks=56442/57649, in_queue=114196, util=49.76%
================== CPU tests ==================
Architecture: aarch64
CPU op-mode(s): 64-bit
Byte Order: Little Endian
CPU(s): 6
On-line CPU(s) list: 0-5
Vendor ID: Apple
Model: 0
Thread(s) per core: 1
Core(s) per cluster: 6
Socket(s): -
Cluster(s): 1
Stepping: 0x0
BogoMIPS: 48.00
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm jscvt fcma lrcpc dcpop sha3 asimddp sha512 asimdfhm dit uscat ilrcpc flagm sb paca pacg dcpodp flagm2 frint
Vulnerability Gather data sampling: Not affected
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Reg file data sampling: Not affected
Vulnerability Retbleed: Not affected
Vulnerability Spec rstack overflow: Not affected
Vulnerability Spec store bypass: Vulnerable
Vulnerability Spectre v1: Mitigation; __user pointer sanitization
Vulnerability Spectre v2: Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
================== PostgreSQL Tests ==================
================== Running connection test ==================
✓ Connection successful
PostgreSQL version: 17.5
================== Running latency test ==================
Query 1: 62.14ms
Query 2: 32.75ms
Query 3: 26.37ms
Query 4: 27.06ms
Query 5: 27.67ms
================== Running write performance test ==================
DROP TABLE
CREATE TABLE
Testing single row INSERT performance (1000 rows)...
Inserted 1000 rows in 50.45ms
Average: .05ms per insert
Testing bulk INSERT performance (10000 rows)...
k Bulk inserted 10000 rows in 292.07ms
Throughput: 34238 rows/sec
================== Running read performance test ==================
Total rows: 10001
Count query took: 29.80ms
SELECT with condition (id < 1000): 30.32ms
Aggregate query (GROUP BY): 32.23ms
================== Running concurrent connection test ==================
Spawned 20 concurrent connections (all completed)
================== Running database info query ==================
Database size: 8531091 bytes
Active connections: 6
PostgreSQL uptime: 2026-05-21 17:37:54.672924+00
================== Running cleanup ==================
DROP TABLE
================== PostgreSQL tests completed ==================
================== Generating 10MB test file... ==================
1+0 records in
1+0 records out
10485760 bytes (10 MB, 10 MiB) copied, 0.0255081 s, 411 MB/s
================== Running S3 transfer test... ==================
================== Upload s3 testfile... ==================
100.00% ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 10.49 MB / 10.49 MB (491.69 kB/s) 22s (1/1)
Script started on 2026-05-21 19:02:22+00:00 []
100.00% ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 10.49 MB / 10.49 MB (491.69 kB/s) 22s (1/1)
Script done on 2026-05-21 19:02:44+00:00 [COMMAND_EXIT_CODE="0"]
================== Upload time: 22 seconds ==================
================== Download s3 testfile... ==================
100.00% ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 10.49 MB / 10.49 MB (7.48 MB/s) 1.6s (1/1)
Script started on 2026-05-21 19:02:44+00:00 []
100.00% ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 10.49 MB / 10.49 MB (7.48 MB/s) 1.6s (1/1)
Script done on 2026-05-21 19:02:45+00:00 [COMMAND_EXIT_CODE="0"]
================== Download time: 1 seconds ==================
================== Verifying file integrity... ==================
================== S3 test passed ==================
File size: 10485760 bytes
MD5 checksum: 29022c552b0f81a9c89f6ff676a5c102
================== Kafka test ==================
================== Creating Kafka Topic ==================
================== Starting Consumer ==================
================== Producing Messages ==================
Produce time: 1 seconds
================== Consumed Messages ==================
Successfully consumed 23 messages
================== All tests completed! ==================
```
---
## 部署 GreptimeDB 单机版
在该指南中,你将学会如何在 Kubernetes 上部署 GreptimeDB 单机版。
:::note
以下输出可能会因 Helm chart 版本和具体环境的不同而有细微差别。
:::
## 前置条件
- [Docker](https://docs.docker.com/get-started/get-docker/) >= v23.0.0
- [kubectl](https://kubernetes.io/docs/tasks/tools/install-kubectl/) >= v1.18.0
- [Helm](https://helm.sh/docs/intro/install/) >= v3.0.0
- [kind](https://kind.sigs.k8s.io/docs/user/quick-start/) >= v0.20.0
## 创建一个测试 Kubernetes 集群
:::warning
不建议在生产环境或性能测试中使用 `kind`。如有这类需求建议使用公有云托管的 Kubernetes 服务,如 [Amazon EKS](https://aws.amazon.com/eks/)、[Google GKE](https://cloud.google.com/kubernetes-engine/) 或 [Azure AKS](https://azure.microsoft.com/en-us/services/kubernetes-service/),或者自行搭建生产级 Kubernetes 集群。
:::
目前有很多方法可以创建一个用于测试的 Kubernetes 集群。在本指南中,我们将使用 [kind](https://kind.sigs.k8s.io/docs/user/quick-start/) 来创建一个本地 Kubernetes 集群。如果你想使用已有的 Kubernetes 集群,可以跳过这一步。
这里是一个使用 `kind` v0.20.0 的示例:
```bash
kind create cluster
```
预期输出
```bash
Creating cluster "kind" ...
✓ Ensuring node image (kindest/node:v1.27.3) 🖼
✓ Preparing nodes 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing CNI 🔌
✓ Installing StorageClass 💾
Set kubectl context to "kind-kind"
You can now use your cluster with:
kubectl cluster-info --context kind-kind
Thanks for using kind! 😊
```
使用以下命令检查集群的状态:
```bash
kubectl cluster-info
```
预期输出
```bash
Kubernetes control plane is running at https://127.0.0.1:60495
CoreDNS is running at https://127.0.0.1:60495/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
```
:::note
中国大陆用户如有网络访问问题,可使用 Greptime 提供的位于阿里云镜像仓库的 `kindest/node:v1.27.3` 镜像:
```bash
kind create cluster --image greptime-registry.cn-hangzhou.cr.aliyuncs.com/kindest/node:v1.27.3
```
:::
## 添加 Greptime Helm 仓库
:::note
中国大陆用户如有网络访问问题,可跳过这一步骤并直接参考下一步中使用阿里云 OCI 镜像仓库的方式。采用这一方式将无需手动添加 Helm 仓库。
:::
我们提供了 GreptimeDB Operator 和 GreptimeDB 集群的[官方 Helm 仓库](https://github.com/GreptimeTeam/helm-charts)。你可以通过运行以下命令来添加仓库:
```bash
helm repo add greptime https://greptimeteam.github.io/helm-charts/
helm repo update
```
检查 Greptime Helm 仓库中的 charts:
```bash
helm search repo greptime
```
预期输出
```bash
NAME CHART VERSION APP VERSION DESCRIPTION
greptime/greptimedb-cluster 0.8.3 1.0.1 A Helm chart for deploying GreptimeDB cluster i...
greptime/greptimedb-enterprise-dashboard 0.1.0 0.1.0 The Helm chart for deploying GreptimeDB Enterpr...
greptime/greptimedb-infra-test 0.1.0 0.1.0 The Helm chart for deploying GreptimeDB infra t...
greptime/greptimedb-operator 0.5.9 0.5.5 The greptimedb-operator Helm chart for Kubernetes.
greptime/greptimedb-remote-compaction 0.1.1 0.1.0 Remote compaction components (scheduler, compac...
greptime/greptimedb-standalone 0.4.2 1.0.1 A Helm chart for deploying standalone greptimedb
```
## 安装 GreptimeDB 单机版
### 基础安装
使用默认配置快速安装:
```bash
helm upgrade --install greptimedb-standalone greptime/greptimedb-standalone -n default
```
期望输出
```bash
Release "greptimedb-standalone" does not exist. Installing it now.
NAME: greptimedb-standalone
LAST DEPLOYED: Sun Apr 26 20:30:51 2026
NAMESPACE: default
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
***********************************************************************
Welcome to use greptimedb-standalone
Chart version: 0.4.2
GreptimeDB Standalone version: 1.0.1
***********************************************************************
Installed components:
* greptimedb-standalone
The greptimedb-standalone is starting, use `kubectl get statefulset greptimedb-standalone -n default` to check its status.
```
```bash
kubectl get pod -n default
```
期望输出
```bash
NAME READY STATUS RESTARTS AGE
greptimedb-standalone-0 1/1 Running 0 40s
```
### 自定义安装
创建自定义配置文件 `values.yaml`:
```yaml
resources:
requests:
cpu: "2"
memory: "4Gi"
limits:
cpu: "4"
memory: "8Gi"
```
更多配置选项请参考 [文档](https://github.com/GreptimeTeam/helm-charts/tree/main/charts/greptimedb-standalone).
使用自定义配置安装:
```bash
helm upgrade --install greptimedb-standalone greptime/greptimedb-standalone \
--values values.yaml \
--namespace default
```
期望输出
```bash
Release "greptimedb-standalone" has been upgraded. Happy Helming!
NAME: greptimedb-standalone
LAST DEPLOYED: Sun Apr 26 20:35:11 2026
NAMESPACE: default
STATUS: deployed
REVISION: 2
TEST SUITE: None
NOTES:
***********************************************************************
Welcome to use greptimedb-standalone
Chart version: 0.4.2
GreptimeDB Standalone version: 1.0.1
***********************************************************************
Installed components:
* greptimedb-standalone
The greptimedb-standalone is starting, use `kubectl get statefulset greptimedb-standalone -n default` to check its status.
```
```bash
kubectl get pod -n default
```
期望输出
```bash
NAME READY STATUS RESTARTS AGE
greptimedb-standalone-0 1/1 Running 0 3s
```
## 访问 GreptimeDB
安装完成后,您可以通过以下方式访问 GreptimeDB:
### MySQL 协议
```bash
kubectl port-forward svc/greptimedb-standalone 4002:4002 -n default > connections.out &
```
```bash
mysql -h 127.0.0.1 -P 4002
```
期望输出
```bash
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MySQL connection id is 8
Server version: 8.4.2 Greptime
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MySQL [(none)]>
```
### PostgreSQL 协议
```bash
kubectl port-forward svc/greptimedb-standalone 4003:4003 -n default > connections.out &
```
```bash
psql -h 127.0.0.1 -p 4003 -d public
```
期望输出
```bash
psql (16.2, server 16.3-GreptimeDB-1.0.1)
Type "help" for help.
public=>
```
### HTTP 协议
```bash
kubectl port-forward svc/greptimedb-standalone 4000:4000 -n default > connections.out &
```
```bash
curl -X POST \
-d 'sql=show databases' \
http://localhost:4000/v1/sql | jq .
```
期望输出
```json
{
"output": [
{
"records": {
"schema": {
"column_schemas": [
{
"name": "Database",
"data_type": "String"
}
]
},
"rows": [
[
"greptime_private"
],
[
"information_schema"
],
[
"public"
]
],
"total_rows": 3
}
}
],
"execution_time_ms": 2
}
```
## 卸载
删除 GreptimeDB 单机版:
```bash
helm uninstall greptimedb-standalone -n default
```
```bash
kubectl delete pvc -l app.kubernetes.io/instance=greptimedb-standalone -n default
```
---
## 部署 Kafka 集群
在该指南中,你将学会如何使用 Helm Chart 在 Kubernetes 上部署 Kafka 集群。
## 前置依赖
- Kubernetes >= v1.18.0
- [kubectl](https://kubernetes.io/docs/tasks/tools/install-kubectl/) >= v1.18.0
- [Helm](https://helm.sh/docs/intro/install/) >= v3.0.0
## 配置管理
在安装之前,你需要创建一个文件来配置 Kafka 集群。请根据你的 Kubernetes 环境调整,以下是 `kafka-values.yaml` 的参考配置:
```yaml
image:
registry: greptime-registry.cn-hangzhou.cr.aliyuncs.com
repository: greptime/kafka
tag: 3.9.0-debian-12-r1
listeners:
client:
containerPort: 9092
protocol: PLAINTEXT
name: CLIENT
controller:
protocol: PLAINTEXT
heapOpts: "-Xmx512m -Xms512m -XX:MetaspaceSize=96m -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:G1HeapRegionSize=16M -XX:MinMetaspaceFreeRatio=50 -XX:MaxMetaspaceFreeRatio=80 -XX:+ExplicitGCInvokesConcurrent"
controller:
replicaCount: 3
resources:
limits:
cpu: '1'
memory: 1Gi
requests:
cpu: 500m
memory: 512Mi
persistence:
enabled: true
storageClass: ""
size: 50Gi
broker:
replicaCount: 3
resources:
limits:
cpu: '1'
memory: 1Gi
requests:
cpu: 500m
memory: 512Mi
persistence:
enabled: true
storageClass: ""
size: 50Gi
extraConfig: |
num.network.threads=3
num.io.threads=8
min.insync.replicas=1
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
allow.everyone.if.no.acl.found=true
auto.create.topics.enable=true
default.replication.factor=1
max.partition.fetch.bytes=1048576
max.request.size=1048576
message.max.bytes=20000000
log.dirs=/bitnami/kafka/data
log.flush.interval.messages=10000
log.flush.interval.ms=1000
log.retention.hours=4
log.roll.hours=3
log.retention.bytes=250000000
log.segment.bytes=1073741824
```
## 安装 Kafka 集群
在 kafka 命名空间中安装 Kafka 集群:
```bash
helm upgrade --install kafka \
--create-namespace \
oci://greptime-registry.cn-hangzhou.cr.aliyuncs.com/charts/kafka \
--version 31.0.0 \
-n kafka --values kafka-values.yaml
```
预期输出
```bash
Release "kafka" does not exist. Installing it now.
Pulled: greptime-registry.cn-hangzhou.cr.aliyuncs.com/charts/kafka:31.0.0
Digest: sha256:85b135981fd5d951ceef8b51cdcbc6917ebface50d0eb3367eb7ddc4a5db482b
NAME: kafka
LAST DEPLOYED: Tue May 12 00:57:32 2026
NAMESPACE: kafka
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: kafka
CHART VERSION: 31.0.0
APP VERSION: 3.9.0
** Please be patient while the chart is being deployed **
Kafka can be accessed by consumers via port 9092 on the following DNS name from within your cluster:
kafka.kafka.svc.cluster.local
Each Kafka broker can be accessed by producers via port 9092 on the following DNS name(s) from within your cluster:
kafka-controller-0.kafka-controller-headless.kafka.svc.cluster.local:9092
kafka-broker-0.kafka-broker-headless.kafka.svc.cluster.local:9092
To create a pod that you can use as a Kafka client run the following commands:
kubectl run kafka-client --restart='Never' --image greptime-registry.cn-hangzhou.cr.aliyuncs.com/greptime/kafka:3.9.0-debian-12-r1 --namespace kafka --command -- sleep infinity
kubectl exec --tty -i kafka-client --namespace kafka -- bash
PRODUCER:
kafka-console-producer.sh \
--bootstrap-server kafka.kafka.svc.cluster.local:9092 \
--topic test
CONSUMER:
kafka-console-consumer.sh \
--bootstrap-server kafka.kafka.svc.cluster.local:9092 \
--topic test \
--from-beginning
Substituted images detected:
- greptime-registry.cn-hangzhou.cr.aliyuncs.com/greptime/kafka:3.9.0-debian-12-r1
```
## 验证 Kafka 集群安装
检查 Kafka 组件(Broker 和 Controller)的状态:
```bash
kubectl get pod -n kafka
```
预期输出
```bash
NAME READY STATUS RESTARTS AGE
kafka-broker-0 1/1 Running 0 8m3s
kafka-broker-1 1/1 Running 0 8m2s
kafka-broker-2 1/1 Running 0 8m1s
kafka-controller-0 1/1 Running 0 8m3s
kafka-controller-1 1/1 Running 0 8m2s
kafka-controller-0 1/1 Running 0 8m1s
```
# 配置 Kafka 端点
在 Kafka 集群部署完成后,GreptimeDB 可以通过配置 Kafka 端点启用 Remote WAL(远程写前日志),更多参考[此篇文档](/user-guide/deployments-administration/deploy-on-kubernetes/configure-remote-wal.md)。
```yaml
remoteWal:
enabled: true
kafka:
brokerEndpoints:
- "kafka-broker-0.kafka-broker-headless.kafka.svc.cluster.local:9092"
- "kafka-broker-1.kafka-broker-headless.kafka.svc.cluster.local:9092"
- "kafka-broker-2.kafka-broker-headless.kafka.svc.cluster.local:9092"
```
# 监控
- 安装 Prometheus Operator (例如: [kube-prometheus-stack](https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack))。
- 安装 podmonitor CRD。
要监控 Kafka 集群,你需要提前部署好监控系统(如 Prometheus 和 Grafana)。然后在 `kafka-values.yaml` 中增加以下内容,并重新执行更新 Kafka 配置:
```yaml
metrics:
jmx:
enabled: true
image:
registry: greptime-registry.cn-hangzhou.cr.aliyuncs.com
repository: greptime/jmx-exporter
tag: 1.0.1-debian-12-r9
serviceMonitor:
enabled: true
namespace: "kafka"
interval: "10s"
labels:
release: kube-prometheus-stack
```
## Grafana dashboard
使用 [Kubernetes Kafka](https://grafana.com/grafana/dashboards/12483-kubernetes-kafka/) (ID: 12483) 来监控 kafka 的指标。
1. 登录你的 Grafana。
2. 导航至 Dashboards -> New -> Import。
3. 输入 Dashboard ID: 12483, 选择数据源并加载图表。
# 卸载 Kafka 集群
可以使用以下命令卸载 Kafka 集群:
```bash
helm -n kafka uninstall kafka
```
## 删除 PVCs
删除 PVCs 操作将会删除 Kafka 集群的持久化数据。请确保在继续操作之前已经备份了数据。
```bash
kubectl -n kafka delete pvc -l app.kubernetes.io/instance=kafka
```
---
## 部署 MinIO 集群
在该指南中,你将学会如何使用 Helm Chart 在 Kubernetes 上部署 MinIO 集群。
## 前置依赖
- Kubernetes >= v1.18.0
- [kubectl](https://kubernetes.io/docs/tasks/tools/install-kubectl/) >= v1.18.0
- [Helm](https://helm.sh/docs/intro/install/) >= v3.0.0
## 配置管理
在安装之前,你需要创建一个 `minio-values.yaml` 配置文件。请根据你的 Kubernetes 环境调整以下配置:
```yaml
global:
security:
allowInsecureImages: true
image:
registry: greptime-registry.cn-hangzhou.cr.aliyuncs.com
repository: greptime/minio
tag: 2025.4.22-debian-12-r1
auth:
rootUser: greptimedbadmin
rootPassword: "greptimedbadmin"
resources:
requests:
cpu: 500m
memory: 500Mi
limits:
cpu: '2'
memory: 2Gi
extraEnvVars:
- name: MINIO_REGION
value: "ap-southeast-1"
statefulset:
replicaCount: 4
mode: distributed
persistence:
storageClass: null
size: 100Gi
```
## 安装 MinIO 集群
在 minio 命名空间中安装 MinIO 集群:
```bash
helm upgrade \
--install minio oci://greptime-registry.cn-hangzhou.cr.aliyuncs.com/charts/minio \
--create-namespace \
--version 16.0.10 \
-n minio --values minio-values.yaml
```
预期输出
```bash
Release "minio" does not exist. Installing it now.
Pulled: greptime-registry.cn-hangzhou.cr.aliyuncs.com/charts/minio:16.0.10
Digest: sha256:96e220fd7cf1596879a243453b39c96a95d34f0005fdd452da3d094a7b386eb4
NAME: minio
LAST DEPLOYED: Tue May 12 17:21:30 2026
NAMESPACE: minio
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: minio
CHART VERSION: 16.0.10
APP VERSION: 2025.4.22
Did you know there are enterprise versions of the Bitnami catalog? For enhanced secure software supply chain features, unlimited pulls from Docker, LTS support, or application customization, see Bitnami Premium or Tanzu Application Catalog. See https://www.arrow.com/globalecs/na/vendors/bitnami for more information.
** Please be patient while the chart is being deployed **
MinIO® can be accessed via port on the following DNS name from within your cluster:
minio.minio.svc.cluster.local
To get your credentials run:
export ROOT_USER=$(kubectl get secret --namespace minio minio -o jsonpath="{.data.root-user}" | base64 -d)
export ROOT_PASSWORD=$(kubectl get secret --namespace minio minio -o jsonpath="{.data.root-password}" | base64 -d)
To connect to your MinIO® server using a client:
- Run a MinIO® Client pod and append the desired command (e.g. 'admin info'):
kubectl run --namespace minio minio-client \
--rm --tty -i --restart='Never' \
--env MINIO_SERVER_ROOT_USER=$ROOT_USER \
--env MINIO_SERVER_ROOT_PASSWORD=$ROOT_PASSWORD \
--env MINIO_SERVER_HOST=minio \
--image docker.io/bitnami/minio-client:2025.4.16-debian-12-r1 -- admin info minio
To access the MinIO® web UI:
- Get the MinIO® URL:
echo "MinIO® web URL: http://127.0.0.1:9001/minio"
kubectl port-forward --namespace minio svc/minio 9001:9001
Substituted images detected:
- greptime-registry.cn-hangzhou.cr.aliyuncs.com/greptime/minio:2025.4.22-debian-12-r1
```
## 验证 MinIO 集群安装
检查 MinIO Pod 的状态:
```bash
kubectl get pod -n minio
```
预期输出
```bash
NAME READY STATUS RESTARTS AGE
minio-0 1/1 Running 0 30s
minio-1 1/1 Running 0 30s
minio-2 1/1 Running 0 30s
minio-3 1/1 Running 0 30s
```
# 创建 Bucket 和 Access Key
## 访问 MinIO 控制台
1. 首先需要将 MinIO 控制台服务暴露出来,你可以使用 `kubectl port-forward` 命令:
```bash
kubectl port-forward -n minio svc/minio 9001:9001
```
2. 打开浏览器访问 http://localhost:9001/login
3. 使用配置文件中设置的账号密码登录:
- username: `greptimedbadmin`
- password: `greptimedbadmin`
## 创建 Bucket
登录 MinIO 控制台后,按照以下步骤创建 Bucket:
1. 点击左侧菜单栏的 "Buckets"
2. 点击 "Create Bucket" 按钮
3. 输入 Bucket 名称,例如:`greptimedb-bucket`
4. 点击 "Create Bucket" 确认创建
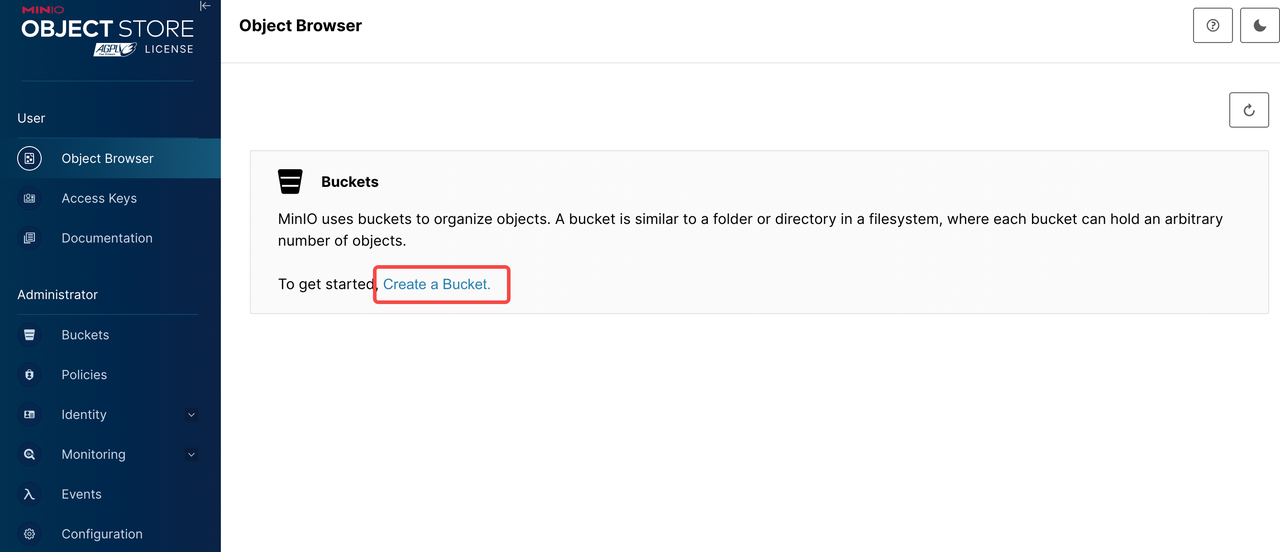
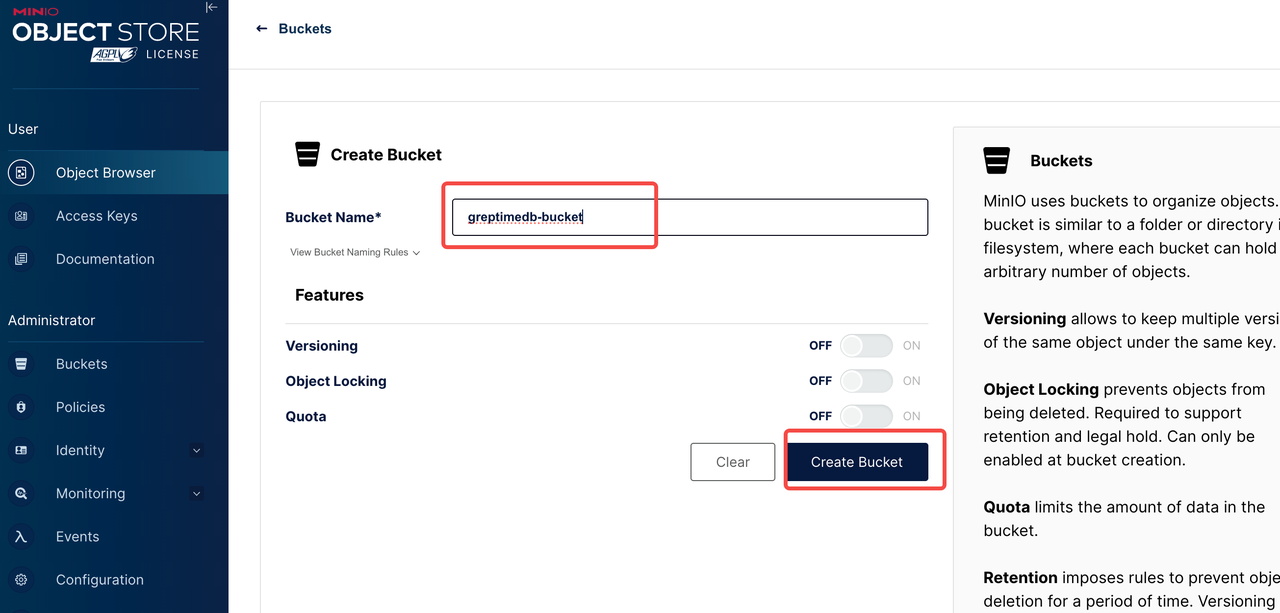
## 生成 Access Key
1. 点击左侧菜单栏的 "Access Keys"
2. 点击 "Create Access Key" 按钮
3. 可选:设置权限策略
4. 点击 "Create" 生成 Access Key 和 Secret Key
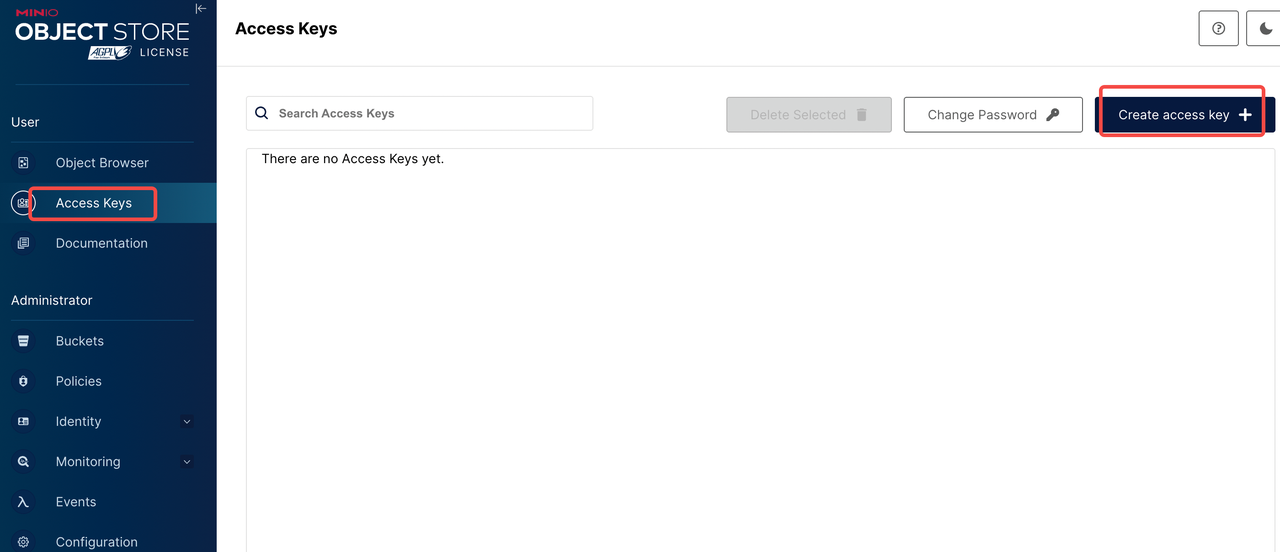
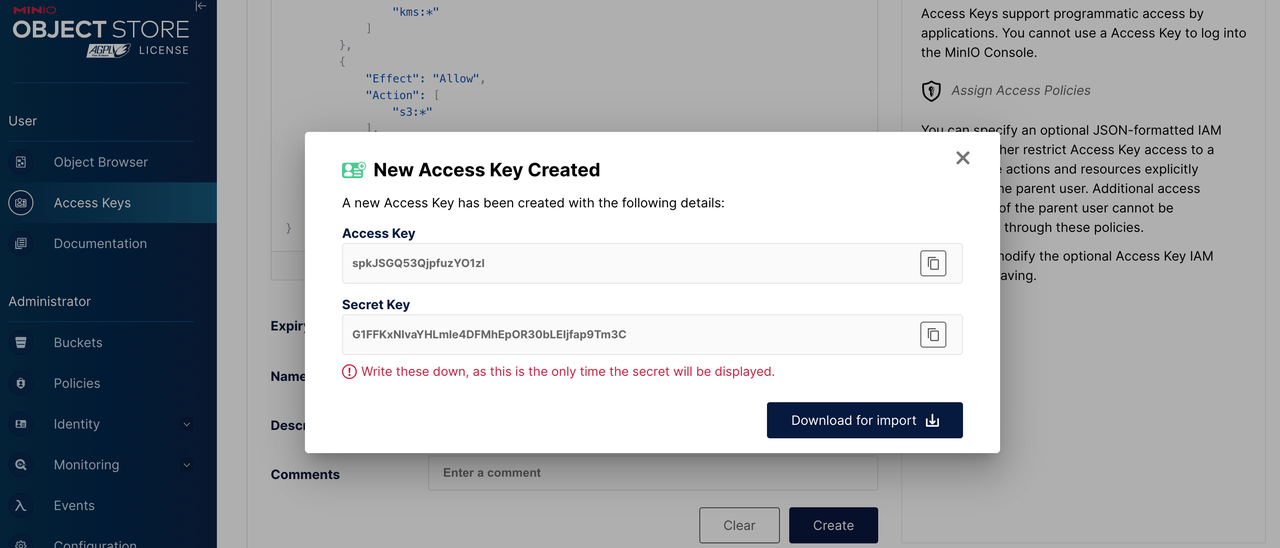
:::warning
⚠️ 重要:请妥善保存以下信息,在部署 GreptimeDB 时会用到。
- Bucket 名称:greptimedb-bucket
- Region:ap-southeast-1
- MinIO Endpoint:`http://minio.minio:9000`
- Access Key:创建时生成的 Access Key
- Secret Key:创建时生成的 Secret Key
:::
# 配置 GreptimeDB 使用 MinIO
在部署 GreptimeDB 集群时,可以通过以下配置使用 MinIO 作为后端存储:
```yaml
objectStorage:
credentials:
accessKeyId: ""
secretAccessKey: ""
s3:
bucket: "greptimedb-bucket"
region: "ap-southeast-1"
root: "greptimedb-data"
endpoint: "http://minio.minio:9000"
```
# 监控
- 安装 Prometheus Operator (例如: [kube-prometheus-stack](https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack))。
- 安装 podmonitor CRD。
要监控 MinIO 集群,你需要提前部署好监控系统(如 Prometheus 和 Grafana)。然后在 `minio-values.yaml` 中增加以下内容,并重新执行更新 MinIO 配置:
```yaml
metrics:
enabled: true
serviceMonitor:
enabled: true
namespace: minio
labels:
release: kube-prometheus-stack
interval: 30s
```
## Grafana dashboard
使用 [MinIO Dashboard](https://grafana.com/grafana/dashboards/13502-minio-dashboard/) (ID: 13502) 来监控 MinIO 的指标。
1. 登录你的 Grafana。
2. 导航至 Dashboards -> New -> Import。
3. 输入 Dashboard ID: 13502, 选择数据源并加载图表。
# 卸载 MinIO 集群
使用以下命令卸载 MinIO 集群:
```bash
helm -n minio uninstall minio
```
## 删除 PVCs
删除 PVCs 操作将会删除 MinIO 集群的持久化数据。请确保在继续操作之前已经备份了数据。
```bash
kubectl -n minio delete pvc -l app.kubernetes.io/instance=minio
```
---
## GreptimeDB Operator 的管理
GreptimeDB Operator 使用 [Operator 模式](https://kubernetes.io/docs/concepts/extend-kubernetes/operator/) 在 [Kubernetes](https://kubernetes.io/) 上管理 [GreptimeDB](https://github.com/GrepTimeTeam/greptimedb) 资源。
就像自动驾驶一样,GreptimeDB Operator 自动化了 GreptimeDB 集群和单机实例的部署、配置和管理。
GreptimeDB Operator 包括但不限于以下功能:
- **自动化部署**: 通过提供 `GreptimeDBCluster` 和 `GreptimeDBStandalone` CRD 来自动化在 Kubernetes 上部署 GreptimeDB 集群和单机实例。
- **多云支持**: 用户可以在任何 Kubernetes 集群上部署 GreptimeDB,包括私有环境和公有云环境(如 AWS、GCP、阿里云等)。
- **扩缩容**: 通过修改 `GreptimeDBCluster` CR 中的 `replicas` 字段即可轻松实现 GreptimeDB 集群的扩缩容。
- **监控**: 通过在 `GreptimeDBCluster` CR 中提供 `monitoring` 字段来自动化部署基于 GreptimeDB 的监控组件。
本指南将展示如何在 Kubernetes 上安装、升级、配置和卸载 GreptimeDB Operator。
:::note
以下输出可能会因 Helm chart 版本和具体环境的不同而有细微差别。
:::
## 前置依赖
- Kubernetes >= v1.18.0
- [kubectl](https://kubernetes.io/docs/tasks/tools/install-kubectl/) >= v1.18.0
- [Helm](https://helm.sh/docs/intro/install/) >= v3.0.0
## 生产环境部署
对于生产环境部署,推荐使用 Helm 来安装 GreptimeDB Operator。
### 安装
你可以参考 [安装和验证 GreptimeDB Operator](/user-guide/deployments-administration/deploy-on-kubernetes/deploy-greptimedb-cluster.md#安装和验证-greptimedb-operator) 获取详细的指导。
:::note
如果你使用 [Argo CD](https://argo-cd.readthedocs.io/en/stable/) 来部署应用,请确保 `Application` 已设置 [`ServerSideApply=true`](https://argo-cd.readthedocs.io/en/latest/user-guide/sync-options/#server-side-apply) 以启用 server-side apply(其他 GitOps 工具可能也有类似的设置)。
:::
### 升级
我们总是将最新版本的 GreptimeDB Operator 作为 Helm chart 发布在我们的[官方 Helm 仓库](https://github.com/GreptimeTeam/helm-charts/tree/main)。
当最新版本的 GreptimeDB Operator 发布时,您可以通过运行以下命令来升级 GreptimeDB Operator。
#### 更新 Helm 仓库
```bash
helm repo update greptime
```
期望输出
```bash
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "greptime" chart repository
Update Complete. ⎈Happy Helming!⎈
```
你可以使用以下命令来搜索 GreptimeDB Operator 的最新版本:
```bash
helm search repo greptime/greptimedb-operator
```
预期输出
```bash
NAME CHART VERSION APP VERSION DESCRIPTION
greptime/greptimedb-operator 0.5.9 0.5.5 The greptimedb-operator Helm chart for Kubernetes.
```
如果你想列出所有可用的版本,你可以使用以下命令:
```
helm search repo greptime/greptimedb-operator --versions
```
#### 升级 GreptimeDB Operator
你可以通过运行以下命令升级到最新发布的 GreptimeDB Operator 版本:
```bash
helm -n greptimedb-admin upgrade --install greptimedb-operator greptime/greptimedb-operator
```
期望输出
```bash
NAME: greptimedb-operator
LAST DEPLOYED: Sun Apr 26 20:43:58 2026
NAMESPACE: greptimedb-admin
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
***********************************************************************
Welcome to use greptimedb-operator
Chart version: 0.5.9
GreptimeDB Operator version: 0.5.5
***********************************************************************
Installed components:
* greptimedb-operator
The greptimedb-operator is starting, use `kubectl get deployment greptimedb-operator -n greptimedb-admin` to check its status.
```
如果你想升级到特定版本,你可以使用以下命令:
```bash
helm -n greptimedb-admin upgrade --install greptimedb-operator greptime/greptimedb-operator --version
```
升级完成后,你可以使用以下命令来验证安装:
```bash
helm list -n greptimedb-admin
```
期望输出
```bash
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
greptimedb-operator greptimedb-admin 1 2026-04-26 20:43:58.003167 +0800 CST deployed greptimedb-operator-0.5.9 0.5.5
```
### CRDs
这里将有两种类型的 CRD 与 GreptimeDB Operator 一起安装:`GreptimeDBCluster` 和 `GreptimeDBStandalone`。
你可以使用以下命令来验证安装:
```bash
kubectl get crd | grep greptime
```
期望输出
```bash
greptimedbclusters.greptime.io 2026-04-26T12:43:58Z
greptimedbstandalones.greptime.io 2026-04-26T12:43:58Z
```
默认情况下,GreptimeDB Operator chart 将管理 CRDs 的安装和升级,用户不需要手动管理它们。如果你想了解这两类 CRD 的具体定义,可参考 GreptimeDB Operator 的 [API 文档](https://github.com/GreptimeTeam/greptimedb-operator/blob/main/docs/api-references/docs.md)。
### 配置
GreptimeDB Operator chart 提供了一组配置选项,允许您自行配置,您可以参考 [GreptimeDB Operator Helm Chart](https://github.com/GreptimeTeam/helm-charts/blob/main/charts/greptimedb-operator/README.md) 来获取更多详细信息。
你可以创建一个 `values.yaml` 来配置 GreptimeDB Operator chart (完整的 `values.yaml` 配置可以参考 [chart](https://github.com/GreptimeTeam/helm-charts/blob/main/charts/greptimedb-operator/values.yaml)),例如:
```yaml
image:
# -- The image registry
registry: docker.io
# -- The image repository
repository: greptime/greptimedb-operator
# -- The image pull policy for the controller
imagePullPolicy: IfNotPresent
# -- The image tag
tag: "v0.6.0"
# -- The image pull secrets
pullSecrets: []
replicas: 1
resources:
limits:
cpu: 500m
memory: 512Mi
requests:
cpu: 250m
memory: 256Mi
```
:::note
中国大陆用户如有网络访问问题,可将上文中的 `image.registry` 配置为阿里云镜像仓库地址 `greptime-registry.cn-hangzhou.cr.aliyuncs.com`。
:::
你可以使用以下的命令来安装或升级带有自定义配置的 GreptimeDB Operator:
```bash
helm -n greptimedb-admin upgrade --install greptimedb-operator greptime/greptimedb-operator -f values.yaml
```
### 卸载
你可以使用 `helm` 命令来卸载 GreptimeDB Operator:
```bash
helm -n greptimedb-admin uninstall greptimedb-operator
```
默认情况下,卸载 GreptimeDB Operator 时不会删除 CRDs。
:::danger
如果你确实想要删除 CRDs,你可以使用以下命令:
```bash
kubectl delete crd greptimedbclusters.greptime.io greptimedbstandalones.greptime.io
```
删除 CRDs 后,相关资源将被删除。
:::
---
## 在 Kubernetes 上部署 GreptimeDB
GreptimeDB 专为云原生环境而构建,从第一天起就可以在 Kubernetes 上部署。
你可以在任何云服务提供商上部署 GreptimeDB,包括 AWS、阿里云或谷歌云等。
## 部署 GreptimeDB 单机版
对于开发、测试或小规模生产用例,你可以在 Kubernetes 上[部署 GreptimeDB 单机实例](deploy-greptimedb-standalone.md)。
这种方式较为简单,无需管理完整集群的复杂性。
## 部署 GreptimeDB 集群
对于需要高可用性和可扩展性的生产环境,
你可以使用 GreptimeDB Operator 在 Kubernetes 上[部署 GreptimeDB 集群](deploy-greptimedb-cluster.md)以建立分布式 GreptimeDB 集群,
水平扩展并高效处理大量数据。
## 配置
在部署 GreptimeDB 集群或单机实例时,你可以通过创建 `values.yaml` 文件
来对 GreptimeDB 应用自定义配置。
有关可用配置选项的完整列表,请参阅[通用 Helm Chart 配置](./common-helm-chart-configurations.md)。
## 管理 GreptimeDB Operator
基于 GreptimeDB Operator,你可以很轻松地部署、升级和管理 GreptimeDB 集群和单机实例。
无论是私有还是公有云部署,GreptimeDB Operator 都将快速部署和扩容 GreptimeDB 变得简单易行。
了解如何[管理 GreptimeDB Operator](./greptimedb-operator-management.md),
包括安装和升级。
## 进阶部署
在熟悉了 [GreptimeDB 的架构和组件](/user-guide/concepts/architecture.md)之后,你可以进一步探索高级部署场景:
- [部署 GreptimeDB 基础设施测试](deploy-greptimedb-infra-test.md): 安装 GreptimeDB 的前置基础设施测试检查。
- [部署 MinIO 集群](deploy-minio.md):学习如何部署,配置和监控 MinIO 集群。
- [部署 Kafka 集群](deploy-kafka.md):学习如何部署,配置和监控 Kafka 集群。
- [部署带有 Remote WAL 的 GreptimeDB 集群](configure-remote-wal.md):将 Kafka 配置为 GreptimeDB 集群的远程预写日志 (WAL),以持久记录每个数据修改并确保不丢失内存缓存的数据。
- [使用 MySQL/PostgreSQL 作为元数据存储](/user-guide/deployments-administration/deploy-on-kubernetes/common-helm-chart-configurations.md#配置-metasrv-后端存储):集成 MySQL/PostgreSQL 数据库以提供强大的元数据存储功能,增强可靠性和性能。
- [部署多 Frontend 的 GreptimeDB 集群](configure-frontend-groups.md):GreptimeDB 集群的 Frontend 组由多个 Frontend 实例组成,以改善负载分配和可用性。
---
## GreptimeDB 导出和导入工具
本指南描述了如何使用 GreptimeDB 的导出和导入工具进行数据库备份和恢复。
有关详细的命令行选项和高级配置,请参阅 [数据导出和导入](/reference/command-lines/utilities/data.md)。
## 概述
## 导出操作
### 完整数据库备份
导出所有数据库备份。此操作将每个数据库导出到单个目录中,包括所有表及其数据。
```bash
# 导出所有数据库备份
greptime cli data export \
--addr localhost:4000 \
--output-dir /tmp/backup/greptimedb
```
输出目录结构:
```
/
└── greptime/
└── /
├── create_database.sql
├── create_tables.sql
├── copy_from.sql
└── <数据文件>
```
#### 导出到 S3
导出所有数据库备份到 S3:
```bash
greptime cli data export \
--addr localhost:4000 \
--s3 \
--s3-bucket \
--s3-access-key-id \
--s3-secret-access-key \
--s3-region \
--s3-root \
--s3-endpoint
```
### 使用 Basic Authentication 导出
如果 GreptimeDB 实例启用了身份认证,请使用 `--auth-basic` 传入凭据:
```bash
greptime cli data export \
--addr localhost:4000 \
--output-dir /tmp/backup/greptimedb \
--auth-basic :
```
### 仅导出表结构
仅导出表结构而不包含数据。此操作将 `CREATE TABLE` 语句导出到 SQL 文件中,允许您备份表结构而不包含实际数据。
```bash
# 仅导出表结构
greptime cli data export \
--addr localhost:4000 \
--output-dir /tmp/backup/schemas \
--target schema
```
### 基于时间范围备份
```bash
# 导出指定时间范围内的数据
greptime cli data export --addr localhost:4000 \
--output-dir /tmp/backup/timerange \
--start-time "2024-01-01 00:00:00" \
--end-time "2024-01-31 23:59:59"
```
### 指定数据库备份
```bash
# 导出指定数据库
greptime cli data export \
--addr localhost:4000 \
--output-dir /tmp/backup/greptimedb \
--database '{my_database_name}'
```
## 导入操作
### 完整数据库备份
导入所有数据库备份。
```bash
# 导入所有数据库
greptime cli data import \
--addr localhost:4000 \
--input-dir /tmp/backup/greptimedb
```
### 使用 Basic Authentication 导入
如果 GreptimeDB 实例启用了身份认证,请使用 `--auth-basic` 传入凭据:
```bash
greptime cli data import \
--addr localhost:4000 \
--input-dir /tmp/backup/greptimedb \
--auth-basic :
```
### 仅导入表结构
仅导入表结构而不包含数据。此操作将 `CREATE TABLE` 语句从 SQL 文件中导入,允许您恢复表结构而不包含实际数据。
```bash
# 仅导入表结构
greptime cli data import \
--addr localhost:4000 \
--input-dir /tmp/backup/schemas \
--target schema
```
### 指定数据库备份
```bash
# 导入指定数据库
greptime cli data import \
--addr localhost:4000 \
--input-dir /tmp/backup/greptimedb \
--database '{my_database_name}'
```
## 最佳实践
1. **并行度配置**
- 根据可用系统资源调整 `--export-jobs`/`--import-jobs`
- 从较低的值开始,逐步增加
- 在操作期间监控系统性能
2. **备份策略**
- 使用时间范围进行增量数据备份
- 定期备份用于灾难恢复
3. **错误处理**
- 使用 `--max-retry` 处理临时异常
- 保留日志以便故障排除
## 性能提示
1. **导出性能**
- 对大型数据集使用时间范围
- 根据 CPU/内存调整并行任务数量
- 考虑网络带宽限制
2. **导入性能**
- 注意监控数据库资源
1. **导出性能**
- 对大型数据集使用时间范围
- 根据 CPU/内存调整并行任务
- 考虑网络带宽限制
2. **导入性能**
- 监控数据库资源
## 故障排除
### 常见问题
1. **连接错误**
- 验证服务器地址和端口
- 检查网络连接
- 确保身份验证凭据正确
2. **权限问题**
- 验证输出/输入目录的读写权限
3. **资源限制**
- 减少并行任务数
- 确保足够的磁盘空间
- 在操作期间监控系统资源
---
## GreptimeDB 元信息导出和导入工具
本指南描述了如何使用 GreptimeDB 的元信息导出和导入工具进行元数据库备份和恢复。
有关详细的命令行选项和高级配置,请参阅 [元数据导出和导入](/reference/command-lines/utilities/metadata.md)。
## 概述
## 导出操作
### 导出到 S3 云存储
将元数据从 PostgreSQL 导出到 S3 云存储,用于云备份存储:
```bash
greptime cli meta snapshot save \
--store-addrs 'password=password dbname=postgres user=postgres host=localhost port=5432' \
--backend postgres-store \
--s3 \
--s3-bucket your-bucket-name \
--s3-region ap-southeast-1 \
--s3-access-key-id \
--s3-secret-access-key
```
**输出**: 在指定的 S3 桶中创建 `metadata_snapshot.metadata.fb` 文件。
### 导出到本地目录
#### 从 PostgreSQL 后端导出
将元数据从 PostgreSQL 导出到本地目录:
```bash
greptime cli meta snapshot save \
--store-addrs 'password=password dbname=postgres user=postgres host=localhost port=5432' \
--backend postgres-store
```
#### 从 MySQL 后端导出
将元数据从 MySQL 导出到本地目录:
```bash
greptime cli meta snapshot save \
--store-addrs 'mysql://user:password@127.0.0.1:3306/database' \
--backend mysql-store
```
#### 从 etcd 后端导出
将元数据从 etcd 导出到本地目录:
```bash
greptime cli meta snapshot save \
--store-addrs 127.0.0.1:2379 \
--backend etcd-store
```
**输出**: 在当前工作目录中创建 `metadata_snapshot.metadata.fb` 文件。
#### 从 RaftEngine 后端导出
:::note
RaftEngine 在 standalone 实例运行期间会锁定元数据目录,请在导出前停止 standalone 实例。
:::
将元数据从 RaftEngine 导出到本地目录:
```bash
greptime cli meta snapshot save \
--store-addrs "raftengine:///path/to/metadata" \
--backend raft-engine-store
```
**输出**: 在当前工作目录中创建 `metadata_snapshot.metadata.fb` 文件。
## 导入操作
:::warning
**重要**: 在导入元数据之前,请确保目标存储后端的对应表中没有**任何数据**,否则可能会导致元数据损坏。
如果你需要导入到具有现有数据的后端,请使用 `--force` 标志绕过此安全检查。但是,请谨慎操作,因为这可能导致数据损坏。
:::
### 从 S3 云存储导入
从 S3 备份恢复元数据到 PostgreSQL 存储后端:
```bash
greptime cli meta snapshot restore \
--store-addrs 'password=password dbname=postgres user=postgres host=localhost port=5432' \
--backend postgres-store \
--s3 \
--s3-bucket your-bucket-name \
--s3-region ap-southeast-1 \
--s3-access-key-id \
--s3-secret-access-key
```
### 从本地文件导入
#### 导入到 PostgreSQL 后端
从本地备份文件恢复元数据到 PostgreSQL:
```bash
greptime cli meta snapshot restore \
--store-addrs 'password=password dbname=postgres user=postgres host=localhost port=5432' \
--backend postgres-store
```
#### 导入到 MySQL 后端
从本地备份文件恢复元数据到 MySQL:
```bash
greptime cli meta snapshot restore \
--store-addrs 'mysql://user:password@127.0.0.1:3306/database' \
--backend mysql-store
```
#### 导入到 etcd 后端
从本地备份文件恢复元数据到 etcd:
```bash
greptime cli meta snapshot restore \
--store-addrs 127.0.0.1:2379 \
--backend etcd-store
```
#### 导入到 RaftEngine 后端
从本地备份文件恢复元数据到 RaftEngine:
```bash
greptime cli meta snapshot restore \
--store-addrs "raftengine:///path/to/metadata" \
--backend raft-engine-store
```
---
## 基于单集群跨区域部署的 DR 解决方案
## GreptimeDB DR 的工作原理
GreptimeDB 非常适合跨区域灾难恢复。GreptimeDB 提供了量身定制的解决方案,以满足不同区域特征和业务需求的多样化要求。
GreptimeDB 资源管理涉及 Availability Zones(AZ)的概念。一个 AZ 是一个逻辑上的灾难恢复单元。
它可以是数据中心(DC),也可以是 DC 的一个分区,这取决于你具体的 DC 条件和部署设计。
在跨区域灾难恢复解决方案中,一个 GreptimeDB 区域是一个城市。当两个 DC 在同一区域且其中一个 DC 不可用时,另一个 DC 可以接管不可用 DC 的服务。这是一种本地化策略。
在了解每个 DR 解决方案的细节之前,有必要先了解以下知识:
1. Remote wal 组件的 DR 解决方案也非常重要。本质上,它构成了整个 DR 解决方案的基础。因此,对于每个 GreptimeDB 的 DR 解决方案,我们将在图中展示 remote wal 组件。目前,GreptimeDB 默认使用基于 Kafka 实现的 remote wal 组件,将来会提供其他实现;然而,在部署上不会有显著差异。
2. GreptimeDB 表:每张表可以根据一定范围划分为多个分区,每个分区可能分布在不同的数据节点上。在写入或查询时,会根据相应的路由规则调用到指定的数据节点。一张表的分区可能如下所示:
```
Table name: T1
Table partition count: 4
T1-1
T1-2
T1-3
T1-4
Table name: T2
Table partition count: 3
T2-1
T2-2
T2-3
```
### 元数据跨两个区域,数据在同一区域
在此解决方案中,数据位于一个区域(2 个 DC),而元数据跨越两个区域。
DC1 和 DC2 一起用于处理读写服务,而位于第二区域的 DC3 是用来满足多数派协议的副本。这种架构也被称为“2-2-1”解决方案。
在极端情况下,DC1 和 DC2 都必须能够处理所有请求,因此请确保分配足够的资源。
网络延迟:
- 同一区域内延迟为 2ms
- 两个区域间延迟为 30ms
支持高可用性级别:
- 单个 AZ 不可用时性能相同
- 单个 DC 不可用时性能几乎相同
如果您想要一个区域级别的灾难恢复解决方案,可以更进一步,在 DC3 上提供读写服务。因此,下一个解决方案是:
### 数据跨两个区域
在此解决方案中,数据跨越两个区域。
每个数据中心必须能够在极端情况下处理所有请求,因此请确保分配足够的资源。
网络延迟:
- 同一区域内延迟为 2 毫秒
- 两个区域间延迟为 30 毫秒
支持高可用性级别:
- 单个可用区不可用时性能不变
- 单个数据中心不可用时性能下降
如果无法容忍单个数据中心故障导致的性能下降,请考虑升级到五个数据中心和三个区域的解决方案。
### 元数据跨三个区域,数据跨两个区域
在此解决方案中,数据跨越两个区域,而元数据跨越三个区域。
Region1 和 Region2 一起用于处理读写服务,而 Region3 是一个副本,用于满足多数派协议。这种架构也被称为“2-2-1”解决方案。
两个相邻的区域中的每一个都必须能够在极端情况下处理所有请求,因此请确保分配足够的资源。
网络延迟:
- 同一区域内延迟为 2ms
- 两个相邻区域之间延迟为 7ms
- 两个远距离区域之间延迟为 30ms
支持高可用性级别:
- 单一 AZ 不可用时性能不变
- 单一 DC 不可用时性能不变
- 单一区域(城市)不可用时性能略有下降
您可以更进一步,在三个区域上提供读写服务。因此,下一个解决方案是:
(此解决方案可能具有更高的延迟,如果无法接受,则不推荐。)
## 数据跨三个区域
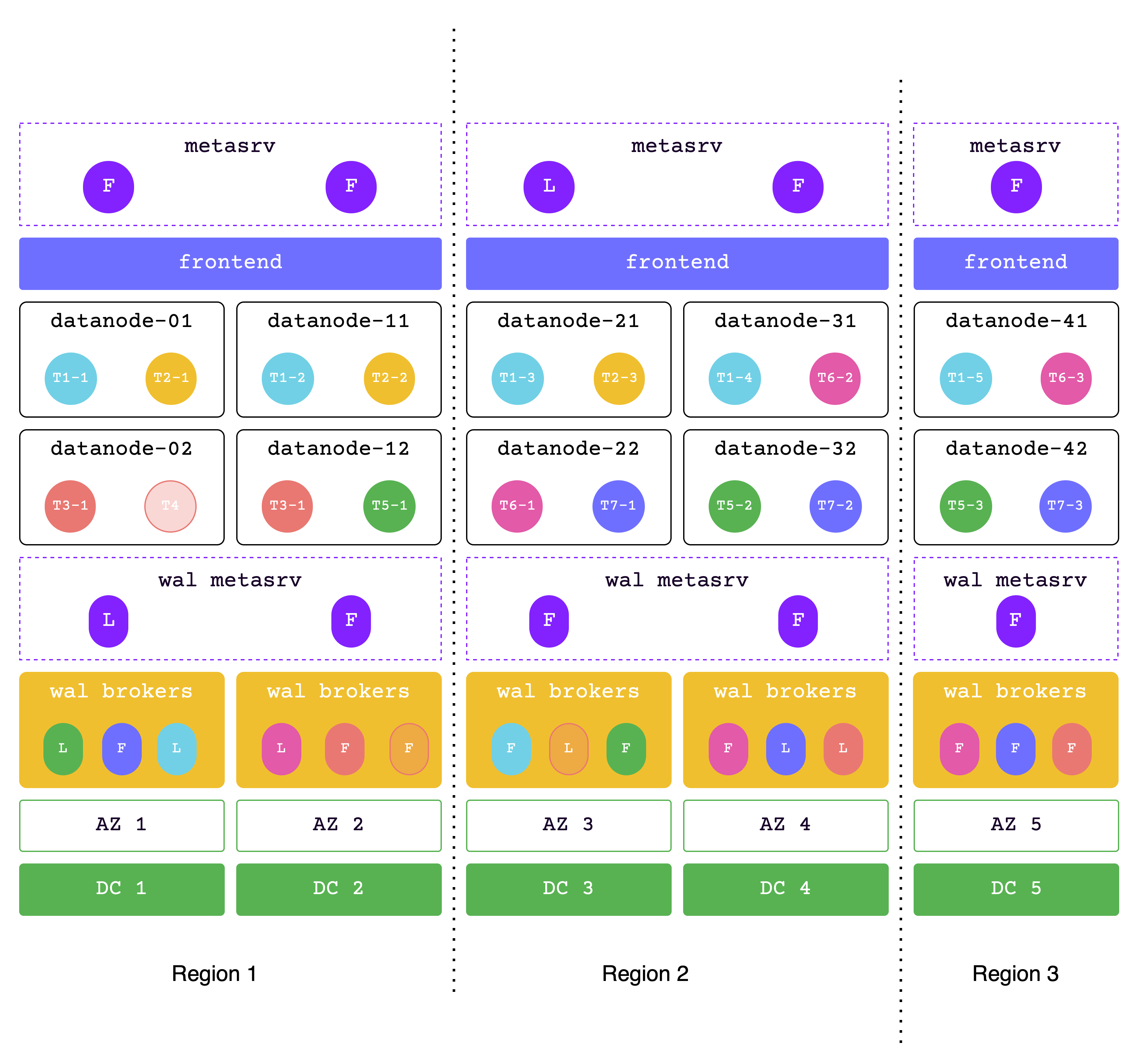
在此解决方案中,数据跨越三个区域。
如果一个区域发生故障,其他两个区域必须能够处理所有请求,因此请确保分配足够的资源。
网络延迟:
- 同一区域内延迟为 2 毫秒
- 相邻两个区域之间的延迟为 7 毫秒
- 两个远距离区域之间的延迟为 30 毫秒
支持高可用性级别:
- 单个 AZ 不可用时性能不变
- 单个 DC 不可用时性能不变
- 单个区域(城市)不可用时性能下降
## 解决方案比较
上述解决方案的目标是在中大型场景中满足高可用性和可靠性的要求。然而,在具体实施过程中,每种解决方案的成本和效果可能会有所不同。下表对每种解决方案进行了比较,以帮助你根据具体场景、需求和成本进行最终选择。
以下是内容格式化为表格:
| 解决方案 | 延迟 | 高可用性 |
| --- | --- | --- |
| 元数据跨两个区域,数据在同一区域 | - 同一区域内延迟 2 毫秒- 两个区域间延迟 30 毫秒 | - 单个 AZ 不可用时性能不变- 单个 DC 不可用时性能几乎不变 |
| 数据跨两个区域 | - 同一区域内延迟 2 毫秒- 两个区域间延迟 30 毫秒 | - 单个 AZ 不可用时性能不变- 单个 DC 不可用时性能下降 |
| 元数据跨三个区域,数据跨两个区域 | - 同一区域内延迟 2 毫秒- 相邻两个区域间延迟 7 毫秒- 两个远距离的区域间延迟 30 毫秒 | - 单个 AZ 不可用时性能不变- 单个 DC 不可用时性能不变- 单一区域(城市)不可用时,性能略有下降 |
| 数据跨三个区域 | - 同一区域内延迟 2 毫秒- 相邻两个区域间延迟 7 毫秒- 两个远距离的区域间延迟 30 毫秒 | - 单个 AZ 不可用时性能不变- 单个 DC 不可用时性能不变 - 单一区域(城市)不可用时,性能下降 |
---
## GreptimeDB Standalone 的 DR 方案
---
## 灾难恢复
作为分布式数据库,GreptimeDB 提供了不同的灾难恢复(DR)解决方案。
本文档包括以下内容:
* DR 中的基本概念
* GreptimeDB 中备份与恢复(BR)的部署架构。
* GreptimeDB 的 DR 解决方案。
* DR 解决方案的比较。
## 基本概念
* **恢复时间目标(RTO)**:指灾难发生后业务流程可以停止的最长时间,而不会对业务产生负面影响。
* **恢复点目标(RPO)**:指自上一个数据恢复点以来可接受的最大时间量,决定了上一个恢复点和服务中断之间可接受的数据丢失量。
下图说明了这两个概念:
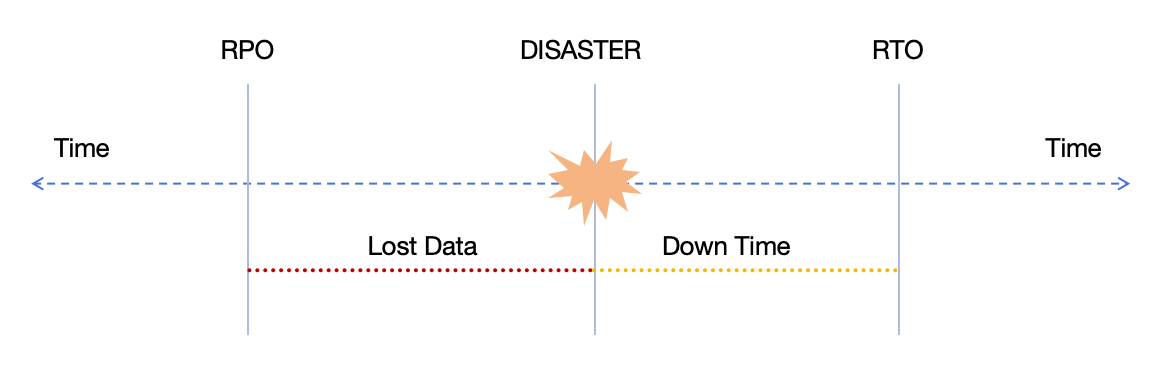
* **预写式日志(WAL)**:持久记录每个数据修改,以确保数据的完整性和一致性。
GreptimeDB 存储引擎是一个典型的 [LSM 树](https://en.wikipedia.org/wiki/Log-structured_merge-tree):
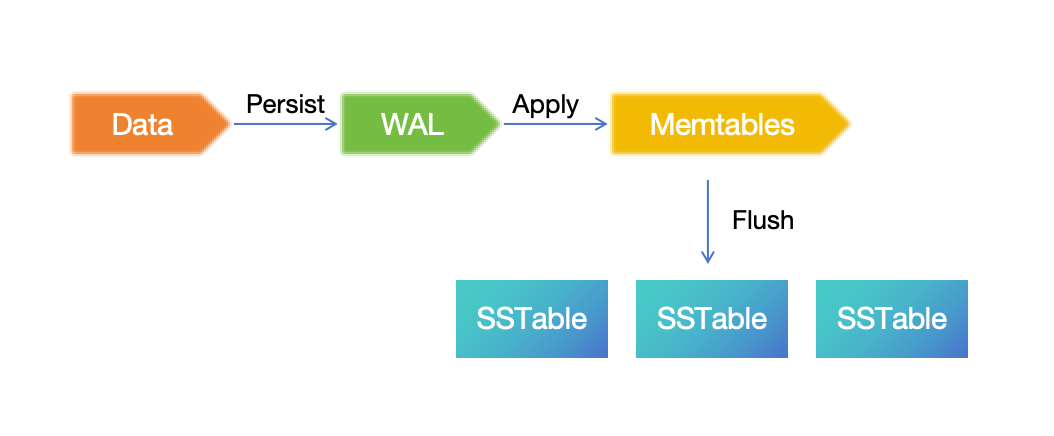
写入的数据首先持久化到 WAL,然后应用到内存中的 Memtable。
在特定条件下(例如超过内存阈值时),
Memtable 将被刷新并持久化为 SSTable。
因此,WAL 和 SSTable 的备份恢复是 GreptimeDB 灾难恢复的关键。
* **Region**:表的连续段,也可以被视为某些关系数据库中的分区。请阅读[表分片](/contributor-guide/frontend/table-sharding.md#region)以获取更多详细信息。
## 组件架构
### GreptimeDB
在深入了解具体的解决方案之前,让我们从灾难恢复的角度看一下 GreptimeDB 组件的架构:
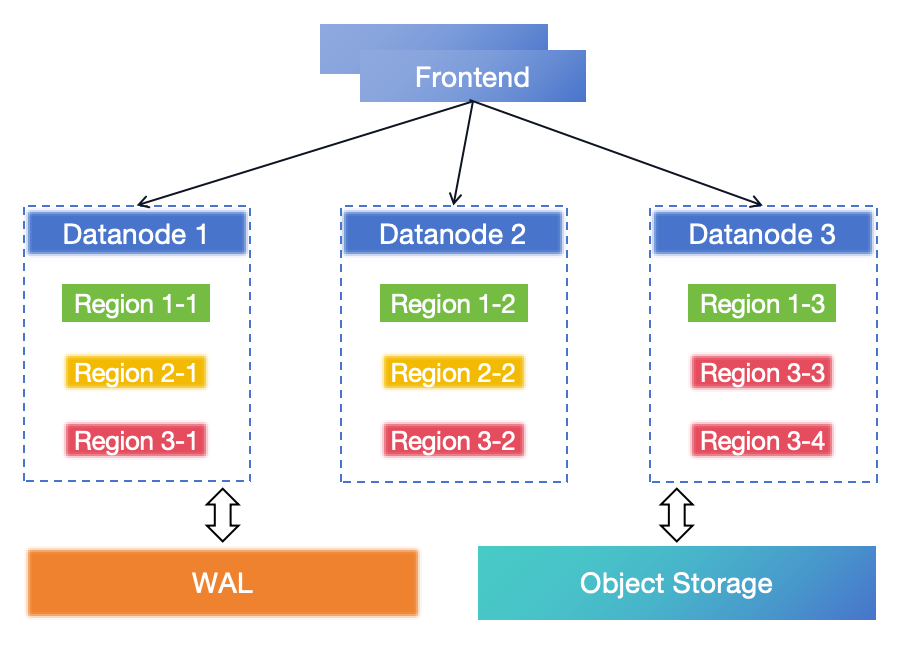
GreptimeDB 基于存储计算分离的云原生架构设计:
* **Frontend**:数据插入和查询的服务层,将请求转发到 Datanode 并处理和合并 Datanode 的响应。
* **Datanode**:GreptimeDB 的存储层,是一个 LSM 存储引擎。Region 是在 Datanode 中存储和调度数据的基本单元。Region 是一个表分区,是一组数据行的集合。Region 中的数据保存在对象存储中(例如 AWS S3)。未刷新的 Memtable 数据被写入 WAL,并可以在灾难发生时恢复。
* **WAL**:持久化内存中未刷新的 Memtable 数据。当 Memtable 被刷新到 SSTable 文件时,WAL 将被截断。它可以是基于本地磁盘的(本地 WAL)或基于 Kafka 集群的(远程 WAL)。
* **对象存储**:持久化 SSTable 数据和索引。
GreptimeDB 将数据存储在对象存储(如 [AWS S3](https://docs.aws.amazon.com/AmazonS3/latest/userguide/DataDurability.html))或兼容的服务中,这些服务在年度范围内提供了 99.999999999% 的持久性和 99.99% 的可用性。像 S3 这样的服务提供了[单区域或跨区域的复制](https://docs.aws.amazon.com/AmazonS3/latest/userguide/replication.html),天然具备灾难恢复能力。
同时,WAL 组件是可插拔的,例如使用 Kafka 作为 WAL 服务以提供成熟的[灾难恢复解决方案](https://www.confluent.io/blog/disaster-recovery-multi-datacenter-apache-kafka-deployments/)。
### 备份与恢复
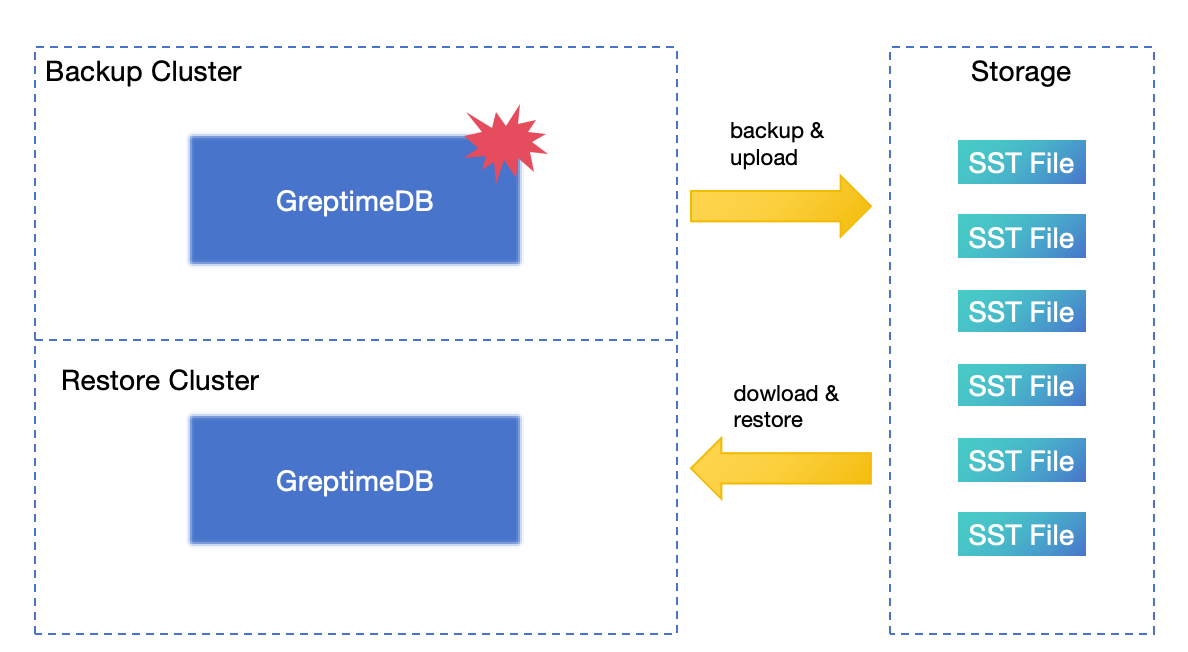
备份与恢复(BR)工具可以在特定时间对数据库或表进行完整快照备份,并支持增量备份。
当集群遇到灾难时,你可以使用备份数据恢复集群。
一般来说,BR 是灾难恢复的最后手段。
## 解决方案介绍
### GreptimeDB Standalone 的 DR 方案
如果 GreptimeDB Standalone 在本地磁盘上运行 WAL 和数据,那么:
* RPO:取决于备份频率。
* RTO:在 Standalone 没有意义,主要取决于要恢复的数据大小、故障响应时间和操作基础设施。
选择将 GreptimeDB Standalone 部署到具有备份和恢复解决方案的 IaaS 平台中是一个很好的开始,例如亚马逊 EC2(结合 EBS 卷)提供了全面的[备份和恢复解决方案](https://docs.aws.amazon.com/zh_cn/prescriptive-guidance/latest/backup-recovery/backup-recovery-ec2-ebs.html)。
但是如果使用远程 WAL 和对象存储运行 Standalone,有一个更好的 DR 解决方案:
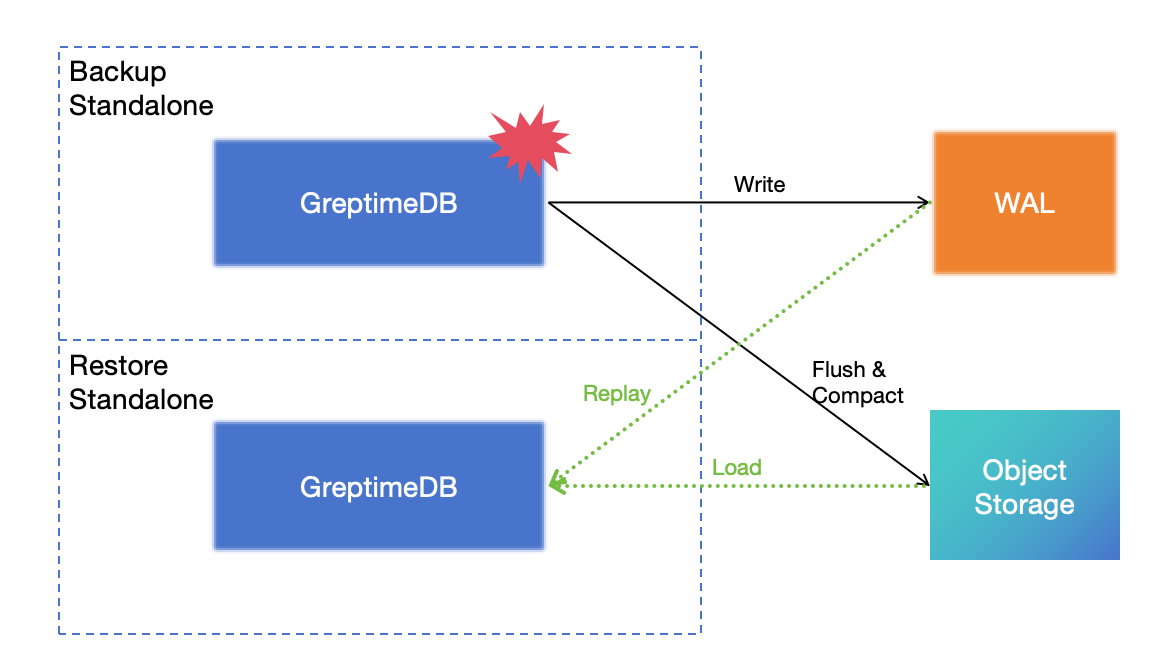
将 WAL 写入 Kafka 集群,并将数据存储在对象存储中,因此数据库本身是无状态的。
在影响独立数据库的灾难事件发生时,你可以使用远程 WAL 和对象存储来恢复它。
此方案能实现 RPO=0 和分钟级 RTO。
### 基于双活互备的 DR 解决方案
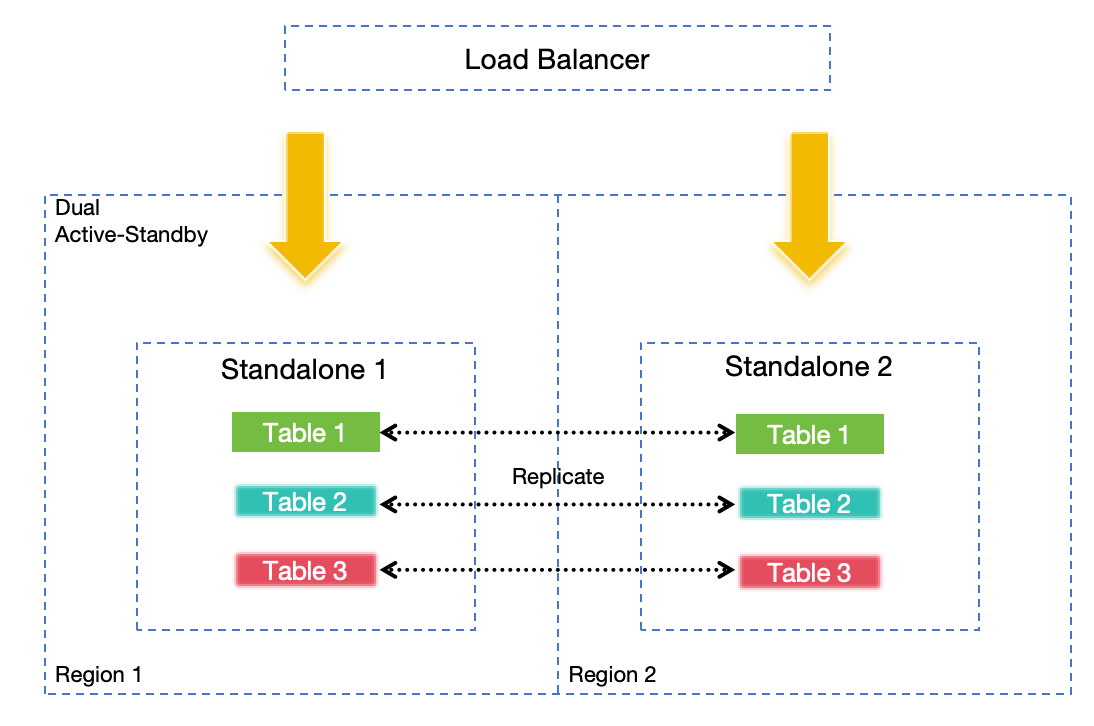
在某些边缘或中小型场景中,或者如果你没有资源部署远程 WAL 或对象存储,双活互备相对于 Standalone 的灾难恢复提供了更好的解决方案。
通过在两个独立节点之间同步复制请求,确保了高可用性。
即使使用基于本地磁盘的 WAL 和数据存储,任何单个节点的故障也不会导致数据丢失或服务可用性降低。
在不同区域部署节点也可以满足区域级灾难恢复要求,但可扩展性有限。
:::tip 注意
**双活互备功能仅在 GreptimeDB 企业版中提供。**
:::
有关此解决方案的更多信息,请参阅[基于双活 - 备份的 DR 解决方案](/enterprise/deployments-administration/disaster-recovery/dr-solution-based-on-active-active-failover.md)。
### 基于单集群跨区域部署的 DR 解决方案
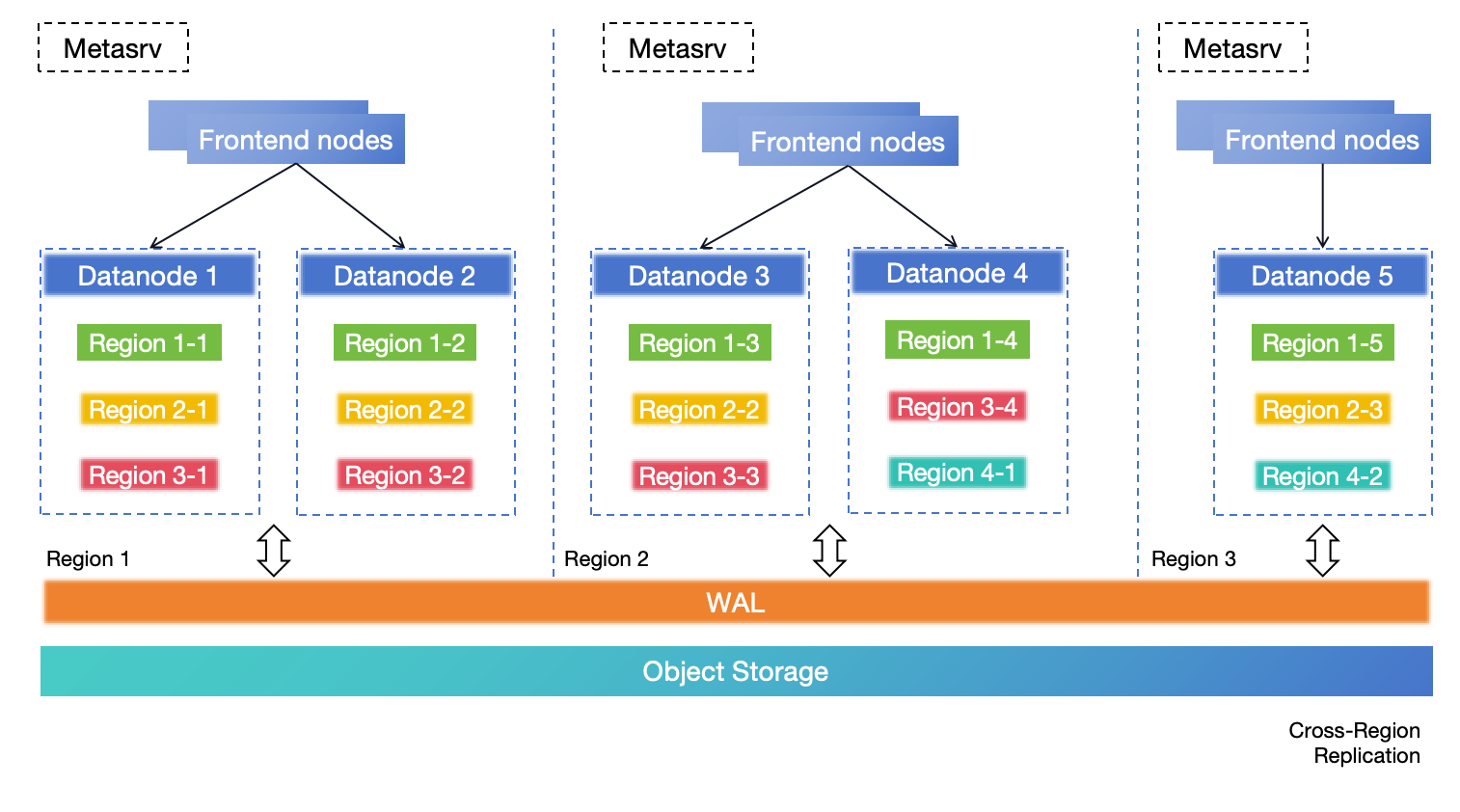
对于需要零 RPO 的中大型场景,强烈推荐此解决方案。
在此部署架构中,整个集群跨越三个 Region,每个 Region 都能处理读写请求。
两者都必须启用跨 Region DR 并使用远程 WAL 和对象存储实现数据复制。
如果 Region 1 因灾难而完全不可用,其中的表 Region 将在其他 Region 中打开和恢复。
Region 3 作为副本遵循 Metasrv 的多种协议。
此解决方案提供 Region 级别的容错、可扩展的写入能力、零 RPO 和分钟级或更低的 RTO。
有关此解决方案的更多信息,请参阅[基于单集群跨区域部署的 DR 解决方案](./dr-solution-based-on-cross-region-deployment-in-single-cluster.md)。
### 基于备份恢复的 DR 解决方案
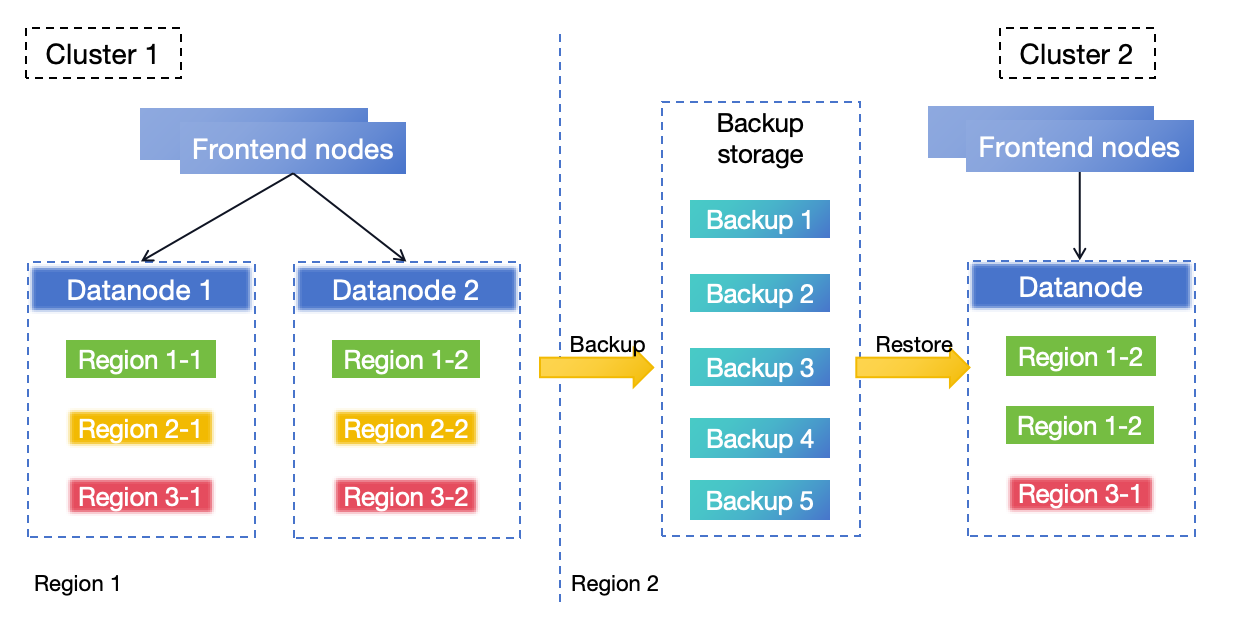
在此架构中,GreptimeDB Cluster 1 部署在 Region 1。
BR 进程持续定期将数据从 Cluster 1 备份到 Region 2。
如果 Region 1 遭遇灾难导致 Cluster 1 无法恢复,
你可以使用备份数据恢复 Region 2 中的新集群(Cluster 2)以恢复服务。
基于 BR 的 DR 解决方案提供的 RPO 取决于备份频率,RTO 随要恢复的数据大小而变化。
阅读[备份与恢复数据](./back-up-&-restore-data.md)获取详细信息。
### 解决方案比较
通过比较这些 DR 解决方案,你可以根据其特定场景、需求和成本选择最终的选项。
| DR 解决方案 | 容错目标 | RPO | RTO | TCO | 场景 | 远程 WAL 和对象存储 | 备注 |
| ------------- | ------------------------- | ----- | ----- | ----- | ---------------- | --------- | --------|
| 独立模式的 DR 解决方案 | 单区域 | 备份间隔 | 分钟或小时级 | 低 | 小型场景中对可用性和可靠性要求较低 | 可选 | |
| 基于双活互备的 DR 解决方案 | 跨区域 | 可配置 | 分钟级 | 低 | 中小型场景中对可用性和可靠性要求较高 | 可选 | 商业功能 |
| 基于单集群跨区域部署的 DR 解决方案 | 多区域 | 0 | 分钟级 | 高 | 中大型场景中对可用性和可靠性要求较高 | 必需 | |
| 基于 BR 的 DR 解决方案 | 单区域 | 备份间隔 | 分钟或小时级 | 低 | 可接受的可用性和可靠性要求 | 可选 | |
## 参考资料
* [备份与恢复数据](./back-up-&-restore-data.md)
* [基于双活 - 备份的 DR 解决方案](/enterprise/deployments-administration/disaster-recovery/dr-solution-based-on-active-active-failover.md)
* [基于单集群跨区域部署的 DR 解决方案](./dr-solution-based-on-cross-region-deployment-in-single-cluster.md)
* [S3 对象副本概述](https://docs.aws.amazon.com/AmazonS3/latest/userguide/replication.html)
---
## 集群维护模式
集群维护模式是 GreptimeDB 中的一个安全特性,用于临时禁止集群的自动调度操作。
该模式在以下情况下特别有用:
- 集群部署
- 集群升级
- 计划停机
- 任何可能暂时影响集群稳定性的操作
## 何时使用维护模式
### 使用 GreptimeDB Operator
如果你使用 GreptimeDB Operator 升级集群,你不需要手动启用维护模式。Operator 会自动处理。
### 不使用 GreptimeDB Operator
当不使用 GreptimeDB Operator 升级集群时,**在以下情况下必须手动启用 Metasrv 的维护模式**:
1. 部署新集群(在 metasrv 节点就绪后启用维护模式)
2. Datanode 节点滚动升级
3. Metasrv 节点升级
4. Frontend 节点升级
5. 任何可能暂时影响节点可用性的操作
在集群部署/升级完成后,你可以停用维护模式。
## 维护模式的影响
当维护模式启用时:
- Region Balancer(如果启用)将暂停
- Region Failover(如果启用)将暂停
- 手动操作/迁移 Region 仍然可行
- 集群读、写服务正常工作
- 监控和指标收集继续运行
## 管理维护模式
维护模式可以通过 Metasrv 的 HTTP 接口启用和禁用:`http://{METASRV}:{HTTP_PORT}/admin/maintenance/enable` 和 `http://{METASRV}:{HTTP_PORT}/admin/maintenance/disable`。请注意,此接口监听 Metasrv 的 `HTTP_PORT`,默认为 `4000`。
### 启用维护模式
:::danger
调用运维模式接口后,请务必检查接口返回的 HTTP 状态码为 200,并确认响应内容符合预期。如果出现异常或接口行为不符合预期,请谨慎操作,并避免继续执行集群升级等高风险操作。
:::
通过发送 POST 请求到 `/admin/maintenance/enable` 端点启用维护模式。
```bash
curl -X POST 'http://localhost:4000/admin/maintenance/enable'
```
预期输出:
```bash
{"enabled":true}
```
如果遇到任何问题或意外行为,请不要继续进行维护操作。
### 停用维护模式
:::danger
在关闭运维模式之前,必须确认**所有组件均已恢复至正常状态**。
:::
通过发送 POST 请求到 `/admin/maintenance/disable` 端点停用维护模式。
在停用维护模式之前:
1. 确保所有组件健康且正常运行
2. 验证所有节点是否正确加入集群
```bash
curl -X POST 'http://localhost:4000/admin/maintenance/disable'
```
预期输出:
```bash
{"enabled":false}
```
### 检查维护模式状态
通过发送 GET 请求到 `/admin/maintenance/status` 端点检查维护模式状态。
```bash
curl -X GET http://localhost:4000/admin/maintenance/status
```
预期输出:
```bash
{"enabled":false}
```
## 故障排除
### 常见问题
1. **无法启用维护模式**
- 验证 Metasrv 是否正在运行且可访问
- 检查你是否具有正确的权限
- 确保 HTTP 端口正确
### 最佳实践
1. 在操作前后始终验证维护模式状态
2. 准备好回滚计划
3. 监控集群健康状况
4. 记录所有维护期间进行的更改
---
## 防止元数据变更
要防止元数据变更,你可以暂停 Procedure Manager。此机制拒绝所有新 procedure(即新的元数据变更操作),同时允许现有 procedure 继续运行。
一旦启用,Metasrv 将拒绝以下 procedure 操作(包括不限于):
**DDL 操作:**
- 创建表
- 删除表
- 修改表
- 创建数据库
- 删除数据库
- 创建视图
- 创建 Flow
- 删除 Flow
**Region 调度操作:**
- Region Migration
- Region Failover (如果启用)
- Region Balancer (如果启用)
你在启用暂停元数据变更功能后尝试执行这些操作时,可能会看到错误消息。对于 Region 调度操作,你可以启用 [集群维护模式](/user-guide/deployments-administration/maintenance/maintenance-mode.md) 来临时暂时它们。
## 管理 Procedure Manager
Procedure Manager 可以通过 Metasrv 的 HTTP 接口暂停和恢复:`http://{METASRV}:{HTTP_PORT}/admin/procedure-manager/pause` 和 `http://{METASRV}:{HTTP_PORT}/admin/procedure-manager/resume`。请注意,此接口监听 Metasrv 的 `HTTP_PORT`,默认为 `4000`。
### 暂停 Procedure Manager
通过向 `/admin/procedure-manager/pause` 端点发送 POST 请求来暂停 Procedure Manager。
```bash
curl -X POST 'http://localhost:4000/admin/procedure-manager/pause'
```
预期输出:
```bash
{"status":"paused"}
```
### 恢复 Procedure Manager
通过向 `/admin/procedure-manager/resume` 端点发送 POST 请求来恢复 Procedure Manager。
```bash
curl -X POST 'http://localhost:4000/admin/procedure-manager/resume'
```
预期输出:
```bash
{"status":"running"}
```
### 检查 Procedure Manager 状态
通过向 `/admin/procedure-manager/status` 端点发送 GET 请求来检查 Procedure Manager 状态。
```bash
curl -X GET 'http://localhost:4000/admin/procedure-manager/status'
```
预期输出:
```bash
{"status":"running"}
```
---
## 集群恢复模式
恢复模式是 GreptimeDB 提供的一项安全机制,使开发者能够在集群出现故障时,手动将其恢复至正常状态。
## 何时使用恢复模式
恢复模式在 Datanode 启动失败时特别有用,通常是由于 "Empty region directory" 错误,这可能是由于:
- Datanode 数据损坏(缺少 Region 数据目录)
- 从元数据快照恢复集群
## 恢复模式管理
恢复模式可以通过 Metasrv 的 HTTP 接口启用和禁用:`http://{METASRV}:{HTTP_PORT}/admin/recovery/enable` 和 `http://{METASRV}:{HTTP_PORT}/admin/recovery/disable`。请注意,此接口监听 Metasrv 的 `HTTP_PORT`,默认为 `4000`。
### 启用恢复模式
通过发送 POST 请求到 `/admin/recovery/enable` 端点启用恢复模式。
```bash
curl -X POST 'http://localhost:4000/admin/recovery/enable'
```
预期输出:
```bash
{"enabled":true}
```
### 禁用恢复模式
通过发送 POST 请求到 `/admin/recovery/disable` 端点禁用恢复模式。
```bash
curl -X POST 'http://localhost:4000/admin/recovery/disable'
```
预期输出:
```bash
{"enabled":false}
```
### 检查恢复模式状态
通过发送 GET 请求到 `/admin/recovery/status` 端点检查恢复模式状态。
```bash
curl -X GET 'http://localhost:4000/admin/recovery/status'
```
预期输出:
```bash
{"enabled":false}
```
---
## 资源标识(ID)管理
资源标识(ID)管理主要用于在从[元数据备份](/user-guide/deployments-administration/manage-metadata/restore-backup.md)恢复集群时,手动设置资源标识(如表 ID)。这是因为备份文件可能未包含最新的`待分配表 ID`值,如果不及时重置,可能会导致资源冲突或数据不一致。
### 理解表 ID 及 待分配表 ID 的关系
在 GreptimeDB 中:
- **表 ID**:每个表都有一个唯一的数字标识符,用于数据库内部识别和管理表
- **待分配表 ID(Next Table ID)**:系统预留的下一个可用的表 ID 值。当创建新表时,系统会自动分配这个 ID 给新表,然后将`待分配表 ID`递增
**举例说明:**
- 假设当前集群中已有表 ID 为 1001、1002、1003 的表
- 此时`待分配表 ID`应该是 1004
- 当创建新表时,系统分配 ID 1004 给新表,并将`待分配表 ID`更新为 1005
- 如果从备份恢复时,`待分配表 ID`仍然是 1002,就会与现有表 ID 1002、1003 产生冲突(通常你会在 Datanode 启动时遇到 `Region 1024 is corrupted, reason: ` 的错误)
通常情况下,资源标识(ID)由数据库自动维护,无需人工干预。但在某些特殊场景下(如从元数据备份恢复集群,且备份后集群又创建了新表),备份中的`待分配表 ID`可能已经落后于实际集群状态,此时需要手动调整。
**如何判断是否需要手动设置`待分配表 ID`:**
1. 查询当前集群中所有表的 ID:`SELECT TABLE_ID FROM INFORMATION_SCHEMA.TABLES ORDER BY TABLE_ID DESC LIMIT 1;`
2. 通过 API 获取当前的`待分配表 ID`(见下方接口说明)
3. 如果现有表 ID 的最大值大于等于当前的`待分配表 ID`,则需要手动设置`待分配表 ID`为一个更大的值。通常为现有表 ID 的最大值加 1。
你可以通过 Metasrv 的 HTTP 接口获取或设置`待分配的表 ID`:`http://{METASRV}:{HTTP_PORT}/admin/sequence/table/next-id`(获取)和 `http://{METASRV}:{HTTP_PORT}/admin/sequence/table/set-next-id`(设置)。请注意,此接口监听 Metasrv 的 `HTTP_PORT`,默认为 `4000`。
### 设置待分配的表 ID
要安全地更新`待分配的表 ID`,请按照以下步骤操作:
1. **启用集群恢复模式** - 这可以防止在更新过程中创建新表。详情请参阅[集群恢复模式](/user-guide/deployments-administration/maintenance/recovery-mode.md)。
2. **设置待分配的表 ID** - 通过 HTTP 接口设置`待分配的表 ID`。
3. **重启 metasrv 节点** - 这确保新的`待分配的表 ID`被正确设置。
4. **禁用集群恢复模式** - 恢复正常的集群操作。
通过发送 POST 请求到 `/admin/sequence/table/set-next-id` 端点设置`待分配的表 ID`:
```bash
curl -X POST 'http://localhost:4000/admin/sequence/table/set-next-id' \
-H 'Content-Type: application/json' \
-d '{"next_table_id": 2048}'
```
预期输出(`next_table_id` 可能不同):
```bash
{"next_table_id":2048}
```
### 获取待分配的表 ID
```bash
curl -X GET 'http://localhost:4000/admin/sequence/table/next-id'
```
预期输出(`next_table_id` 可能不同):
```bash
{"next_table_id":1254}
```
---
## 表元数据修复
## 概述
在 GreptimeDB 分布式环境中,系统采用了分层的元数据管理架构:
- **Metasrv**:作为元数据管理层,负责维护集群中所有表的元信息
- **Datanode**:负责实际的数据存储和查询执行,同时会持久化部分表元信息
在理想情况下,Metasrv 和 Datanode 的表元信息应该保持完全一致。但在实际生产环境中,从[元数据备份](/user-guide/deployments-administration/manage-metadata/restore-backup.md)恢复集群的操作可能会导致元数据不一致。
**Table Reconciliation** 是 GreptimeDB 提供的表元数据修复机制,用于:
- 检测 Metasrv 与 Datanode 之间的元信息差异
- 根据预定义的策略修复不一致问题
- 确保系统能够从异常状态恢复到一致、可用的状态
## 在开始之前
在开始表元数据修复之前,你需要:
1. 从[元数据备份](/user-guide/deployments-administration/manage-metadata/restore-backup.md)中恢复集群
2. 将[待分配表 ID](/user-guide/deployments-administration/maintenance/sequence-management.md) 设置为原集群的待分配表 ID
## 修复场景
### `Table not found` 错误
当集群从特定元数据恢复后,写入和查询可能出现 `Table not found` 错误。
- **场景一**:原集群在备份元数据后新增了表,导致新增表的元数据没有包含在备份中,从而查询这些新增表时出现 `Table not found` 错误。这种情况下,新建表将丢失,同时你必须手动设置 [待分配表 ID](/user-guide/deployments-administration/maintenance/sequence-management.md),确保恢复后的集群在新创建表时不会因为表 ID 冲突导致创建失败。
- **场景二**:原集群在备份元数据后将原有表重命名,这种情况下新表名将丢失。
### `Empty region directory` 错误
当集群从特定元数据恢复后,启动 Datanode 时出现 `Empty region directory` 错误。这通常是因为原集群在备份元数据后删除了表(即执行 `DROP TABLE`),导致删除表的元数据没有包含在备份中,从而启动 Datanode 时出现该错误。针对这种情况,你需要在启动集群时,在 Metasrv 启动后开启 [Recovery Mode](/user-guide/deployments-administration/maintenance/recovery-mode.md),确保 Datanode 可以正常启动。
- **Mito Engine 表**:表元信息不可修复,需要手动执行 `DROP TABLE` 命令删除不存在的表。
- **Metric Engine 表**:表元信息可以修复,需要手动执行 `ADMIN reconcile_table('table_name')` 命令修复表元信息。
### `No field named` 错误
当集群从特定元数据恢复后,写入和查询可能出现 `No field named` 错误。这通常是因为原集群在备份元数据后删除了列(即执行 `DROP COLUMN`),导致删除列的元数据没有包含在备份中,从而查询这些已删除列时出现该错误。针对这种情况,你需要手动执行 `ADMIN reconcile_table('table_name')` 命令修复表元信息。
### `schema has a different type` 错误
当集群从特定元数据恢复后,写入和查询可能出现 `schema has a different type` 错误。这通常是因为原集群在备份元数据后修改了列类型(即执行 `MODIFY COLUMN [column_name] [type]`),导致修改列类型的元数据没有包含在备份中,从而查询这些修改后的列时出现该错误。针对这种情况,你需要手动执行 `ADMIN reconcile_table('table_name')` 命令修复表元信息。
### 缺少特定列
当集群从特定元数据恢复后,写入和查询可能正常运行,但是未包含一些列。这是因为原集群在备份元数据后新增了列(即执行 `ADD COLUMN`),导致新增列的元数据未包含在备份中,从而查询时无法列出这些列。针对这种情况,你需要手动执行 `ADMIN reconcile_table('table_name')` 命令修复表元信息。
### 列缺少索引
当集群从特定元数据恢复后,写入和查询可能正常运行,但是 `SHOW CREATE TABLE`/`SHOW INDEX FROM [table_name]` 显示某些列未包含预期索引。这是因为原集群在备份元数据后修改了索引(即执行 `MODIFY INDEX [column_name] SET [index_type] INDEX`),导致索引变更后的元数据未包含在备份中。针对这种情况,你需要手动执行 `ADMIN reconcile_table('table_name')` 命令修复表元信息。
## 修复操作
GreptimeDB 提供了以下 Admin 函数用于触发表元数据修复:
### 修复所有表
修复整个集群中所有表的元数据不一致问题:
```sql
ADMIN reconcile_catalog()
```
### 修复指定数据库
修复指定数据库中所有表的元数据不一致问题:
```sql
ADMIN reconcile_database('database_name')
```
### 修复指定表
修复单个表的元数据不一致问题:
```sql
ADMIN reconcile_table('table_name')
```
### 查看修复进度
上述 Admin 函数执行后会返回一个 `ProcedureID`,你可以通过以下命令查看修复任务的执行进度:
```sql
ADMIN procedure_state('procedure_id')
```
当 `procedure_state` 返回 Done 时,标识修复任务完成。
## 注意事项
在执行表元数据修复操作时,请注意以下几点:
- 修复操作是异步执行的,可以通过 `procedure_id` 查看执行进度
- 建议在业务低峰期执行修复操作,以减少对系统性能的影响
- 对于大规模的修复操作(如 `reconcile_catalog()`),建议先在测试环境验证
---
## 表的基本操作
在阅读本文档之前请先阅读 [数据模型](/user-guide/concepts/data-model.md).
GreptimeDB 通过 SQL 提供了表管理的功能,下面通过 [MySQL Command-Line Client](https://dev.mysql.com/doc/refman/8.0/en/mysql.html) 来演示它。
以下部分更详细的关于 SQL 语法的解释,请参考 [SQL reference](/reference/sql/overview.md)。
## 创建数据库
默认的数据库是 `public`,可以手动创建一个数据库。
```sql
CREATE DATABASE test;
```
```sql
Query OK, 1 row affected (0.05 sec)
```
创建一个具有 7 天 `TTL`(数据存活时间)的数据库,也就是该数据库中的所有表如果没有单独设置 TTL 选项,都将继承此选项值。
```sql
CREATE DATABASE test WITH (ttl='7d');
```
列出所有现有的数据库。
```sql
SHOW DATABASES;
```
```sql
+--------------------+
| Database |
+--------------------+
| greptime_private |
| information_schema |
| public |
| test |
+--------------------+
4 rows in set (0.00 sec)
```
使用 `like` 语法:
```sql
SHOW DATABASES LIKE 'p%';
```
```sql
+----------+
| Database |
+----------+
| public |
+----------+
1 row in set (0.00 sec)
```
然后更改数据库:
```sql
USE test;
```
## 创建表
:::tip NOTE
注意:GreptimeDB 提供了一种 schemaless 方法来写入数据,不需要使用额外的协议手动创建表。参见 [自动生成表结构](/user-guide/ingest-data/overview.md#自动生成表结构)\*\*。
:::
如果您有特殊需要,仍然可以通过 SQL 手动创建表。假设我们想要创建一个名为 `monitor` 的表,其数据模型如下:
- `host` 是独立机器的主机名,是 `Tag` 列,用于在查询时过滤数据。
- `ts` 是收集数据的时间,是 `Timestamp` 列。它也可以在查询数据时用作时间范围的过滤器。
- `cpu` 和 `memory` 是机器的 CPU 利用率和内存利用率,是包含实际数据且未索引的 `Field` 列。
创建表的 SQL 代码如下。在 SQL 中,我们使用 PRIMARY KEY 来指定 `Tag`,使用 `TIME INDEX` 来指定 `Timestamp` 列,其余列是 `Field`。
```sql
CREATE TABLE monitor (
host STRING,
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP() TIME INDEX,
cpu FLOAT64 DEFAULT 0,
memory FLOAT64,
PRIMARY KEY(host));
```
```sql
Query OK, 0 row affected (0.03 sec)
```
创建一个具有 7 天 `TTL`(数据存活时间)的表:
```sql
CREATE TABLE monitor (
host STRING,
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP() TIME INDEX,
cpu FLOAT64 DEFAULT 0,
memory FLOAT64,
PRIMARY KEY(host)
) WITH (ttl='7d');
```
:::warning NOTE
GreptimeDB 目前不支持在创建表后更改 TIME INDEX 约束,
因此,在创建表之前,仔细选择适当的 TIME INDEX 列。
:::
### `CREATE TABLE` 语法
- 时间戳列:GreptimeDB 是一个时序数据库系统,在创建表时,必须用 `TIME INDEX` 关键字明确指定时间序列的列。
时间序列的列的数据类型必须是 `TIMESTAMP`。
- 主键:`Primary key`指定的主键列类似于其他时序系统中的 Tag,比如 [InfluxDB][1]。主键和时间戳列用于唯一地定义一条时间线,这类似于其他时间序列系统中的时间线的概念,如 [InfluxDB][2]。
- 表选项:当创建一个表时,可以指定一组表选项,点击[这里](/reference/sql/create.md#table-options)了解更多细节。
### 表名约束
GreptimeDB 支持在表名中使用有限的特殊字符,但必须遵守以下约束:
- 有效的 GreptimeDB 表名必须以字母(小写或大写)或 `-` / `_` / `:` 开头。
- 表名的其余部分可以是字母数字或以下特殊字符:`-` / `_` / `:` / `@` / `#`。
- 任何包含特殊字符的表名都必须用反引号括起来。
- 任何包含大写字母的表名都必须用反引号括起来。
以下是有效和无效表名的例子:
```sql
-- ✅ Ok
create table a (ts timestamp time index);
-- ✅ Ok
create table a0 (ts timestamp time index);
-- 🚫 Invalid table name
create table 0a (ts timestamp time index);
-- 🚫 Invalid table name
create table -a (ts timestamp time index);
-- ✅ Ok
create table `-a` (ts timestamp time index);
-- ✅ Ok
create table `a@b` (ts timestamp time index);
-- 🚫 Invalid table name
create table memory_HugePages (ts timestamp time index);
-- ✅ Ok
create table `memory_HugePages` (ts timestamp time index);
```
[1]: https://docs.influxdata.com/influxdb/v1.8/concepts/glossary/#tag-key
[2]: https://docs.influxdata.com/influxdb/v1/concepts/glossary/#series
## 描述表
显示表的详细信息:
```sql
DESC TABLE monitor;
```
```sql
+--------+----------------------+------+------+---------------------+---------------+
| Column | Type | Key | Null | Default | Semantic Type |
+--------+----------------------+------+------+---------------------+---------------+
| host | String | PRI | YES | | TAG |
| ts | TimestampMillisecond | PRI | NO | current_timestamp() | TIMESTAMP |
| cpu | Float64 | | YES | 0 | FIELD |
| memory | Float64 | | YES | | FIELD |
+--------+----------------------+------+------+---------------------+---------------+
4 rows in set (0.01 sec)
```
Semantic Type 列描述了表的数据模型。`host` 是 `Tag` 列,`ts` 是 `Timestamp` 列,`cpu` 和 `memory` 是 `Field` 列。
## 显示表定义和索引
使用 `SHOW CREATE TABLE table_name` 来获取创建表时的语句:
```sql
SHOW CREATE TABLE monitor;
```
```
+---------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+---------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| monitor | CREATE TABLE IF NOT EXISTS `monitor` (
`host` STRING NULL,
`ts` TIMESTAMP(3) NOT NULL DEFAULT current_timestamp(),
`cpu` DOUBLE NULL DEFAULT 0,
`memory` DOUBLE NULL,
TIME INDEX (`ts`),
PRIMARY KEY (`host`)
)
ENGINE=mito
|
+---------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
```
列出表中的所有索引:
```sql
SHOW INDEXES FROM monitor;
```
```sql
+---------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+-------------------------+---------+---------------+---------+------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
+---------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+-------------------------+---------+---------------+---------+------------+
| monitor | 1 | PRIMARY | 1 | host | A | NULL | NULL | NULL | YES | greptime-primary-key-v1 | | | YES | NULL |
| monitor | 1 | TIME INDEX | 1 | ts | A | NULL | NULL | NULL | NO | | | | YES | NULL |
+---------+------------+------------+--------------+-------------+-----------+-------------+----------+--------+------+-------------------------+---------+---------------+---------+------------+
```
有关 `SHOW` 语句的更多信息,请阅读 [SHOW 参考](/reference/sql/show.md#show)。
## 列出现有的表
可以使用 `show tables` 语句来列出现有的表
```sql
SHOW TABLES;
```
```sql
+----------------+
| Tables_in_test |
+----------------+
| monitor |
+----------------+
1 row in set (0.00 sec)
```
其目前只支持表名的过滤,可以通过表名字对其进行过滤。
```sql
SHOW TABLES LIKE monitor;
```
```sql
+----------------+
| Tables_in_test |
+----------------+
| monitor |
+----------------+
1 row in set (0.00 sec)
```
列出指定数据库中的表:
```sql
SHOW TABLES FROM test;
```
```sql
+----------------+
| Tables_in_test |
+----------------+
| monitor |
+----------------+
1 row in set (0.01 sec)
```
## 改动表
可以像在 MySQL 数据库中一样,改变现有表的模式
```sql
ALTER TABLE monitor ADD COLUMN label VARCHAR;
```
```sql
Query OK, 0 rows affected (0.03 sec)
```
```sql
ALTER TABLE monitor DROP COLUMN label;
```
```sql
Query OK, 0 rows affected (0.03 sec)
```
`ALTER TABLE` 语句还支持添加、删除、重命名列以及修改列的数据类型等更改。有关更多信息,请参阅[ALTER 参考指南](/reference/sql/alter.md)。
## 删除表
:::danger 危险操作
表删除后不可撤销!请谨慎操作!
:::
`DROP TABLE [db.]table` 用于删除 `db` 或当前正在使用的数据库中的表。
删除当前数据库中的表 `monitor`:
```sql
DROP TABLE monitor;
```
```sql
Query OK, 1 row affected (0.01 sec)
```
## 删除数据库
:::danger 危险操作
数据库删除后不可撤销!请谨慎操作!
:::
可以使用 `DROP DATABASE` 删除数据库。
例如,切换回 `public` 数据库并删除 `test` 数据库:
```sql
USE public;
DROP DATABASE test;
```
请前往 [DROP](/reference/sql/drop.md#drop-database) 文档了解更多内容。
## HTTP API
使用以下代码,通过 POST 方法创建一个表:
```shell
curl -X POST \
-H 'authorization: Basic {{authorization if exists}}' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d 'sql=CREATE TABLE monitor (host STRING, ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP(), cpu FLOAT64 DEFAULT 0, memory FLOAT64, TIME INDEX (ts), PRIMARY KEY(host))' \
http://localhost:4000/v1/sql?db=public
```
```json
{ "output": [{ "affectedrows": 0 }], "execution_time_ms": 10 }
```
关于 SQL HTTP 请求的更多信息,请参考 [API 文档](/user-guide/protocols/http.md#post-sql-语句)。
## 时区
SQL 客户端会话中指定的时区将影响创建或更改表时的默认时间戳值。
如果将时间戳列的默认值设置为不带时区的字符串,则该默认值会被自动添加客户端的时区信息。
有关客户端时区的影响,请参考 [写入数据](/user-guide/ingest-data/for-iot/sql.md#时区) 文档中的时区部分。
---
## Compaction
对于基于 LSM 树的数据库,压缩是极其关键的。它将重叠的碎片化 SST 文件合并成一个有序的文件,丢弃已删除的数据,同时显著提高查询性能。
从 v0.9.1 版本开始,GreptimeDB 提供了控制 SST 文件如何压缩的策略:时间窗口压缩策略(TWCS)和严格窗口压缩策略(SWCS)。
## 概念
让我们从 GreptimeDB 中压缩的核心概念开始介绍。
### SST 文件
当内存表刷新到持久存储(如磁盘和对象存储)时,会生成排序的 SST 文件。
在 GreptimeDB 中,SST 文件中的数据行按[tag 列](/user-guide/concepts/data-model.md)和时间戳组织,如下所示。每个 SST 文件覆盖特定的时间范围。当查询指定一个时间范围时,GreptimeDB 只检索可能包含该范围内数据的相关 SST 文件,而不是加载所有已持久化的文件。
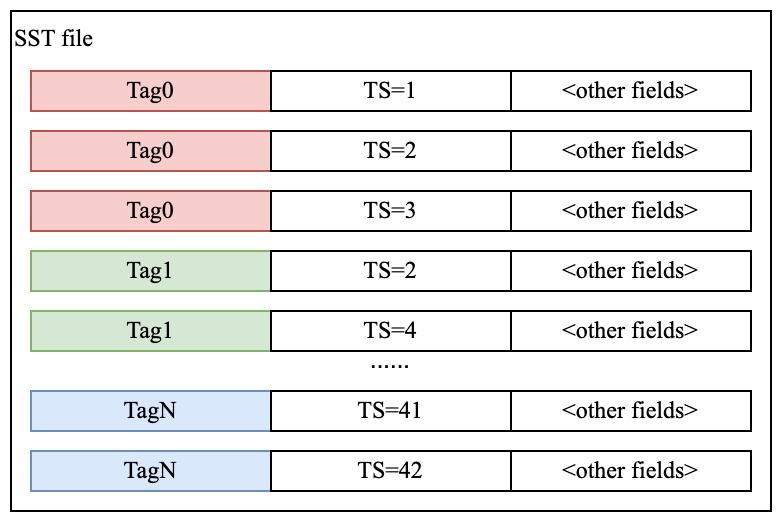
通常,在实时写入工作负载中,SST 文件的时间范围不会重叠。然而,由于数据删除和乱序写入等因素,SST 文件可能会有重叠的时间范围,这会影响查询性能。
### 时间窗口
时间序列工作负载呈现出显著的“窗口”特征,即最近插入的行更有可能被读取。因此,GreptimeDB 将时间轴逻辑上划分为不同的时间窗口,我们更关注压缩那些落在同一时间窗口内的 SST 文件。
特定表的时间窗口参数通常是从最新 flush 到存储的 SST 文件推断出来的,或者如果选择了 TWCS,您可以在建表时手动指定时间窗口。
GreptimeDB 预设了一组窗口大小,它们是:
- 1 小时
- 2 小时
- 12 小时
- 1 天
- 1 周
如果未指定时间窗口大小,GreptimeDB 将使用 1 小时作为初始时间窗口并在第一次压缩时通过文件的时间分布推断窗口,通过从上述集合中选择**能够覆盖所有要压缩文件的整个时间跨度的**,**最小的**时间窗口作为时间窗口大小。
例如,在第一次压缩期间,所有输入 SST 文件的时间跨度为 4 小时,那么 GreptimeDB 将选择 12 小时作为该表的时间窗口,并将此参数持久化以便后续的压缩中使用。
### 有序组
有序组(sorted runs)是一个包含已排序且时间范围不重叠的 SST 文件的集合。
例如,一个表包含 5 个 SST,时间范围如下(全部包括在内):`[0, 10]`, `[12, 23]`, `[22, 25]`,`[24, 30]`,`[26,33]`,我们可以找到 2 个有序组:
有序组的数量往往能够反映 SST 文件的有序性。更多的有序组通常会导致查询性能变差,因为特定时间范围的查询往往会命中多个重叠的文件。压缩的主要目标是减少有序组的数量。
### 层级
基于 LSM 树的数据库常常有多个层级,数据的键(key)会逐层进行合并。GreptimeDB 只有两个层级,分别是 0(未压缩)和 1(已压缩)。
## 压缩策略
GreptimeDB 提供了上述两种压缩策略,但在创建表时只能选择时间窗口压缩策略(TWCS)。严格窗口(SWCS)仅在执行手动压缩时可用。
## 时间窗口压缩策略(TWCS)
TWCS 主要旨在减少压缩过程中的读 / 写放大。
TWCS 将要压缩的文件分配到不同的时间窗口。对于每个窗口,TWCS 会识别有序组。如当前出现了多于一个有序组,TWCS 会基于合并开销来计算一个文件合并策略,从而将有序组的数量减少到 1。如果有序组的数量没有超过 1(也就是任意两个文件的时间范围都不重叠),TWCS 会检查是否存在过多的文件碎片,并在必要时合并这些碎片文件,因为 SST 文件数量也会影响查询性能。
对于窗口分配,SST 文件可能跨越多个时间窗口。为了确保不受陈旧数据影响,TWCS 根据 SST 的最大时间戳来进行分配。在时间序列工作负载中,无序写入很少发生,即使发生了,最近数据的查询性能也比陈旧数据更为重要。
常用的 TWCS 表级参数包括:
- `trigger_file_num`: 单一时间窗口中触发 compaction 的文件数量(默认为 4)
- `time_window`: TWCS compaction 的时间窗口大小
- `max_output_file_size`: compaction 产生文件的最大大小(默认 512MB)
以下图表显示了当 `trigger_file_num`为 3 时,窗口中的文件如何被压缩:
- 在 A 中,有两个 SST 文件 `[0, 3]` 和 `[5, 6, 9]`,但只有一个有序组,因为这两个文件的时间范围不重叠。
- 在 B 中,一个新的 SST 文件 `[1, 4]` 被写入,因此形成了两个有序组。然后将 `[0, 3]` 和 `[1, 4]` 合并为 `[0, 1, 3, 4]`。
- 在 C 中,一个新的 SST 文件 `[9, 10]` 被写入,它将与 `[5, 6, 10]` 合并以创建 `[5, 6, 9, 10]`,经过压缩后文件将变成 D 中的样子。
- 在 E 中,一个新文件 `[11, 12]` 被写入。尽管仍然只有一个有序组,但文件数量达到了 `trigger_file_num`(3),因此将会把 `[5, 6, 9,10]` 与 `[11,12]` 合并形成 `[5,6,9,10,11,12 ]`.
### 指定 TWCS 参数
TWCS 参数可以在两个级别指定:
1. **表级别**:在创建或修改表时明确设置
2. **数据库级别**:为数据库中的所有表设置默认值
有效的压缩设置在压缩调度时动态解析,优先级如下:
- 表级别设置(如果指定)
- 数据库级别设置(如果指定且没有表级别覆盖)
- 内置默认值
#### 表级别压缩设置
用户可以在创建表时指定 TWCS 参数:
```sql
CREATE TABLE monitor (
host STRING,
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP() TIME INDEX,
cpu FLOAT64 DEFAULT 0,
memory FLOAT64,
PRIMARY KEY(host))
WITH (
'compaction.type'='twcs',
'compaction.twcs.trigger_file_num'='8',
'compaction.twcs.time_window'='1h',
'compaction.twcs.max_output_file_size'='500MB'
);
```
#### 数据库级别压缩设置
您也可以为数据库中的所有表设置默认压缩参数。这些设置将被没有明确设置压缩选项的表继承。参见 [ALTER DATABASE](/reference/sql/alter.md#修改数据库的压缩选项) 获取示例。
:::note
与存储在表元数据中的表级别设置不同,数据库级别的压缩设置在运行时动态解析。更改数据库级别的压缩选项会立即影响数据库中所有没有明确设置压缩选项的表。此行为类似于[数据库级别的 TTL](/reference/sql/create.md#create-database) 的工作方式。
:::
## 严格窗口压缩策略(SWCS)和手动压缩
与 TWCS 根据 SST 文件的最大时间戳为每个窗口分配一个 SST 文件不同的是,严格窗口策略(SWCS)将 SST 文件分配给**所有与此文件的时间范围重叠**的窗口,正如其名称所示。因此,一个 SST 文件可能会包含在多个压缩输出中。由于其在压缩期间的高读取放大率,SWCS 并不是默认的压缩策略。然而,当用户需要手动触发压缩以重新组织 SST 文件布局时,它是有用的,特别是当单个 SST 文件跨越较大的时间范围而显著减慢查询速度时。GreptimeDB 提供了一个简单的 SQL 函数来触发手动压缩:
```sql
ADMIN COMPACT_TABLE(
,
,
[]
);
```
`` 参数可以是 `regular`(或 `twcs`)来指定常规 TWCS compaction,也可以是 `swcs`(或 `strict_window`)来指定严格窗口压缩策略。该值大小写不敏感。
对于 `swcs` 策略, `` 可以指定:
- 用于拆分 SST 文件的窗口大小(以秒为单位)
- `parallelism` 参数用于控制压缩的并行度(默认为 1)
例如,触发使用 1 小时窗口的压缩:
```sql
ADMIN COMPACT_TABLE(
"monitor",
"swcs",
"3600"
);
+------------------------------------------------+
| ADMIN COMPACT_TABLE("monitor", "swcs", "3600") |
+------------------------------------------------+
| 0 |
+------------------------------------------------+
1 row in set (0.01 sec)
```
执行此语句时,GreptimeDB 会将每个 SST 文件按 1 小时(3600 秒)的时间跨度拆分成多个分块,并将这些分块合并为一个输出文件,确保没有重叠的文件。
你还可以指定 `parallelism` 参数来通过并发处理多个文件以加速压缩:
```sql
-- 使用默认时间窗口和并行度为 2 的 SWCS 压缩
ADMIN COMPACT_TABLE("monitor", "swcs", "parallelism=2");
-- 使用自定义时间窗口和并行度的 SWCS 压缩
ADMIN COMPACT_TABLE("monitor", "swcs", "window=1800,parallelism=2");
```
`parallelism` 参数同样适用于常规压缩:
```sql
-- 并行度为 2 的常规压缩
ADMIN COMPACT_TABLE("monitor", "regular", "parallelism=2");
```
下图展示了一次 SWCS 压缩的过程:
在图 A 中,有 3 个重叠的 SST 文件,分别是 `[0, 3]`(也就是包含 0、1、2、3 的时间戳)、`[3, 8]` 和 `[8, 10]`。
严格窗口压缩策略会将覆盖了窗口 0、4、8 的文件 `[3, 8]` 分别分配给 3 个窗口,从而分别和 `[0, 3]` 以及 `[8, 10]` 合并。
图 B 给出了最终的压缩结果,分别有 3 个文件: `[0, 3]`、`[4, 7]` 和 `[8, 10]`,它们彼此互相不重叠。
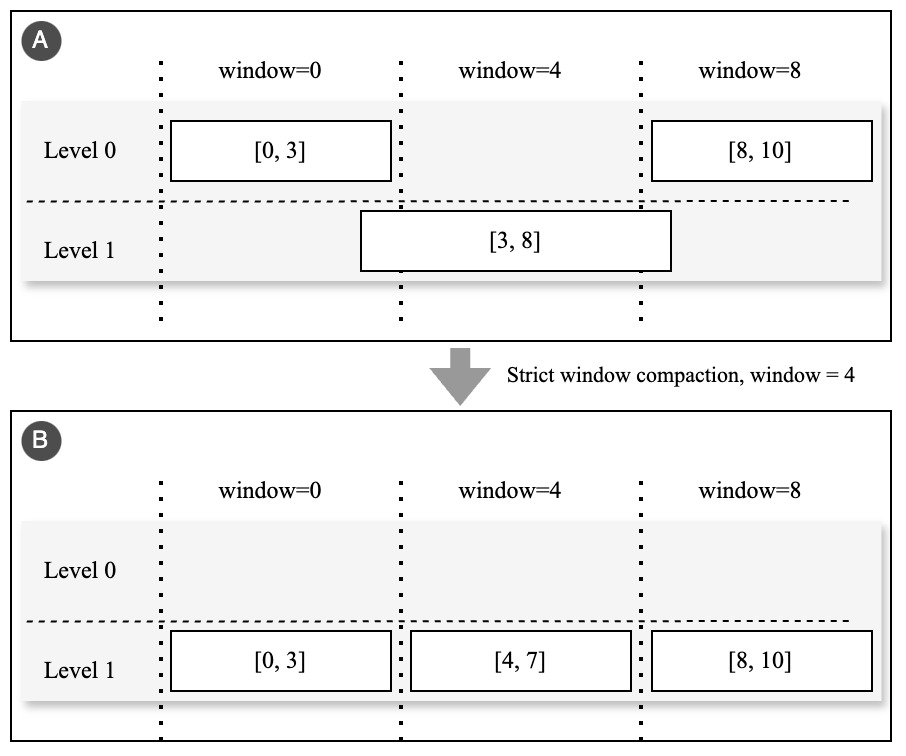
---
## 垃圾回收(GC)
GreptimeDB GC 会延迟删除 SST/索引文件,直到所有引用(运行中的查询、[repartition](./repartition.md) 的跨 region 文件引用)释放。配置包含两部分:
- Metasrv 配置
- Datanode 配置
## 工作原理
- **角色**:Meta 决定何时/何处清理;Datanode 负责实际删除,同时保护正在使用的文件。
- **安全窗口**:`lingering_time` 会额外保留已移除文件;`unknown_file_lingering_time` 用于极少见的保护场景。
- **列举模式**:快速模式删除系统已标记的文件;全量列举遍历对象存储以发现滞留/孤儿文件。

## Metasrv 配置
在 Metasrv 侧,GC 负责为各个 region 安排清理任务,并协调 GC 的运行时机。
```toml
[gc]
enable = true # 开启 meta GC 调度器,默认值为 false;必须与 datanode 一致。
gc_cooldown_period = "5m" # 同一 region 再次 GC 的最小间隔。
```
### 配置
| 配置项 | 说明 |
| --- | --- |
| `enable` | 启用 meta GC 调度器,必须与 datanode 的 GC 开关一致。 |
| `gc_cooldown_period` | 同一 region 再次被调度 GC 的最小间隔;请保证 datanode 的 `lingering_time` 大于该值。 |
## Datanode 配置
Datanode 负责实际删除,同时保护仍在使用中的文件。
```toml
[[region_engine]]
[region_engine.mito]
[region_engine.mito.gc]
enable = true # 开启 datanode GC worker;必须与 meta 一致。
lingering_time = "10m" # 已移除文件在活跃查询期间保留时长。
unknown_file_lingering_time = "1h" # 未记录 expel time 的文件保留时长;罕见保护。
```
### 配置
| 配置项 | 说明 |
| --- | --- |
| `enable` | 启用 datanode GC worker,必须与 meta GC 的 `enable` 一致。 |
| `lingering_time` | manifest 中已移除文件在删除前的保留时长,用于保护长时间 follower-region 查询/跨 region 引用;请设置为大于 `gc_cooldown_period`。设为 `"0s"` 表示立即删除。 |
| `unknown_file_lingering_time` | 对缺少 expel time 的文件的安全保留时间(未在 manifest 中追踪)。建议设置为较长值;此类情况较少。 |
:::warning
`gc.enable` 必须在 metasrv 与所有 datanode 上保持一致。开关不一致会导致 GC 被跳过或卡住。
:::
## 何时启用
- GC 仅在表使用对象存储时生效;本地文件系统上的表会忽略 GC 设置。
- 如果需要重分区,请开启 GC,以便跨 region 引用在删除前安全释放。
- 对于有长时间 follower-region 查询的集群,开启 GC 并将 `lingering_time` 设为大于 `gc_cooldown_period`,确保 GC 周期内创建或引用的文件保持存活(在用或 lingering)直到至少下个周期。
- 如果不进行重分区且不需要延迟删除,可保持 GC 关闭。
## 运维注意事项
- GC 面向对象存储后端(需支持 list/delete);确保存储凭据与权限允许列举和删除。
- 删除的文件会在对象存储中保留直到 GC 清理;确保具备列举/删除权限。
- 启用后重启 Metasrv 与 Datanode 以使配置生效。
---
## 管理数据
* [存储位置说明](/user-guide/concepts/storage-location.md)
* [表的基本操作](basic-table-operations.md): 如何创建、修改和删除表
* [更新或删除数据](/user-guide/manage-data/overview.md)
* [通过设置 TTL 过期数据](/user-guide/manage-data/overview.md#使用-ttl-策略保留数据)
* [表分片](table-sharding.md): 按 Region 对表进行分区
* [重分区](repartition.md): 调整已创建表的分区边界
* [Region Migration](region-migration.md): 为负载均衡迁移 Region
* [Region Failover](/user-guide/deployments-administration/manage-data/region-failover.md)
* [Compaction](compaction.md)
---
## Region Failover
Region Failover 提供了从 Region 故障中恢复的能力。使用 Kafka WAL (Remote WAL) 和共享存储时,Region Failover 可以在不丢失数据的情况下恢复 Region。这是通过 [Region 迁移](/user-guide/deployments-administration/manage-data/region-migration.md) 实现的。
## 开启 Region Failover
该功能仅在 GreptimeDB 集群模式下可用,并且需要满足以下条件
- 使用 Kafka WAL (Remote WAL),或者使用 Local WAL 并设置 `allow_region_failover_on_local_wal=true`(在 Local WAL 上启用 Region Failover,Failover 过程中可能会导致数据丢失)
- 使用[共享存储](/user-guide/deployments-administration/configuration.md#storage-options) (例如:AWS S3)
如果想要在本地 WAL 上启用 Region Failover,需要设置 `allow_region_failover_on_local_wal=true` 在 [metasrv](/user-guide/deployments-administration/configuration.md#metasrv-only-configuration) 配置文件中。不建议启用此选项,因为它可能会导致数据丢失。
### 通过配置文件
在 [metasrv](/user-guide/deployments-administration/configuration.md#metasrv-only-configuration) 配置文件中设置 `enable_region_failover=true`.
另外,你还需要将 `region_failure_detector_initialization_delay` 设置为较大的值,并在 `region_failure_detector_initialization_delay` 期间内,启动[集群维护模式](/user-guide/deployments-administration/maintenance/maintenance-mode.md),以避免在 Datanode 启动或升级期间触发不必要的 Region Failover。
### 通过 GreptimeDB Operator
要通过 GreptimeDB Operator 启用 Region Failover,可以参考 [常见 Helm Chart 配置项](/user-guide/deployments-administration/deploy-on-kubernetes/common-helm-chart-configurations.md#enable-region-failover) 了解更多详细信息。
## Region Failover 的恢复用时
使用 Kafka WAL (Remote WAL) 时,Region Failover 的恢复时间取决于:
- 每个 Topic 的 region 数量
- Kafka 集群的读取吞吐性能
### 读放大
在最佳实践中,[Kafka 集群所支持的 topics/partitions 数量是有限的](https://docs.aws.amazon.com/msk/latest/developerguide/bestpractices.html)(超过这个数量可能会导致 Kafka 集群性能下降)。
因此,GreptimeDB 允许多个 regions 共享一个 topic 作为 WAL,然而这可能会带来读放大的问题。
属于特定 Region 的数据由数据文件和 WAL 中的数据(通常为 WAL[LastCheckpoint...Latest])组成。特定 Region 的 failover 只需要读取该 Region 的 WAL 数据以重建内存状态,这被称为 Region 重放(region replaying)。然而,如果多个 Region 共享一个 Topic,则从 Topic 重放特定 Region 的数据需要过滤掉不相关的数据(即其他 Region 的数据)。这意味着从 Topic 重放特定 Region 的数据需要读取比该 Region 实际 WAL 数据大小更多的数据,这种现象被称为读取放大(read amplification)。
尽管多个 Region 共享同一个 Topic,可以让 Datanode 支持更多的 Region,但这种方法的代价是在 Region 重放过程中产生读取放大。
例如,为 [metasrv](/user-guide/deployments-administration/configuration.md#metasrv-only-configuration) 配置 128 个 Topic,如果整个集群包含 1024 个 Region(物理 Region),那么每 8 个 Region 将共享一个 Topic。
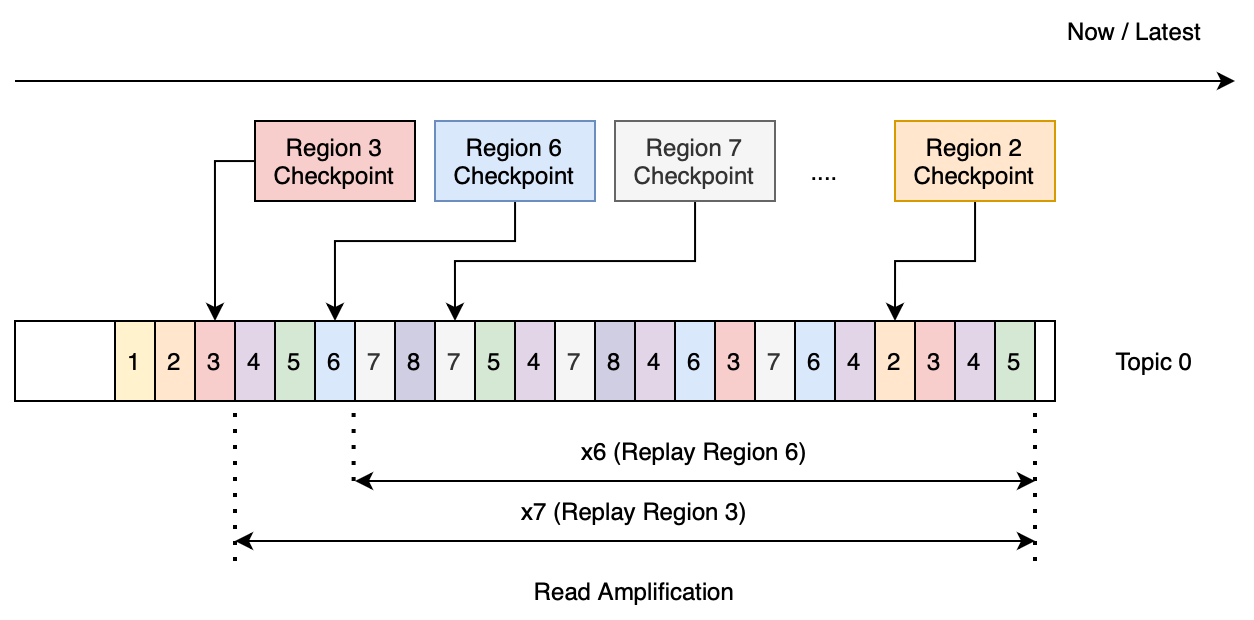
(图 1:恢复 Region 3 需要读取比实际大小大 7 倍的冗余数据)
估算冗余读取放大倍数(冗余重放数据大小/实际数据大小)的简单模型:
- 对于单个 Topic,如果我们尝试重放属于该 Topic 的所有 Region,那么放大倍数将是 7+6+...+1 = 28 倍。(图 1 显示了 Region WAL 数据分布。重放 Region 3 将读取约为实际大小 7 倍的数据;重放 Region 6 将读取约为实际大小 6 倍的数据,以此类推)
- 在恢复 100 个 Region 时(需要大约 13 个 Topic),放大倍数大约为 28 \* 13 = 364 倍。
假设要恢复 100 个 Region,所有 Region 的实际数据大小是 0.5 GB,下表根据每个 Topic 的 Region 数量展示了数据重放的总量。
| 每个 Topic 的 Region 数量 | 100 个 Region 所需 Topic 数量 | 单个 Topic 冗余读取系数 | 总冗余读取系数 | 重放数据大小(GB) |
| ------------------------- | ----------------------------- | --------------------- | ------------ | ------------------ |
| 1 | 100 | 0 | 0 | 0.5 |
| 2 | 50 | 1 | 50 | 25.5 |
| 4 | 25 | 6 | 150 | 75.5 |
| 8 | 13 | 28 | 364 | 182.5 |
| 16 | 7 | 120 | 840 | 420.5 |
下表展示了在 Kafka 集群在不同读取吞吐量情况下,100 个 region 的恢复时间。例如在提供 300MB/s 的读取吞吐量的情况下,恢复 100 个 Region 大约需要 10 分钟(182.5GB/0.3GB = 10 分钟)。
| 每个主题的区域数 | 重放数据大小(GB) | Kafka 吞吐量 300MB/s- 恢复时间(秒) | Kafka 吞吐量 1000MB/s- 恢复时间(秒) |
| ---------------- | ------------------ | ------------------------------------ | ------------------------------------- |
| 1 | 0.5 | 2 | 1 |
| 2 | 25.5 | 85 | 26 |
| 4 | 75.5 | 252 | 76 |
| 8 | 182.5 | 608 | 183 |
| 16 | 420.5 | 1402 | 421 |
### 改进恢复时间的建议
在上文中我们根据不同的每个 Topic 包含的 Region 数量计算了恢复时间以供参考。
在实际场景中,读取放大的现象可能会比这个模型更为严重。
如果使用 Kafka WAL 且对恢复时间非常敏感,我们建议每个 Region 都有自己的 Topic(即,每个 Topic 包含的 Region 数量为 1)。
---
## Region Migration
Region 迁移允许用户在 Datanode 间移动 Region 数据。
:::warning 注意
该功能仅在 GreptimeDB 集群模式下可用,并且需要满足以下条件
- 使用共享存储 (例如:AWS S3)
无法在任何上述以外的情况下使用 Region 迁移。
:::
## 查询 Region 分布
首先需要查询该数据表分区(Region)分布情况,即查询数据表中的 Region 分别在哪一些 Datanode 节点上。
```sql
select b.peer_id as datanode_id,
a.greptime_partition_id as region_id
from information_schema.partitions a left join information_schema.region_peers b
on a.greptime_partition_id = b.region_id where a.table_name='migration_target' order by datanode_id asc;
```
例如:有以下的 Region 分布
```sql
+-------------+---------------+
| datanode_id | region_id |
+-------------+---------------+
| 1 | 4398046511104 |
+-------------+---------------+
1 row in set (0.01 sec)
```
更多关于 `region_peers` 表的信息,请阅读 [REGION-PEERS](/reference/sql/information-schema/region-peers.md)。
## 选择 Region 迁移的目标节点
:::warning Warning
当起始节点等于目标节点时,Region 迁移不会被执行
:::
如果你通过 GreptimeDB operator 部署 DB 集群,Datanode 的 `peer_id` 总是从 0 开始递增。例如,DB 集群有 3 个 Datanode,则 `peer_id` 应为 0,1,2。
最后,你可以通过以下 SQL 请求发起 Region 迁移请求:
```sql
ADMIN migrate_region(4398046511104, 1, 2, 60);
```
`migrate_region` 参数说明:
```sql
ADMIN migrate_region(region_id, from_peer_id, to_peer_id);
ADMIN migrate_region(region_id, from_peer_id, to_peer_id, replay_timeout);
```
| Option | Description | Required | |
| ---------------- | ---------------------------------------------------------------------------------------------------------------------- | ------------ | --- |
| `region_id` | Region Id | **Required** | |
| `from_peer_id` | 迁移起始节点 (Datanode) 的 peer id。 | **Required** | |
| `to_peer_id` | 迁移目标节点 (Datanode) 的 peer id。 | **Required** | |
| `replay_timeout` | 迁移时回放数据的超时时间(单位:秒)。省略时默认 300 秒。如果新 Region 未能在指定时间内回放数据,迁移将失败,旧 Region 中的数据不会丢失。 | Optional | |
## 查询迁移状态
`migrate_region` 函数将返回执行迁移的 Procedure Id,可以通过它查询过程状态:
```sql
ADMIN procedure_state('538b7476-9f79-4e50-aa9c-b1de90710839')
```
如果顺利完成,将输出 JSON 格式的状态:
```json
{"status":"Done"}
```
当然,最终可以通过从 `information_schema` 中查询 `region_peers` 和 `partitions` 来确认 Region 分布是否符合预期。
---
## 重分区
重分区可以在表创建后调整分区规则。GreptimeDB 通过 `ALTER TABLE` 的分区拆分与合并能力来完成重分区,详细语法请参考 [ALTER TABLE](/reference/sql/alter.md#分区拆分与合并)。
重分区仅支持分布式集群。
## 原理
重分区的核心是在线调整分区规则和 Region 路由,而不是把数据手工迁移到新的表。
GreptimeDB 会通过更新每个 Region 的 manifest 文件引用切换到新的分区布局,从而让分区规则重新贴合当前的数据分布。
当业务流量模式发生变化时,这种方式可以帮助你继续保持分区规则与负载匹配,而不需要重建整张表。
重分区期间,写入可能会出现短暂波动,建议客户端开启重试机制。
## 什么时候需要重分区
如果出现下面这些情况,就可以考虑重分区:
- 某些 Region 的写入或查询明显更热,负载长期不均衡;
- 业务分布发生变化,原有分区边界已经不再合适;
- 部分 Region 变得很小且很冷,希望通过合并减少资源占用;
- 需要把某个分区进一步细分,以改善写入并发或查询性能。
通常来说,当分区规则已经不能很好地反映当前数据分布时,就值得考虑重分区。
## 如何发现热点分区
在做重分区之前,建议先确认哪些 Region 已经出现热点。
你可以先把 Region 级别的统计信息和分区规则关联起来,找出最热的规则:
```sql
SELECT
t.table_name,
r.region_id,
r.region_number,
p.partition_name,
p.partition_description,
r.region_role,
r.written_bytes_since_open,
r.region_rows
FROM information_schema.region_statistics r
JOIN information_schema.tables t
ON r.table_id = t.table_id
JOIN information_schema.partitions p
ON p.table_schema = t.table_schema
AND p.table_name = t.table_name
AND p.greptime_partition_id = r.region_id
WHERE t.table_schema = 'public'
AND t.table_name = 'your_table'
ORDER BY r.written_bytes_since_open DESC
LIMIT 10;
```
如果某些 Region 的 `written_bytes_since_open` 长期明显更高,通常就说明这条分区规则比较热,适合优先考虑拆分。
同时也建议检查 Region 对应的节点是否正常,避免把节点抖动误判为热点:
```sql
SELECT
p.region_id,
p.peer_addr,
p.status,
p.down_seconds
FROM information_schema.region_peers p
WHERE p.table_schema = 'public'
AND p.table_name = 'your_table'
ORDER BY p.region_id, p.peer_addr;
```
如果节点状态正常,而热点信号持续存在,就可以继续设计重分区方案。
## 前置条件
:::warning 警告
该功能仅在 GreptimeDB 的分布式集群中可用,并且
- 使用[共享对象存储](/user-guide/deployments-administration/configuration.md#storage-options)(例如 AWS S3)
- 在 metasrv 和所有 datanode 上启用 [GC](/user-guide/deployments-administration/manage-data/gc.md)
否则你无法执行重分区。
:::
当前开源版支持通过多次 `SPLIT PARTITION` / `MERGE PARTITION` 组合完成分区调整,最常见的场景是 1 拆 2 或 2 合 1。对于更复杂的分区变更,也可以通过逐步拆分和合并来完成。
对象存储用于保存 region 文件,GC 则负责在引用释放后再回收旧文件,避免重分区过程中误删仍在使用的数据。
如需了解详细配置,请参考:
- [GC](/user-guide/deployments-administration/manage-data/gc.md)
- [对象存储配置](/user-guide/deployments-administration/configuration.md#storage-options)
### 通过 GreptimeDB Operator
如果你使用 GreptimeDB Operator 部署,可以参考 [常见 Helm Chart 配置项](/user-guide/deployments-administration/deploy-on-kubernetes/common-helm-chart-configurations.md) 快速完成 GC 和对象存储配置。
## 重分区示例
你可以通过先合并现有分区,然后用新规则拆分它们来修改分区规则。下面的示例展示了如何将 `device_id < 100` 的设备的分区键 `area` 从 `South` 更改为 `North`:
```sql
ALTER TABLE sensor_readings MERGE PARTITION (
device_id < 100 AND area < 'South',
device_id < 100 AND area >= 'South'
);
ALTER TABLE sensor_readings SPLIT PARTITION (
device_id < 100
) INTO (
device_id < 100 AND area < 'North',
device_id < 100 AND area >= 'North'
);
```
## 延伸阅读
如果你希望查看包含更多背景说明和完整示例的教程,请参考博客文章:[如何在 GreptimeDB 中在线拆分与合并分区](https://greptime.cn/blogs/2026-03-19-greptimedb-repartition-guide)。
:::caution 注意
重分区仅支持在分布式集群中执行。请确认 GC 与对象存储已正确配置后,再运行相关操作。
:::
---
## 表分片
表分片是一种将大表分成多个小表的技术。
这种做法通常用于提高数据库系统的性能。
在 GreptimeDB 中,数据从逻辑上被分片成多个分区。
由于 GreptimeDB 使用“表”来分组数据并使用 SQL 来查询数据,
因此采用了 OLTP 数据库中常用的术语“分区”。
## 表分片的时机
在 GreptimeDB 中,数据管理和调度都是基于 region 级别的,
每个 region 对应一个表分区。
因此,当你的表太大而无法放入单个节点,
或者表太热而无法由单个节点提供服务时,
应该考虑进行分片。
GreptimeDB 中的一个 region 具有相对固定的吞吐量,
表中的 region 数量决定了表的总吞吐量容量。
如果你想增加表的吞吐量容量,
可以增加表中的 region 数量。
理想情况下,表的整体吞吐量应与 region 的数量成正比。
至于使用哪个特定的分区列或创建多少个 region,
这取决于数据分布和查询模式。
一个常见的目标是使数据在 region 之间的分布尽可能均匀。
在设计分区规则集时应考虑查询模式,
因为一个查询可以在 region 之间并行处理。
换句话说,查询延迟取决于“最慢”的 region 延迟。
请注意,region 数量的增加会带来一些基本的消耗并增加系统的复杂性。
你需要考虑数据写入速率的要求、查询性能、存储系统上的数据分布。
只有在必要时才应进行表分片。
有关分区和 region 之间关系的更多信息,请参阅贡献者指南中的[表分片](/contributor-guide/frontend/table-sharding.md)部分。
## 分区
在 GreptimeDB 中,表可以按列值范围进行水平分区。
目前,GreptimeDB 支持使用 `PARTITION ON COLUMNS` 语法进行范围分区。
每个分区仅包含表中的一部分数据,
并按某些列的值范围进行分组。
例如,我们可以在 GreptimeDB 中这样分区一个表:
```sql
CREATE TABLE (...)
PARTITION ON COLUMNS () (
);
```
该语法主要由两部分组成:
1. `PARTITION ON COLUMNS` 后跟一个用逗号分隔的列名列表,指定了将用于分区的列。这里指定的列必须是 Tag 类型(由 PRIMARY KEY 指定)。请注意,所有分区的范围必须**不能**重叠。
2. `RULE LIST` 是多个分区规则的列表。每个规则是一个分区条件,GreptimeDB 会为这些规则生成 `p0`、`p1` 等分区名称。这里的表达式可以使用 `=`, `!=`, `>`, `>=`, `<`, `<=`, `AND`, `OR`, 列名和字面量。
:::tip 提示
`PARTITION ON COLUMNS` 括号里只能写列名(如 `device_id`、`area`),不支持表达式。GreptimeDB 不支持 MySQL 的 `PARTITION BY RANGE` 语法。
:::
### 示例
## 创建分布式表
你可以使用 MySQL CLI [连接到 GreptimeDB](/user-guide/protocols/mysql.md) 并创建一个分布式表。
下方的示例创建了一个表并基于 `device_id` 列进行分区。
```SQL
CREATE TABLE sensor_readings (
device_id INT16,
reading_value FLOAT64,
ts TIMESTAMP DEFAULT current_timestamp(),
PRIMARY KEY (device_id),
TIME INDEX (ts)
)
PARTITION ON COLUMNS (device_id) (
device_id < 100,
device_id >= 100 AND device_id < 200,
device_id >= 200
);
```
你可以使用更多的分区列来创建更复杂的分区规则:
```sql
CREATE TABLE sensor_readings (
device_id INT,
area STRING,
reading_value FLOAT64,
ts TIMESTAMP DEFAULT current_timestamp(),
PRIMARY KEY (device_id, area),
TIME INDEX (ts)
)
PARTITION ON COLUMNS (device_id, area) (
device_id < 100 AND area < 'South',
device_id < 100 AND area >= 'South',
device_id >= 100 AND area <= 'East',
device_id >= 100 AND area > 'East'
);
```
以下内容以具有两个分区列的 `sensor_readings` 表为例。
## 重分区
如果你需要修改已创建表的分区规则,请参考单独的 [重分区](/user-guide/deployments-administration/manage-data/repartition.md) 页面。
## 向表中插入数据
以下代码向 `sensor_readings` 表的每个分区插入 3 行数据。
```sql
INSERT INTO sensor_readings (device_id, area, reading_value, ts)
VALUES (1, 'North', 22.5, '2023-09-19 08:30:00'),
(10, 'North', 21.8, '2023-09-19 09:45:00'),
(50, 'North', 23.4, '2023-09-19 10:00:00');
INSERT INTO sensor_readings (device_id, area, reading_value, ts)
VALUES (20, 'South', 20.1, '2023-09-19 11:15:00'),
(40, 'South', 19.7, '2023-09-19 12:30:00'),
(90, 'South', 18.9, '2023-09-19 13:45:00');
INSERT INTO sensor_readings (device_id, area, reading_value, ts)
VALUES (110, 'East', 25.3, '2023-09-19 14:00:00'),
(120, 'East', 26.5, '2023-09-19 15:30:00'),
(130, 'East', 27.8, '2023-09-19 16:45:00');
INSERT INTO sensor_readings (device_id, area, reading_value, ts)
VALUES (150, 'West', 24.1, '2023-09-19 17:00:00'),
(170, 'West', 22.9, '2023-09-19 18:15:00'),
(180, 'West', 23.7, '2023-09-19 19:30:00');
```
:::tip NOTE
注意,当写入数据不满足分区规则中的任何规则时,数据将被分配到默认分区(即表的第一个分区 0)。
:::
## 分布式查询
只需使用 `SELECT` 语法查询数据:
```sql
SELECT * FROM sensor_readings order by reading_value desc LIMIT 5;
```
```sql
+-----------+------+---------------+---------------------+
| device_id | area | reading_value | ts |
+-----------+------+---------------+---------------------+
| 130 | East | 27.8 | 2023-09-19 16:45:00 |
| 120 | East | 26.5 | 2023-09-19 15:30:00 |
| 110 | East | 25.3 | 2023-09-19 14:00:00 |
| 150 | West | 24.1 | 2023-09-19 17:00:00 |
| 180 | West | 23.7 | 2023-09-19 19:30:00 |
+-----------+------+---------------+---------------------+
5 rows in set (0.02 sec)
```
```sql
SELECT MAX(reading_value) AS max_reading
FROM sensor_readings;
```
```sql
+-------------+
| max_reading |
+-------------+
| 27.8 |
+-------------+
1 row in set (0.03 sec)
```
```sql
SELECT * FROM sensor_readings
WHERE area = 'North' AND device_id < 50
ORDER BY device_id;
```
```sql
+-----------+-------+---------------+---------------------+
| device_id | area | reading_value | ts |
+-----------+-------+---------------+---------------------+
| 1 | North | 22.5 | 2023-09-19 08:30:00 |
| 10 | North | 21.8 | 2023-09-19 09:45:00 |
+-----------+-------+---------------+---------------------+
2 rows in set (0.03 sec)
```
## 检查分片表
GreptimeDB 提供了几个系统表来检查数据库的状态。
对于表分片信息,你可以查询 [`information_schema.partitions`](/reference/sql/information-schema/partitions.md),
它提供了一个表内分区的详细信息,
以及 [`information_schema.region_peers`](/reference/sql/information-schema/region-peers.md) 提供了 region 的运行时分布信息。
---
## 元数据存储配置
本节介绍如何为 GreptimeDB Metasrv 组件配置不同的元数据存储后端。元数据存储用于存储关键的系统信息,包括 catalog、schema、table、region 以及其他对 GreptimeDB 运行至关重要的元数据。
## 可用存储后端
GreptimeDB 支持以下元数据存储后端:
- **etcd**:开发和测试环境的默认推荐后端,提供简单性和易用性
- **MySQL/PostgreSQL**:适合生产环境的后端选择,能够无缝对接现有的数据库基础设施和云服务商提供的 RDS 服务
本文档描述的每种后端的 TOML 配置,适用于没有使用 Helm Chart 部署 GreptimeDB 的情况下。
如果你使用 Helm Chart 部署 GreptimeDB,可以参考 [Common Helm Chart Configurations](/user-guide/deployments-administration/deploy-on-kubernetes/common-helm-chart-configurations.md#configuring-metasrv-backend-storage) 了解更多详情。
## 使用 etcd 作为元数据存储
虽然 etcd 适合开发和测试环境,但对于需要高可用性和可扩展性的生产环境来说可能并不是最佳选择。
配置 metasrv 组件使用 etcd 作为元数据存储:
```toml
# metasrv 组件的元数据存储后端
backend = "etcd_store"
# 存储服务器地址
# 可以指定多个 etcd 端点以实现高可用性
store_addrs = ["127.0.0.1:2379"]
# etcd 后端客户端选项
[backend_client]
# 后端客户端的保持连接超时时间
keep_alive_timeout = "3s"
# 后端客户端的保持连接间隔
keep_alive_interval = "10s"
# 后端客户端的连接超时时间
connect_timeout = "3s"
[backend_tls]
# - "disable" - 不使用 TLS
# - "require" - 要求 TLS
mode = "prefer"
# 客户端证书文件路径(用于客户端身份验证)
# 例如 "/path/to/client.crt"
cert_path = ""
# 客户端私钥文件路径(用于客户端身份验证)
# 例如 "/path/to/client.key"
key_path = ""
# CA 证书文件路径(用于服务器证书验证)
# 使用自定义 CA 或自签名证书时必需
# 留空则仅使用系统根证书
# 例如 "/path/to/ca.crt"
ca_cert_path = ""
```
### 最佳实践
虽然 etcd 可以用作元数据存储,但我们不建议在生产环境中使用它,除非你对 etcd 的操作和维护有丰富的经验。有关 etcd 管理的详细指南,包括安装、备份和维护程序,请参阅[管理 etcd](/user-guide/deployments-administration/manage-metadata/manage-etcd.md)。
使用 etcd 作为元数据存储时:
- 在不同可用区部署多个端点以实现高可用性
- 配置适当的自动压缩设置以管理存储增长
- 实施定期维护程序:
- 定期运行 `Defrag` 命令以回收磁盘空间
- 监控 etcd 集群健康指标
- 根据使用模式审查和调整资源限制
## 使用 MySQL 作为元数据存储
MySQL 可作为一种可行的元数据存储后端选项。特别是在需要与现有 MySQL 基础设施集成,或存在特定 MySQL 相关需求的场景下,这一选择尤为适用。对于生产环境部署,我们强烈建议使用各大云服务商提供的关系型数据库服务(RDS),以获得更高的可靠性和托管服务带来的便利。
配置 metasrv 组件以使用 MySQL 作为元数据存储:
```toml
# metasrv 组件的元数据存储后端
backend = "mysql_store"
# 存储服务器地址
# 格式:mysql://user:password@ip:port/dbname
store_addrs = ["mysql://user:password@ip:port/dbname"]
# 可选:自定义元数据存储表名
# 默认值: greptime_metakv
meta_table_name = "greptime_metakv"
[backend_tls]
# - "disable" - 不使用 TLS
# - "prefer" (默认) - 尝试 TLS,失败时回退到明文连接
# - "require" - 要求 TLS
# - "verify_ca" - 要求 TLS 并验证 CA
# - "verify_full" - 要求 TLS 并验证主机名
mode = "prefer"
# 客户端证书文件路径(用于客户端身份验证)
# 例如 "/path/to/client.crt"
cert_path = ""
# 客户端私钥文件路径(用于客户端身份验证)
# 例如 "/path/to/client.key"
key_path = ""
# CA 证书文件路径(用于服务器证书验证)
# 使用自定义 CA 或自签名证书时必需
# 留空则仅使用系统根证书
# 例如 "/path/to/ca.crt"
ca_cert_path = ""
```
当多个 GreptimeDB 集群共享同一个 MySQL 实例时,必须为每个 GreptimeDB 集群设置一个唯一的 `meta_table_name` 以避免元数据冲突。
## 使用 PostgreSQL 作为元数据存储
PostgreSQL 可作为一种可行的元数据存储后端选项。特别是在需要与现有 PostgreSQL 基础设施集成,或存在特定 PostgreSQL 相关需求的场景下,这一选择尤为适用。对于生产环境部署,我们强烈建议使用各大云服务商提供的关系型数据库服务(RDS),以获得更高的可靠性和托管服务带来的便利。
配置 metasrv 组件以使用 PostgreSQL 作为元数据存储:
```toml
# metasrv 组件的元数据存储后端
backend = "postgres_store"
# 存储服务器地址
# 格式: password=password dbname=postgres user=postgres host=localhost port=5432
store_addrs = ["password=password dbname=postgres user=postgres host=localhost port=5432"]
# 可选:自定义元数据存储表名
# 默认值: greptime_metakv
meta_table_name = "greptime_metakv"
# 可选:PostgreSQL schema,用于元数据表和选举表名称限定。
# 在 PostgreSQL 15 及更高版本中,默认的 public schema 通常被限制写入权限,
# 非超级用户无法在 public schema 中创建表。
# 当遇到权限限制时,可通过此参数指定一个具有写入权限的 schema。
meta_schema_name = "greptime_schema"
# 可选:如果 PostgreSQL schema 不存在则自动创建。
# 启用后,系统会在创建元数据表之前执行 `CREATE SCHEMA IF NOT EXISTS `。
# 这在生产环境中可能受限于手动创建 schema 的情况下非常有用。
# 默认值:true
# 注意:PostgreSQL 用户必须具有 CREATE SCHEMA 权限才能使此功能生效。
auto_create_schema = true
# 可选: 用于选举的 Advisory lock ID
# 默认值: 1
meta_election_lock_id = 1
[backend_tls]
# - "disable" - 不使用 TLS
# - "prefer" (默认) - 尝试 TLS,失败时回退到明文连接
# - "require" - 要求 TLS
# - "verify_ca" - 要求 TLS 并验证 CA
# - "verify_full" - 要求 TLS 并验证主机名
mode = "prefer"
# 客户端证书文件路径(用于客户端身份验证)
# 例如 "/path/to/client.crt"
cert_path = ""
# 客户端私钥文件路径(用于客户端身份验证)
# 例如 "/path/to/client.key"
key_path = ""
# CA 证书文件路径(用于服务器证书验证)
# 使用自定义 CA 或自签名证书时必需
# 留空则仅使用系统根证书
# 例如 "/path/to/ca.crt"
ca_cert_path = ""
```
当多个 GreptimeDB 集群共享同一个 PostgreSQL 实例或与其他应用程序共享时,必须配置两个唯一标识符以防止冲突:
1. 为每个 GreptimeDB 集群设置唯一的 `meta_table_name` 以避免元数据冲突
2. 为每个 GreptimeDB 集群分配唯一的 `meta_election_lock_id` 以防止与使用同一 PostgreSQL 实例的其他应用程序发生 advisory lock 冲突
---
## 管理 etcd
GreptimeDB 集群默认需要一个 etcd 集群用于[元数据存储](https://docs.greptime.com/nightly/contributor-guide/metasrv/overview)。让我们使用 Bitnami 的 etcd Helm [chart](https://github.com/bitnami/charts/tree/main/bitnami/etcd) 安装一个 etcd 集群。
## 先决条件
- [Kubernetes](https://kubernetes.io/docs/setup/) >= v1.23
- [kubectl](https://kubernetes.io/docs/tasks/tools/install-kubectl/) >= v1.18.0
- [Helm](https://helm.sh/docs/intro/install/) >= v3.0.0
## 安装
将以下配置保存为文件 `etcd.yaml`:
```yaml
global:
security:
allowInsecureImages: true
image:
registry: greptime-registry.cn-hangzhou.cr.aliyuncs.com
repository: bitnami/etcd
tag: 3.6.1-debian-12-r3
replicaCount: 3
auth:
rbac:
create: false
token:
enabled: false
persistence:
storageClass: null
size: 8Gi
resources:
limits:
cpu: '2'
memory: 8Gi
requests:
cpu: '2'
memory: 8Gi
autoCompactionMode: "periodic"
autoCompactionRetention: "1h"
extraEnvVars:
- name: ETCD_QUOTA_BACKEND_BYTES
value: "8589934592"
- name: ETCD_ELECTION_TIMEOUT
value: "2000"
- name: ETCD_SNAPSHOT_COUNT
value: "10000"
```
安装 etcd 集群:
```bash
helm upgrade \
--install etcd oci://greptime-registry.cn-hangzhou.cr.aliyuncs.com/charts/etcd \
--create-namespace \
--version 12.0.8 \
-n etcd-cluster \
--values etcd.yaml
```
等待 etcd 集群运行:
```bash
kubectl get pod -n etcd-cluster
```
Expected Output
```bash
NAME READY STATUS RESTARTS AGE
etcd-0 1/1 Running 0 64s
etcd-1 1/1 Running 0 65s
etcd-2 1/1 Running 0 72s
```
等待 etcd 集群运行完毕,使用以下命令检查 etcd 集群的健康状态:
```bash
kubectl -n etcd-cluster \
exec etcd-0 -- etcdctl \
--endpoints etcd-0.etcd-headless.etcd-cluster:2379,etcd-1.etcd-headless.etcd-cluster:2379,etcd-2.etcd-headless.etcd-cluster:2379 \
endpoint status -w table
```
Expected Output
```bash
+----------------------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| etcd-0.etcd-headless.etcd-cluster:2379 | 680910587385ae31 | 3.5.15 | 20 kB | false | false | 4 | 73991 | 73991 | |
| etcd-1.etcd-headless.etcd-cluster:2379 | d6980d56f5e3d817 | 3.5.15 | 20 kB | false | false | 4 | 73991 | 73991 | |
| etcd-2.etcd-headless.etcd-cluster:2379 | 12664fc67659db0a | 3.5.15 | 20 kB | true | false | 4 | 73991 | 73991 | |
+----------------------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
```
## 备份
在 bitnami etcd chart 中,使用共享存储卷 Network File System (NFS) 存储 etcd 备份数据。通过 Kubernetes 中的 CronJob 进行 etcd 快照备份,并挂载 NFS PersistentVolumeClaim (PVC),可以将快照传输到 NFS 中。
添加以下配置,并将其命名为 `etcd-backup.yaml` 文件,注意需要将 **existingClaim** 修改为你的 NFS PVC 名称:
```yaml
global:
security:
allowInsecureImages: true
image:
registry: greptime-registry.cn-hangzhou.cr.aliyuncs.com
repository: bitnami/etcd
tag: 3.6.1-debian-12-r3
replicaCount: 3
auth:
rbac:
create: false
token:
enabled: false
persistence:
storageClass: null
size: 8Gi
resources:
limits:
cpu: '2'
memory: 8Gi
requests:
cpu: '2'
memory: 8Gi
autoCompactionMode: "periodic"
autoCompactionRetention: "1h"
extraEnvVars:
- name: ETCD_QUOTA_BACKEND_BYTES
value: "8589934592"
- name: ETCD_ELECTION_TIMEOUT
value: "2000"
- name: ETCD_SNAPSHOT_COUNT
value: "10000"
# Backup settings
disasterRecovery:
enabled: true
cronjob:
schedule: "*/30 * * * *"
historyLimit: 2
snapshotHistoryLimit: 2
pvc:
existingClaim: "${YOUR_NFS_PVC_NAME_HERE}"
```
重新部署 etcd 集群:
```bash
helm upgrade \
--install etcd oci://greptime-registry.cn-hangzhou.cr.aliyuncs.com/charts/etcd \
--create-namespace \
--version 12.0.8 \
-n etcd-cluster \
--values etcd-backup.yaml
```
你可以看到 etcd 备份计划任务:
```bash
kubectl get cronjob -n etcd-cluster
```
Expected Output
```bash
NAME SCHEDULE TIMEZONE SUSPEND ACTIVE LAST SCHEDULE AGE
etcd-snapshotter */30 * * * * False 0 36s
```
```bash
kubectl get pod -n etcd-cluster
```
Expected Output
```bash
NAME READY STATUS RESTARTS AGE
etcd-0 1/1 Running 0 35m
etcd-1 1/1 Running 0 36m
etcd-2 0/1 Running 0 6m28s
etcd-snapshotter-28936038-tsck8 0/1 Completed 0 4m49s
```
```bash
kubectl logs etcd-snapshotter-28936038-tsck8 -n etcd-cluster
```
Expected Output
```log
etcd-0.etcd-headless.etcd-cluster.svc.cluster.local:2379 is healthy: successfully committed proposal: took = 2.698457ms
etcd 11:18:07.47 INFO ==> Snapshotting the keyspace
{"level":"info","ts":"2025-01-06T11:18:07.579095Z","caller":"snapshot/v3_snapshot.go:65","msg":"created temporary db file","path":"/snapshots/db-2025-01-06_11-18.part"}
{"level":"info","ts":"2025-01-06T11:18:07.580335Z","logger":"client","caller":"v3@v3.5.15/maintenance.go:212","msg":"opened snapshot stream; downloading"}
{"level":"info","ts":"2025-01-06T11:18:07.580359Z","caller":"snapshot/v3_snapshot.go:73","msg":"fetching snapshot","endpoint":"etcd-0.etcd-headless.etcd-cluster.svc.cluster.local:2379"}
{"level":"info","ts":"2025-01-06T11:18:07.582124Z","logger":"client","caller":"v3@v3.5.15/maintenance.go:220","msg":"completed snapshot read; closing"}
{"level":"info","ts":"2025-01-06T11:18:07.582688Z","caller":"snapshot/v3_snapshot.go:88","msg":"fetched snapshot","endpoint":"etcd-0.etcd-headless.etcd-cluster.svc.cluster.local:2379","size":"20 kB","took":"now"}
{"level":"info","ts":"2025-01-06T11:18:07.583008Z","caller":"snapshot/v3_snapshot.go:97","msg":"saved","path":"/snapshots/db-2025-01-06_11-18"}
Snapshot saved at /snapshots/db-2025-01-06_11-18
```
接下来,可以在 NFS 服务器中看到 etcd 备份快照:
```bash
ls ${NFS_SERVER_DIRECTORY}
```
Expected Output
```bash
db-2025-01-06_11-18 db-2025-01-06_11-20 db-2025-01-06_11-22
```
## 恢复
当您遇到 etcd 数据丢失或损坏(例如,存储在 etcd 中的关键信息被意外删除,或者发生无法恢复的灾难性集群故障)时,您需要执行 etcd 恢复。此外,恢复 etcd 还可用于开发和测试目的。
恢复前需要停止向 etcd 集群写入数据(停止 GreptimeDB Metasrv 对 etcd 的写入),并创建最新的快照文件用于恢复。
添加以下配置文件,命名为 `etcd-restore.yaml`。注意,**existingClaim** 是你的 NFS PVC 的名字,**snapshotFilename** 为 etcd 快照文件名:
```yaml
global:
security:
allowInsecureImages: true
image:
registry: greptime-registry.cn-hangzhou.cr.aliyuncs.com
repository: bitnami/etcd
tag: 3.6.1-debian-12-r3
replicaCount: 3
auth:
rbac:
create: false
token:
enabled: false
persistence:
storageClass: null
size: 8Gi
resources:
limits:
cpu: '2'
memory: 8Gi
requests:
cpu: '2'
memory: 8Gi
autoCompactionMode: "periodic"
autoCompactionRetention: "1h"
extraEnvVars:
- name: ETCD_QUOTA_BACKEND_BYTES
value: "8589934592"
- name: ETCD_ELECTION_TIMEOUT
value: "2000"
- name: ETCD_SNAPSHOT_COUNT
value: "10000"
# Restore settings
startFromSnapshot:
enabled: true
existingClaim: "${YOUR_NFS_PVC_NAME_HERE}"
snapshotFilename: "${YOUR_ETCD_SNAPSHOT_FILE_NAME}"
```
部署 etcd 恢复集群:
```bash
helm upgrade \
--install etcd-recover oci://greptime-registry.cn-hangzhou.cr.aliyuncs.com/charts/etcd \
--create-namespace \
--version 12.0.8 \
-n etcd-cluster \
--values etcd-restore.yaml
```
等待 etcd 恢复集群运行:
```bash
kubectl get pod -n etcd-cluster -l app.kubernetes.io/instance=etcd-recover
```
Expected Output
```bash
NAME READY STATUS RESTARTS AGE
etcd-recover-0 1/1 Running 0 91s
etcd-recover-1 1/1 Running 0 91s
etcd-recover-2 1/1 Running 0 91s
```
:::tip NOTE
chart 版本之间的配置结构已发生变化:
- 旧版本: `meta.etcdEndpoints`
- 新版本: `meta.backendStorage.etcd.endpoints`
请参考 chart 仓库中配置 [values.yaml](https://github.com/GreptimeTeam/helm-charts/blob/main/charts/greptimedb-cluster/values.yaml) 以获取最新的结构。
:::
接着,将 Metasrv 的 [backendStorage.etcd.endpoints](https://github.com/GreptimeTeam/helm-charts/tree/main/charts/greptimedb-cluster) 改成新的 etcd recover 集群,本例中为 `"etcd-recover.etcd-cluster.svc.cluster.local:2379"`:
```yaml
apiVersion: greptime.io/v1alpha1
kind: GreptimeDBCluster
metadata:
name: greptimedb
spec:
# 其他配置
meta:
backendStorage:
etcd:
endpoints:
- "etcd-recover.etcd-cluster.svc.cluster.local:2379"
```
然后重启 GreptimeDB Metasrv 完成 etcd 恢复。
## Monitoring
- 安装 Prometheus Operator (例如: [kube-prometheus-stack](https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack))。
- 安装 podmonitor CRD。
将以下配置保存为文件 `etcd-monitoring.yaml`:
```yaml
global:
security:
allowInsecureImages: true
image:
registry: greptime-registry.cn-hangzhou.cr.aliyuncs.com
repository: bitnami/etcd
tag: 3.6.1-debian-12-r3
replicaCount: 3
auth:
rbac:
create: false
token:
enabled: false
persistence:
storageClass: null
size: 8Gi
resources:
limits:
cpu: '2'
memory: 8Gi
requests:
cpu: '2'
memory: 8Gi
autoCompactionMode: "periodic"
autoCompactionRetention: "1h"
extraEnvVars:
- name: ETCD_QUOTA_BACKEND_BYTES
value: "8589934592"
- name: ETCD_ELECTION_TIMEOUT
value: "2000"
- name: ETCD_SNAPSHOT_COUNT
value: "10000"
# Monitoring settings
metrics:
enabled: true
podMonitor:
enabled: true
namespace: etcd-cluster
interval: 10s
scrapeTimeout: 10s
additionalLabels:
release: prometheus
```
部署并监控 etcd:
```bash
helm upgrade \
--install etcd oci://greptime-registry.cn-hangzhou.cr.aliyuncs.com/charts/etcd \
--create-namespace \
--version 12.0.8 \
-n etcd-cluster \
--values etcd-monitoring.yaml
```
### Grafana dashboard
使用 [ETCD Cluster Overview dashboard](https://grafana.com/grafana/dashboards/15308-etcd-cluster-overview/) (ID: 15308) 来监控 etcd 的指标。
1. 登录你的 Grafana。
2. 导航至 Dashboards -> New -> Import。
3. 输入 Dashboard ID: 15308, 选择数据源并加载图表。
## ⚠️ Defrag - Critical Warning
Defrag 是一项高风险操作,可能会严重影响您的 ETCD 集群及其依赖系统(例如 GreptimeDB):
1. 执行期间会阻止所有读/写操作(集群将不可用)。
2. 高 I/O 使用率可能导致客户端应用程序超时。
3. 如果碎片整理耗时过长,可能会触发领导者选举。
4. 如果资源分配不当,可能会导致 OOM 终止。
5. 如果在过程中中断,可能会损坏数据。
ETCD 使用多版本并发控制 (MVCC) 机制,用于存储多个版本的 KV。随着时间的推移,随着数据的更新和删除,后端数据库可能会变得碎片化,从而增加存储空间并降低性能。Defrag 是指压缩这些存储空间以回收空间并提高性能的过程。
在 `etcd-defrag.yaml` 文件中添加以下与 defrag 相关的配置:
```yaml
global:
security:
allowInsecureImages: true
image:
registry: greptime-registry.cn-hangzhou.cr.aliyuncs.com
repository: bitnami/etcd
tag: 3.6.1-debian-12-r3
replicaCount: 3
auth:
rbac:
create: false
token:
enabled: false
persistence:
storageClass: null
size: 8Gi
resources:
limits:
cpu: '2'
memory: 8Gi
requests:
cpu: '2'
memory: 8Gi
autoCompactionMode: "periodic"
autoCompactionRetention: "1h"
extraEnvVars:
- name: ETCD_QUOTA_BACKEND_BYTES
value: "8589934592"
- name: ETCD_ELECTION_TIMEOUT
value: "2000"
- name: ETCD_SNAPSHOT_COUNT
value: "10000"
# Defragmentation settings
defrag:
enabled: true
cronjob:
schedule: "0 3 * * *" # Daily at 3:00 AM
suspend: false
successfulJobsHistoryLimit: 1
failedJobsHistoryLimit: 1
```
部署 etcd 集群并开启 defrag 功能:
```bash
helm upgrade \
--install etcd oci://greptime-registry.cn-hangzhou.cr.aliyuncs.com/charts/etcd \
--create-namespace \
--version 12.0.8 \
-n etcd-cluster \
--values etcd-defrag.yaml
```
你可以看到 etcd defrag 定时任务:
```bash
kubectl get cronjob -n etcd-cluster
```
Expected Output
```bash
NAME SCHEDULE TIMEZONE SUSPEND ACTIVE LAST SCHEDULE AGE
etcd-defrag 0 3 * * * False 0 34s
```
```bash
kubectl get pod -n etcd-cluster
```
Expected Output
```bash
NAME READY STATUS RESTARTS AGE
etcd-0 1/1 Running 0 4m30s
etcd-1 1/1 Running 0 4m29s
etcd-2 1/1 Running 0 4m29s
etcd-defrag-29128518-sstbf 0/1 Completed 0 90s
```
```bash
kubectl logs etcd-defrag-29128518-sstbf -n etcd-cluster
```
Expected Output
```log
Finished defragmenting etcd member[http://etcd-0.etcd-headless.etcd-cluster.svc.cluster.local:2379]
Finished defragmenting etcd member[http://etcd-1.etcd-headless.etcd-cluster.svc.cluster.local:2379]
Finished defragmenting etcd member[http://etcd-2.etcd-headless.etcd-cluster.svc.cluster.local:2379]
```
---
## GreptimeDB Metasrv 元数据管理概述
# 概述
GreptimeDB 集群 Metasrv 组件需要一个元数据存储来保存元数据。GreptimeDB 提供了灵活的元数据存储选项,包括 [etcd](https://etcd.io/)、[MySQL](https://www.mysql.com/) 和 [PostgreSQL](https://www.postgresql.org/)。每种选项都针对不同的部署场景设计,在可扩展性、可靠性和运维开销之间取得平衡。
- [etcd](https://etcd.io/):一个轻量级的分布式键值存储,非常适合元数据管理。其简单性和易于设置的特点使其成为开发和测试环境的绝佳选择。
- [MySQL](https://www.mysql.com/) 和 [PostgreSQL](https://www.postgresql.org/):企业级关系型数据库,提供强大的元数据存储能力。它们提供包括 ACID 事务、复制和全面的备份解决方案在内的基本功能,使其成为生产环境的理想选择。这两种数据库在各大云平台上都广泛提供托管数据库服务(RDS)。
## 推荐方案
对于测试和开发环境,[etcd](https://etcd.io/) 提供了一个轻量级且简单的元数据存储解决方案。
**对于生产环境部署,我们强烈建议使用云服务商提供的关系型数据库服务(RDS)作为元数据存储。** 这种方式具有以下优势:
- 托管服务内置高可用性和灾难恢复能力
- 自动化的备份和维护
- 专业的监控和支持
- 相比自托管解决方案,降低了运维复杂度
- 与其他云服务无缝集成
## 最佳实践
- 为元数据存储实施定期备份计划
- 建立全面的存储健康状态和性能指标监控
- 制定清晰的灾难恢复流程
- 记录元数据存储配置和维护程序
## 后续步骤
- 要配置元数据存储后端,请参阅[配置](/user-guide/deployments-administration/manage-metadata/configuration.md)。
- 要为测试和开发环境设置 etcd,请参阅[管理 etcd](/user-guide/deployments-administration/manage-metadata/manage-etcd.md)。
---
## 备份、恢复和迁移
GreptimeDB 通过其 CLI 工具提供元数据备份和恢复功能。该功能支持所有主要的元数据存储后端,包括 etcd、MySQL 和 PostgreSQL。有关使用这些功能的详细说明,请参阅[备份和恢复](/user-guide/deployments-administration/disaster-recovery/back-up-&-restore-data.md)指南。
## 备份
为了获得最佳的备份可靠性,建议在 DDL(数据定义语言)操作(即建表、删表、修改表结构等)较少的时段进行元数据备份。这有助于确保数据一致性,并降低部分或不完整备份的风险。
执行备份的步骤:
1. 确认 GreptimeDB 集群处于正常运行状态
2. 使用 CLI 工具执行备份,按照[备份和恢复](/user-guide/deployments-administration/disaster-recovery/back-up-&-restore-meta-data.md)指南中的导出元数据步骤操作
3. 确保备份输出文件已创建,且文件大小大于 0
## 恢复
从备份恢复的步骤:
1. 使用 CLI 工具恢复元数据,按照[备份和恢复](/user-guide/deployments-administration/disaster-recovery/back-up-&-restore-meta-data.md)指南中的导入元数据步骤操作
2. 重启 GreptimeDB 集群以应用恢复的元数据
3. 将[待分配表 ID](/user-guide/deployments-administration/maintenance/sequence-management.md) 设置为原集群的待分配表 ID
4. 调用[表元数据修复](/user-guide/deployments-administration/maintenance/table-reconciliation.md)函数,修复表元数据不一致问题
## 迁移
我们建议在 DDL(数据定义语言)操作(即建表、删表、修改表结构等)较少的时段进行元数据迁移,以确保数据一致性并降低部分或不完整迁移的风险。
将元数据从一个存储后端迁移到另一个存储后端的步骤:
1. 从源存储备份元数据
2. 将元数据恢复到目标存储
3. 重启整个 GreptimeDB 集群(所有组件)以应用恢复的元数据
---
## 检查 GreptimeDB 状态
GreptimeDB 包含了一系列的 HTTP 接口可供查询 GreptimeDB 的运行情况。
以下发起的 HTTP 请求均假定 GreptimeDB 运行在节点 `127.0.0.1` 上,其 HTTP 服务监听默认的 `4000` 端口。
## 查看 GreptimeDB 是否正常运行:
你可以使用 `/health` 接口检查 GreptimeDB 是否正常运行。
HTTP 状态码 `200 OK` 表示 GreptimeDB 运行正常。
例子:
```bash
curl -i -X GET http://127.0.0.1:4000/health
```
输出:
```text
HTTP/1.1 200 OK
content-type: application/json
vary: origin, access-control-request-method, access-control-request-headers
access-control-allow-origin: *
content-length: 2
date: Sun, 26 Apr 2026 13:46:41 GMT
{}
```
有关健康检查接口的更多信息,请参考[健康检查接口](/reference/http-endpoints.md#健康检查)。
## 查看 GreptimeDB 的部署状态
你可以使用 `/status` 接口检查 GreptimeDB 的部署状态。
```bash
curl -X GET http://127.0.0.1:4000/status | jq
```
输出:
```json
{
"commit": "8d2f92c01ae762287a3cac587156519a536ae134",
"branch": "",
"rustc_version": "rustc 1.96.0-nightly (ac7f9ec7d 2026-03-20)",
"hostname": "127.0.0.1",
"version": "1.0.1"
}
```
有关状态接口的更多信息,请参考[状态接口](/reference/http-endpoints.md#状态)。
---
## 自监控 GreptimeDB 集群
在阅读本文档前,请确保你已经了解如何[在 Kubernetes 上部署 GreptimeDB 集群](/user-guide/deployments-administration/deploy-on-kubernetes/deploy-greptimedb-cluster.md)。
本文将介绍在部署 GreptimeDB 集群时如何配置监控。
## 快速开始
你可以在使用 Helm Chart 部署 GreptimeDB 集群时,通过对 `values.yaml` 文件进行配置来启用监控和 Grafana。下面是一个完整的 `values.yaml` 示例,用于部署一个最小化的带有监控和 Grafana 的 GreptimeDB 集群:
```yaml
image:
registry: greptime-registry.cn-hangzhou.cr.aliyuncs.com
# 镜像仓库:
# OSS GreptimeDB 使用 `greptime/greptimedb`,
# GreptimeDB 企业版配置请咨询工作人员
repository:
# 镜像标签:
# OSS GreptimeDB 使用数据库版本,例如 `v1.0.2`
# GreptimeDB 企业版配置请咨询工作人员
tag:
pullSecrets: []
initializer:
registry: greptime-registry.cn-hangzhou.cr.aliyuncs.com
repository: greptime/greptimedb-initializer
tag: "v0.6.0"
monitoring:
# 启用监控
enabled: true
# 监控数据的默认保留时间
ttl: 30d
vector:
# 监控需要使用 Vector
registry: greptime-registry.cn-hangzhou.cr.aliyuncs.com
grafana:
# 用于监控面板
# 需要先启用监控 `monitoring.enabled: true` 选项
enabled: true
image:
registry: greptime-registry.cn-hangzhou.cr.aliyuncs.com
frontend:
replicas: 1
meta:
replicas: 1
backendStorage:
etcd:
endpoints: ["etcd.etcd-cluster.svc.cluster.local:2379"]
datanode:
replicas: 1
flownode:
replicas: 1
```
当启用 `monitoring` 后,GreptimeDB Operator 会额外启动一个 GreptimeDB Standalone 实例用于收集 GreptimeDB 集群的指标和日志数据。
为了收集日志数据,GreptimeDB Operator 会在每一个 Pod 中启动一个 [Vector](https://vector.dev/) 的 Sidecar 容器。
当启用 `grafana` 后,会部署一个 Grafana 实例,并将用于集群监控的 GreptimeDB Standalone 实例作为其数据源。
这样就可以开箱即用地通过 Prometheus 和 MySQL 协议来可视化 GreptimeDB 集群的监控数据。
接下来使用上述配置的 `values.yaml` 文件来部署 GreptimeDB 集群:
```bash
helm upgrade --install mycluster \
greptime/greptimedb-cluster \
--values /path/to/values.yaml \
-n default
```
部署完成后,你可以用如下命令来查看 GreptimeDB 集群的 Pod 状态:
```bash
kubectl -n default get pods
```
期望输出
```bash
NAME READY STATUS RESTARTS AGE
mycluster-datanode-0 2/2 Running 0 77s
mycluster-flownode-0 2/2 Running 0 2m26s
mycluster-frontend-6ffdd549b-9s7gx 2/2 Running 0 66s
mycluster-grafana-675b64786-ktqps 1/1 Running 0 6m35s
mycluster-meta-58bc88b597-ppzvj 2/2 Running 0 86s
mycluster-monitor-standalone-0 1/1 Running 0 6m35s
```
你可以转发 Grafana 的端口到本地来访问 Grafana 仪表盘:
```bash
kubectl -n default port-forward svc/mycluster-grafana 18080:80
```
请参考[访问 Grafana 仪表盘](#访问-grafana仪表盘)章节来查看相应的数据面板。
## 配置监控数据的收集
本节将介绍监控配置的细节。
### 启用监控
在使用 Helm Chart 部署 GreptimeDB 集群时,在 [`values.yaml`](/user-guide/deployments-administration/deploy-on-kubernetes/deploy-greptimedb-cluster.md#setup-valuesyaml) 中添加以下配置来启用监控:
```yaml
monitoring:
enabled: true
```
这将部署一个名为 `${cluster-name}-monitoring` 的 GreptimeDB Standalone 实例来收集指标和日志。你可以使用以下命令验证部署:
```bash
kubectl get greptimedbstandalones.greptime.io ${cluster-name}-monitoring -n ${namespace}
```
GreptimeDB Standalone 实例使用 `${cluster-name}-monitoring-standalone` 作为 Kubernetes Service 名称来暴露服务。你可以使用以下地址访问监控数据:
- **Prometheus 指标**:`http://${cluster-name}-monitor-standalone.${namespace}.svc.cluster.local:4000/v1/prometheus`
- **SQL 日志**:`${cluster-name}-monitor-standalone.${namespace}.svc.cluster.local:4002`。默认情况下,集群日志存储在 `public._gt_logs` 表中。
### 自定义监控数据存储
默认情况下,GreptimeDB Standalone 实例使用 Kubernetes 默认的 StorageClass 将监控数据存储在本地存储中。
你可以通过 `values.yaml` 中的 `monitoring.standalone` 字段来配置 GreptimeDB Standalone 实例。例如,以下配置使用 S3 对象存储来存储监控数据:
```yaml
monitoring:
enabled: true
ttl: 30d
standalone:
base:
main:
# 用于配置 GreptimeDB Standalone 实例的镜像
image: "greptime-registry.cn-hangzhou.cr.aliyuncs.com/greptime/greptimedb:v1.0.2"
# 用于配置 GreptimeDB Standalone 实例的资源配置
resources:
requests:
cpu: "2"
memory: "4Gi"
limits:
cpu: "2"
memory: "4Gi"
# 用于配置 GreptimeDB Standalone 实例的对象存储
objectStorage:
s3:
# 用于配置 GreptimeDB Standalone 实例的对象存储的 bucket
bucket: "monitoring"
# 用于配置 GreptimeDB Standalone 实例的对象存储的 region
region: "ap-southeast-1"
# 用于配置 GreptimeDB Standalone 实例的对象存储的 secretName
secretName: "s3-credentials"
# 用于配置 GreptimeDB Standalone 实例的对象存储的 root
root: "standalone-with-s3-data"
```
### 自定义 Vector Sidecar
用于日志收集的 Vector Sidecar 配置可以通过 `monitoring.vector` 字段进行自定义。
例如,你可以按如下方式调整 Vector 的镜像和资源:
```yaml
monitoring:
enabled: true
ttl: 30d
vector:
# 用于配置 Vector 的镜像仓库
registry: greptime-registry.cn-hangzhou.cr.aliyuncs.com
# 用于配置 Vector 的镜像仓库
repository: timberio/vector
# 用于配置 Vector 的镜像标签
tag: "0.49.0-debian"
# 用于配置 Vector 的资源配置
resources:
requests:
cpu: "50m"
memory: "64Mi"
limits:
cpu: "250m"
memory: "256Mi"
```
### 使用 `kubectl` 部署的 YAML 配置
如果你没有使用 Helm Chart 部署 GreptimeDB 集群,
可以在 `GreptimeDBCluster` 的 YAML 中使用 `monitoring` 字段来手动配置自监控模式:
```yaml
monitoring:
enabled: true
```
详细的配置选项请参考 [`GreptimeDBCluster` API 文档](https://github.com/GreptimeTeam/greptimedb-operator/blob/main/docs/api-references/docs.md#monitoringspec)。
## Grafana 配置
### 启用 Grafana
在 `values.yaml` 中添加以下配置启用 Grafana 部署,
注意该功能必须先启用[监控(`monitoring.enabled: true`)配置](#启用监控):
```yaml
monitoring:
enabled: true
grafana:
enabled: true
```
### 自定义 Grafana 数据源
默认情况下,Grafana 使用 `mycluster` 和 `default` 作为集群名称和命名空间来创建数据源。
要监控其他名称或命名空间的集群,请根据实际的集群名称和命名空间自定义配置。
以下是 `values.yaml` 配置示例:
```yaml
monitoring:
enabled: true
grafana:
enabled: true
datasources:
datasources.yaml:
datasources:
# Query the cluster metrics.
- name: greptimedb-metrics
type: prometheus
url: http://${cluster-name}-monitor-standalone.${namespace}.svc.cluster.local:4000/v1/prometheus
access: proxy
# Query the cluster traces.
- name: greptimedb-traces
type: jaeger
url: http://${cluster-name}-monitor-standalone.${namespace}.svc.cluster.local:4000/v1/jaeger
access: proxy
# Query the cluster logs and slow queries.
- name: greptimedb-logs
type: mysql
url: ${cluster-name}-monitor-standalone.${namespace}.svc.cluster.local:4002
access: proxy
database: public
# Query the information schema from the cluster.
- name: information_schema
type: mysql
url: ${cluster-name}-frontend.${namespace}.svc.cluster.local:4002
access: proxy
database: information_schema
```
此配置会在 Grafana 中为 GreptimeDB 集群的监控创建以下数据源:
- **`greptimedb-metrics`**:用于存储监控数据的单机数据库中的集群指标,通过 Prometheus 协议提供服务(`type: prometheus`)。
- **`greptimedb-logs`**:用于存储监控数据的单机数据库中的集群日志,通过 MySQL 协议提供服务(`type: mysql`),默认使用 `public` 数据库。
- **`greptimedb-traces`**: 用于存储监控数据的单机数据库中的集群 traces,通过 Jaeger 协议提供服务 (`type: jaeger`)。
- **`information_schema`**: 用于存储数据库中的集群信息,通过 MySQL 协议提供服务 (`type: mysql`)。
### 访问 Grafana 仪表盘
你可以通过将 Grafana 服务端口转发到本地来访问 Grafana 仪表盘:
```bash
kubectl -n ${namespace} port-forward svc/${cluster-name}-grafana 18080:80
```
然后打开 `http://localhost:18080` 来访问 Grafana 仪表盘。
默认登录凭据为:
- **用户名**:`admin`
- **密码**:`gt-operator`
接着进入到 `Dashboards` 部分来查看用于监控 GreptimeDB 集群而预配置的仪表盘。

## 清理 PVC
:::danger
清理操作将移除 GreptimeDB 集群的元数据和数据,请确保在操作前已备份数据。
:::
请参考[清理 GreptimeDB 集群](/user-guide/deployments-administration/deploy-on-kubernetes/deploy-greptimedb-cluster.md#cleanup)文档
查看如何卸载 GreptimeDB 集群,
要清理 GreptimeDB 用于监控的单机数据库的 PVC,请使用以下命令:
```bash
kubectl -n default delete pvc -l app.greptime.io/component=${cluster-name}-monitor-standalone
```
---
## 运维关键日志
GreptimeDB 在运行过程中,会将一些关键的操作以及预期外的错误信息输出到日志中。
你可以通过这些日志了解 GreptimeDB 的运行情况,以及排查错误出现的原因。
## 日志位置
GreptimeDB 的组件默认都会输出 INFO 级别的日志到以下位置:
- 标准输出
- GreptimeDB 当前工作目录下的 `greptimedb_data/logs` 目录
日志文件的输出目录也可以通过配置文件的 `[logging]` 小节或者启动参数 `--log_dir` 修改:
```toml
[logging]
dir = "/path/to/logs"
```
日志文件格式为:
- `greptimedb.YYYY-MM-DD-HH` 包含 INFO 以上等级的日志
- `greptimedb-err.YYYY-MM-DD-HH` 包含错误日志
例如:
```bash
greptimedb.2025-04-11-06
greptimedb-err.2025-04-11-06
```
目前 GreptimeDB 的组件包括
- frontend
- datanode
- metasrv
- flownode
如果需要调整日志级别,如查看某组件 DEBUG 级别的日志,可以参考[这篇文档](https://github.com/GreptimeTeam/greptimedb/blob/main/docs/how-to/how-to-change-log-level-on-the-fly.md)在运行时进行修改。
## 重要日志
以下将列举建议关注的日志
### 错误日志
数据库在正常平稳运行时,不会输出错误日志。如果数据库的一些操作出现异常,或者出现了 panic,都会打印错误日志。建议用户检查所有组件的错误日志。
#### Panic
如果数据库出现了 panic ,则建议收集 panic 的日志反馈给官方。通常 panic 日志如下,关键字为 `panicked at`:
```bash
2025-04-02T14:44:24.485935Z ERROR common_telemetry::panic_hook: panicked at /greptime/.cargo/git/checkouts/datafusion-11a8b534adb6bd68-shallow/2464703/datafusion/expr/src/logical_plan/plan.rs:1035:25:
with_new_exprs for Distinct does not support sort expressions backtrace= 0: backtrace::backtrace::libunwind::trace
at /greptime/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/backtrace-0.3.74/src/backtrace/libunwind.rs:116:5
backtrace::backtrace::trace_unsynchronized
at /greptime/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/backtrace-0.3.74/src/backtrace/mod.rs:66:5
1: backtrace::backtrace::trace
at /greptime/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/backtrace-0.3.74/src/backtrace/mod.rs:53:14
2: backtrace::capture::Backtrace::create
at /greptime/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/backtrace-0.3.74/src/capture.rs:292:9
3: backtrace::capture::Backtrace::new
at /greptime/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/backtrace-0.3.74/src/capture.rs:257:22
4: common_telemetry::panic_hook::set_panic_hook::{{closure}}
at /greptime/codes/greptime/procedure-traits/src/common/telemetry/src/panic_hook.rs:37:25
5: as core::ops::function::Fn>::call
at /rustc/409998c4e8cae45344fd434b358b697cc93870d0/library/alloc/src/boxed.rs:1984:9
std::panicking::rust_panic_with_hook
at /rustc/409998c4e8cae45344fd434b358b697cc93870d0/library/std/src/panicking.rs:820:13
6: std::panicking::begin_panic_handler::{{closure}}
at /rustc/409998c4e8cae45344fd434b358b697cc93870d0/library/std/src/panicking.rs:678:13
7: std::sys::backtrace::__rust_end_short_backtrace
at /rustc/409998c4e8cae45344fd434b358b697cc93870d0/library/std/src/sys/backtrace.rs:168:18
8: rust_begin_unwind
at /rustc/409998c4e8cae45344fd434b358b697cc93870d0/library/std/src/panicking.rs:676:5
9: core::panicking::panic_fmt
at /rustc/409998c4e8cae45344fd434b358b697cc93870d0/library/core/src/panicking.rs:75:14
10: datafusion_expr::logical_plan::plan::LogicalPlan::with_new_exprs
at /greptime/.cargo/git/checkouts/datafusion-11a8b534adb6bd68-shallow/2464703/datafusion/expr/src/logical_plan/plan.rs:1035:25
11: ::analyze::{{closure}}
at /greptime/codes/greptime/procedure-traits/src/query/src/optimizer/type_conversion.rs:105:17
12: core::ops::function::impls::::call_mut
at /greptime/.rustup/toolchains/nightly-2024-12-25-aarch64-apple-darwin/lib/rustlib/src/rust/library/core/src/ops/function.rs:272:13
13: core::ops::function::impls::::call_once
at /greptime/.rustup/toolchains/nightly-2024-12-25-aarch64-apple-darwin/lib/rustlib/src/rust/library/core/src/ops/function.rs:305:13
14: datafusion_common::tree_node::Transformed::transform_parent
at /greptime/.cargo/git/checkouts/datafusion-11a8b534adb6bd68-shallow/2464703/datafusion/common/src/tree_node.rs:764:44
15: datafusion_common::tree_node::TreeNode::transform_up::transform_up_impl::{{closure}}
at /greptime/.cargo/git/checkouts/datafusion-11a8b534adb6bd68-shallow/2464703/datafusion/common/src/tree_node.rs:265:13
16: stacker::maybe_grow
at /greptime/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/stacker-0.1.17/src/lib.rs:55:9
datafusion_common::tree_node::TreeNode::transform_up::transform_up_impl
at /greptime/.cargo/git/checkouts/datafusion-11a8b534adb6bd68-shallow/2464703/datafusion/common/src/tree_node.rs:260:9
17: datafusion_common::tree_node::TreeNode::transform_up
at /greptime/.cargo/git/checkouts/datafusion-11a8b534adb6bd68-shallow/2464703/datafusion/common/src/tree_node.rs:269:9
18: datafusion_common::tree_node::TreeNode::transform
at /greptime/.cargo/git/checkouts/datafusion-11a8b534adb6bd68-shallow/2464703/datafusion/common/src/tree_node.rs:220:9
19: ::analyze
at /greptime/codes/greptime/procedure-traits/src/query/src/optimizer/type_conversion.rs:46:9
20: query::query_engine::state::QueryEngineState::optimize_by_extension_rules::{{closure}}
at /greptime/codes/greptime/procedure-traits/src/query/src/query_engine/state.rs:195:17
21: core::iter::traits::iterator::Iterator::try_fold
at /greptime/.rustup/toolchains/nightly-2024-12-25-aarch64-apple-darwin/lib/rustlib/src/rust/library/core/src/iter/traits/iterator.rs:2370:21
22: query::query_engine::state::QueryEngineState::optimize_by_extension_rules
at /greptime/codes/greptime/procedure-traits/src/query/src/query_engine/state.rs:192:9
23: query::planner::DfLogicalPlanner::plan_sql::{{closure}}::{{closure}}
at /greptime/codes/greptime/procedure-traits/src/query/src/planner.rs:119:20
24: as core::future::future::Future>::poll
at /greptime/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/tracing-0.1.40/src/instrument.rs:321:9
25: query::planner::DfLogicalPlanner::plan_sql::{{closure}}
at /greptime/codes/greptime/procedure-traits/src/query/src/planner.rs:71:5
26: ::plan::{{closure}}::{{closure}}
at /greptime/codes/greptime/procedure-traits/src/query/src/planner.rs:198:73
27: as core::future::future::Future>::poll
at /greptime/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/tracing-0.1.40/src/instrument.rs:321:9
28: ::plan::{{closure}}
at /greptime/codes/greptime/procedure-traits/src/query/src/planner.rs:195:5
...
```
### Metasrv
当 GreptimeDB 集群出现节点上线,节点下线,region 迁移,schema 变更等情况时, metasrv 都会记录相应的日志。因此,除了各个组件的错误日志外,也建议关注 metasrv 的以下日志关键字
#### Metasrv 切主/发起选举
```bash
// error 级别,标识当前 leader step down, 接下来会发生新的选举,注意 {:?} 这部分是 leader 标识
"Leader :{:?} step down"
```
#### Region 续租失败
```bash
// Warn 级别,表示一个 region 被拒绝续租,region 在某个 DN 上未被正常关闭/调度时,该 region 续租请求会被拒绝。
Denied to renew region lease for datanode: {datanode_id}, region_id: {region_id}
```
```bash
// Info 级别,DN 收到续租失败信息,并尝试关闭目标 region
Closing staled region:
```
#### Region Failover
```bash
// Warn 级别,发现部分 region 未通过 Phi 健康检测,需要执行 failover 操作,冒号后面好打印出相关的 region ids
Detects region failures:
// 某一个 region 迁移失败
Failed to wait region migration procedure
// Info 级别,当维护模式打开时,failover procedure 会被跳过。
Maintenance mode is enabled, skip failover
```
#### Region 迁移
```bash
// info 级别,表明某一个 region 开始迁移,日志后面会打印出 region 相关信息
Starting region migration procedure
// error 级别,某一个 region 迁移失败
Failed to wait region migration procedure
```
#### Procedure
Metasrv 内部通过一个叫做 procedure 的组件执行一些分布式操作。可以关注该组件的错误日志
```bash
Failed to execute procedure
```
#### Flow 创建失败
在创建 flow 失败时,通常在 procedure 的错误日志中可以看到失败的原因。日志可能包含以下关键字
```bash
Failed to execute procedure metasrv-procedure:: CreateFlow
```
### Datanode
#### Compaction
在 compaction 开始和结束时,datanode 上会有如下日志:
```bash
2025-05-16T06:01:08.794415Z INFO mito2::compaction::task: Compacted SST files, region_id: 4612794875904(1074, 0), input: [FileMeta { region_id: 4612794875904(1074, 0), file_id: FileId(a29500fb-cae0-4f3f-8376-cb3f14653378), time_range: (1686455010000000000::Nanosecond, 1686468410000000000::Nanosecond), level: 0, file_size: 45893329, available_indexes: [], index_file_size: 0, num_rows: 5364000, num_row_groups: 53, sequence: Some(114408000) }, FileMeta { region_id: 4612794875904(1074, 0), file_id: FileId(a31dcb1b-19ae-432f-8482-9e1b7db7b53b), time_range: (1686468420000000000::Nanosecond, 1686481820000000000::Nanosecond), level: 0, file_size: 45900506, available_indexes: [], index_file_size: 0, num_rows: 5364000, num_row_groups: 53, sequence: Some(119772000) }], output: [FileMeta { region_id: 4612794875904(1074, 0), file_id: FileId(5d105ca7-9e3c-4298-afb3-e85baae3b2e8), time_range: (1686455010000000000::Nanosecond, 1686481820000000000::Nanosecond), level: 1, file_size: 91549797, available_indexes: [], index_file_size: 0, num_rows: 10728000, num_row_groups: 105, sequence: Some(119772000) }], window: Some(86400), waiter_num: 0, merge_time: 3.034328293s
```
```bash
2025-05-16T06:01:08.805366Z INFO mito2::request: Successfully compacted region: 4612794875904(1074, 0)
```
---
## 使用 Prometheus 监控 GreptimeDB Cluster
在阅读本文档之前,请确保你已经了解如何[在 Kubernetes 上部署 GreptimeDB 集群](/user-guide/deployments-administration/deploy-on-kubernetes/deploy-greptimedb-cluster.md)。
我们推荐使用[自监控方法](cluster-monitoring-deployment.md)来监控 GreptimeDB 集群,
这种模式配置简单且提供了开箱即用的 Grafana 仪表板。
但如果你已经在 Kubernetes 集群中部署了 Prometheus 实例,并希望写入
GreptimeDB 集群的监控指标,请按照本文档中的步骤操作。
## 检查 Prometheus 实例配置
请先确保你已经部署 Prometheus Operator 并创建了 Prometheus 实例。例如,你可以使用 [kube-prometheus-stack](https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack) 来部署 Prometheus 技术栈。请参考其[官方文档](https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack)了解更多详情。
在部署 Prometheus 实例时,确保你设置了用于抓取 GreptimeDB 集群指标的标签。
例如,你现有的 Prometheus 实例包含下面的配置:
```yaml
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: greptime-podmonitor
namespace: default
spec:
selector:
matchLabels:
release: prometheus
# 其他配置...
```
当 `PodMonitor` 被部署后,
Prometheus Operator 会持续监视 `default` 命名空间中匹配 `spec.selector.matchLabels` 中定义的所有标签(在此示例中为 `release: prometheus`)的 Pod。
## 为 GreptimeDB 集群启用 `prometheusMonitor`
使用 Helm Chart 部署 GreptimeDB 集群时,
在你的 `values.yaml` 文件中启用 `prometheusMonitor` 字段。例如:
```yaml
prometheusMonitor:
# 启用 Prometheus 监控 - 这将创建 PodMonitor 资源
enabled: true
# 配置抓取间隔
interval: "30s"
# 配置标签
labels:
release: prometheus
```
**重要:** `labels` 字段的值(`release: prometheus`)
必须与创建 Prometheus 实例时使用的 `matchLabels` 的值匹配,
否则指标收集将无法正常工作。
配置 `prometheusMonitor` 后,
GreptimeDB Operator 将自动创建 `PodMonitor` 资源并按指定的时间间隔 `interval` 将指标导入到 Prometheus。
你可以使用以下命令检查 `PodMonitor` 资源:
```
kubectl get podmonitors.monitoring.coreos.com -n ${namespace}
```
:::note
如果你没有使用 Helm Chart 部署 GreptimeDB 集群,
可以在 `GreptimeDBCluster` YAML 中手动配置 Prometheus 监控:
```yaml
apiVersion: greptime.io/v1alpha1
kind: GreptimeDBCluster
metadata:
name: basic
spec:
base:
main:
image: greptime/greptimedb:v1.0.2
frontend:
replicas: 1
meta:
replicas: 1
backendStorage:
etcd:
endpoints:
- "etcd.etcd-cluster.svc.cluster.local:2379"
datanode:
replicas: 1
prometheusMonitor:
enabled: true
interval: "30s"
labels:
release: prometheus
```
:::
## Grafana 仪表板
你需要自己部署 Grafana,
然后导入仪表板。
### 添加数据源
部署 Grafana 后,
参考 Grafana 的[数据源](https://grafana.com/docs/grafana/latest/datasources/)文档添加以下两种类型的数据源:
- **Prometheus**:将其命名为 `metrics`。此数据源连接到你的收集 GreptimeDB 集群监控指标的 Prometheus 实例,因此请使用你的 Prometheus 实例 URL 作为连接 URL。
- **MySQL**:将其命名为 `information-schema`。此数据源连接到你的 GreptimeDB 集群,通过 SQL 协议访问集群元数据。如果你已经按照[在 Kubernetes 上部署 GreptimeDB 集群](/user-guide/deployments-administration/deploy-on-kubernetes/deploy-greptimedb-cluster.md)指南部署了 GreptimeDB,服务器地址为 `${cluster-name}-frontend.${namespace}.svc.cluster.local:4002`,数据库为 `information_schema`。
### 导入仪表板
[GreptimeDB 集群指标仪表板](https://github.com/GreptimeTeam/greptimedb/tree/v1.0.2/grafana/dashboards/metrics/cluster)使用 `metrics` 和 `information-schema` 数据源来显示 GreptimeDB 集群指标。
请参考 Grafana 的[导入仪表板](https://grafana.com/docs/grafana/latest/dashboards/build-dashboards/import-dashboards/)文档了解如何导入仪表板。
---
## 监控
数据库的有效管理在很大程度上依赖于监控。
你可以使用以下方法监控 GreptimeDB:
---
## 运行时信息
`INFORMATION_SCHEMA` 数据库提供了对系统元数据的访问,如数据库或表的名称、列的数据类型等。
* 通过 [CLUSTER_INFO](/reference/sql/information-schema/cluster-info.md) 表查找集群的拓扑信息。
* 通过 [PARTITIONS](/reference/sql/information-schema/partitions.md) 表和[REGION_PEERS](/reference/sql/information-schema/region-peers.md) 表查找表的 Region 分布。
例如查询一张表的所有 Region Id:
```sql
SELECT greptime_partition_id FROM PARTITIONS WHERE table_name = 'monitor'
```
查询一张表的 region 分布在哪些 datanode 上:
```sql
SELECT b.peer_id as datanode_id,
a.greptime_partition_id as region_id
FROM information_schema.partitions a LEFT JOIN information_schema.region_peers b
ON a.greptime_partition_id = b.region_id
WHERE a.table_name='monitor'
ORDER BY datanode_id ASC
```
请阅读[参考文档](/reference/sql/information-schema/overview.md)获取更多关于 `INFORMATION_SCHEMA` 数据库的信息。
---
## 慢查询(实验性功能)
GreptimeDB 提供了慢查询日志功能,帮助您发现和修复慢查询。默认情况下,慢查询会输出到系统表 `greptime_private.slow_queries` 中,阈值为 `30s`,采样率为 `1.0`,TTL 为 `30d`。
`greptime_private.slow_queries` 表的架构如下:
```sql
+--------------+----------------------+------+------+---------+---------------+
| Column | Type | Key | Null | Default | Semantic Type |
+--------------+----------------------+------+------+---------+---------------+
| cost | UInt64 | | NO | | FIELD |
| threshold | UInt64 | | NO | | FIELD |
| query | String | | NO | | FIELD |
| is_promql | Boolean | | NO | | FIELD |
| timestamp | TimestampNanosecond | PRI | NO | | TIMESTAMP |
| promql_range | UInt64 | | NO | | FIELD |
| promql_step | UInt64 | | NO | | FIELD |
| promql_start | TimestampMillisecond | | NO | | FIELD |
| promql_end | TimestampMillisecond | | NO | | FIELD |
+--------------+----------------------+------+------+---------+---------------+
```
- `cost`: 查询的执行时间,单位为毫秒。
- `threshold`: 慢查询的阈值,单位为毫秒。
- `query`: 查询语句。
- `is_promql`: 是否为 PromQL 查询。
- `timestamp`: 查询的时间戳。
- `promql_range`: 查询的时间范围。仅当 `is_promql` 为 `true` 时使用。
- `promql_step`: 查询的时间步长。仅当 `is_promql` 为 `true` 时使用。
- `promql_start`: 查询的开始时间。仅当 `is_promql` 为 `true` 时使用。
- `promql_end`: 查询的结束时间。仅当 `is_promql` 为 `true` 时使用。
在集群模式下,你可以在 frontend 配置中配置慢查询(与单机模式相同),例如:
```toml
[slow_query]
## 是否启用慢查询日志。
enable = true
## 慢查询的记录类型。可以是 `system_table` 或 `log`。
## 如果选择 `system_table`,慢查询将记录在系统表 `greptime_private.slow_queries` 中。
## 如果选择 `log`,慢查询将记录在日志文件 `greptimedb-slow-queries.*` 中。
record_type = "system_table"
## 慢查询的阈值。可以是可读的时间字符串,例如:`10s`,`100ms`,`1s`。
threshold = "30s"
## 慢查询日志的采样率。值应在 (0, 1] 范围内。例如,`0.1` 表示 10% 的慢查询将被记录,`1.0` 表示所有慢查询将被记录。
sample_ratio = 1.0
## `slow_queries` 系统表的 TTL。当 `record_type` 为 `system_table` 时,默认值为 `30d`。
ttl = "30d"
```
如果你使用 Helm 部署 GreptimeDB,可以在 `values.yaml` 文件中配置慢查询,例如:
```yaml
slowQuery:
enable: true
recordType: "system_table"
threshold: "30s"
sampleRatio: "1.0"
ttl: "30d"
```
如果使用 `log` 作为记录类型,慢查询将记录在日志文件 `greptimedb-slow-queries.*` 中。默认情况下,日志文件位于 `${data_home}/logs` 目录。
---
## 单机监控
GreptimeDB 单机版在 HTTP 端口(默认 `4000`)上提供 `/metrics` 端点,暴露 [Prometheus 指标](/reference/http-endpoints.md#指标)。
你可以使用 Prometheus 抓取这些指标,并使用 Grafana 进行可视化展示。
## Grafana 仪表板集成
GreptimeDB 为监控单机部署提供预构建的 Grafana 仪表板。你可以从 [GreptimeDB 代码库](https://github.com/GreptimeTeam/greptimedb/tree/v1.0.2/grafana/dashboards/metrics/standalone) 访问仪表板 JSON 文件。
---
## 链路追踪
GreptimeDB 支持分布式链路追踪。GreptimeDB 使用基于 gRPC 的 OTLP 协议导出所有采集到的 Span。您可以使用 [Jaeger](https://www.jaegertracing.io/)、[Tempo](https://grafana.com/oss/tempo/) 等支持基于 gRPC 的 OTLP 协议后端接收 GreptimeDB 采集到的 Span。
在配置中的 [logging 部分](/user-guide/deployments-administration/configuration.md#logging-选项) 有对 tracing 的相关配置项说明,[standalone.example.toml](https://github.com/GreptimeTeam/greptimedb/blob/v1.0.2/config/standalone.example.toml) 的 logging 部分提供了参考配置项。
## 动态链路追踪控制
GreptimeDB 提供了通过 HTTP API 在运行时动态启用或禁用链路追踪的功能,无需重启服务器。这对于排查生产环境问题或临时启用追踪进行调试非常有用。
启用链路追踪:
```bash
curl --data "true" http://127.0.0.1:4000/debug/enable_trace
# 输出: trace enabled
```
禁用链路追踪:
```bash
curl --data "false" http://127.0.0.1:4000/debug/enable_trace
# 输出: trace disabled
```
## 教程:使用 Jaeger 追踪 GreptimeDB 调用链路
[Jaeger](https://www.jaegertracing.io/) 是一个开源的、端到端的分布式链路追踪系统,最初由 Uber 开发并开源。它的目标是帮助开发人员监测和调试复杂的微服务架构中的请求流程。
Jaeger 支持基于 gRPC 的 OTLP 协议,所以 GreptimeDB 可以将跟踪数据导出到 Jaeger。以下教程向您展示如何部署和使用 Jaeger 来跟踪 GreptimeDB。
### 步骤一:部署 Jaeger
使用 jaeger 官方提供的 `all-in-one` docker 镜像启动一个 Jaeger 实例:
```bash
docker run --rm -d --name jaeger \
-e COLLECTOR_ZIPKIN_HOST_PORT=:9411 \
-p 6831:6831/udp \
-p 6832:6832/udp \
-p 5778:5778 \
-p 16686:16686 \
-p 4317:4317 \
-p 4318:4318 \
-p 14250:14250 \
-p 14268:14268 \
-p 14269:14269 \
-p 9411:9411 \
jaegertracing/all-in-one:latest
```
### 步骤二:部署 GreptimeDB
编写配置文件,允许 GreptimeDB 进行链路追踪。将下面的配置项保存为文件 `config.toml`
```Toml
[logging]
enable_otlp_tracing = true
```
之后使用 standalone 模式启动 GreptimeDB
```bash
greptime standalone start -c config.toml
```
参考章节 [Mysql](/user-guide/protocols/mysql.md) 如何连接到 GreptimeDB。在 Mysql Client 中运行下面的 SQL 语句:
```sql
CREATE TABLE host (
ts timestamp(3) time index,
host STRING PRIMARY KEY,
val BIGINT,
);
INSERT INTO TABLE host VALUES
(0, 'host1', 0),
(20000, 'host2', 5);
SELECT * FROM host ORDER BY ts;
DROP TABLE host;
```
### 步骤三:在 Jaeger 中获取 trace 信息
1. 转到 http://127.0.0.1:16686/ 并选择“Search”选项卡。
2. 在服务下拉列表中选择 `greptime-standalone` 服务。
3. 单击 **Find Traces** 以显示追踪到的链路信息。
## 指南:如何配置 tracing 采样率
GreptimeDB 提供了许多协议与接口,用于数据的插入、查询等功能。您可以通过 tracing 采集到每种操作的调用链路。但是对于某些高频操作,将所有该操作的 tracing 都采集下来,可能没有必要而且浪费存储空间。这个时候,您可以使用 `tracing_sample_ratio` 来对各种操作 tracing 的采样率进行设置,这样能够很大程度上减少导出 tracing 的数量并有利于系统观测。
GreptimeDB 根据接入的协议,还有该协议对应的操作,对所有 tracing 进行了分类:
| **protocol** | **request_type** |
|--------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| grpc | inserts / query.sql / query.logical_plan / query.prom_range / query.empty / ddl.create_database / ddl.create_table / ddl.alter / ddl.drop_table / ddl.truncate_table / ddl.empty / deletes / row_inserts / row_deletes |
| mysql | |
| postgres | |
| otlp | metrics / traces |
| opentsdb | |
| influxdb | write_v1 / write_v2 |
| prometheus | remote_read / remote_write / format_query / instant_query / range_query / labels_query / series_query / label_values_query |
| http | sql / promql
您可以通过 `tracing_sample_ratio` 来配置不同 tracing 的采样率。
```toml
[logging]
enable_otlp_tracing = true
[logging.tracing_sample_ratio]
default_ratio = 0.0
[[logging.tracing_sample_ratio.rules]]
protocol = "mysql"
ratio = 1.0
[[logging.tracing_sample_ratio.rules]]
protocol = "grpc"
request_types = ["inserts"]
ratio = 0.3
```
上述配置制定了两条采样规则,并制定了默认采样率,GreptimeDB 会根据您提供的采样规则,从第一条开始匹配,并使用第一条匹配到的采样规则作为该 tracing 的采样率,如果没有任何规则匹配,则 `default_ratio` 会被作为默认采样率被使用。采样率的范围是 `[0.0, 1.0]`, `0.0` 代表所有 tracing 都不采样,`1.0` 代表采样所有 tracing。
比如上面提供的规则,使用 mysql 协议接入的所有调用都将被采样,使用 grpc 插入的数据会被采样 30%,其余所有 tracing 都不会被采样。
---
## 运维部署及管理
GreptimeDB 可以部署在你自己的基础设施上,也可以通过全托管云服务 GreptimeCloud 进行管理。
本指南概述了部署策略、配置、监控和管理的相关内容。
## GreptimeDB 架构
在进行 GreptimeDB 的部署和管理之前,有必要了解其[架构](/user-guide/concepts/architecture.md)。
## 自托管 GreptimeDB 部署
本节概述了自托管环境中部署和管理 GreptimeDB 的关键点。
### 配置和部署
- **配置:** 在部署 GreptimeDB 前,[检查配置](configuration.md)以确保满足你的相关需要,包括协议设置、存储选项等。
- **鉴权:** 默认情况下鉴权没有被启动。了解如何[启用和配置鉴权](./authentication/overview.md)。
- **Kubernetes 部署:** 按照[部署指南](./deploy-on-kubernetes/overview.md)在 Kubernetes 上部署 GreptimeDB。
- **容量规划:** 通过[容量规划](/user-guide/deployments-administration/capacity-plan.md)确保集群能够处理业务所需的工作负载。
### 组件管理
- **Cluster Failover:** 通过设置 [Remote WAL](./wal/remote-wal/configuration.md) 以实现高可用性。
- **管理元数据:** 为 GreptimeDB 设置[元数据存储](./manage-data/overview.md)。
### 监控
- **监控:** 通过指标、Traces 和运行时信息[监控集群的健康状况和性能](./monitoring/overview.md)。
### 数据管理和性能
- **数据管理:** 通过[管理数据策略](/user-guide/deployments-administration/manage-data/overview.md) 以防止数据丢失、降低成本并优化性能。
- **性能调优:** 查看[性能调优技巧](/user-guide/deployments-administration/performance-tuning/performance-tuning-tips.md)并学习如何[设计表结构](/user-guide/deployments-administration/performance-tuning/design-table.md)以提高性能。
### 灾难恢复
- **灾难恢复:** 实施[灾难恢复策略](/user-guide/deployments-administration/disaster-recovery/overview.md)以保护你的数据并确保业务连续性。
### 其他
- **在 Android 上运行:** 了解如何[在 Android 设备上运行 GreptimeDB](run-on-android.md)。
- **升级:** 按照[升级指南](/user-guide/deployments-administration/upgrade.md)升级 GreptimeDB。
---
## 数据建模指南
表结构设计将极大影响写入和查询性能。
在写入数据之前,你需要了解业务中涉及到的数据类型、数据规模以及常用查询,
并根据这些数据特征进行数据建模。
本文档将详细介绍 GreptimeDB 的数据模型使用指南,以及常见场景的表结构设计方式。
## 了解 GreptimeDB 的数据模型
在阅读本文档之前,请先阅读 GreptimeDB [数据模型文档](/user-guide/concepts/data-model.md)。
## 基本概念
**基数(Cardinality)**:指数据集中唯一值的数量。可以分为"高基数"和"低基数":
- **低基数(Low Cardinality)**:低基数列通常具有固定值。
唯一值的总数通常不超过1万个。
例如,`namespace`、`cluster`、`http_method` 通常是低基数的。
- **高基数(High Cardinality)**:高基数列包含大量的唯一值。
例如,`trace_id`、`span_id`、`user_id`、`uri`、`ip`、`uuid`、`request_id`、表的自增 ID,时间戳通常是高基数的。
## 列类型
在 GreptimeDB 中,列被分为三种语义类型:`Tag`、`Field` 和 `Timestamp`。
时间戳通常表示数据采样的时间或日志/事件发生的时间。
GreptimeDB 使用 `TIME INDEX` 约束来标识 `Timestamp` 列。
因此,`Timestamp` 列也被称为 `TIME INDEX` 列。
如果你有多个时间戳数据类型的列,你只能将其中一个定义为 `TIME INDEX`,其他的定义为 `Field` 列。
在 GreptimeDB 中,Tag 列是可选的。Tag 列的主要用途包括:
1. 定义存储时数据的排序方式。
GreptimeDB 使用 `PRIMARY KEY` 约束来定义 tag 列和 tag 的排序顺序。
与传统数据库不同,GreptimeDB 的主键是用来定义时间序列的。
GreptimeDB 中的表按照 `(primary key, timestamp)` 的顺序对行进行排序。
这提高了具有相同 tag 数据的局部性。
如果没有定义 tag 列,GreptimeDB 按时间戳对行进行排序。
2. 唯一标识一个时间序列。
当表不是 append-only 模式时,GreptimeDB 根据时间戳在同一时间序列(主键)下去除重复行。
3. 便于从使用 label 或 tag 的其他时序数据库迁移。
这种顺序就是磁盘上 Parquet SST 文件中的物理行布局。
要了解数据在 SST 文件中如何组织,以及这种排序、tag 基数和索引为什么会影响性能,详见[存储引擎](/contributor-guide/datanode/storage-engine.md#sst-文件中的数据布局)文档。
## 主键
### 主键是可选的
错误的主键或索引可能会显著降低性能。
通常,你可以创建一个没有主键的仅追加表,因为对于许多场景来说,按时间戳排序数据已经有不错测性能了。
这也可以作为性能基准。
```sql
CREATE TABLE http_logs (
access_time TIMESTAMP TIME INDEX,
application STRING,
remote_addr STRING,
http_status STRING,
http_method STRING,
http_refer STRING,
user_agent STRING,
request_id STRING,
request STRING,
) with ('append_mode'='true');
```
`http_logs` 表是存储 HTTP 服务器日志的示例。
- `'append_mode'='true'` 选项将表创建为仅追加表。
这确保一个日志不会覆盖另一个具有相同时间戳的日志。
- 该表按时间对日志进行排序,因此按时间搜索日志效率很高。
### 主键设计与 SST 格式
当有适合的列且满足以下条件之一时,可以使用主键:
- 大多数查询可以从排序中受益。
- 你需要通过主键和时间索引对行进行去重(包括删除)。
例如,如果你总是只查询特定应用程序的日志,可以将 `application` 列设为主键(tag)。
```sql
SELECT message FROM http_logs WHERE application = 'greptimedb' AND access_time > now() - '5 minute'::INTERVAL;
```
应用程序的数量通常是有限的。表 `http_logs_v2` 使用 `application` 作为主键。
它按应用程序对日志进行排序,因此查询同一应用程序下的日志速度更快,因为它只需要扫描少量行。设置 tag 还能减少磁盘空间,因为它提高了数据的局部性,对压缩更友好。
```sql
CREATE TABLE http_logs_v2 (
access_time TIMESTAMP TIME INDEX,
application STRING,
remote_addr STRING,
http_status STRING,
http_method STRING,
http_refer STRING,
user_agent STRING,
request_id STRING,
request STRING,
PRIMARY KEY(application),
) with ('append_mode'='true');
```
过长的主键将对插入性能产生负面影响并增加内存占用。主键最好不超过 5 个列。
#### 选择合适的 SST 格式
GreptimeDB 支持两种 [SST 格式](/reference/sql/create.md#创建指定-sst-格式的表):`flat`(默认)和 `primary_key`。它们针对不同的主键基数进行了优化。
默认的 `flat` 格式适用于较广范围的主键基数,包括 `trace_id`、`span_id` 或 `user_id` 等高基数列。在 `flat` 格式下,当按某些列排序对查询有益,或者需要按这些列去重时,可以将高基数列放入主键。请注意,在高基数主键上进行去重始终是昂贵的——如果可以容忍重复,使用 append-only 表能获得最佳性能。
```sql
CREATE TABLE http_logs_v3 (
access_time TIMESTAMP TIME INDEX,
application STRING,
remote_addr STRING,
http_status STRING,
http_method STRING,
http_refer STRING,
user_agent STRING,
request_id STRING,
request STRING,
PRIMARY KEY(application, request_id),
) with ('append_mode'='true');
```
当主键基数较低时(通常不超过 10 万个不同值),`primary_key` 格式可能会带来更好的性能。一般情况下,建议优先使用默认的 `flat` 格式,除非你已经验证 `primary_key` 更适合你的场景。
你可以通过 `ALTER TABLE` 修改已有表的 SST 格式。GreptimeDB 旧版本默认使用 `primary_key` 格式,因此如果你从旧版本升级,或者不确定一张表当前使用的是哪种格式,可以将其切换为 `flat`:
```sql
-- 切换为 flat(默认)。
ALTER TABLE http_logs_v3 SET 'sst_format' = 'flat';
-- 在主键基数较低的场景下切换为 primary_key。
ALTER TABLE http_logs_v3 SET 'sst_format' = 'primary_key';
```
选取 tag 列的建议:
- 在 `WHERE`/`GROUP BY`/`ORDER BY` 中频繁出现的低基数列。
这些列通常很少变化。
例如,`namespace`、`cluster` 或 AWS `region`。
- 无需将所有低基数列设为 tag,因为这可能影响写入和查询性能。
- 通常对 tag 使用短字符串和整数,避免 `FLOAT`、`DOUBLE`、`TIMESTAMP`。
- 在默认的 `flat` 格式下,`trace_id`、`span_id` 和 `user_id` 等高基数列也可以作为 tag 使用。
## 索引
除了主键外,你还可以使用倒排索引按需加速特定查询。
GreptimeDB 支持倒排索引,可以加速对低基数列的过滤。
创建表时,可以使用 `INVERTED INDEX` 子句指定[倒排索引](/contributor-guide/datanode/data-persistence-indexing.md#倒排索引)列。
例如,`http_logs_v3` 为 `http_method` 列添加了倒排索引。
```sql
CREATE TABLE http_logs_v3 (
access_time TIMESTAMP TIME INDEX,
application STRING,
remote_addr STRING,
http_status STRING,
http_method STRING INVERTED INDEX,
http_refer STRING,
user_agent STRING,
request_id STRING,
request STRING,
PRIMARY KEY(application),
) with ('append_mode'='true');
```
以下查询可以使用 `http_method` 列上的倒排索引。
```sql
SELECT message FROM http_logs_v3 WHERE application = 'greptimedb' AND http_method = `GET` AND access_time > now() - '5 minute'::INTERVAL;
```
倒排索引支持以下运算符:
- `=`
- `<`
- `<=`
- `>`
- `>=`
- `IN`
- `BETWEEN`
- `~`
### 跳数索引
对于高基数列如 `trace_id`、`request_id`,使用[跳数索引](/user-guide/manage-data/data-index.md#跳数索引)更为合适。
这种方法的存储开销更低,资源使用量更少,特别是在内存和磁盘消耗方面。
示例:
```sql
CREATE TABLE http_logs_v4 (
access_time TIMESTAMP TIME INDEX,
application STRING,
remote_addr STRING,
http_status STRING,
http_method STRING INVERTED INDEX,
http_refer STRING,
user_agent STRING,
request_id STRING SKIPPING INDEX,
request STRING,
PRIMARY KEY(application),
) with ('append_mode'='true');
```
以下查询可以使用跳数索引过滤 `request_id` 列。
```sql
SELECT message FROM http_logs_v4 WHERE application = 'greptimedb' AND request_id = `25b6f398-41cf-4965-aa19-e1c63a88a7a9` AND access_time > now() - '5 minute'::INTERVAL;
```
然而,请注意跳数索引的查询功能通常不如倒排索引丰富。
跳数索引无法处理复杂的过滤条件,在低基数列上可能有较低的过滤性能。它只支持等于运算符。
### 全文索引
对于需要分词和按术语搜索的非结构化日志消息,GreptimeDB 提供了全文索引。
例如,`raw_logs` 表在 `message` 字段中存储非结构化日志。
```sql
CREATE TABLE IF NOT EXISTS `raw_logs` (
message STRING NULL FULLTEXT INDEX WITH(analyzer = 'English', case_sensitive = 'false'),
ts TIMESTAMP(9) NOT NULL,
TIME INDEX (ts),
) with ('append_mode'='true');
```
`message` 字段使用 `FULLTEXT INDEX` 选项进行全文索引。
更多信息请参见[fulltext 列选项](/reference/sql/create.md#fulltext-列选项)。
存储和查询结构化日志通常比带有全文索引的非结构化日志性能更好。
建议[使用 Pipeline](/user-guide/logs/quick-start.md#创建-pipeline) 将日志转换为结构化日志。
### 何时使用索引
GreptimeDB 中的索引十分灵活。
你可以为任何列创建索引,无论该列是 tag 还是 field。
为 time index 列创建额外索引没有意义。
另外,你一般不需要为所有列创建索引。
因为维护索引可能引入额外成本并阻塞 ingestion。
不良的索引可能会占用过多磁盘空间并使查询变慢。
你可以用没有额外索引的表作为 baseline。
如果查询性能已经可接受,就无需为表创建索引。
在以下情况可以为列创建索引:
- 该列在过滤条件中频繁出现。
- 没有索引的情况下过滤该列不够快。
- 该列有合适的索引类型。
下表列出了所有索引类型的适用场景。
| | 倒排索引 | 全文索引 | 跳数索引|
| ----- | ----------- | ------------- |------------- |
| 适用场景 | - 过滤低基数列 | - 文本内容搜索 | - 精确过滤高基数列 |
| 创建方法 | - 使用 `INVERTED INDEX` 指定 |- 在列选项中使用 `FULLTEXT INDEX` 指定 | - 在列选项中使用 `SKIPPING INDEX` 指定 |
## 去重
如果需要去重,可以使用默认表选项,相当于将 `append_mode` 设为 `false` 并启用去重功能。
```sql
CREATE TABLE IF NOT EXISTS system_metrics (
host STRING,
cpu_util DOUBLE,
memory_util DOUBLE,
disk_util DOUBLE,
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY(host),
TIME INDEX(ts)
);
```
当表不是 append-only 的时候,GreptimeDB 会通过相同的主键和时间戳对行进行去重。
例如,`system_metrics` 表通过 `host` 和 `ts` 删除重复行。
### 数据更新和合并
GreptimeDB 支持两种不同的去重策略:`last_row` 和 `last_non_null`。
你可以通过 `merge_mode` 表选项来指定策略。
GreptimeDB 使用基于 LSM-Tree 的存储引擎,
不会就地覆盖旧数据,而是允许多个版本的数据共存。
这些版本在查询时再合并。
默认的合并行为是 `last_row`,意味着只保留最近插入的行。
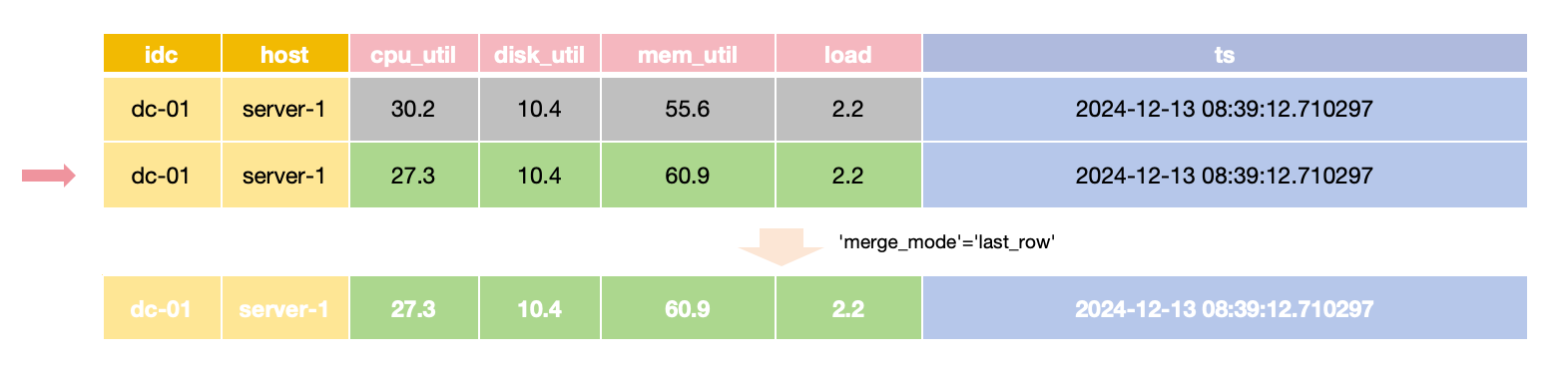
在 `last_row` 合并模式下,
对于相同主键和时间值,只返回最新的行,
所以更新一行时需要提供所有 field 的值。
对于只需要更新特定 field 值而其他 field 保持不变的场景,
可以将 `merge_mode` 选项设为 `last_non_null`。
该模式在查询时会选取每个字段的最新的非空值,
这样可以在更新时只提供需要更改的 field 的值。
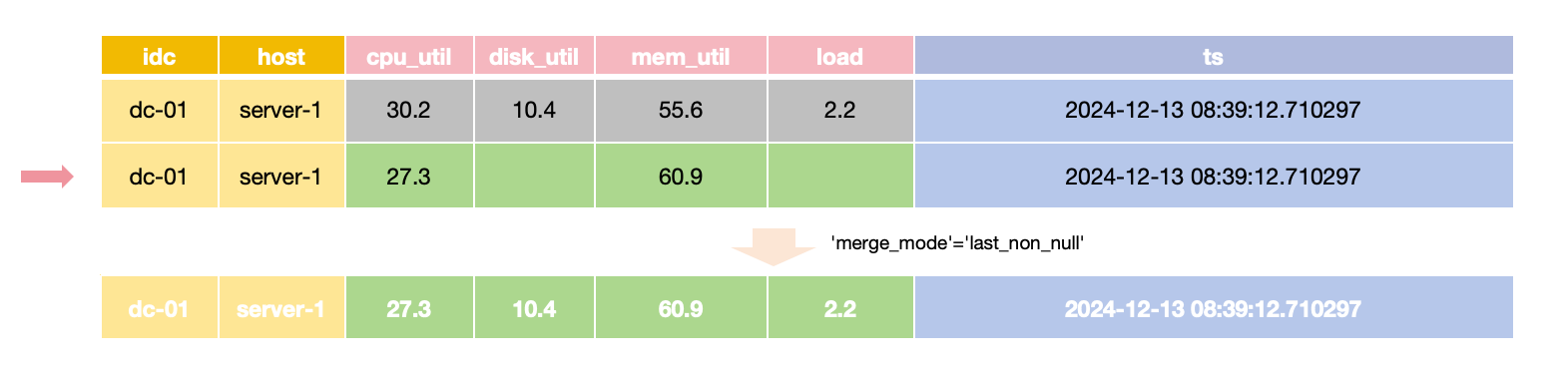
为了与 InfluxDB 的更新行为一致,通过 InfluxDB line protocol 自动创建的表默认启用 `last_non_null` 合并模式。
`last_row` 合并模式不需要检查每个单独的字段值,因此通常比 `last_non_null` 模式更快。
请注意,append-only 表不能设置 `merge_mode`,因为它们不执行合并。
### 何时使用 append-only 表
如果不需要以下功能,可以使用 append-only 表:
- 去重
- 删除
GreptimeDB 通过去重功能实现 `DELETE`,因此 append-only 表目前不支持删除。
去重需要更多的计算并限制了写入和查询的并行性,所以使用 append-only 表通常具有更好的性能。
## 宽表 vs. 多表
在监控或 IoT 场景中,通常同时收集多个指标。
我们建议将同时收集的指标放在单个表中,以提高读写吞吐量和数据压缩效率。
比较遗憾,Prometheus 的存储还是多表单值的方式,不过 GreptimeDB 的 Prometheus Remote Storage protocol 通过[Metric Engine](/contributor-guide/datanode/metric-engine.md)在底层使用宽表数据共享。
## 分布式表
GreptimeDB 支持对数据表进行分区,以分散读写热点并实现水平扩展。
### 关于分布式表的两个误解
作为时序数据库,GreptimeDB 在存储层自动基于 TIME INDEX 列对数据进行分区。
因此,你无需也不建议按时间分区数据
(例如,每天一个分区或每周一个表)。
此外,GreptimeDB 是列式存储数据库,
因此对表进行分区是指按行进行水平分区,
每个分区包含所有列。
### 何时分区以及确定分区数量
单个表能够利用机器中的所有资源,特别是在查询的时候。
分区表并不总是能提高性能:
- 分布式查询计划并不总是像本地查询计划那样高效。
- 分布式查询可能会引入网络间额外的数据传输。
因此,除非单台机器不足以服务表,否则无需分区表。
例如:
- 本地磁盘空间不足以存储数据或在使用对象存储时缓存数据。
- 你需要更多 CPU 来提高查询性能或更多内存用于高开销的查询。
- 磁盘吞吐量成为瓶颈。
- 写入速率大于单个节点的吞吐量。
GreptimeDB 在每次主要版本更新时都会发布[benchmark report](https://github.com/GreptimeTeam/greptimedb/tree/v1.0.2/docs/benchmarks/tsbs),
里面提供了单个分区的写入吞吐量作为参考。
你可以在你的目标场景根据该报告来估计写入量是否接近单个分区的限制。
估计分区总数时,可以考虑写入吞吐量并额外预留 50% 的 CPU 资源,以确保查询性能和稳定性。也可以根据需要调整此比例。例如,如果查询较多,那么可以预留更多 CPU 资源。
### 分区方法
GreptimeDB 使用表达式定义分区规则。
为获得最佳性能,建议选择均匀分布、稳定且与查询条件一致的分区键。
例如:
- 按 trace id 的前缀分区。
- 按数据中心名称分区。
- 按业务名称分区。
分区键应该尽量贴合查询条件。
例如,如果大多数查询针对特定数据中心的数据,那么可以使用数据中心名称作为分区键。
如果不了解数据分布,可以对现有数据执行聚合查询以收集相关信息。
更多详情,请参考[表分区指南](/user-guide/deployments-administration/manage-data/table-sharding.md#partition)
---
## 性能调优技巧
GreptimeDB 实例的默认配置可能不适合所有场景。因此根据场景调整数据库配置和使用方式相当重要。
GreptimeDB 提供了各种指标来帮助监控和排查性能问题。官方仓库里提供了用于独立模式和集群模式的 [Grafana dashboard 模版](https://github.com/GreptimeTeam/greptimedb/tree/main/grafana)。
## 查询
### ANALYZE QUERY
GreptimeDB 支持查询分析功能,通过 `EXPLAIN ANALYZE [VERBOSE] ` 语句可以看到逐步的查询耗时。
### 指标
以下指标可用于诊断查询性能问题:
| 指标 | 类型 | 描述 |
|---|---|---|
| greptime_mito_read_stage_elapsed_bucket | histogram | 存储引擎中查询不同阶段的耗时。 |
| greptime_mito_cache_bytes | gauge | 缓存内容的大小 |
| greptime_mito_cache_hit | counter | 缓存命中总数 |
| greptime_mito_cache_miss | counter | 缓存未命中总数 |
### 增大缓存大小
可以监控 `greptime_mito_cache_bytes` 和 `greptime_mito_cache_miss` 指标来确定是否需要增加缓存大小。这些指标中的 `type` 标签表示缓存的类型。
如果 `greptime_mito_cache_miss` 指标一直很高并不断增加,或者 `greptime_mito_cache_bytes` 指标达到缓存容量,可能需要调整存储引擎的缓存大小配置。
以下是一个例子:
```toml
[[region_engine]]
[region_engine.mito]
# 写入缓存的缓存大小。此缓存的 `type` 标签值为 `file`。
write_cache_size = "10G"
# 在写入缓存未命中时从对象存储下载文件填充缓存
enable_refill_cache_on_read = true
# SST 元数据的缓存大小。此缓存的 `type` 标签值为 `sst_meta`。
sst_meta_cache_size = "128MB"
# 向量和箭头数组的缓存大小。此缓存的 `type` 标签值为 `vector`。
vector_cache_size = "512MB"
# SST 行组页面的缓存大小。此缓存的 `type` 标签值为 `page`。
page_cache_size = "512MB"
# 时间序列查询结果(例如 `last_value()`)的缓存大小。此缓存的 `type` 标签值为 `selector_result`。
selector_result_cache_size = "512MB"
[region_engine.mito.index]
## 索引暂存目录的最大容量。
staging_size = "10GB"
```
一些建议:
- 至少将写入缓存设置为磁盘空间的 1/10。使用对象存储时,建议使用较大的写入缓存。
- 使用对象存储时,GreptimeDB 默认在缓存未命中时自动下载文件以填充写入缓存(`enable_refill_cache_on_read = true`)。这可以提高查询性能,但会增加网络流量。如果你想减少网络使用或存储成本,可以考虑禁用此选项。
- 如果数据库内存使用率低于 20%,则可以至少将 `page_cache_size` 设置为总内存大小的 1/4
- 如果缓存命中率低于 50%,则可以将缓存大小翻倍
- 如果使用全文索引,至少将 `staging_size` 设置为磁盘空间的 1/10
### 选择合适的 SST 格式
GreptimeDB 支持两种 [SST 格式](/reference/sql/create.md#创建指定-sst-格式的表):`flat` 和 `primary_key`。根据主键的基数选择合适的格式可以显著提升性能。
- **`flat` 格式(默认)**:针对高基数主键进行了优化。如果主键包含 `trace_id` 或 `uuid` 等列,`flat` 格式可以提供更好的写入和查询性能。对于具有高基数主键的表,还可以考虑使用 [append-only](/reference/sql/create.md#创建-append-only-表) 表来进一步提升性能。
- **`primary_key` 格式**:当主键基数不高时,可能会提供更好的性能。
更多细节(包括如何修改已有表的格式)请参阅[选择合适的 SST 格式](/user-guide/deployments-administration/performance-tuning/design-table.md#选择合适的-sst-格式)。
### 尽可能使用 append-only 表
一般来说,append-only 表具有更高的扫描性能,因为存储引擎可以跳过合并和去重操作。此外,如果表是 append-only 表,查询引擎可以使用统计信息来加速某些查询。
如果表不需要去重或性能优先于去重,我们建议为表启用 [append_mode](/reference/sql/create.md#创建-append-only-表)。例如,日志表应该是 append-only 表,因为日志消息可能具有相同的时间戳。
### 禁用预写式日志(WAL)
如果您是从 Kafka 等可以重放的数据源消费并写入到 GreptimeDB,可以通过禁用 WAL 来进一步提升写入吞吐量。
请注意,当 WAL 被禁用后,未刷新到磁盘或对象存储的数据将无法恢复,需要从原始数据源重新恢复,比如重新从 Kafka 读取或重新抓取日志。
通过设置表选项 `skip_wal='true'` 来禁用 WAL:
```sql
CREATE TABLE logs(
message STRING,
ts TIMESTAMP TIME INDEX
) WITH (skip_wal = 'true');
```
## 写入
### 指标
以下指标有助于诊断写入问题:
| 指标 | 类型 | 描述 |
|---|---|---|
| greptime_mito_write_stage_elapsed_bucket | histogram | 存储引擎中处理写入请求的不同阶段的耗时 |
| greptime_mito_write_buffer_bytes | gauge | 当前为写入缓冲区(memtables)分配的字节数(估算) |
| greptime_mito_write_rows_total | counter | 写入存储引擎的行数 |
| greptime_mito_write_stall_total | gauge | 当前由于内存压力过高而被阻塞的行数 |
| greptime_mito_write_reject_total | counter | 由于内存压力过高而被拒绝的行数 |
| raft_engine_sync_log_duration_seconds_bucket | histogram | 将 WAL 刷入磁盘的耗时 |
| greptime_mito_flush_elapsed | histogram | 刷入 SST 文件的耗时 |
### 批量写入行
批量写入是指通过同一个请求将多行数据发送到数据库。这可以显著提高写入吞吐量。建议的起始值是每批 1000 行。如果延迟和资源使用仍然可以接受,可以扩大攒批大小。
### 按时间窗口写入
虽然 GreptimeDB 可以处理乱序数据,但乱序数据仍然会影响性能。GreptimeDB 从写入的数据中推断出时间窗口的大小,并根据时间戳将数据划分为多个时间窗口。如果写入的行不在同一个时间窗口内,GreptimeDB 需要将它们拆分,这会影响写入性能。
通常,实时数据不会出现上述问题,因为它们始终使用最新的时间戳。如果需要将具有较长时间范围的数据导入数据库,我们建议提前创建表并 [指定 compaction.twcs.time_window 选项](/reference/sql/create.md#创建自定义-compaction-参数的表)。
## 表结构
### 使用多值
在设计架构时,我们建议将可以一起收集的相关指标放在同一个表中。这也可以提高写入吞吐量和压缩率。
例如,以下三个表收集了 CPU 的使用率指标。
```sql
CREATE TABLE IF NOT EXISTS cpu_usage_user (
hostname STRING NULL,
usage_value BIGINT NULL,
ts TIMESTAMP(9) NOT NULL,
TIME INDEX (ts),
PRIMARY KEY (hostname)
);
CREATE TABLE IF NOT EXISTS cpu_usage_system (
hostname STRING NULL,
usage_value BIGINT NULL,
ts TIMESTAMP(9) NOT NULL,
TIME INDEX (ts),
PRIMARY KEY (hostname)
);
CREATE TABLE IF NOT EXISTS cpu_usage_idle (
hostname STRING NULL,
usage_value BIGINT NULL,
ts TIMESTAMP(9) NOT NULL,
TIME INDEX (ts),
PRIMARY KEY (hostname)
);
```
我们可以将它们合并为一个具有三个字段的表。
```sql
CREATE TABLE IF NOT EXISTS cpu (
hostname STRING NULL,
usage_user BIGINT NULL,
usage_system BIGINT NULL,
usage_idle BIGINT NULL,
ts TIMESTAMP(9) NOT NULL,
TIME INDEX (ts),
PRIMARY KEY (hostname)
);
```
---
## 在安卓平台运行
从 v0.4.0 开始,GreptimeDB 支持在采用了 ARM64 CPU 和 Android API 23 版本以上的安卓平台运行。
## 安装终端模拟器
您可以从 [GitHub release 页面](https://github.com/termux/termux-app/releases/latest) 下载 [Termux 终端模拟器](https://termux.dev/) 来运行 GreptimeDB.
## 下载 GreptimeDB 的二进制
请执行以下命令来下载安卓平台的 GreptimeDB 二进制:
```bash
VERSION=$(curl -sL \
-H "Accept: application/vnd.github+json" \
-H "X-GitHub-Api-Version: 2022-11-28" \
"https://api.github.com/repos/GreptimeTeam/greptimedb/releases/latest" | sed -n 's/.*"tag_name": "\([^"]*\)".*/\1/p')
curl -sOL "https://github.com/GreptimeTeam/greptimedb/releases/download/${VERSION}/greptime-android-arm64-${VERSION}.tar.gz"
tar zxvf ./greptime-android-arm64-${VERSION}.tar.gz
./greptime -V
```
如果下载成功,以上命令将输出当前 GreptimeDB 的版本信息。
## 创建 GreptimeDB 的配置文件
您可以通过以下命令来创建一个最小化的配置文件以允许从局域网访问 GreptimeDB:
```bash
DATA_DIR="$(pwd)/greptimedb-data"
mkdir -p ${DATA_DIR}
cat < ./config.toml
[http]
addr = "0.0.0.0:4000"
[grpc]
bind_addr = "0.0.0.0:4001"
[mysql]
addr = "0.0.0.0:4002"
[storage]
data_home = "${DATA_DIR}"
type = "File"
EOF
```
## 从命令行启动 GreptimeDB
```bash
./greptime --log-dir=$(pwd)/logs standalone start -c ./config.toml
```
## 从局域网连接运行在安卓设备上的 GreptimeDB
> 您可以通过`ifconfig`来获取您所使用的安卓设备的网络地址。
在启动 GreptimeDB 后,您可以从局域网内安装了 MySQL 客户端的设备上通过 MySQL 协议访问 GreptimeDB。
```bash
mysql -h -P 4002
```
连接成功后,您可以像在任何其他平台一样使用运行在安卓设备上的 GreptimeDB!
```
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 8
Server version: 5.1.10-alpha-msql-proxy Greptime
Copyright (c) 2000, 2023, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> CREATE TABLE monitor (env STRING, host STRING, ts TIMESTAMP, cpu DOUBLE DEFAULT 0, memory DOUBLE, TIME INDEX (ts), PRIMARY KEY(env,host));
Query OK, 0 rows affected (0.14 sec)
mysql> INSERT INTO monitor(ts, env, host, cpu, memory) VALUES
-> (1655276557000,'prod', 'host1', 66.6, 1024),
-> (1655276557000,'prod', 'host2', 66.6, 1024),
-> (1655276557000,'prod', 'host3', 66.6, 1024),
-> (1655276558000,'prod', 'host1', 77.7, 2048),
-> (1655276558000,'prod', 'host2', 77.7, 2048),
-> (1655276558000,'test', 'host3', 77.7, 2048),
-> (1655276559000,'test', 'host1', 88.8, 4096),
-> (1655276559000,'test', 'host2', 88.8, 4096),
-> (1655276559000,'test', 'host3', 88.8, 4096);
Query OK, 9 rows affected (0.14 sec)
mysql>
mysql> select * from monitor where env='test' and host='host3';
+------+-------+---------------------+------+--------+
| env | host | ts | cpu | memory |
+------+-------+---------------------+------+--------+
| test | host3 | 2022-06-15 15:02:38 | 77.7 | 2048 |
| test | host3 | 2022-06-15 15:02:39 | 88.8 | 4096 |
+------+-------+---------------------+------+--------+
2 rows in set (0.20 sec)
```
---
## 问题排查
在遇到错误或者性能问题时,我们可以基于指标和日志了解 GreptimeDB 的状态。这些信息也可以帮助进一步排查问题的原因。
以下列举了部分常见异常情况的排查方法。对于无法简单定位原因的情况,提供指标和日志给官方团队也能提高官方排查问题的效率。
## 查看 CPU 和 Memory 负载
可直接从 Dashboard 中查看对应组件的 CPU 和 Memory 负载,其中 CPU 显示的是 millicore,Memory 则是当前进程的 RSS。此时需要要关注对应的 CPU 和 Memory 负载是否有超过 Pod 的 Limit,如果 CPU 已经触碰到 Pod 的 Limit,那么将会触发 throttle,用户可感受的现象就是请求处理变慢;如果 Memory 已经到达 Limit 超过 70%,那么将有可能会被 OOM。
## 创建 flow 失败
创建 flow 失败时,一个场景的原因是没有部署 flownode,可以检查
- 集群中是否部署了 flownode
- 集群中 flownode 状态是否 READY
如果已经部署了 flownode,则可以通过排查 metasrv 和 flownode 的日志进一步排查,也可以通过内部表查看 flow 节点是否成功创建:
```sql
select * from information_schema.cluster_info;
```
## 对象存储配置问题
对象存储配置不对时,GreptimeDB 访问对象存储会出现异常。如果 GreptimeDB 没有存储任何数据,一般不需要访问对象存储,因此刚部署完成时可能观察不到错误。当创建一张表或者开始通过写入协议往 GreptimeDB 写入数据后,则可以观察到请求报错。
通常 DB 返回错误信息会包含对象存储的报错。可以通过 DB 的错误日志找到对象存储具体的报错信息。一些常见的错误原因包括
- Access Key 或 Secret Access Key 填写错误
- 对象存储的权限配置不对
- 如果使用的是腾讯云 COS 的 S3 兼容 API,由于腾讯云[禁用了 path-style 域名](https://cloud.tencent.com/document/product/436/102489),需要在 GreptimeDB 的 S3 配置中设置 `enable_virtual_host_style = true`
以 S3 为例,GreptimeDB 需要用到的权限包括
```txt
"s3:PutObject",
"s3:ListBucket",
"s3:GetObject",
"s3:DeleteObject"
```
## 写入吞吐低
通过大盘里的 Ingestion 相关面板可以观察到写入的吞吐:
如果写入吞吐低于预期压力,那么有可能是写入延时较高,DB 出现积压导致的。大盘在 `Frontend Requests` 区域中提供了一些面板来观察请求的耗时:
你可以通过 `Mito Engine` 区域的 `Write Stall` 面板观察是否有节点出现了 stall(stall 的值长时间超过 0)。
如果有,则说明节点写入出现了瓶颈。
通过观察 `Write Buffer` 的面板也可以观察用于写入的 buffer 的大小变化,如果 buffer 很快被写满,那么可以考虑成比例调大 `global_write_buffer_size` 和 `global_write_buffer_reject_size`:
通过 Write Stage 面板可以查看写入耗时高的阶段:
可以通过 Compaction/Flush 相关面板查看后台任务的情况
- 是否出现频繁的 flush 操作,如果有,则可以考虑成比例调大 `global_write_buffer_size` 和 `global_write_buffer_reject_size`
- 是否有长时间的 compaction 和 flush 操作,如果有,则写入有可能受这些后台任务影响
此外,通过日志里 `flush memtables` 相关的日志可以看到单次 flush 的耗时,
## 写入内存消耗过高
DB 写入过程中会估算出当前所有 memtable 的总大小。可以通过 `Write Buffer` 面板查看 memtable 的内存占用。
注意这部分的值可能比实际申请的内存要小。
如果发现写入时 DB 的内存增长速度过快,或者写入经常出现 OOM 的情况,则可能跟表结构设计不合理有关。
一个常见的原因是主键(Primary Key)设计不合理。如果主键的数量过多,则会导致写入时消耗非常多的内存,可能导致数据库内存占用过大。出现这种情况时,往往 `Write Buffer` 会长期处于高位置。这种情况增加写入 buffer 的大小一般不会改善问题,需要减少主键的列数,或者去掉高基数的主键列。
## 查询耗时高
如果查询的耗时较高,可以通过在查询前面加上 `EXPLAIN ANALYZE` 或 `EXPLAIN ANALYZE VERBOSE` 重新执行。查询的结果会带上各个阶段执行的耗时用于协助排查。
此外 `Read Stage` 的面板也能协助了解不同阶段的查询耗时:
## 缓存写满
如果需要了解各个缓存的大小,可以通过 `Cached Bytes` 面板查询节不同缓存已经使用的大小:
对于查询耗时高的节点,也可以通过查询缓存大小来判断是否缓存已经写满。
## 对象存储耗时
可以通过大盘中的 `OpenDAL` 区域的面板查看对象存储操作的耗时,例如以下面板是对象存储写入操作的响应耗时:
如果怀疑对象存储操作出现抖动,可以观察相关的面板。
---
## 版本升级
## 概览
本指南提供 GreptimeDB 的升级说明,包括每个版本的兼容性信息和破坏性变更。升级前,请确保查看与你的升级路径相关的破坏性变更。
完整的版本历史和功能新增,请参见[发行说明](/release-notes/)。
## 升级到 v1.0 的路径
### 从 v0.16 到 v1.0
如果你当前运行的是 v0.16,可以直接升级到 v1.0。请参见[从 v0.16 升级到 v1.0](#从-v016-升级到-v10) 了解所有相关的破坏性变更。
### 从 v0.17 到 v1.0
如果你当前运行的是 v0.17,可以直接升级到 v1.0。请参见[从 v0.17 升级到 v1.0](#从-v017-升级到-v10) 了解破坏性变更。
### 从更早版本升级
**重要提示:** 本指南仅涵盖从 v0.16 及更高版本的升级。
如果你运行的版本早于 v0.16,必须先按照当前版本的升级文档升级到 v0.16。成功升级到 v0.16 后,再使用本指南升级到 v1.0。
## 各版本的破坏性变更
### 从 v0.17 升级到 v1.0
#### 移除 Jaeger HTTP Header
**影响:** HTTP header 废弃
HTTP header `x-greptime-jaeger-time-range-for-operations` 已被废弃并移除。
**需要的操作:**
- 如果你在 Jaeger 数据源或代理中配置了此 header,请从配置中移除
- 此 header 将不再有任何效果
#### Metric Engine 默认启用稀疏主键编码
**影响:** 默认配置变更,带来性能提升
Metric Engine 现在默认启用**稀疏主键编码**,以提高指标场景的存储效率和查询性能。
**配置变更:**
- **新的默认值:** `sparse_primary_key_encoding = true`
- **已废弃:** `experimental_sparse_primary_key_encoding`(请使用 `sparse_primary_key_encoding` 代替)
**需要的操作:**
- 此变更不会导致数据格式兼容性问题
- 所有指标表将默认自动使用稀疏编码
- 如果想继续使用旧的编码方法,请显式设置:
```toml
[metric_engine]
sparse_primary_key_encoding = false
```
#### `greptime_identity` Pipeline JSON 行为变更
**影响:** JSON 处理逻辑变更
`greptime_identity` pipeline 中的 JSON 处理逻辑发生了重大变化:
**新行为:**
- 嵌套的 JSON 对象会自动展平为使用点号分隔的独立列(例如 `object.a`、`object.b`)
- 数组存储为 JSON 字符串而不是 JSON 对象
- `flatten_json_object` 参数已被移除
- 新的 `max_nested_levels` 参数控制展平深度(默认:10 层)
- 当超过深度限制时,剩余的嵌套结构将序列化为 JSON 字符串
**需要的操作:**
1. 检查使用 `greptime_identity` 的 pipeline 配置
2. 移除已废弃的 `flatten_json_object` 参数的任何使用
3. 调整引用嵌套 JSON 字段的查询以使用新的点号表示法
4. 如果有深层嵌套的 JSON(>10 层),考虑适当设置 `max_nested_levels`
**示例:**
v0.17 之前:
```json
{ "user": { "name": "Alice", "age": 30 } }
```
存储为单个 JSON 列。
v1.0 之后:
```
user.name = "Alice"
user.age = 30
```
存储为独立的列。
#### Metric Engine TSID 生成算法变更
**影响:** 时间序列 ID 生成优化,对查询有影响
TSID(时间序列 ID)生成算法已通过将 `mur3::Hasher128` 替换为高性能的 `fxhash::FxHasher` 进行优化,包括针对没有 NULL 标签的序列的快速路径。
**性能提升:**
- 常规场景:快 5-6 倍
- 包含 NULL 标签的场景:快约 2.5 倍
**破坏性变更影响:**
这是一个**破坏性变更**,影响时间序列识别:
- **升级前(时间 < t):** 数据使用旧算法生成 TSID
- **升级后(时间 > t):** 数据使用新算法生成 TSID
**查询行为:**
- 时间范围**跨越升级时间 `t`** 的查询可能在时间 `t` 附近出现轻微的时间序列匹配差异
- 时间范围**不包含 `t`** 的查询不受影响
**需要的操作:**
选择以下升级策略之一:
1. **直接升级(推荐给大多数用户):**
- 接受升级时间附近的轻微查询差异
- 适用于可以接受升级时间附近近似结果的场景
2. **导出-升级-导入(零容忍场景):**
- 如果无法接受任何差异,使用此完全兼容的升级方法:
1. 升级前导出所有数据
2. 升级到 v1.0
3. 将数据导入回新版本
- 参考[备份与恢复文档](/user-guide/deployments-administration/disaster-recovery/back-up-&-restore-data/)
### 从 v0.16 升级到 v1.0
如果你从 v0.16 升级,需要查看:
1. **从 v0.17 到 v1.0 的所有破坏性变更**(如上所列)
2. **v0.17.0 的破坏性变更**(如下所列)
这确保你了解 v0.16 和 v1.0 之间发生的所有变更。
### v0.17.0 破坏性变更
#### 有序集聚合函数
**影响:** SQL 语法变更
有序集聚合函数现在需要 `WITHIN GROUP (ORDER BY …)` 子句。
**之前:**
```sql
SELECT approx_percentile_cont(latency, 0.95) FROM metrics;
```
**之后:**
```sql
SELECT approx_percentile_cont(0.95) WITHIN GROUP (ORDER BY latency) FROM metrics;
```
**需要的操作:** 更新所有使用有序集聚合函数(`approx_percentile_cont`、`approx_percentile_cont_weight` 等)的查询,包含 `WITHIN GROUP (ORDER BY …)` 子句。
#### MySQL 协议注释样式
**影响:** 注释语法严格性
MySQL 协议中不再允许不正确的注释样式。注释必须以 `--` 开头,而不是 `---`。
**之前:**
```sql
--- 这是一个注释
SELECT * FROM table;
```
**之后:**
```sql
-- 这是一个注释
SELECT * FROM table;
```
**需要的操作:** 更新任何使用 `---` 样式注释的 SQL 脚本或查询,改用标准的 `--` 格式。
## v1.0 的其他变更(非破坏性)
### v1.0.0-beta.3
#### 缓存配置改进
缓存架构已重构以获得更好的性能:
**新配置:**
- `region_engine.mito.manifest_cache_size`(默认:256MB)- 专用的 manifest 文件缓存
**移除的配置:**
- `storage.cache_path`
- `storage.enable_read_cache`
- `storage.cache_capacity`
**需要的操作:** 更新配置文件以使用新的 `manifest_cache_size` 设置,并移除已废弃的存储缓存选项。
### v1.0.0-beta.2
#### 改进的数据库兼容性
- 数值类型别名与 PostgreSQL 和 MySQL 标准对齐
- 更好的 PostgreSQL 扩展查询支持
- 改进的 MySQL 二进制协议处理
**需要的操作:** 测试你的应用程序以确保与改进后的行为兼容。
## 将升级对业务带来的影响最小化
在升级 GreptimeDB 之前,请全面备份数据以防止潜在的数据丢失。此备份作为升级过程中出现任何问题时的安全保障。
### 最佳实践
#### 滚动升级
在 Kubernetes 上采用[滚动升级](https://kubernetes.io/docs/tutorials/kubernetes-basics/update/update-intro/)策略逐步更替 GreptimeDB 实例。该方案通过新旧实例渐进式替换,在确保服务持续可用的前提下实现零停机升级。
#### 自动重试
建议在客户端配置具备指数退避特性的自动重试策略,可有效规避升级过程中的瞬时服务不可用问题。
#### 暂停写操作
对于允许短暂维护的业务场景,可在升级窗口期暂时停止写入操作,此方案能最大限度保障数据一致性。
#### 双写
实施新旧版本双写机制,待新版本验证通过后逐步切换流量。该方案既能确保数据一致性校验,又可实现读流量灰度迁移。
## 升级检查清单
在升级到 v1.0 之前,请完成以下检查清单:
### 升级前
- [ ] 查看与你的升级路径相关的所有破坏性变更
- [ ] **备份所有数据和配置**
- [ ] 识别使用有序集聚合函数的查询(如果从 v0.16 或更早版本升级)
- [ ] 识别使用 `greptime_identity` 处理 JSON 数据的 pipeline
- [ ] 检查是否使用了已废弃的 Jaeger HTTP header(如果从 v0.17 或更早版本升级)
- [ ] 如果使用 Metric Engine,检查指标表
### 配置更新
- [ ] 更新配置文件(移除已废弃的缓存设置)
- [ ] 如需要,更新 metric engine 配置(`sparse_primary_key_encoding`)
- [ ] 更新 pipeline 配置(移除 `flatten_json_object`,如需要添加 `max_nested_levels`)
### 代码更新
- [ ] 更新使用有序集聚合的 SQL 查询以使用 `WITHIN GROUP (ORDER BY ...)`
- [ ] 更新使用 `---` 注释的 SQL 脚本改用 `--`
- [ ] 更新访问嵌套 JSON 字段的查询以使用点号表示法
- [ ] 如存在,移除 Jaeger header 配置
### 测试与部署
- [ ] 在非生产环境中测试升级
- [ ] 验证查询结果,特别是:
- 有序集聚合函数
- 嵌套 JSON 数据访问
- 指标查询(如果受 TSID 变更影响)
- [ ] 规划滚动升级或维护窗口
- [ ] 准备回滚计划以防出现问题
- [ ] 升级后监控系统行为
### Metric Engine 用户的特别考虑
如果由于 TSID 算法变更无法接受升级时间附近的查询差异:
- [ ] 规划导出-升级-导入流程
- [ ] 为数据导出和导入分配充足时间
- [ ] 参考[备份与恢复文档](/user-guide/deployments-administration/disaster-recovery/back-up-&-restore-data/)
---
## 本地 WAL
本节介绍如何配置 GreptimeDB Datanode 组件的本地 WAL。
```toml
[wal]
provider = "raft_engine"
file_size = "128MB"
purge_threshold = "1GB"
purge_interval = "1m"
read_batch_size = 128
sync_write = false
```
## 选项
如果你使用 Helm Chart 部署 GreptimeDB,可以参考[常见 Helm Chart 配置项](/user-guide/deployments-administration/deploy-on-kubernetes/common-helm-chart-configurations.md)了解如何通过注入配置文件以配置 Datanode。
| 配置项 | 描述 | 默认值 |
| ----------------- | ----------------------------------------------------------------------------------------------- | ----------------- |
| `provider` | WAL 的提供者。可选项:`raft_engine`(本地文件系统存储)、`kafka`(使用 Kafka 的远程 WAL 存储)或 `noop`(无操作 WAL 提供者) | `"raft_engine"` |
| `dir` | 日志写入目录 | `{data_home}/wal` |
| `file_size` | 单个 WAL 日志文件的大小 | `128MB` |
| `purge_threshold` | 触发清理的 WAL 总大小阈值 | `1GB` |
| `purge_interval` | 触发清理的时间间隔 | `1m` |
| `read_batch_size` | 读取批次大小 | `128` |
| `sync_write` | 是否在每次写入日志时调用 fsync | `false` |
## 最佳实践
### 使用单独的高性能卷作为 WAL 目录
在部署 GreptimeDB 时,配置单独的卷作为 WAL 目录具有显著优势。这样做可以:
- 使用高性能磁盘——包括专用物理卷或自定义的高性能 `StorageClass`,以提升 WAL 的写入吞吐量。
- 隔离 WAL I/O 与缓存文件访问,降低 I/O 竞争,提升整体系统性能。
如果你使用 Helm Chart 部署 GreptimeDB,可以参考[常见 Helm Chart 配置项](/user-guide/deployments-administration/deploy-on-kubernetes/common-helm-chart-configurations.md)了解如何配置专用 WAL 卷。
---
## Noop WAL
Noop WAL 是一种特殊的 WAL 提供者,用于 WAL 暂时不可用时的紧急情况。它不会存储任何 WAL 数据。
## 可用性
Noop WAL **仅在集群模式下可用**,单机模式不支持。
## 使用场景
- **WAL 暂时不可用**:当 WAL 提供者(如 Kafka)暂时不可用时,可以将 Datanode 切换到 Noop WAL 保持集群运行。
- **测试和开发**:适用于不需要 WAL 持久化的测试场景。
## 数据丢失警告
**使用 Noop WAL 时,Datanode 关闭或重启会导致所有未刷新的数据丢失。** 仅应在 WAL 提供者不可用时临时使用,不建议用于生产环境,除非是紧急情况。
## 配置
为 Datanode 配置 Noop WAL:
```toml
[wal]
provider = "noop"
```
在 GreptimeDB 集群中,WAL 配置分为两部分:
- **Metasrv** - 负责为新 Region 生成 WAL 元数据,应配置为 `raft_engine` 或 `kafka`。
- **Datanode** - 负责 WAL 数据读写,可在 WAL 提供者不可用时配置为 `noop`。
注意:Noop WAL 只能配置在 Datanode 上,Metasrv 不支持。使用 Noop WAL 时,Metasrv 仍使用原配置的 WAL 提供者。
## 最佳实践
- 定期使用 `admin flush_table()` 或 `admin flush_region()` 刷新 Region,减少数据丢失。
- WAL 提供者恢复后,尽快切换回正常配置。
---
## GreptimeDB WAL 概述
# 概述
[预写日志](/contributor-guide/datanode/wal.md#introduction)(WAL) 是 GreptimeDB 的关键组件之一,负责持久化记录每次数据修改操作,以确保内存中的数据在故障发生时不会丢失。GreptimeDB 支持三种 WAL 存储方案:
- **本地 WAL**: 使用嵌入式存储引擎 [raft-engine](https://github.com/tikv/raft-engine) ,直接集成在 [Datanode](/user-guide/concepts/why-greptimedb.md) 服务中。
- **Remote WAL**: 使用 [Apache Kafka](https://kafka.apache.org/) 作为外部的 WAL 存储组件。
- **Noop WAL**: 无操作 WAL 提供者,用于 WAL 暂时不可用的紧急情况,不存储任何数据。
## 本地 WAL
### 优点
- **低延迟**: 本地 WAL 运行于 Datanode 进程内,避免了网络传输开销,提供更低的写入延迟。
- **易于部署**: 由于 WAL 与 Datanode 紧耦合,无需引入额外组件,部署和运维更加简便。
- **零 RPO**: 在云环境中部署 GreptimeDB 时,可以结合云存储服务(如 AWS EBS 或 GCP Persistent Disk)将 WAL 数据持久化存储,从而实现零[恢复点目标](https://en.wikipedia.org/wiki/Disaster_recovery#Recovery_Point_Objective) (RPO),即使发生故障也不会丢失任何已写入的数据。
### 缺点
- **高 RTO**: 由于 WAL 与 Datanode 紧密耦合,[恢复时间目标](https://en.wikipedia.org/wiki/Disaster_recovery#Recovery_Time_Objective) (RTO) 相对较高。在 Datanode 重启后,必须重放 WAL 以恢复最新数据,在此期间节点保持不可用。
- **单点访问限制**: 本地 WAL 与 Datanode 进程紧密耦合,仅支持单个消费者访问,限制了区域热备份和 [Region Migration](/user-guide/deployments-administration/manage-data/region-migration.md) 等功能的实现。
## Remote WAL
### 优点
- **低 RTO**: 通过将 WAL 与 Datanode 解耦,[恢复时间目标](https://en.wikipedia.org/wiki/Disaster_recovery#Recovery_Time_Objective) (RTO) 得以最小化。当 Datanode 崩溃时,Metasrv 会发起 [Region Failover](/user-guide/deployments-administration/manage-data/region-failover.md) ,将受影响 Region 迁移至健康节点,无需本地重放 WAL。
- **多消费者订阅**: Remote WAL 支持多个消费者同时订阅 WAL 日志,实现 Region 热备和 [Region Migration](/user-guide/deployments-administration/manage-data/region-migration.md) 等功能,提升系统的高可用性和灵活性。
### 缺点
- **外部依赖**: Remote WAL 依赖外部 Kafka 集群,增加了部署和运维复杂度。
- **网络开销**: WAL 数据需通过网络传输,需合理规划集群网络带宽,确保低延迟与高吞吐量,尤其在写入密集型负载下。
## Noop WAL
Noop WAL 是一种特殊的 WAL 提供者,用于 WAL 暂时不可用的紧急情况。它不会存储任何 WAL 数据,仅在集群模式下可用。
详细配置说明请参阅 [Noop WAL](/user-guide/deployments-administration/wal/noop-wal.md)。
## 后续步骤
- 如需配置本地 WAL 存储,请参阅[本地 WAL](/user-guide/deployments-administration/wal/local-wal.md)。
- 想了解更多 Remote WAL 相关信息,请参阅 [Remote WAL](/user-guide/deployments-administration/wal/remote-wal/configuration.md)。
- 想了解更多 Noop WAL 相关信息,请参阅 [Noop WAL](/user-guide/deployments-administration/wal/noop-wal.md)。
---
## GreptimeDB Remote WAL 配置
# 配置
GreptimeDB 支持使用 Kafka 实现 Remote WAL 存储。要启用 Remote WAL,需要分别配置 Metasrv 和 Datanode。
如果你使用 Helm Chart 部署 GreptimeDB,可以参考[常见 Helm Chart 配置项](/user-guide/deployments-administration/deploy-on-kubernetes/common-helm-chart-configurations.md)了解如何配置 Remote WAL。
## Metasrv 配置
Metasrv 负责 Kafka topics 的管理及过期 WAL 数据的自动清理。
```toml
[wal]
provider = "kafka"
broker_endpoints = ["kafka.kafka-cluster.svc.cluster.local:9092"]
# WAL 数据清理策略
auto_prune_interval = "30m"
auto_prune_parallelism = 10
flush_trigger_size = "512MB"
checkpoint_trigger_size = "128MB"
# Topic 自动创建配置
auto_create_topics = true
num_topics = 64
replication_factor = 1
topic_name_prefix = "greptimedb_wal_topic"
create_topic_timeout = "30s"
```
### 配置
| 配置项 | 说明 |
|----------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| `provider` | 设置为 `"kafka"` 以启用 Remote WAL。 |
| `broker_endpoints` | Kafka broker 的地址列表。 |
| `auto_prune_interval` | 自动清理过期 WAL 的间隔时间,设为 `"0s"` 表示禁用。 |
| `auto_prune_parallelism` | 并发清理任务的最大数量。 |
| `auto_create_topics` | 是否自动创建 Kafka topic,设为 `false` 时需手动预创建。 |
| `num_topics` | 用于存储 WAL 的 Kafka topic 数量。 |
| `replication_factor` | 每个 topic 的副本数量。 |
| `topic_name_prefix` | Kafka topic 名称前缀,必须匹配正则 `[a-zA-Z_:-][a-zA-Z0-9_:\-\.@#]*`。 |
| `flush_trigger_size` | 触发 region flush 操作的预估大小阈值(如 `"512MB"`)。计算公式为 `(latest_entry_id - flushed_entry_id) * avg_record_size`。当此值超过 `flush_trigger_size` 时,MetaSrv 会触发 region flush 操作。设为 `"0"` 时由系统自动控制。该配置还可控制 region 重放期间从 topic 重放的最大数据量,较小的值有助于缩短 Datanode 启动时的重放时间。 |
| `checkpoint_trigger_size` | 触发 region checkpoint 操作的预估大小阈值(如 `"128MB"`)。计算公式为 `(latest_entry_id - last_checkpoint_entry_id) * avg_record_size`。当此值超过 `checkpoint_trigger_size` 时,MetaSrv 会启动检查点操作。设为 `"0"` 时由系统自动控制。较小的值有助于缩短 Datanode 启动时的重放时间。 |
| `create_topic_timeout` | 创建 Kafka topic 的超时时间,默认值为 `"30s"`。 |
#### Kafka Topic 与权限要求
请确保以下设置正确,以保证 Remote WAL 正常运行:
- 如果 `auto_create_topics = false`:
- 必须**在启动 Metasrv 之前**手动创建好所有 WAL topics;
- Topic 名称必须符合 `{topic_name_prefix}_{index}` 的格式,其中 index 的取值范围是 `0` 到 `{num_topics - 1}`。例如,默认前缀为 `greptimedb_wal_topic`,且 `num_topics = 64` 时,需要创建从 `greptimedb_wal_topic_0` 到 `greptimedb_wal_topic_63` 的 topic。
- Topic 必须配置为支持**LZ4 压缩**。
- Kafka 用户需具备以下权限:
- 对 topics 追加数据;
- 读取 topics 中数据;
- 删除 topics 中数据;
- 若启用自动创建(`auto_create_topics = true`),还需具备 创建 topic 的权限。
## Datanode 配置
Datanode 负责将数据写入 Kafka 并从中读取数据。
```toml
[wal]
provider = "kafka"
broker_endpoints = ["kafka.kafka-cluster.svc.cluster.local:9092"]
max_batch_bytes = "1MB"
overwrite_entry_start_id = true
connect_timeout = "3s"
timeout = "3s"
```
### 配置
| 配置项 | 说明 |
| -------------------------- | -------------------------------------------------------------------------------------------- |
| `provider` | 设置为 `"kafka"` 以启用 Remote WAL。 |
| `broker_endpoints` | Kafka broker 的地址列表。 |
| `max_batch_bytes` | 每个写入批次的最大大小,默认不能超过 Kafka 配置的单条消息上限(通常为 1MB)。 |
| `overwrite_entry_start_id` | 若设为 `true`,在 WAL 回放时跳过缺失的 entry,避免 out-of-range 错误(但可能掩盖数据丢失)。 |
| `connect_timeout` | Kafka 客户端的连接超时时间,默认值为 `"3s"`。 |
| `timeout` | Kafka 客户端操作的超时时间,默认值为 `"3s"`。 |
#### 注意事项与限制
:::warning 重要:Kafka 保留策略配置
请非常小心地配置 Kafka 保留策略以避免数据丢失。GreptimeDB 会自动回收不需要的 WAL 数据,因此在大多数情况下你不需要设置保留策略。但是如果你确实需要设置,请确保以下几点:
- **基于大小的保留策略**:通常不需要设置,因为数据库会管理自己的数据生命周期
- **基于时间的保留策略**:如果你选择设置此项,请确保保留时间**远大于自动刷新间隔** **(auto-flush-interval)** 以防止过早删除数据。
不当的保留设置可能导致数据丢失,如果 WAL 数据在 GreptimeDB 处理之前被删除。
:::
- 如果 `overwrite_entry_start_id = true`:
- 确保 Metasrv 中的 `auto_prune_interval` 已启用,以允许自动清理 WAL;
- Kafka topics 不应使用**基于大小保留策略**;
- 如果启用基于时间的保留策略,请确保保留时间**远大于自动刷新间隔(auto-flush-interval)**,至少是它的两倍。
- 确保 Datanode 使用的 Kafka 用户具有以下权限:
- 对 topics 追加数据;
- 读取 topics 中数据;
- 确保 `max_batch_bytes` 不超过 Kafka topic 的最大消息大小(通常为 1MB)。
## Kafka 认证配置
Kafka 的认证参数在 Metasrv 和 Datanode 的 `[wal]` 段中配置。
### SASL 认证
支持的 SASL 机制包括:`PLAIN`、`SCRAM-SHA-256` 和 `SCRAM-SHA-512`。
```toml
[wal]
broker_endpoints = ["kafka.kafka-cluster.svc.cluster.local:9092"]
[wal.sasl]
type = "SCRAM-SHA-512"
username = "user"
password = "secret"
```
### TLS
要启用 TLS,可在 `[wal.tls]` 段进行配置,支持以下几种方式:
#### 使用系统 CA 证书
无需提供证书路径,自动使用系统信任的 CA:
```toml
[wal]
broker_endpoints = ["kafka.kafka-cluster.svc.cluster.local:9092"]
[wal.tls]
```
#### 使用自定义 CA 证书
用于 Kafka 集群使用私有 CA 的场景:
```toml
[wal]
broker_endpoints = ["kafka.kafka-cluster.svc.cluster.local:9092"]
[wal.tls]
server_ca_cert_path = "/path/to/server.crt"
```
#### 使用双向 TLS(mTLS)
同时提供客户端证书与私钥:
```toml
[wal]
broker_endpoints = ["kafka.kafka-cluster.svc.cluster.local:9092"]
[wal.tls]
server_ca_cert_path = "/path/to/server_cert"
client_cert_path = "/path/to/client_cert"
client_key_path = "/path/to/key"
```
---
## 管理 Kafka
GreptimeDB 集群在启用 [Remote WAL](/user-guide/deployments-administration/wal/remote-wal/configuration.md) 时,会使用 Kafka 作为 WAL 存储。本文介绍如何部署和管理 Kafka 集群,使用的是 Bitnami 提供的 Kafka Helm [chart](https://github.com/bitnami/charts/tree/main/bitnami/kafka)。
## 先决条件
- [Kubernetes](https://kubernetes.io/docs/setup/) >= v1.23
- [kubectl](https://kubernetes.io/docs/tasks/tools/install-kubectl/) >= v1.18.0
- [Helm](https://helm.sh/docs/intro/install/) >= v3.0.0
## 安装
将以下内容保存为配置文件 `kafka.yaml`:
```yaml
global:
security:
allowInsecureImages: true
image:
registry: docker.io
repository: greptime/kafka
tag: 3.9.0-debian-12-r12
controller:
replicaCount: 3
resources:
requests:
cpu: 2
memory: 2Gi
limits:
cpu: 2
memory: 2Gi
persistence:
enabled: true
size: 200Gi
broker:
replicaCount: 3
resources:
requests:
cpu: 2
memory: 2Gi
limits:
cpu: 2
memory: 2Gi
persistence:
enabled: true
size: 200Gi
listeners:
client:
# 部署到生产环境时,通常会使用一个更安全的协议,例如 SASL。
# 请参考 chart 的文档获取配置方法:https://artifacthub.io/packages/helm/bitnami/kafka#enable-security-for-kafka
# 此处为了例子的简单,我们使用 plaintext 协议(无权限验证)。
protocol: plaintext
```
安装 Kafka 集群:
```bash
helm upgrade --install kafka \
oci://registry-1.docker.io/bitnamicharts/kafka \
--values kafka.yaml \
--version 32.4.3 \
--create-namespace \
-n kafka-cluster
```
等待 Kafka 集群启动完成:
```bash
kubectl wait --for=condition=ready pod \
-l app.kubernetes.io/instance=kafka \
-n kafka-cluster
```
```bash
kubectl get pods -n kafka-cluster
```
检查 Kafka 集群状态:
```bash
kubectl get pods -n kafka-cluster
```
Expected Output
```bash
NAME READY STATUS RESTARTS AGE
kafka-controller-0 1/1 Running 0 64s
kafka-controller-1 1/1 Running 0 64s
kafka-controller-2 1/1 Running 0 64s
kafka-broker-0 1/1 Running 0 63s
kafka-broker-1 1/1 Running 0 62s
kafka-broker-2 1/1 Running 0 61s
```
---
## 持续聚合
持续聚合是处理时间序列数据以提供实时洞察的关键方面。
Flow 引擎使开发人员能够无缝地执行持续聚合,例如计算总和、平均值和其他指标。
它在指定的时间窗口内高效地更新聚合数据,使其成为分析的宝贵工具。
持续聚合的三个主要用例示例如下:
1. **实时分析**:一个实时分析平台,不断聚合来自事件流的数据,提供即时洞察,同时可选择将数据降采样到较低分辨率。例如,此系统可以编译来自高频日志事件流(例如,每毫秒发生一次)的数据,以提供每分钟的请求数、平均响应时间和每分钟的错误率等最新洞察。
2. **实时监控**:一个实时监控系统,不断聚合来自事件流的数据,根据聚合数据提供实时警报。例如,此系统可以处理来自传感器事件流的数据,以提供当温度超过某个阈值时的实时警报。
3. **实时仪表盘**:一个实时仪表盘,显示每分钟的请求数、平均响应时间和每分钟的错误数。此仪表板可用于监控系统的健康状况,并检测系统中的任何异常。
在所有这些用例中,持续聚合系统不断聚合来自事件流的数据,并根据聚合数据提供实时洞察和警报。系统还可以将数据降采样到较低分辨率,以减少存储和处理的数据量。这使得系统能够提供实时洞察和警报,同时保持较低的数据存储和处理成本。
## 实时分析示例
### 日志统计
这个例子是根据输入表中的数据计算一系列统计数据,包括一分钟时间窗口内的总日志数、最小大小、最大大小、平均大小以及大小大于 550 的数据包数。
首先,创建一个 source 表 `ngx_access_log` 和一个 sink 表 `ngx_statistics`,如下所示:
```sql
CREATE TABLE `ngx_access_log` (
`client` STRING NULL,
`ua_platform` STRING NULL,
`referer` STRING NULL,
`method` STRING NULL,
`endpoint` STRING NULL,
`trace_id` STRING NULL FULLTEXT INDEX,
`protocol` STRING NULL,
`status` SMALLINT UNSIGNED NULL,
`size` DOUBLE NULL,
`agent` STRING NULL,
`access_time` TIMESTAMP(3) NOT NULL,
TIME INDEX (`access_time`)
)
WITH(
append_mode = 'true'
);
```
```sql
CREATE TABLE `ngx_statistics` (
`status` SMALLINT UNSIGNED NULL,
`total_logs` BIGINT NULL,
`min_size` DOUBLE NULL,
`max_size` DOUBLE NULL,
`avg_size` DOUBLE NULL,
`high_size_count` BIGINT NULL,
`time_window` TIMESTAMP time index,
`update_at` TIMESTAMP NULL,
PRIMARY KEY (`status`)
);
```
然后创建名为 `ngx_aggregation` 的 flow 任务,包括 `count`、`min`、`max`、`avg` `size` 列的聚合函数,以及大于 550 的所有数据包的大小总和。聚合是在 `access_time` 列的 1 分钟固定窗口中计算的,并且还按 `status` 列分组。因此,你可以实时了解有关数据包大小和对其的操作的信息,例如,如果 `high_size_count` 在某个时间点变得太高,你可以进一步检查是否有任何问题,或者如果 `max_size` 列在 1 分钟时间窗口内突然激增,你可以尝试定位该数据包并进一步检查。
下方 SQL 语句中的 `EXPIRE AFTER '6h'` 参数确保 flow 计算仅使用过去 6 小时内的源数据。对于 sink 表中超过 6 小时的历史数据,本 flow 不会对其进行修改。有关`EXPIRE AFTER`的详细信息,请参阅[管理 Flow](manage-flow.md#expire-after)
```sql
CREATE FLOW ngx_aggregation
SINK TO ngx_statistics
EXPIRE AFTER '6h'
COMMENT 'aggregate nginx access logs'
AS
SELECT
status,
count(client) AS total_logs,
min(size) as min_size,
max(size) as max_size,
avg(size) as avg_size,
sum(case when `size` > 550 then 1 else 0 end) as high_size_count,
date_bin('1 minutes'::INTERVAL, access_time) as time_window,
FROM ngx_access_log
GROUP BY
status,
time_window;
```
要检查持续聚合是否正常工作,首先插入一些数据到源表 `ngx_access_log` 中。
```sql
INSERT INTO ngx_access_log
VALUES
('android', 'Android', 'referer', 'GET', '/api/v1', 'trace_id', 'HTTP', 200, 1000, 'agent', now() - INTERVAL '1' minute),
('ios', 'iOS', 'referer', 'GET', '/api/v1', 'trace_id', 'HTTP', 200, 500, 'agent', now() - INTERVAL '1' minute),
('android', 'Android', 'referer', 'GET', '/api/v1', 'trace_id', 'HTTP', 200, 600, 'agent', now()),
('ios', 'iOS', 'referer', 'GET', '/api/v1', 'trace_id', 'HTTP', 404, 700, 'agent', now());
```
则 `ngx_access_log` 表将被增量更新以包含以下数据:
```sql
SELECT * FROM ngx_statistics;
```
```sql
+--------+------------+----------+----------+----------+-----------------+---------------------+----------------------------+
| status | total_logs | min_size | max_size | avg_size | high_size_count | time_window | update_at |
+--------+------------+----------+----------+----------+-----------------+---------------------+----------------------------+
| 200 | 2 | 500 | 1000 | 750 | 1 | 2025-04-24 06:46:00 | 2025-04-24 06:47:06.680000 |
| 200 | 1 | 600 | 600 | 600 | 1 | 2025-04-24 06:47:00 | 2025-04-24 06:47:06.680000 |
| 404 | 1 | 700 | 700 | 700 | 1 | 2025-04-24 06:47:00 | 2025-04-24 06:47:06.680000 |
+--------+------------+----------+----------+----------+-----------------+---------------------+----------------------------+
3 rows in set (0.01 sec)
```
尝试向 `ngx_access_log` 表中插入更多数据:
```sql
INSERT INTO ngx_access_log
VALUES
('android', 'Android', 'referer', 'GET', '/api/v1', 'trace_id', 'HTTP', 200, 500, 'agent', now()),
('ios', 'iOS', 'referer', 'GET', '/api/v1', 'trace_id', 'HTTP', 404, 800, 'agent', now());
```
结果表 `ngx_statistics` 将被增量更新,注意 `max_size`、`avg_size` 和 `high_size_count` 是如何更新的:
```sql
SELECT * FROM ngx_statistics;
```
```sql
+--------+------------+----------+----------+----------+-----------------+---------------------+----------------------------+
| status | total_logs | min_size | max_size | avg_size | high_size_count | time_window | update_at |
+--------+------------+----------+----------+----------+-----------------+---------------------+----------------------------+
| 200 | 2 | 500 | 1000 | 750 | 1 | 2025-04-24 06:46:00 | 2025-04-24 06:47:06.680000 |
| 200 | 2 | 500 | 600 | 550 | 1 | 2025-04-24 06:47:00 | 2025-04-24 06:47:21.720000 |
| 404 | 2 | 700 | 800 | 750 | 2 | 2025-04-24 06:47:00 | 2025-04-24 06:47:21.720000 |
+--------+------------+----------+----------+----------+-----------------+---------------------+----------------------------+
3 rows in set (0.01 sec)
```
`ngx_statistics` 表中的列解释如下:
- `status`: HTTP 响应的状态码。
- `total_logs`: 相同状态码的日志总数。
- `min_size`: 相同状态码的数据包的最小大小。
- `max_size`: 相同状态码的数据包的最大大小。
- `avg_size`: 相同状态码的数据包的平均大小。
- `high_size_count`: 包大小大于 550 的数据包数。
- `time_window`: 聚合的时间窗口。
- `update_at`: 聚合结果更新的时间。
### 按时间窗口查询国家
另一个实时分析的示例是从 `ngx_access_log` 表中查询所有不同的国家。
你可以使用以下查询按时间窗口对国家进行分组:
```sql
/* source 表 */
CREATE TABLE ngx_access_log (
client STRING,
country STRING,
access_time TIMESTAMP TIME INDEX,
PRIMARY KEY(client)
)WITH(
append_mode = 'true'
);
/* sink 表 */
CREATE TABLE ngx_country (
country STRING,
time_window TIMESTAMP TIME INDEX,
update_at TIMESTAMP,
PRIMARY KEY(country)
);
/* 创建 flow 任务以计算不同的国家 */
CREATE FLOW calc_ngx_country
SINK TO ngx_country
EXPIRE AFTER '7days'::INTERVAL
COMMENT 'aggregate for distinct country'
AS
SELECT
DISTINCT country,
date_bin('1 hour'::INTERVAL, access_time) as time_window,
FROM ngx_access_log
GROUP BY
country,
time_window;
```
上述查询将 `ngx_access_log` 表中的数据聚合到 `ngx_country` 表中,它计算了每个时间窗口内的不同国家。
`date_bin` 函数用于将数据聚合到一小时的间隔中。
`ngx_country` 表将不断更新聚合数据,以监控访问系统的不同国家。`EXPIRE AFTER` 参数将确保流式处理流程自动忽略 `access_time` 超过 7 天的数据且不再参与 flow 计算,详见 请参阅[管理 Flow](manage-flow.md#expire-after) 中的说明。
你可以向 source 表 `ngx_access_log` 插入一些数据:
```sql
INSERT INTO ngx_access_log VALUES
('client1', 'US', now() - '2 hour'::INTERVAL),
('client2', 'US', now() - '2 hour'::INTERVAL),
('client3', 'UK', now() - '2 hour'::INTERVAL),
('client4', 'UK', now() - '1 hour'::INTERVAL),
('client5', 'CN', now() - '1 hour'::INTERVAL),
('client6', 'CN', now() - '1 hour'::INTERVAL),
('client7', 'JP', now()),
('client8', 'JP', now()),
('client9', 'KR', now()),
('client10', 'KR', now());
```
等待几秒钟,让 flow 将结果写入 sink 表,然后查询:
```sql
select * from ngx_country;
```
```sql
+---------+---------------------+----------------------------+
| country | time_window | update_at |
+---------+---------------------+----------------------------+
| CN | 2025-04-24 05:00:00 | 2025-04-24 06:55:17.217000 |
| JP | 2025-04-24 06:00:00 | 2025-04-24 06:55:17.217000 |
| KR | 2025-04-24 06:00:00 | 2025-04-24 06:55:17.217000 |
| UK | 2025-04-24 04:00:00 | 2025-04-24 06:55:17.217000 |
| UK | 2025-04-24 05:00:00 | 2025-04-24 06:55:17.217000 |
| US | 2025-04-24 04:00:00 | 2025-04-24 06:55:17.217000 |
+---------+---------------------+----------------------------+
```
## 实时监控示例
假设你有一个来自温度传感器网络的传感器事件流,你希望实时监控这些事件。
传感器事件包含传感器 ID、温度读数、读数的时间戳和传感器的位置等信息。
你希望不断聚合这些数据,以便在温度超过某个阈值时提供实时告警。持续聚合的查询如下:
```sql
/* 创建 source 表 */
CREATE TABLE temp_sensor_data (
sensor_id INT,
loc STRING,
temperature DOUBLE,
ts TIMESTAMP TIME INDEX
)WITH(
append_mode = 'true'
);
/* 创建 sink 表 */
CREATE TABLE temp_alerts (
sensor_id INT,
loc STRING,
max_temp DOUBLE,
time_window TIMESTAMP TIME INDEX,
update_at TIMESTAMP,
PRIMARY KEY(sensor_id, loc)
);
CREATE FLOW temp_monitoring
SINK TO temp_alerts
EXPIRE AFTER '1h'
AS
SELECT
sensor_id,
loc,
max(temperature) as max_temp,
date_bin('10 seconds'::INTERVAL, ts) as time_window,
FROM temp_sensor_data
GROUP BY
sensor_id,
loc,
time_window
HAVING max_temp > 100;
```
上述查询将 `temp_sensor_data` 表中的数据不断聚合到 `temp_alerts` 表中。
它计算每个传感器和位置的最大温度读数,并过滤出最大温度超过 100 度的数据。
`temp_alerts` 表将不断更新聚合数据,
当温度超过阈值时提供实时警报(即 `temp_alerts` 表中的新行)。`EXPIRE AFTER '1h'` 使 flow 仅计算 `ts` 列处于 `(now - 1h, now)` 时间范围内的源数据,详见 [管理 Flow](manage-flow.md#expire-after) 中的说明。
现在我们已经创建了 flow 任务,可以向 source 表 `temp_sensor_data` 插入一些数据:
```sql
INSERT INTO temp_sensor_data VALUES
(1, 'room1', 98.5, now() - '10 second'::INTERVAL),
(2, 'room2', 99.5, now());
```
表现在应该是空的,等待几秒钟让 flow 将结果更新到输出表:
```sql
SELECT * FROM temp_alerts;
```
```sql
Empty set (0.00 sec)
```
插入一些会触发警报的数据:
```sql
INSERT INTO temp_sensor_data VALUES
(1, 'room1', 101.5, now()),
(2, 'room2', 102.5, now());
```
等待几秒钟,让 flow 将结果更新到输出表:
```sql
SELECT * FROM temp_alerts;
```
```sql
+-----------+-------+----------+---------------------+----------------------------+
| sensor_id | loc | max_temp | time_window | update_at |
+-----------+-------+----------+---------------------+----------------------------+
| 1 | room1 | 101.5 | 2025-04-24 06:58:20 | 2025-04-24 06:58:32.379000 |
| 2 | room2 | 102.5 | 2025-04-24 06:58:20 | 2025-04-24 06:58:32.379000 |
+-----------+-------+----------+---------------------+----------------------------+
```
## 实时仪表盘
假设你需要一个条形图来显示每个状态码的包大小分布,以监控系统的健康状况。持续聚合的查询如下:
```sql
/* 创建 source 表 */
CREATE TABLE ngx_access_log (
client STRING,
stat INT,
size INT,
access_time TIMESTAMP TIME INDEX
)WITH(
append_mode = 'true'
);
/* 创建 sink 表 */
CREATE TABLE ngx_distribution (
stat INT,
bucket_size INT,
total_logs BIGINT,
time_window TIMESTAMP TIME INDEX,
update_at TIMESTAMP,
PRIMARY KEY(stat, bucket_size)
);
/* 创建 flow 任务以计算每个状态码的包大小分布 */
CREATE FLOW calc_ngx_distribution SINK TO ngx_distribution
EXPIRE AFTER '6h'
AS
SELECT
stat,
trunc(size, -1)::INT as bucket_size,
count(client) AS total_logs,
date_bin('1 minutes'::INTERVAL, access_time) as time_window,
FROM
ngx_access_log
GROUP BY
stat,
time_window,
bucket_size;
```
该查询将 `ngx_access_log` 表中的数据汇总到 `ngx_distribution` 表中。
它计算每个时间窗口内的状态代码和数据包大小存储桶(存储桶大小为 10,由 `trunc` 指定,第二个参数为 -1)的日志总数。
`date_bin` 函数将数据分组为一分钟的间隔。
因此,`ngx_distribution` 表会不断更新,
提供每个状态代码的数据包大小分布的实时洞察。`EXPIRE AFTER '6h'` 使 flow 仅计算 `access_time` 列处于 `(now - 6h, now)` 时间范围内的源数据,详见 [管理 Flow](manage-flow.md#expire-after)。
现在我们已经创建了 flow 任务,可以向 source 表 `ngx_access_log` 插入一些数据:
```sql
INSERT INTO ngx_access_log VALUES
('cli1', 200, 100, now()),
('cli2', 200, 104, now()),
('cli3', 200, 120, now()),
('cli4', 200, 124, now()),
('cli5', 200, 140, now()),
('cli6', 404, 144, now()),
('cli7', 404, 160, now()),
('cli8', 404, 164, now()),
('cli9', 404, 180, now()),
('cli10', 404, 184, now());
```
等待几秒钟,让 flow 将结果更新到 sink 表:
```sql
SELECT * FROM ngx_distribution;
```
```sql
+------+-------------+------------+---------------------+----------------------------+
| stat | bucket_size | total_logs | time_window | update_at |
+------+-------------+------------+---------------------+----------------------------+
| 200 | 100 | 2 | 2025-04-24 07:05:00 | 2025-04-24 07:05:56.308000 |
| 200 | 120 | 2 | 2025-04-24 07:05:00 | 2025-04-24 07:05:56.308000 |
| 200 | 140 | 1 | 2025-04-24 07:05:00 | 2025-04-24 07:05:56.308000 |
| 404 | 140 | 1 | 2025-04-24 07:05:00 | 2025-04-24 07:05:56.308000 |
| 404 | 160 | 2 | 2025-04-24 07:05:00 | 2025-04-24 07:05:56.308000 |
| 404 | 180 | 2 | 2025-04-24 07:05:00 | 2025-04-24 07:05:56.308000 |
+------+-------------+------------+---------------------+----------------------------+
6 rows in set (0.00 sec)
```
## 将 TQL 与 Flow 结合使用进行高级时序分析
:::warning 实验性特性
此实验性功能可能存在预期外的行为,其功能未来可能发生变化。
:::
TQL(时序查询语言)可以与 Flow 无缝集成,以执行高级时序计算,如速率计算、移动平均值和其他复杂的时间窗口操作。这种组合允许你创建连续聚合的 Flow,利用 TQL 强大的分析功能来获取实时洞察。
### 理解 TQL Flow 组件
TQL 与 Flow 的集成提供了以下几个优势:
1. **时间范围指定**:`EVAL (start_time, end_time, step)` 语法允许精确控制计算窗口,详见 [TQL](/reference/sql/tql.md)。
2. **自动生成表结构**:GreptimeDB 根据 TQL 函数输出创建适当的 Sink 表。
3. **连续处理**:结合 Flow 的调度,TQL 函数在传入数据上持续运行。
4. **高级分析**:使用复杂的时序函数,如 `rate()`、`increase()` 和统计聚合。
### 设置 Source 表
首先,让我们创建一个 Source 表来存储 HTTP 请求指标:
```sql
CREATE TABLE http_requests_total (
host STRING,
job STRING,
instance STRING,
byte DOUBLE,
ts TIMESTAMP TIME INDEX,
PRIMARY KEY (host, job, instance)
);
```
此表将作为基于 TQL 的 Flow 计算的数据源。`ts` 列作为时间索引, `byte` 表示想要分析的指标值。
### 创建速率计算 Flow
现在我们将创建一个 Flow,它使用 TQL 来计算 `byte` 随时间的速率:
```sql
CREATE FLOW calc_rate
SINK TO rate_reqs
EVAL INTERVAL '1m' AS
TQL EVAL (now() - '1m'::interval, now(), '30s') rate(http_requests_total{job="my_service"}[1m]);
```
此 Flow 定义包含几个关键组件:
- **EVAL INTERVAL '1m'**:每分钟执行 Flow 以进行连续更新。
- **TQL EVAL**:指定从 1 分钟前到现在的时间范围进行评估,详见 [TQL](/reference/sql/tql.md)。
- **rate()**:计算变化率的 TQL 函数。
- **[1m]**:定义速率计算的 1 分钟回溯窗口。
### 用 CTE 包装 TQL
如果你想让 Flow 定义更清晰,或者希望提前固定输出列名,可以在 `CREATE FLOW` 中用一个简单的 CTE 包装 `TQL EVAL`:
```sql
CREATE FLOW calc_rate_cte
SINK TO rate_reqs_cte
EVAL INTERVAL '1m' AS
WITH rate_data (ts, req_rate, host, job, instance) AS (
TQL EVAL (now() - '1m'::interval, now(), '30s')
rate(http_requests_total{job="my_service"}[1m])
AS req_rate
)
SELECT * FROM rate_data;
```
当你希望在 GreptimeDB 推断 sink 表 schema 之前先重命名列时,这种写法会很有用,尤其适合值列名较长的 TQL 表达式。
这个能力目前是刻意限制范围的:
- 只能使用一个 TQL CTE。
- Flow 查询必须以 `SELECT * FROM ` 结束。
- 不能再增加 `WHERE`、JOIN、额外投影或其他 CTE。
- 如果 CTE 名称使用了引号,外层查询也要保持同样的带引号写法。
### 检查生成的 Sink 表
你可以检查自动创建的 Sink 表结构:
```sql
SHOW CREATE TABLE rate_reqs;
```
```sql
+-----------+-------------------------------------+
| Table | Create Table |
+-----------+-------------------------------------+
| rate_reqs | CREATE TABLE IF NOT EXISTS `rate_reqs` (
`ts` TIMESTAMP(3) NOT NULL,
`prom_rate(ts_range,byte,ts,Int64(60000))` DOUBLE NULL,
`host` STRING NULL,
`job` STRING NULL,
`instance` STRING NULL,
TIME INDEX (`ts`),
PRIMARY KEY (`host`, `job`, `instance`)
)
ENGINE=mito
|
+-----------+-------------------------------------+
```
上述结果展示了 GreptimeDB 自动生成了用于存储 TQL 计算结果的合适 Schema,即创建一个与 PromQL 查询结果具有相同结构的表。
### 使用示例数据进行测试
现在可以插入一些测试数据,看看 Flow 的实际效果:
```sql
INSERT INTO TABLE http_requests_total VALUES
('localhost', 'my_service', 'instance1', 100, now() - INTERVAL '2' minute),
('localhost', 'my_service', 'instance1', 200, now() - INTERVAL '1' minute),
('remotehost', 'my_service', 'instance1', 300, now() - INTERVAL '30' second),
('remotehost', 'their_service', 'instance1', 300, now() - INTERVAL '30' second),
('localhost', 'my_service', 'instance1', 400, now());
```
这将创建一个随时间递增的简单值序列,当由我们的 TQL Flow 处理时,将产生对应的速率结果。
### 触发 Flow 执行
要手动触发 Flow 计算并查看即时结果:
```sql
ADMIN FLUSH_FLOW('calc_rate');
```
此命令强制 Flow 立即处理所有可用数据,而不是等待下一个计划的间隔。
### 验证结果
最后,验证 Flow 是否已成功处理数据:
```sql
SELECT count(*) > 0 FROM rate_reqs;
```
```sql
+---------------------+
| count(*) > Int64(0) |
+---------------------+
| true |
+---------------------+
```
此查询确认速率计算的 FLow 已产生结果并将结果写入了 Sink 表。
你还可以查询实际计算出的速率值:
```sql
SELECT * FROM rate_reqs;
```
```sql
+---------------------+------------------------------------------+-----------+------------+-----------+
| ts | prom_rate(ts_range,byte,ts,Int64(60000)) | host | job | instance |
+---------------------+------------------------------------------+-----------+------------+-----------+
| 2025-09-01 13:14:34 | 4.166666666666666 | localhost | my_service | instance1 |
| 2025-09-01 13:15:04 | 4.444444444444444 | localhost | my_service | instance1 |
+---------------------+------------------------------------------+-----------+------------+-----------+
2 rows in set (0.03 sec)
```
请注意,时间戳和确切的速率值可能会因你运行示例的时间而不同,但此示例的速率计算是相同的。
### 清理
完成实验后,清理资源:
```sql
DROP FLOW calc_rate;
DROP TABLE http_requests;
DROP TABLE rate_reqs;
```
## 下一步
- [管理 Flow](manage-flow.md):深入了解 Flow 引擎的机制和定义 Flow 的 SQL 语法。
- [表达式](expressions.md):了解 Flow 引擎支持的数据转换表达式。
---
## 表达式
## 聚合函数
Flow 支持标准 SQL 查询所支持的所有聚合函数,例如 `COUNT`、`SUM`、`MIN`、`MAX` 等。
有关详细的函数列表,请参阅 [聚合函数](/reference/sql/functions/df-functions.md#aggregate-functions)。
## 标量函数
Flow 支持标准 SQL 查询所支持的所有标量函数,详见我们的 [SQL 参考](/reference/sql/functions/overview.md)。
以下是一些 flow 中最常用的标量函数:
- [`date_bin`](/reference/sql/functions/df-functions.md#date_bin): calculate time intervals and returns the start of the interval nearest to the specified timestamp.
- [`date_trunc`](/reference/sql/functions/df-functions.md#date_trunc): truncate a timestamp value to a specified precision.
- [`trunc`](/reference/sql/functions/df-functions.md#trunc): truncate a number to a whole number or truncated to the specified decimal places.
---
## 管理 Flow
每一个 `flow` 是 GreptimeDB 中的一个持续聚合查询。
它根据传入的数据持续更新并聚合数据。
本文档描述了如何创建和删除一个 flow。
## 创建输入表
在创建 `flow` 之前,你需要先创建一张输入表来存储原始的输入数据,比如:
```sql
CREATE TABLE temp_sensor_data (
sensor_id INT,
loc STRING,
temperature DOUBLE,
ts TIMESTAMP TIME INDEX,
PRIMARY KEY(sensor_id, loc)
);
```
但是如果你不想存储输入数据,可以在创建输入表时设置表选项 `WITH ('ttl' = 'instant')` 如下:
```sql
CREATE TABLE temp_sensor_data (
sensor_id INT,
loc STRING,
temperature DOUBLE,
ts TIMESTAMP TIME INDEX,
PRIMARY KEY(sensor_id, loc)
) WITH ('ttl' = 'instant');
```
将 `ttl` 设置为 `'instant'` 会使得输入表成为一张临时的表,也就是说它会自动丢弃一切插入的数据,而表本身一直会是空的,插入数据只会被送到 `flow` 任务处用作计算用途。
## 创建 sink 表
在创建 flow 之前,你需要有一个 sink 表来存储 flow 生成的聚合数据。
虽然它与常规的时间序列表相同,但有一些重要的注意事项:
- **列的顺序和类型**:确保 sink 表中列的顺序和类型与 flow 查询结果匹配。
- **时间索引**:为 sink 表指定 `TIME INDEX`,通常使用时间窗口函数生成的时间列。
- **更新时间**:Flow 引擎会自动将更新时间附加到每个计算结果行的末尾。此更新时间存储在 `update_at` 列中。请确保在 sink 表的 schema 中包含此列。
- **Tag**:使用 `PRIMARY KEY` 指定 Tag,与 time index 一起作为行数据的唯一标识,并优化查询性能。
例如:
```sql
/* 创建 sink 表 */
CREATE TABLE temp_alerts (
sensor_id INT,
loc STRING,
max_temp DOUBLE,
time_window TIMESTAMP TIME INDEX,
update_at TIMESTAMP,
PRIMARY KEY(sensor_id, loc)
);
CREATE FLOW temp_monitoring
SINK TO temp_alerts
AS
SELECT
sensor_id,
loc,
max(temperature) AS max_temp,
date_bin('10 seconds'::INTERVAL, ts) AS time_window
FROM temp_sensor_data
GROUP BY
sensor_id,
loc,
time_window
HAVING max_temp > 100;
```
sink 表包含列 `sensor_id`、`loc`、`max_temp`、`time_window` 和 `update_at`。
- 前四列分别对应 flow 的查询结果列 `sensor_id`、`loc`、`max(temperature)` 和 `date_bin('10 seconds'::INTERVAL, ts)`。
- `time_window` 列被指定为 sink 表的 `TIME INDEX`。
- `update_at` 列是 schema 中的最后一列,用于存储数据的更新时间。
- 最后的 `PRIMARY KEY` 指定 `sensor_id` 和 `loc` 作为 Tag 列。
这意味着 flow 将根据 Tag `sensor_id` 和 `loc` 以及时间索引 `time_window` 插入或更新数据。
## 创建 flow
创建 flow 的语法是:
```sql
CREATE [ OR REPLACE ] FLOW [ IF NOT EXISTS ]
SINK TO
[ EXPIRE AFTER ]
[ COMMENT '' ]
AS
;
```
当指定 `OR REPLACE` 时,如果已经存在同名的 flow,它将被更新为新 flow。请注意,这仅影响 flow 任务本身,source 表和 sink 表将不会被更改。当指定 `IF NOT EXISTS` 时,如果 flow 已经存在,它将不执行任何操作,而不是报告错误。还需要注意的是,`OR REPLACE` 不能与 `IF NOT EXISTS` 一起使用。
- `flow-name` 是目录级别的唯一标识符。
- `sink-table-name` 是存储聚合数据的表名。
它可以是一个现有的表或一个新表。如果目标表不存在,`flow` 将创建目标表。
- `EXPIRE AFTER` 是一个可选的时间间隔,用于从 Flow 引擎中过期数据。
有关更多详细信息,请参考 [`EXPIRE AFTER`](#expire-after) 部分。
- `COMMENT` 是 flow 的描述。
- `SQL` 部分定义了用于持续聚合的查询。
它定义了为 flow 提供数据的源表。
每个 flow 可以有多个源表。
有关详细信息,请参考[编写查询](#编写-sql-查询) 部分。
一个创建 flow 的简单示例:
```sql
CREATE FLOW IF NOT EXISTS my_flow
SINK TO my_sink_table
EXPIRE AFTER '1 hour'::INTERVAL
COMMENT 'My first flow in GreptimeDB'
AS
SELECT
max(temperature) as max_temp,
date_bin('10 seconds'::INTERVAL, ts) as time_window,
FROM temp_sensor_data
GROUP BY time_window;
```
创建的 flow 将每 10 秒计算一次 `max(temperature)` 并将结果存储在 `my_sink_table` 中。
所有在 1 小时内的数据都将用于 flow 计算。
### EXPIRE AFTER
`EXPIRE AFTER` 子句指定数据将在 flow 引擎中过期的时间间隔。
source 表中超出指定过期时间的数据将不再被包含在 flow 的计算范围内。
同理,sink 表中超过过期时间的历史数据也不会被更新。
这意味着 flow 引擎在聚合计算时会自动忽略早于该时间间隔的数据。这一机制有助于管理有状态查询(例如涉及 `GROUP BY` 的查询)的状态存储规模。
需特别注意的是:
- `EXPIRE AFTER` 子句**不会删除** source 表或 sink 表中的数据,它仅控制 flow 引擎对数据的处理范围
- 若需删除表数据,请在创建表时通过 [`TTL` 策略](/user-guide/manage-data/overview.md#使用-ttl-策略保留数据)实现
为 `EXPIRE AFTER` 设置合理的时间间隔,可有效限制 flow 的状态存储规模并避免内存溢出。该机制与流处理中的 ["水位线"](https://docs.risingwave.com/processing/watermarks) 概念有相似之处——两者均通过时间边界定义计算的有效数据范围,过期数据将不再参与流式计算过程。
例如,如果 flow 引擎在 10:00:00 处理聚合,并且设置了 `'1 hour'::INTERVAL`,
当前时刻若输入数据的 Time Index 超过 1 小时(即早于 09:00:00),则会被判定为过期数据并被忽略。
仅时间戳为 09:00:00 及之后的数据会参与聚合计算,并更新到目标表。
### 编写 SQL 查询
flow 的 `SQL` 部分类似于标准的 `SELECT` 子句,但有一些不同之处。查询的语法如下:
```sql
SELECT AGGR_FUNCTION(column1, column2,..) [, TIME_WINDOW_FUNCTION() as time_window] FROM GROUP BY {time_window | column1, column2,.. };
```
在 `SELECT` 关键字之后只允许以下类型的表达式:
- 聚合函数:有关详细信息,请参阅[表达式](./expressions.md)文档。
- 时间窗口函数:有关详细信息,请参阅[定义时间窗口](#define-time-window)部分。
- 标量函数:例如 `col`、`to_lowercase(col)`、`col + 1` 等。这部分与 GreptimeDB 中的标准 `SELECT` 子句相同。
查询语法中的其他部分需要注意以下几点:
- 必须包含一个 `FROM` 子句以指定 source 表。由于目前不支持 join 子句,因此只能聚合来自单个表的列。
- 支持 `WHERE` 和 `HAVING` 子句。`WHERE` 子句在聚合之前过滤数据,而 `HAVING` 子句在聚合之后过滤数据。
- `DISTINCT` 目前仅适用于 `SELECT DISTINCT column1 ..` 语法。它用于从结果集中删除重复行。`SELECT count(DISTINCT column1) ...` 尚不可用,但将来会添加。
- `GROUP BY` 子句的工作方式与标准查询相同,即按指定列对数据进行分组,在其中指定时间窗口列对于持续聚合场景至关重要。
`GROUP BY` 中的其他表达式可以是 literal、列名或 scalar 表达式。
- 不支持`ORDER BY`、`LIMIT` 和 `OFFSET`。
有关如何在实时分析、监控和仪表板中使用持续聚合的更多示例,请参阅[持续聚合](./continuous-aggregation.md)。
### 定义时间窗口
时间窗口是持续聚合查询的重要属性。
它定义了数据在流中的聚合方式。
这些窗口是左闭右开的区间。
时间窗口对应于时间范围。
source 表中的数据将根据时间索引列映射到相应的窗口。
时间窗口也是聚合表达式计算的范围,因此每个时间窗口将在结果表中生成一行。
你可以在 `SELECT` 关键字之后使用 `date_bin()` 来定义固定的时间窗口。
例如:
```sql
SELECT
max(temperature) as max_temp,
date_bin('10 seconds'::INTERVAL, ts) as time_window
FROM temp_sensor_data
GROUP BY time_window;
```
在此示例中,`date_bin('10 seconds'::INTERVAL, ts)` 函数创建从 UTC 00:00:00 开始的 10 秒时间窗口。
`max(temperature)` 函数计算每个时间窗口内的最大温度值。
有关该函数行为的更多详细信息,
请参阅 [`date_bin`](/reference/sql/functions/df-functions.md#date_bin)。
:::tip 提示
目前,flow 依赖时间窗口表达式来确定如何增量更新结果。因此,建议尽可能使用相对较小的时间窗口。
:::
## 刷新 flow
当 source 表中有新数据到达时,flow 引擎会在短时间内(比如数秒)自动处理聚合操作。
但你依然可以使用 `ADMIN FLUSH_FLOW` 命令手动触发 flow 引擎立即执行聚合操作。
```sql
ADMIN FLUSH_FLOW('')
```
## 删除 flow
请使用以下 `DROP FLOW` 子句删除 flow:
```sql
DROP FLOW [IF EXISTS]
```
例如:
```sql
DROP FLOW IF EXISTS my_flow;
```
---
## 流计算
GreptimeDB 的 Flow 引擎实现了数据流的实时计算。
它特别适用于提取 - 转换 - 加载 (ETL) 过程或执行即时的过滤、计算和查询,例如求和、平均值和其他聚合。
Flow 引擎确保数据被增量和连续地处理,
根据到达的新的流数据更新最终结果。
你可以将其视为一个聪明的物化视图,
它知道何时更新结果视图表以及如何以最小的努力更新它。
使用案例包括:
- 降采样数据点,使用如平均池化等方法减少存储和分析的数据量
- 提供近实时分析、可操作的信息
## 程序模型
在将数据插入 source 表后,
数据会同时被写入到 Flow 引擎中。
在每个触发间隔(一秒)时,
Flow 引擎执行指定的计算并将结果更新到 sink 表中。
source 表和 sink 表都是 GreptimeDB 中的时间序列表。
在创建 Flow 之前,
定义这些表的 schema 并设计 Flow 以指定计算逻辑是至关重要的。
此过程在下图中直观地表示:

## 快速入门示例
为了说明 GreptimeDB 的 Flow 引擎的功能,
考虑从 nginx 日志计算 user_agent 统计信息的任务。
source 表是 `nginx_access_log`,
sink 表是 `user_agent_statistics`。
首先,创建 source 表 `nginx_access_log`。
为了优化计算 `user_agent` 字段的性能,
使用 `PRIMARY KEY` 关键字将其指定为 `TAG` 列类型。
```sql
CREATE TABLE ngx_http_log (
ip_address STRING,
http_method STRING,
request STRING,
status_code INT16,
body_bytes_sent INT32,
user_agent STRING,
response_size INT32,
ts TIMESTAMP TIME INDEX,
PRIMARY KEY (ip_address, http_method, user_agent, status_code)
) WITH ('append_mode'='true');
```
接下来,创建 sink 表 `user_agent_statistics`。
`update_at` 列跟踪数据的最后更新时间,由 Flow 引擎自动更新。
尽管 GreptimeDB 中的所有表都是时间序列表,但此计算不需要时间窗口。
因此增加了 `__ts_placeholder` 列作为时间索引占位列。
```sql
CREATE TABLE user_agent_statistics (
user_agent STRING,
total_count INT64,
update_at TIMESTAMP,
__ts_placeholder TIMESTAMP TIME INDEX,
PRIMARY KEY (user_agent)
);
```
最后,创建 Flow `user_agent_flow` 以计算 `ngx_http_log` 表中每个 user_agent 的出现次数。
```sql
CREATE FLOW user_agent_flow
SINK TO user_agent_statistics
AS
SELECT
user_agent,
COUNT(user_agent) AS total_count
FROM
ngx_http_log
GROUP BY
user_agent;
```
一旦创建了 Flow,
Flow 引擎将持续处理 `nginx_access_log` 表中的数据,并使用计算结果更新 `user_agent_statistics` 表。
要观察 Flow 的结果,
将示例数据插入 `nginx_access_log` 表。
```sql
INSERT INTO ngx_http_log
VALUES
('192.168.1.1', 'GET', '/index.html', 200, 512, 'Mozilla/5.0', 1024, '2023-10-01T10:00:00Z'),
('192.168.1.2', 'POST', '/submit', 201, 256, 'curl/7.68.0', 512, '2023-10-01T10:01:00Z'),
('192.168.1.1', 'GET', '/about.html', 200, 128, 'Mozilla/5.0', 256, '2023-10-01T10:02:00Z'),
('192.168.1.3', 'GET', '/contact', 404, 64, 'curl/7.68.0', 128, '2023-10-01T10:03:00Z');
```
插入数据后,
查询 `user_agent_statistics` 表以查看结果。
```sql
SELECT * FROM user_agent_statistics;
```
查询结果将显示 `user_agent_statistics` 表中每个 user_agent 的总数。
```sql
+-------------+-------------+----------------------------+---------------------+
| user_agent | total_count | update_at | __ts_placeholder |
+-------------+-------------+----------------------------+---------------------+
| Mozilla/5.0 | 2 | 2024-12-12 06:45:33.228000 | 1970-01-01 00:00:00 |
| curl/7.68.0 | 2 | 2024-12-12 06:45:33.228000 | 1970-01-01 00:00:00 |
+-------------+-------------+----------------------------+---------------------+
```
## 下一步
- [持续聚合](./continuous-aggregation.md):探索时间序列数据处理中的主要场景,了解持续聚合的三种常见使用案例。
- [管理 Flow](manage-flow.md):深入了解 Flow 引擎的机制和定义 Flow 的 SQL 语法。
- [表达式](expressions.md):了解 Flow 引擎支持的数据转换表达式。
---
## EMQX
[EMQX](https://www.emqx.io/) 是一款开源的大规模分布式 MQTT 消息服务器,专为物联网和实时通信应用而设计。EMQX 支持多种协议,包括 MQTT (3.1、3.1.1 和 5.0)、HTTP、QUIC 和 WebSocket 等,保证各种网络环境和硬件设备的可访问性。
GreptimeDB 可以作为 EMQX 的数据系统。请参考[将 MQTT 数据写入 GreptimeDB](https://docs.emqx.com/zh/emqx/latest/data-integration/data-bridge-greptimedb.html) 了解如何将 GreptimeDB 集成到 EMQX 中。
---
## Go
GreptimeDB 提供了用于高吞吐量数据写入的 ingester 库。
它使用 gRPC 协议,支持自动生成表结构,无需在写入数据前创建表。
更多信息请参考 [自动生成表结构](/user-guide/ingest-data/overview.md#自动生成表结构)。
GreptimeDB 提供的 Go Ingest SDK 是一个轻量级、并发安全的库,使用起来非常简单。
## 快速开始 Demo
你可以通过 [快速开始 Demo](https://github.com/GreptimeTeam/greptimedb-ingester-go/tree/main/examples) 来了解如何使用 GreptimeDB Go SDK。
## 安装
使用下方的命令安装 Go Ingest SDK:
```shell
go get -u github.com/GreptimeTeam/greptimedb-ingester-go@v0.7.2
```
引入到代码中:
```go
greptime "github.com/GreptimeTeam/greptimedb-ingester-go"
ingesterContext "github.com/GreptimeTeam/greptimedb-ingester-go/context"
"github.com/GreptimeTeam/greptimedb-ingester-go/table"
"github.com/GreptimeTeam/greptimedb-ingester-go/table/types"
)
```
## 连接数据库
如果你在启动 GreptimeDB 时设置了 [`--user-provider`](/user-guide/deployments-administration/authentication/overview.md),
则需要提供用户名和密码才能连接到 GreptimeDB。
以下示例显示了使用 SDK 连接到 GreptimeDB 时如何设置用户名和密码。
```go
cfg := greptime.NewConfig("127.0.0.1").
// 将数据库名称更改为你的数据库名称
WithDatabase("public").
// 默认端口 4001
// WithPort(4001).
// 如果服务配置了 TLS,设置 TLS 选项来启用安全连接
// WithInsecure(false).
// 设置鉴权信息
// 如果数据库不需要鉴权,移除 WithAuth 方法即可
WithAuth("username", "password")
cli, _ := greptime.NewClient(cfg)
defer cli.Close()
```
## 数据模型
表中的每条行数据包含三种类型的列:`Tag`、`Timestamp` 和 `Field`。更多信息请参考 [数据模型](/user-guide/concepts/data-model.md)。
列值的类型可以是 `String`、`Float`、`Int`、`JSON`, `Timestamp` 等。更多信息请参考 [数据类型](/reference/sql/data-types.md)。
## 设置表选项
虽然在通过 SDK 向 GreptimeDB 写入数据时会自动创建时间序列表,但你仍然可以配置表选项。
SDK 支持以下表选项:
- `auto_create_table`:默认值为 `True`。如果设置为 `False`,则表示表已经存在且不需要自动创建,这可以提高写入性能。
- `ttl`、`append_mode`、`merge_mode`:更多详情请参考[表选项](/reference/sql/create.md#table-options)。
你可以使用 `ingesterContext` 设置表选项。
例如设置 `ttl` 选项:
```go
hints := []*ingesterContext.Hint{
{
Key: "ttl",
Value: "3d",
},
}
ctx, cancel := context.WithTimeout(context.Background(), time.Second*3)
ctx = ingesterContext.New(ctx, ingesterContext.WithHint(hints))
// 使用 ingesterContext 写入数据到 GreptimeDB
// `data` 对象在之后的章节中描述
resp, err := cli.Write(ctx, data)
if err != nil {
return err
}
```
关于如何向 GreptimeDB 写入数据,请参考以下各节。
## 低级 API
GreptimeDB 的低级 API 通过向具有预定义模式的 `table` 对象添加 `row` 来写入数据。
### 创建行数据
以下代码片段首先构建了一个名为 `cpu_metric` 的表,其中包括 `host`、`cpu_user`、`cpu_sys` 和 `ts` 列。
随后,它向表中插入了一行数据。
该表包含三种类型的列:
- `Tag`:`host` 列,值类型为 `String`。
- `Field`:`cpu_user` 和 `cpu_sys` 列,值类型为 `Float`。
- `Timestamp`:`ts` 列,值类型为 `Timestamp`。
```go
// 为 CPU 指标构建表结构
cpuMetric, err := table.New("cpu_metric")
if err != nil {
// 处理错误
}
// 添加一个 'Tag' 列,用于主机标识符
cpuMetric.AddTagColumn("host", types.STRING)
// 添加一个 'Timestamp' 列,用于记录数据收集的时间
cpuMetric.AddTimestampColumn("ts", types.TIMESTAMP_MILLISECOND)
// 添加 'Field' 列,用于测量用户和系统 CPU 使用率
cpuMetric.AddFieldColumn("cpu_user", types.FLOAT)
cpuMetric.AddFieldColumn("cpu_sys", types.FLOAT)
// 插入示例数据
// 注意:参数必须按照定义的表结构中的列的顺序排列:host, ts, cpu_user, cpu_sys
err = cpuMetric.AddRow("127.0.0.1", time.Now(), 0.1, 0.12)
err = cpuMetric.AddRow("127.0.0.1", time.Now(), 0.11, 0.13)
if err != nil {
// 处理错误
}
```
为了提高写入数据的效率,你可以一次创建多行数据以便写入到 GreptimeDB。
```go
cpuMetric, err := table.New("cpu_metric")
if err != nil {
// 处理错误
}
cpuMetric.AddTagColumn("host", types.STRING)
cpuMetric.AddTimestampColumn("ts", types.TIMESTAMP_MILLISECOND)
cpuMetric.AddFieldColumn("cpu_user", types.FLOAT)
cpuMetric.AddFieldColumn("cpu_sys", types.FLOAT)
err = cpuMetric.AddRow("127.0.0.1", time.Now(), 0.1, 0.12)
if err != nil {
// 处理错误
}
memMetric, err := table.New("mem_metric")
if err != nil {
// 处理错误
}
memMetric.AddTagColumn("host", types.STRING)
memMetric.AddTimestampColumn("ts", types.TIMESTAMP_MILLISECOND)
memMetric.AddFieldColumn("mem_usage", types.FLOAT)
err = memMetric.AddRow("127.0.0.1", time.Now(), 112)
if err != nil {
// 处理错误
}
```
### 插入数据
下方示例展示了如何向 GreptimeDB 的表中插入行数据。
```go
resp, err := cli.Write(context.Background(), cpuMetric, memMetric)
if err != nil {
// 处理错误
}
log.Printf("affected rows: %d\n", resp.GetAffectedRows().GetValue())
```
### 流式插入
当你需要插入大量数据时,例如导入历史数据,流式插入是非常有用的。
```go
err := cli.StreamWrite(context.Background(), cpuMetric, memMetric)
if err != nil {
// 处理错误
}
```
在所有数据写入完毕后关闭流式写入。
一般情况下,连续写入数据时不需要关闭流式写入。
```go
affected, err := cli.CloseStream(ctx)
```
## 高级 API
SDK 的高级 API 使用 ORM 风格的对象写入数据,
它允许你以更面向对象的方式创建、插入和更新数据,为开发者提供了更友好的体验。
然而,高级 API 不如低级 API 高效。
这是因为 ORM 风格的对象在转换对象时可能会消耗更多的资源和时间。
### 创建行数据
```go
type CpuMetric struct {
Host string `greptime:"tag;column:host;type:string"`
CpuUser float64 `greptime:"field;column:cpu_user;type:float64"`
CpuSys float64 `greptime:"field;column:cpu_sys;type:float64"`
Ts time.Time `greptime:"timestamp;column:ts;type:timestamp;precision:millisecond"`
}
func (CpuMetric) TableName() string {
return "cpu_metric"
}
cpuMetrics := []CpuMetric{
{
Host: "127.0.0.1",
CpuUser: 0.10,
CpuSys: 0.12,
Ts: time.Now(),
}
}
```
### 插入数据
```go
resp, err := cli.WriteObject(context.Background(), cpuMetrics)
log.Printf("affected rows: %d\n", resp.GetAffectedRows().GetValue())
```
### 流式插入
当你需要插入大量数据时,例如导入历史数据,流式插入是非常有用的。
```go
err := streamClient.StreamWriteObject(context.Background(), cpuMetrics, memMetrics)
```
在所有数据写入完毕后关闭流式写入。
一般情况下,连续写入数据时不需要关闭流式写入。
```go
affected, err := cli.CloseStream(ctx)
```
## 插入 JSON 类型的数据
GreptimeDB 支持使用 [JSON 类型数据](/reference/sql/data-types.md#json-类型) 存储复杂的数据结构。
使用此 ingester 库,你可以通过字符串值插入 JSON 数据。
假如你有一个名为 `sensor_readings` 的表,并希望添加一个名为 `attributes` 的 JSON 列,
请参考以下代码片段。
在 [低级 API](#低级-api) 中,
你可以使用 `AddFieldColumn` 方法将列类型指定为 `types.JSON` 来添加 JSON 列。
然后使用 `struct` 或 `map` 插入 JSON 数据。
```go
sensorReadings, err := table.New("sensor_readings")
// 此处省略了创建其他列的代码
// ...
// 将列类型指定为 JSON
sensorReadings.AddFieldColumn("attributes", types.JSON)
// 使用 struct 插入 JSON 数据
type Attributes struct {
Location string `json:"location"`
Action string `json:"action"`
}
attributes := Attributes{ Location: "factory-1" }
sensorReadings.AddRow(... , attributes)
// 以下省略了写入数据的代码
// ...
```
在 [高级 API](#高级-api) 中,你可以使用 `greptime:"field;column:details;type:json"` 标签将列类型指定为 JSON。
```go
type SensorReadings struct {
// 此处省略了创建其他列的代码
// ...
// 将列类型指定为 JSON
Attributes string `greptime:"field;column:details;type:json"`
// ...
}
// 使用 struct 插入 JSON 数据
type Attributes struct {
Location string `json:"location"`
Action string `json:"action"`
}
attributes := Attributes{ Action: "running" }
sensor := SensorReadings{
// ...
Attributes: attributes,
}
// 以下省略了写入数据的代码
// ...
```
请参考 SDK 仓库中的 [示例](https://github.com/GreptimeTeam/greptimedb-ingester-go/tree/main/examples/jsondata) 获取插入 JSON 数据的可执行代码。
## Bulk 写入
当你需要批量导入数据并且要求高吞吐写入时,可以使用 Bulk Write API。它专为批量导入的场景设计,能够高效地写入大规模数据。
通过在客户端使用 Arrow IPC 编码将多个表或对象聚合,并在一次 gRPC 请求中发送,与常规 Write API 相比,可以显著减少网络开销并提升整体写入性能。
### 添加数据
你可以构建的数据对象添加到批量写入器中。
```go
// 构建 CPU 指标表
cpuMetric, err := table.New("cpu_metric")
if err != nil {
// 处理错误
}
cpuMetric.AddTagColumn("host", types.STRING)
cpuMetric.AddTimestampColumn("ts", types.TIMESTAMP_MILLISECOND)
cpuMetric.AddFieldColumn("cpu_user", types.FLOAT64)
cpuMetric.AddFieldColumn("cpu_sys", types.FLOAT64)
// 添加多行数据
cpuMetric.AddRow("127.0.0.1", time.Now(), 0.1, 0.12)
cpuMetric.AddRow("127.0.0.2", time.Now(), 0.2, 0.15)
```
### 执行 bulk 写入
```go
resp, err := cli.BulkWrite(context.TODO(), cpuMetric)
if err != nil {
// 处理错误
}
log.Printf("Bulk write affected rows: %d\n", resp.GetAffectedRows().GetValue())
```
请参考 SDK 仓库中的 [示例](https://github.com/GreptimeTeam/greptimedb-ingester-go/tree/main/examples/bulkwrite) 获取 bulk 写入的可执行代码。
## Ingester 库参考
- [API 文档](https://pkg.go.dev/github.com/GreptimeTeam/greptimedb-ingester-go)
---
## Java Ingester for GreptimeDB
GreptimeDB 提供了用于高吞吐量数据写入的 ingester 库。
它使用 gRPC 协议,支持无 schema 写入,无需在写入数据前创建表。
更多信息请参考 [自动生成表结构](/user-guide/ingest-data/overview.md#自动生成表结构)。
GreptimeDB 提供的 Java ingester SDK 是一个轻量级、高性能的客户端,专为高效的时间序列数据写入而设计。它利用 gRPC 协议提供非阻塞、纯异步的 API,在保持与应用程序无缝集成的同时提供高吞吐数据写入。
该客户端提供针对各种性能要求和使用场景优化的多种写入方法。你可以选择最适合你特定需求的方法——无论你需要低延迟操作的简单一元写入,还是处理大量时间序列数据时最大效率的高吞吐量批量流式传输。
## 架构
```
+-----------------------------------+
| Client Applications |
| +------------------+ |
| | Application Code | |
| +------------------+ |
+-------------+---------------------+
|
v
+-------------+---------------------+
| API Layer |
| +---------------+ |
| | GreptimeDB | |
| +---------------+ |
| / \ |
| v v |
| +-------------+ +-------------+ | +------------------+
| | BulkWrite | | Write | | | Data Model |
| | Interface | | Interface | |------->| |
| +-------------+ +-------------+ | | +------------+ |
+-------|----------------|----------+ | | Table | |
| | | +------------+ |
v v | | |
+-------|----------------|----------+ | v |
| Transport Layer | | +------------+ |
| +-------------+ +-------------+ | | | TableSchema| |
| | BulkWrite | | Write | | | +------------+ |
| | Client | | Client | | +------------------+
| +-------------+ +-------------+ |
| | \ / | |
| | \ / | |
| | v v | |
| | +-------------+ | |
| | |RouterClient | | |
+-----|--+-------------|---+--------+
| | | |
| | | |
v v v |
+-----|----------------|---|--------+
| Network Layer |
| +-------------+ +-------------+ |
| | Arrow Flight| | gRPC Client | |
| | Client | | | |
| +-------------+ +-------------+ |
| | | |
+-----|----------------|------------+
| |
v v
+-------------------------+
| GreptimeDB Server |
+-------------------------+
```
- **API Layer**:为客户端应用程序提供与 GreptimeDB 交互的上层接口
- **Data Model**:定义时间序列数据的结构和组织,包括表和 schemas
- **Transport Layer**:处理通信逻辑、请求路由和客户端管理
- **Network Layer**:使用 Arrow Flight 和 gRPC 底层协议通信
## 使用方法
### 安装
1. 安装 Java 开发工具包(JDK)
确保你的系统已安装 JDK 8 或更高版本。有关如何检查 Java 版本并安装 JDK 的更多信息,请参见 [Oracle JDK 安装概述文档](https://www.oracle.com/java/technologies/javase-downloads.html)
2. 将 GreptimeDB Java SDK 添加为依赖项
如果你使用的是 [Maven](https://maven.apache.org/),请将以下内容添加到 pom.xml 的依赖项列表中:
```xml
io.greptime
ingester-all
0.15.0
```
最新版本可以在 [这里](https://central.sonatype.com/search?q=io.greptime&name=ingester-all) 查看。
配置依赖项后,请确保它们对项目可用。这可能需要在 IDE 中刷新项目或运行依赖项管理器。
### 客户端初始化
GreptimeDB Ingester Java 客户端的入口点是 `GreptimeDB` 类。你可以通过调用静态创建方法并传入适当的配置选项来创建客户端实例。
```java
// GreptimeDB 在默认目录 "greptime" 中有一个名为 "public" 的默认数据库,
// 我们可以将其用作测试数据库
String database = "public";
// 默认情况下,GreptimeDB 使用 gRPC 协议在端口 4001 上监听。
// 我们可以提供多个指向同一 GreptimeDB 集群的端点。
// 客户端将基于负载均衡策略调用这些端点。
// 客户端执行定期健康检查并自动将请求路由到健康节点,
// 为你的应用程序提供容错能力和改进的可靠性。
String[] endpoints = {"127.0.0.1:4001"};
// 设置认证信息。
AuthInfo authInfo = new AuthInfo("username", "password");
GreptimeOptions opts = GreptimeOptions.newBuilder(endpoints, database)
// 如果数据库不需要认证,我们可以使用 `AuthInfo.noAuthorization()` 作为参数。
.authInfo(authInfo)
// 如果你的服务器由 TLS 保护,请启用安全连接
//.tlsOptions(new TlsOptions())
// 好的开始 ^_^
.build();
// 初始化客户端
// 注意:客户端实例是线程安全的,应作为全局单例重用
// 以获得更好的性能和资源利用率。
GreptimeDB client = GreptimeDB.create(opts);
```
### 写入数据
Ingester 通过 `Table` 抽象为写入数据到 GreptimeDB 提供了统一的方法。所有数据写入操作,包括高级 API,都建立在这个基础结构之上。要写入数据,你需要创建一个 `Table` 为其填充时间序列数据,最后将其写入数据库。
#### 创建和写入表
定义表结构并创建表:
```java
// 创建表结构
TableSchema schema = TableSchema.newBuilder("metrics")
.addTag("host", DataType.String)
.addTag("region", DataType.String)
.addField("cpu_util", DataType.Float64)
.addField("memory_util", DataType.Float64)
.addTimestamp("ts", DataType.TimestampMillisecond)
.build();
// 从 schema 创建表数据容器
Table table = Table.from(schema);
// 向表中添加行
// 值必须按照结构中定义的顺序提供
// 在这种情况下:addRow(host, region, cpu_util, memory_util, ts)
table.addRow("host1", "us-west-1", 0.42, 0.78, System.currentTimeMillis());
table.addRow("host2", "us-west-2", 0.46, 0.66, System.currentTimeMillis());
// 添加更多行
// ..
// 把表标记为完成以使其不可变。这将最终确定表的数据内容以进行写入。
// 如果你忘记了调用此方法,它将在表数据写入前自动在内部调用
table.complete();
// 写入数据库
CompletableFuture> future = client.write(table);
```
GreptimeDB 支持使用 [JSON 类型数据](/reference/sql/data-types.md#json-类型) 存储复杂的数据结构。你可以在表结构中定义 JSON 列,并使用 Map 对象插入数据:
```java
// 为 sensor_readings 构建表结构
TableSchema sensorReadings = TableSchema.newBuilder("sensor_readings")
// 省略创建其他列的代码
// ...
// 将列类型指定为 JSON
.addField("attributes", DataType.Json)
.build();
// ...
// 使用 map 插入 JSON 数据
Map attr = new HashMap<>();
attr.put("location", "factory-1");
Table table = Table.from(sensorReadings);
table.addRow(... , attr);
```
##### TableSchema
`TableSchema` 定义了写入数据到 GreptimeDB 的结构。它指定表结构,包括列名、语义类型和数据类型。有关列语义类型(`Tag`、`Timestamp`、`Field`)的详细信息,请参考 [数据模型](/user-guide/concepts/data-model.md) 文档。
##### Table
`Table` 接口表示可以写入到 GreptimeDB 的数据。它提供添加行和操作数据的方法。本质上,`Table` 将数据临时存储在内存中,允许你在将数据发送到数据库之前累积多行进行批处理,这比写入单个行显著提高了写入效率。
表经历几个不同的生命周期阶段:
1. **创建**:使用 `Table.from(schema)` 从 schema 初始化表
2. **数据添加**:使用 `addRow()` 方法用行填充表
3. **完成**:添加所有行后使用 `complete()` 冻结表不允许再修改
4. **写入**:将完成的表发送到数据库
重要提醒:
- 表不是线程安全的,应该单线程访问
- 写入后不能重用表 - 需要为每个写入操作创建新实例
- 关联的 `TableSchema` 是不可变的,可以在多个操作中安全地复用
### 写入操作
虽然在通过 SDK 向 GreptimeDB 写入数据时会自动创建时间序列表,
但你仍然可以配置表选项。
SDK 支持以下表选项:
- `auto_create_table`:默认为 `True`。如果设置为 `False`,表示表已经存在且不需要自动创建,这可以提高写入性能。
- `ttl`、`append_mode`、`merge_mode`:更多详情请参考 [表选项](/reference/sql/create.md#table-options)。
你可以使用 `Context` 设置表选项。
例如,要设置 `ttl` 选项,请使用以下代码:
```java
Context ctx = Context.newDefault();
// 添加提示使数据库创建具有指定 TTL(生存时间)的表
ctx = ctx.withHint("ttl", "3d");
// 将压缩算法设置为 Zstd。
ctx = ctx.withCompression(Compression.Zstd);
// 写入数据到 GreptimeDB 时使用 ctx
CompletableFuture> future = client.write(Arrays.asList(table1, table2), WriteOp.Insert, ctx);
```
有关如何向 GreptimeDB 写入数据,请参阅以下部分。
### 批量写入
批量写入允许你在单个请求中向多个表写入数据。它返回 `CompletableFuture>` 是一个典型的异步编程方式。
对于大多数使用场景,这是向 GreptimeDB 写入数据的推荐方式。
```java
// 批量写入 API
CompletableFuture> future = client.write(table1, table2, table3);
// 出于性能考虑,SDK 被设计为纯异步的。
// 返回值是一个 CompletableFuture 对象。如果你想立即获取
// 结果,可以调用 `future.get()`,这将阻塞直到操作完成。
// 对于生产环境,建议使用回调或
// CompletableFuture API 等非阻塞方法。
Result result = future.get();
```
### 流式写入
流式写入 API 维护到 GreptimeDB 的持久连接,以便进行具有速率限制的连续数据写入。它允许通过单个流向多个表写入数据。
以下场景推荐使用此 API:
- 中小规模的连续数据收集
- 通过一个连接管道写入多个表的数据
- 简单性和便利性比最大吞吐量更重要的情况
```java
// 创建流写入器
StreamWriter writer = client.streamWriter();
// 写入多个表
writer.write(table1)
.write(table2)
.write(table3);
// 完成流并获取结果
CompletableFuture result = writer.completed();
```
你还可以为流式写入设置速率限制:
```java
// 限制为每秒 1000 个数据点
StreamWriter writer = client.streamWriter(1000);
```
### Bulk 写入
Bulk 写入 API 提供了一种高性能、内存高效的机制,用于将大量时间序列数据写入到 GreptimeDB 中。它利用堆外内存管理,在写入大批量数据时实现最佳吞吐量。
**重要说明**:
1. **需要手动创建表**:Bulk API **不会**自动创建表。你必须事先创建表,使用以下方法之一:
- 常规写入 API(支持自动创建表),或
- SQL DDL 语句(CREATE TABLE)
2. **Schema 匹配**:Bulk API 中的表模板必须与现有表结构完全匹配。
此 API 仅支持每个流写入一个表,并处理大数据量(每次写入可高达 200MB+),具有自适应流量控制。性能优势包括:
- 使用 Arrow 缓冲区的堆外内存管理减少不必要的内置拷贝
- 高效的二进制序列化和数据传输
- 可选压缩选项
- 批量操作
此方法特别适用于:
- 大规模批处理和数据迁移
- 高吞吐量日志和传感器数据写入
- 具有苛刻性能要求的时间序列应用程序
- 处理高频数据收集的系统
以下是使用批处理写入 API 的典型模式:
```java
// 使用表结构创建 BulkStreamWriter
try (BulkStreamWriter writer = greptimeDB.bulkStreamWriter(schema)) {
// 写入多个批次
for (int batch = 0; batch < batchCount; batch++) {
// 为此批次获取 TableBufferRoot
Table.TableBufferRoot table = writer.tableBufferRoot(1000); // 列缓冲区大小
// 向批次添加行
for (int row = 0; row < rowsPerBatch; row++) {
Object[] rowData = generateRow(batch, row);
table.addRow(rowData);
}
// 完成表以准备传输
table.complete();
// 发送批次并获取完成的 future
CompletableFuture future = writer.writeNext();
// 等待批次被处理(可选)
Integer affectedRows = future.get();
System.out.println("Batch " + batch + " wrote " + affectedRows + " rows");
}
// 发出流完成信号
writer.completed();
}
```
#### 配置
可以使用多个选项配置 Bulk API 以优化性能:
```java
BulkWrite.Config cfg = BulkWrite.Config.newBuilder()
.allocatorInitReservation(64 * 1024 * 1024L) // 自定义内存分配:64MB 初始保留
.allocatorMaxAllocation(4 * 1024 * 1024 * 1024L) // 自定义内存分配:4GB 最大分配
.timeoutMsPerMessage(60 * 1000) // 每个请求 60 秒超时
.maxRequestsInFlight(8) // 并发控制:配置 8 个最大并发请求
.build();
// 启用 Zstd 压缩
Context ctx = Context.newDefault().withCompression(Compression.Zstd);
BulkStreamWriter writer = greptimeDB.bulkStreamWriter(schema, cfg, ctx);
```
### 资源管理
使用完客户端后正确关闭客户端很重要:
```java
// 优雅地关闭客户端
client.shutdownGracefully();
```
### 性能调优
#### 压缩选项
Ingester 支持各种压缩算法以降低网络带宽占用并提高吞吐量。
```java
// 将压缩算法设置为 Zstd
Context ctx = Context.newDefault().withCompression(Compression.Zstd);
```
#### 写入操作比较
了解不同写入方法的性能特征对于优化数据写入至关重要。
| 写入方法 | API | 吞吐量 | 延迟 | 内存效率 | CPU 使用 | 最佳用途 | 限制 |
|----------|-----|---------|------|----------|----------|----------|------|
| Batching Write | `write(tables)` | 较好 | 良好 | 高 | 较高 | 简单应用程序,低延迟需求 | 大量数据的吞吐量较低 |
| Streaming Write | `streamWriter()` | 中等 | 良好 | 中等 | 中等 | 连续数据流,中等吞吐量 | 比常规写入更复杂 |
| Bulk Write | `bulkStreamWriter()` | 最佳 | 较高 | 最佳 | 中等 | 最大吞吐量,大批量操作 | 延迟较高,需要手动创建表 |
#### 缓冲区大小优化
使用 `BulkStreamWriter` 时,你可以配置列缓冲区大小:
```java
// 获取具有特定列缓冲区大小的表缓冲区
Table.TableBufferRoot table = bulkStreamWriter.tableBufferRoot(columnBufferSize);
```
此选项可以显著提高数据转换为底层格式的速度。为了获得最佳性能,我们建议将列缓冲区大小设置为 1024 或更大,具体取决于你的特定工作负载特征和可用内存。
### 导出指标
Ingester 公开全面的指标,使你能够监控其性能、健康状况和操作状态。
有关可用指标及其使用的详细信息,请参考 [Ingester Prometheus Metrics](https://github.com/GreptimeTeam/greptimedb-ingester-java/tree/main/ingester-prometheus-metrics) 文档。
## 主要配置选项
`GreptimeOptions` 是 GreptimeDB Java 客户端的主要配置类,用于配置客户端连接、写入选项、RPC 设置和各种其他参数。
对于生产环境,你可能需要配置这些常用选项。完整参考:[GreptimeOptions JavaDoc](https://javadoc.io/static/io.greptime/ingester-protocol/0.15.0/io/greptime/options/GreptimeOptions.html)。
**主要选项:**
- `database`:目标数据库名称,格式为 `[catalog-]schema`(默认值:`public`)
- `authInfo`:生产环境的身份验证凭据
- `rpcOptions.defaultRpcTimeout`:RPC 请求超时时间(默认值:60 秒)
- `writeMaxRetries`:写入失败时的最大重试次数(默认值:1)
- `maxInFlightWritePoints`:写入流控制的最大在途数据点数(默认值:655360)
- `writeLimitedPolicy`:写入流量限制超出时的策略(默认值:AbortOnBlockingTimeoutPolicy 3秒)
- `defaultStreamMaxWritePointsPerSecond`:StreamWriter 的速率限制(默认值:655360)
```java
// Production-ready configuration
RpcOptions rpcOpts = RpcOptions.newDefault();
rpcOpts.setDefaultRpcTimeout(30000); // 30 seconds timeout
AuthInfo authInfo = new AuthInfo("username", "password");
GreptimeOptions options = GreptimeOptions.newBuilder("127.0.0.1:4001", "production_db")
.authInfo(authInfo)
.rpcOptions(rpcOpts)
.writeMaxRetries(3)
.maxInFlightWritePoints(1000000)
.writeLimitedPolicy(new LimitedPolicy.AbortOnBlockingTimeoutPolicy(5, TimeUnit.SECONDS))
.defaultStreamMaxWritePointsPerSecond(50000)
.build();
```
## FAQ
### 为什么我会遇到一些连接异常?
使用 GreptimeDB Java ingester SDK 时,你可能会遇到一些连接异常。
例如,异常是"`Caused by: java.nio.channels.UnsupportedAddressTypeException`"、
"`Caused by: java.net.ConnectException: connect(..) failed: Address family not supported by protocol`" 或
"`Caused by: java.net.ConnectException: connect(..) failed: Invalid argument`"。当你确定
GreptimeDB 服务器正在运行,并且其端点可达时。
这些连接异常可能都是因为在打包过程中,gRPC 的 `io.grpc.NameResolverProvider` 服务提供程序没有
打包到最终的 JAR 中。所以修复方法可以是:
- 如果你使用 Maven Assembly 插件,请将 `metaInf-services` 容器描述符处理程序添加到你的 assembly
文件中,如下所示:
```xml
...
metaInf-services
```
- 如果你使用 Maven Shade 插件,可以添加 `ServicesResourceTransformer`:
```xml
...
org.apache.maven.plugins
maven-shade-plugin
3.6.0
shade
...
```
## API 文档和示例
- [API 参考](https://javadoc.io/doc/io.greptime/ingester-protocol/latest/index.html)
- [示例](https://github.com/GreptimeTeam/greptimedb-ingester-java/tree/main/ingester-example/)
---
## 使用 SDK 写入数据
本指南将演示如何使用 SDK 在 GreptimeDB 中写入数据。
- [Go](go.md)
- [Java](java.md)
- [Rust](https://github.com/GreptimeTeam/greptimedb-ingester-rust)
- [.NET](https://github.com/GreptimeTeam/greptimedb-ingester-dotnet)
- [Erlang](https://github.com/GreptimeTeam/greptimedb-ingester-erl)
- [TypeScript](https://github.com/GreptimeTeam/greptimedb-ingester-ts)
---
## InfluxDB Line Protocol
GreptimeDB 支持 HTTP InfluxDB Line 协议。
## 写入新数据
### 协议
#### Post 指标
你可以通过 `/influxdb/write` API 写入数据。
以下是一个示例:
```shell
curl -i -XPOST "http://localhost:4000/v1/influxdb/api/v2/write?db=public&precision=ms" \
-H "authorization: token {{greptime_user:greptimedb_password}}" \
--data-binary \
'monitor,host=127.0.0.1 cpu=0.1,memory=0.4 1667446797450
monitor,host=127.0.0.2 cpu=0.2,memory=0.3 1667446798450
monitor,host=127.0.0.1 cpu=0.5,memory=0.2 1667446798450'
```
```shell
curl -i -XPOST "http://localhost:4000/v1/influxdb/write?db=public&precision=ms&u=&p=" \
--data-binary \
'monitor,host=127.0.0.1 cpu=0.1,memory=0.4 1667446797450
monitor,host=127.0.0.2 cpu=0.2,memory=0.3 1667446798450
monitor,host=127.0.0.1 cpu=0.5,memory=0.2 1667446798450'
```
`/influxdb/write` 支持查询参数,包括:
* `db`:指定要写入的数据库。默认值为 `public`。
* `precision`:定义请求体中提供的时间戳的精度,可接受的值为 `ns`(纳秒)、`us`(微秒)、`ms`(毫秒)和 `s`(秒),默认值为 `ns`(纳秒)。该 API 写入的时间戳类型为 `TimestampNanosecond`,因此默认精度为 `ns`(纳秒)。如果你在请求体中使用了其他精度的时间戳,需要使用此参数指定精度。该参数确保时间戳能够被准确解释并以纳秒精度存储。
你还可以在发送请求时省略 timestamp,GreptimeDB 将使用主机机器的当前系统时间(UTC 时间)作为 timestamp。例如:
```shell
curl -i -XPOST "http://localhost:4000/v1/influxdb/api/v2/write?db=public" \
-H "authorization: token {{greptime_user:greptimedb_password}}" \
--data-binary \
'monitor,host=127.0.0.1 cpu=0.1,memory=0.4
monitor,host=127.0.0.2 cpu=0.2,memory=0.3
monitor,host=127.0.0.1 cpu=0.5,memory=0.2'
```
```shell
curl -i -XPOST "http://localhost:4000/v1/influxdb/write?db=public&u=&p=" \
--data-binary \
'monitor,host=127.0.0.1 cpu=0.1,memory=0.4
monitor,host=127.0.0.2 cpu=0.2,memory=0.3
monitor,host=127.0.0.1 cpu=0.5,memory=0.2'
```
#### 鉴权
GreptimeDB 与 InfluxDB 的行协议鉴权格式兼容,包括 V1 和 V2。
如果你在 GreptimeDB 中[配置了鉴权](/user-guide/deployments-administration/authentication/overview.md),需要在 HTTP 请求中提供用户名和密码。
InfluxDB 的 [V2 协议](https://docs.influxdata.com/influxdb/v1.8/tools/api/?t=Auth+Enabled#apiv2query-http-endpoint) 使用了类似 HTTP 标准 basic 认证方案的格式。
```shell
curl 'http://localhost:4000/v1/influxdb/api/v2/write?db=public' \
-H 'authorization: token {{username:password}}' \
-d 'monitor,host=127.0.0.1 cpu=0.1,memory=0.4'
```
对于 InfluxDB 的 [V1 协议](https://docs.influxdata.com/influxdb/v1.8/tools/api/?t=Auth+Enabled#query-string-parameters-1) 的鉴权格式。在 HTTP 查询字符串中添加 `u` 作为用户和 `p` 作为密码,如下所示:
```shell
curl 'http://localhost:4000/v1/influxdb/write?db=public&u=&p=' \
-d 'monitor,host=127.0.0.1 cpu=0.1,memory=0.4'
```
### Telegraf
GreptimeDB 支持 [InfluxDB 行协议](../for-iot/influxdb-line-protocol.md)也意味着 GreptimeDB 与 Telegraf 兼容。
要配置 Telegraf,只需将 GreptimeDB 的 URL 添加到 Telegraf 配置中:
```toml
[[outputs.influxdb_v2]]
urls = ["http://:4000/v1/influxdb"]
token = ":"
bucket = ""
## Leave empty
organization = ""
```
```toml
[[outputs.influxdb]]
urls = ["http://:4000/v1/influxdb"]
database = ""
username = ""
password = ""
```
## 数据模型
你可能已经熟悉了 [InfluxDB 的关键概念](https://docs.influxdata.com/influxdb/v2/reference/key-concepts/),
GreptimeDB 的[数据模型](/user-guide/concepts/data-model.md) 是值得了解的新事物。
下方解释了 GreptimeDB 和 InfluxDB 数据模型的相似和不同之处:
- 两者都是 [schemaless 写入](/user-guide/ingest-data/overview.md#自动生成表结构)的解决方案,这意味着在写入数据之前无需定义表结构。
- GreptimeDB 的表在自动创建时会设置表选项 [`merge_mode`](/reference/sql/create.md#创建带有-merge-模式的表)为 `last_non_null`。
这意味着表会通过保留每个字段的最新值来合并具有相同主键和时间戳的行,该行为与 InfluxDB 相同。
- 在 InfluxDB 中,一个点代表一条数据记录,包含一个 measurement、tag 集、field 集和时间戳。
在 GreptimeDB 中,它被表示为时间序列表中的一行数据。
表名对应于 measurement,列由三种类型组成:Tag、Field 和 Timestamp。
- GreptimeDB 使用 `TimestampNanosecond` 作为来自 [InfluxDB 行协议 API](/user-guide/ingest-data/for-iot/influxdb-line-protocol.md) 的时间戳数据类型。
- GreptimeDB 使用 `Float64` 作为来自 InfluxDB 行协议 API 的数值数据类型。
以 InfluxDB 文档中的[示例数据](https://docs.influxdata.com/influxdb/v2/reference/key-concepts/data-elements/#sample-data)为例:
|_time|_measurement|location|scientist|_field|_value|
|---|---|---|---|---|---|
|2019-08-18T00:00:00Z|census|klamath|anderson|bees|23|
|2019-08-18T00:00:00Z|census|portland|mullen|ants|30|
|2019-08-18T00:06:00Z|census|klamath|anderson|bees|28|
|2019-08-18T00:06:00Z|census|portland|mullen|ants|32|
上述数据的 InfluxDB 行协议格式为:
```shell
census,location=klamath,scientist=anderson bees=23 1566086400000000000
census,location=portland,scientist=mullen ants=30 1566086400000000000
census,location=klamath,scientist=anderson bees=28 1566086760000000000
census,location=portland,scientist=mullen ants=32 1566086760000000000
```
在 GreptimeDB 数据模型中,上述数据将被表示为 `census` 表中的以下内容:
```sql
+---------------------+----------+-----------+------+------+
| greptime_timestamp | location | scientist | bees | ants |
+---------------------+----------+-----------+------+------+
| 2019-08-18 00:00:00 | klamath | anderson | 23 | NULL |
| 2019-08-18 00:06:00 | klamath | anderson | 28 | NULL |
| 2019-08-18 00:00:00 | portland | mullen | NULL | 30 |
| 2019-08-18 00:06:00 | portland | mullen | NULL | 32 |
+---------------------+----------+-----------+------+------+
```
`census` 表结构如下:
```sql
+--------------------+----------------------+------+------+---------+---------------+
| Column | Type | Key | Null | Default | Semantic Type |
+--------------------+----------------------+------+------+---------+---------------+
| location | String | PRI | YES | | TAG |
| scientist | String | PRI | YES | | TAG |
| bees | Float64 | | YES | | FIELD |
| greptime_timestamp | TimestampNanosecond | PRI | NO | | TIMESTAMP |
| ants | Float64 | | YES | | FIELD |
+--------------------+----------------------+------+------+---------+---------------+
```
## 参考
- [InfluxDB Line protocol](https://docs.influxdata.com/influxdb/v2.7/reference/syntax/line-protocol/)
---
## Kafka
请参考 [Kafka 文档](/user-guide/ingest-data/for-observability/kafka.md)了解如何将数据从 Kafka 写入到 GreptimeDB。
---
## OpenTSDB
GreptimeDB 支持通过 HTTP API 使用 OpenTSDB 协议。
## 写入新数据
### HTTP API
GreptimeDB 还支持通过 HTTP 接口插入 OpenTSDB 数据,接口是 `/opentsdb/api/put`,使用的请求和响应格式与 OpenTSDB 的 `/api/put` 接口相同。
GreptimeDB 的 HTTP Server 默认监听 `4000` 端口。例如使用 curl 写入一个指标数据:
```shell
curl -X POST http://127.0.0.1:4000/v1/opentsdb/api/put \
-H 'Authorization: Basic {{authentication}}' \
-d '
{
"metric": "sys.cpu.nice",
"timestamp": 1667898896,
"value": 18,
"tags": {
"host": "web01",
"dc": "hz"
}
}
'
```
插入多个指标数据:
```shell
curl -X POST http://127.0.0.1:4000/v1/opentsdb/api/put \
-H 'Authorization: Basic {{authentication}}' \
-d '
[
{
"metric": "sys.cpu.nice",
"timestamp": 1667898896,
"value": 1,
"tags": {
"host": "web02",
"dc": "hz"
}
},
{
"metric": "sys.cpu.nice",
"timestamp": 1667898897,
"value": 9,
"tags": {
"host": "web03",
"dc": "sh"
}
}
]
'
```
:::tip 注意
记得在路径前加上 GreptimeDB 的 HTTP API 版本 `v1`。
:::
---
## 物联网(IoT)数据写入
数据的写入是物联网数据流程的关键部分。
它从各种来源(如传感器、设备和应用程序)收集数据并将其存储在中央位置以供进一步处理和分析。
数据写入过程对于确保数据的准确性、可靠性和安全性至关重要。
GreptimeDB 可处理并存储超大规模量级的数据以供分析,
支持各种数据格式、协议和接口,以便集成不同的物联网设备和系统。
- [SQL INSERT](sql.md):简单直接的数据插入方法。
- [gRPC SDK](./grpc-sdks/overview.md):提供高效、高性能的数据写入,特别适用于实时数据和复杂的物联网基础设施。
- [InfluxDB Line Protocol](influxdb-line-protocol.md):一种广泛使用的时间序列数据协议,便于从 InfluxDB 迁移到 GreptimeDB。该文档同样介绍了 Telegraf 的集成方式。
- [EMQX](emqx.md):支持大规模设备连接的 MQTT 代理,可直接将数据写入到 GreptimeDB。
- [OpenTSDB](opentsdb.md):使用 OpenTSDB 协议将数据写入到 GreptimeDB。
---
## SQL
你可以使用 [MySQL](/user-guide/protocols/mysql.md) 或 [PostgreSQL](/user-guide/protocols/postgresql.md) 客户端执行 SQL 语句,
使用任何你喜欢的编程语言(如 Java JDBC)通过 MySQL 或 PostgreSQL 协议访问 GreptimeDB。
我们将使用 `monitor` 表作为示例来展示如何写入数据。有关如何创建 `monitor` 表的 SQL 示例,请参见[表管理](/user-guide/deployments-administration/manage-data/basic-table-operations.md#创建表)。
## 创建表
在插入数据之前,你需要创建一个表。例如,创建一个名为 `monitor` 的表:
```sql
CREATE TABLE monitor (
host STRING,
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP() TIME INDEX,
cpu FLOAT64 DEFAULT 0,
memory FLOAT64,
PRIMARY KEY(host));
```
上述语句将创建一个具有以下 schema 的表:
```sql
+--------+----------------------+------+------+---------------------+---------------+
| Column | Type | Key | Null | Default | Semantic Type |
+--------+----------------------+------+------+---------------------+---------------+
| host | String | PRI | YES | | TAG |
| ts | TimestampMillisecond | PRI | NO | current_timestamp() | TIMESTAMP |
| cpu | Float64 | | YES | 0 | FIELD |
| memory | Float64 | | YES | | FIELD |
+--------+----------------------+------+------+---------------------+---------------+
4 rows in set (0.01 sec)
```
有关 `CREATE TABLE` 语句的更多信息,请参阅[表管理](/user-guide/deployments-administration/manage-data/basic-table-operations.md#create-a-table)。
## 插入数据
让我们向 `monitor` 表中插入一些测试数据。你可以使用 `INSERT INTO` 语句:
```sql
INSERT INTO monitor
VALUES
("127.0.0.1", 1702433141000, 0.5, 0.2),
("127.0.0.2", 1702433141000, 0.3, 0.1),
("127.0.0.1", 1702433146000, 0.3, 0.2),
("127.0.0.2", 1702433146000, 0.2, 0.4),
("127.0.0.1", 1702433151000, 0.4, 0.3),
("127.0.0.2", 1702433151000, 0.2, 0.4);
```
```sql
Query OK, 6 rows affected (0.01 sec)
```
你还可以插入数据时指定列名:
```sql
INSERT INTO monitor (host, ts, cpu, memory)
VALUES
("127.0.0.1", 1702433141000, 0.5, 0.2),
("127.0.0.2", 1702433141000, 0.3, 0.1),
("127.0.0.1", 1702433146000, 0.3, 0.2),
("127.0.0.2", 1702433146000, 0.2, 0.4),
("127.0.0.1", 1702433151000, 0.4, 0.3),
("127.0.0.2", 1702433151000, 0.2, 0.4);
```
通过上面的语句,我们成功的向 `monitor` 表中插入了六条数据。请参考 [`INSERT`](/reference/sql/insert.md) 获得更多写入数据的相关信息。
## 时区
SQL 客户端中指定的时区将影响没有时区信息的字符串格式的时间戳。
该时间戳值将会自动添加客户端的时区信息。
例如,下面的 SQL 将时区设置为 `+8:00`:
```sql
SET time_zone = '+8:00';
```
然后向 `monitor` 表中插入值:
```sql
INSERT INTO monitor (host, ts, cpu, memory)
VALUES
("127.0.0.1", "2024-01-01 00:00:00", 0.4, 0.1),
("127.0.0.2", "2024-01-01 00:00:00+08:00", 0.5, 0.1);
```
第一个时间戳值 `2024-01-01 00:00:00` 没有时区信息,因此它将自动添加客户端的时区信息。
在插入数据后,它将等同于第二个值 `2024-01-01 00:00:00+08:00`。
`+8:00` 时区下的结果如下:
```sql
+-----------+---------------------+------+--------+
| host | ts | cpu | memory |
+-----------+---------------------+------+--------+
| 127.0.0.1 | 2024-01-01 00:00:00 | 0.4 | 0.1 |
| 127.0.0.2 | 2024-01-01 00:00:00 | 0.5 | 0.1 |
+-----------+---------------------+------+--------+
```
`UTC` 时区下的结果如下:
```sql
+-----------+---------------------+------+--------+
| host | ts | cpu | memory |
+-----------+---------------------+------+--------+
| 127.0.0.1 | 2023-12-31 16:00:00 | 0.4 | 0.1 |
| 127.0.0.2 | 2023-12-31 16:00:00 | 0.5 | 0.1 |
+-----------+---------------------+------+--------+
```
---
## Grafana Alloy
[Grafana Alloy](https://grafana.com/docs/alloy/latest/) 是一个用于 OpenTelemetry (OTel)、Prometheus、Pyroscope、Loki 等其他指标、日志、追踪和分析工具的可观测性数据管道。
你可以将 GreptimeDB 集成为 Alloy 的数据接收端。
## Prometheus Remote Write
将 GreptimeDB 配置为远程写入目标:
```hcl
prometheus.remote_write "greptimedb" {
endpoint {
url = "${GREPTIME_SCHEME:=http}://${GREPTIME_HOST:=greptimedb}:${GREPTIME_PORT:=4000}/v1/prometheus/write?db=${GREPTIME_DB:=public}"
basic_auth {
username = "${GREPTIME_USERNAME}"
password = "${GREPTIME_PASSWORD}"
}
}
}
```
- `GREPTIME_HOST`: GreptimeDB 主机地址,例如 `localhost`。
- `GREPTIME_DB`: GreptimeDB 数据库名称,默认是 `public`。
- `GREPTIME_USERNAME` 和 `GREPTIME_PASSWORD`: GreptimeDB 的[鉴权认证信息](/user-guide/deployments-administration/authentication/static.md)。
有关从 Prometheus 到 GreptimeDB 的数据模型转换的详细信息,请参阅 Prometheus Remote Write 指南中的[数据模型](/user-guide/ingest-data/for-observability/prometheus.md#数据模型)部分。
## OpenTelemetry
GreptimeDB 也可以配置为 OpenTelemetry Collector 的目标。
### 指标
```hcl
otelcol.exporter.otlphttp "greptimedb" {
client {
endpoint = "${GREPTIME_SCHEME:=http}://${GREPTIME_HOST:=greptimedb}:${GREPTIME_PORT:=4000}/v1/otlp/"
headers = {
"X-Greptime-DB-Name" = "${GREPTIME_DB:=public}",
}
auth = otelcol.auth.basic.credentials.handler
}
}
otelcol.auth.basic "credentials" {
username = "${GREPTIME_USERNAME}"
password = "${GREPTIME_PASSWORD}"
}
```
- `GREPTIME_HOST`: GreptimeDB 主机地址,例如 `localhost`。
- `GREPTIME_DB`: GreptimeDB 数据库名称,默认是 `public`。
- `GREPTIME_USERNAME` 和 `GREPTIME_PASSWORD`: GreptimeDB 的[鉴权认证信息](/user-guide/deployments-administration/authentication/static.md)。
有关从 OpenTelemetry 到 GreptimeDB 的指标数据模型转换的详细信息,请参阅 OpenTelemetry 指南中的[数据模型](/user-guide/ingest-data/for-observability/opentelemetry.md#数据模型)部分。
### 日志
此示例通过 OpenTelemetry 管道将日志发送到 GreptimeDB。
对于生产环境中的日志管道,建议在 exporter 之前显式添加一个 batch processor。详情请参阅[批处理](#批处理)部分。
```hcl
loki.source.file "greptime" {
targets = [
{__path__ = "/tmp/foo.txt"},
]
forward_to = [otelcol.receiver.loki.greptime.receiver]
}
otelcol.receiver.loki "greptime" {
output {
logs = [otelcol.processor.batch.greptimedb_logs.input]
}
}
otelcol.processor.batch "greptimedb_logs" {
send_batch_size = 5000
send_batch_max_size = 10000
timeout = "1s"
output {
logs = [otelcol.exporter.otlphttp.greptimedb_logs.input]
}
}
otelcol.auth.basic "credentials" {
username = "${GREPTIME_USERNAME}"
password = "${GREPTIME_PASSWORD}"
}
otelcol.exporter.otlphttp "greptimedb_logs" {
client {
endpoint = "${GREPTIME_SCHEME:=http}://${GREPTIME_HOST:=greptimedb}:${GREPTIME_PORT:=4000}/v1/otlp/"
headers = {
"X-Greptime-DB-Name" = "${GREPTIME_DB:=public}",
"X-Greptime-Log-Table-Name" = "${GREPTIME_LOG_TABLE_NAME:=demo_logs}",
"X-Greptime-Log-Extract-Keys" = "filename,log.file.name,loki.attribute.labels",
}
auth = otelcol.auth.basic.credentials.handler
}
sending_queue {
queue_size = 10000
num_consumers = 10
}
}
```
- `GREPTIME_HOST`: GreptimeDB 主机地址,例如 `localhost`。
- `GREPTIME_DB`: GreptimeDB 数据库名称,默认是 `public`。
- `GREPTIME_LOG_TABLE_NAME`: 目标日志表名,默认为 `demo_logs`。
- `GREPTIME_USERNAME` 和 `GREPTIME_PASSWORD`: GreptimeDB 的[鉴权认证信息](/user-guide/deployments-administration/authentication/static.md)。
- `X-Greptime-Log-Extract-Keys`: 从 OTLP 日志属性中提取的键。详情请参阅 [OTLP/HTTP API 文档](/user-guide/ingest-data/for-observability/opentelemetry.md#otlphttp-api-1)。
有关从 OpenTelemetry 到 GreptimeDB 的日志数据模型转换的详细信息,请参阅 OpenTelemetry 指南中的[数据模型](/user-guide/ingest-data/for-observability/opentelemetry.md#数据模型-1)部分。
## Loki
GreptimeDB 也支持通过 Loki Push 协议写入日志。
如果你的 Alloy 日志管道本身就是基于 Loki 组件构建的,建议优先使用原生的 Loki 写入路径。
关于 Loki 协议的详细说明和数据模型映射,请参阅 [Loki 指南](/user-guide/ingest-data/for-observability/loki.md)。
### 日志
此示例仅使用 Loki 组件读取、处理并通过 Loki Push API 将日志发送到 GreptimeDB:
```hcl
loki.source.file "greptime" {
targets = [
{__path__ = "/tmp/foo.txt"},
]
forward_to = [loki.process.greptime.receiver]
}
loki.process "greptime" {
forward_to = [loki.write.greptimedb.receiver]
stage.static_labels {
values = {
job = "greptime",
from = "alloy",
}
}
}
loki.write "greptimedb" {
endpoint {
url = "${GREPTIME_SCHEME:=http}://${GREPTIME_HOST:=greptimedb}:${GREPTIME_PORT:=4000}/v1/loki/api/v1/push"
headers = {
"X-Greptime-DB-Name" = "${GREPTIME_DB:=public}",
"X-Greptime-Log-Table-Name" = "${GREPTIME_LOG_TABLE_NAME:=loki_demo_logs}",
}
basic_auth {
username = "${GREPTIME_USERNAME}"
password = "${GREPTIME_PASSWORD}"
}
}
}
```
- `GREPTIME_HOST`: GreptimeDB 主机地址,例如 `localhost`。
- `GREPTIME_DB`: GreptimeDB 数据库名称,默认是 `public`。
- `GREPTIME_LOG_TABLE_NAME`: 目标日志表名,默认为 `loki_demo_logs`。
- `GREPTIME_USERNAME` 和 `GREPTIME_PASSWORD`: GreptimeDB 的[鉴权认证信息](/user-guide/deployments-administration/authentication/static.md)。
该配置会读取 `/tmp/foo.txt`,添加两个静态标签,并通过 `loki.write` 将日志直接发送到 GreptimeDB。
## 批处理
`otelcol.exporter.otlphttp` 默认不会启用批处理。
当 Alloy 读取突发日志时,例如文件或 Docker 容器中的大量历史积压日志,exporter 队列可能会在记录被充分聚合前就被塞满,从而导致 `sending queue is full` 这类错误。
根据生产环境中的测试反馈,仅启用 exporter 内部的 `sending_queue.batch` 配置,对于突发型日志负载仍然可能不够。
在 exporter 前增加 `otelcol.processor.batch` 通常是更可靠的做法,因为这样 exporter 接收到的是较大的批次,而不是大量单条日志记录。
如果你通过 OTLP/HTTP 写入日志,建议按以下顺序组织管道:
1. `loki.source.*`
2. `otelcol.receiver.loki`
3. `otelcol.processor.batch`
4. `otelcol.exporter.otlphttp`
如果你的管道已经是原生 Loki 方案,且不需要 OpenTelemetry 处理链路,建议优先使用 `loki.write` 和 Loki Push 协议。
:::tip 提示
有关 `loki.write`、`otelcol.processor.batch` 和 `otelcol.exporter.otlphttp` 的最新组件行为和调优建议,请参考 Grafana Alloy 官方文档。
:::
---
## Elasticsearch
## 概述
GreptimeDB 支持使用 Elasticsearch 的 [`_bulk` API](https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-bulk.html) 来写入数据。我们会将 Elasticsearch 中的 Index 概念映射为 GreptimeDB 的 Table,同时用户可在 HTTP 请求的 URL 参数中用 `db` 来指定相应的数据库名。**不同于原生 Elasticsearch,该 API 仅支持数据写入,不支持数据的修改和删除**。在实现层面上,GreptimeDB 会将原生 Elasticsearch `_bulk` API 请求中的 `index` 和 `create` 命令都视为**创建操作**。除此之外,GreptimeDB 仅支持解析原生 `_bulk` API 命令请求中的 `_index` 字段而忽略其他字段。
## HTTP API
在大多数日志收集器(比如下文中的 Logstash 和 Filebeat)的配置中,你只需要将 HTTP endpoint 配置为 `http://${db_host}:${db_http_port}/v1/elasticsearch`,比如 `http://localhost:4000/v1/elasticsearch`。
GreptimeDB 支持通过实现以下两个 HTTP endpoint 来实现 Elasticsearch 协议的数据写入:
- **`/v1/elasticsearch/_bulk`**:用户可使用 POST 方法将数据以 NDJSON 格式写入到 GreptimeDB 中。
以下面请求为例,GreptimeDB 将会创建一个名为 `test` 的表,并写入两条数据:
```json
POST /v1/elasticsearch/_bulk
{"create": {"_index": "test", "_id": "1"}}
{"name": "John", "age": 30}
{"create": {"_index": "test", "_id": "2"}}
{"name": "Jane", "age": 25}
```
- **`/v1/elasticsearch/${index}/_bulk`**:用户可使用 POST 方法将数据以 NDJSON 格式写入到 GreptimeDB 中的 `${index}` 表中。如果 POST 请求中也有 `_index` 字段,则 URL 中的 `${index}` 将被忽略。
以下面请求为例,GreptimeDB 将会创建一个名为 `test` 和 `another_index` 的表,并各自写入相应的数据:
```json
POST /v1/elasticsearch/test/_bulk
{"create": {"_id": "1"}}
{"name": "John", "age": 30}
{"create": {"_index": "another_index", "_id": "2"}}
{"name": "Jane", "age": 25}
```
### HTTP Header 参数
- `x-greptime-db-name`:指定写入的数据库名。如不指定,则默认使用 `public` 数据库;
- `x-greptime-pipeline-name`:指定写入的 pipeline 名,如不指定,则默认使用 GreptimeDB 内部的 pipeline `greptime_identity`;
- `x-greptime-pipeline-version`:指定写入的 pipeline 版本,如不指定,则默认对应 pipeline 的最新版本;
更多关于 Pipeline 的详细信息,请参考 [管理 Pipelines](/user-guide/logs/manage-pipelines.md) 文档。
### URL 参数
你可以使用以下 HTTP URL 参数:
- `db`:指定写入的数据库名。如不指定,则默认使用 `public` 数据库;
- `pipeline_name`:指定写入的 pipeline 名,如不指定,则默认使用 GreptimeDB 内部的 pipeline `greptime_identity`;
- `version`:指定写入的 pipeline 版本,如不指定,则默认对应 pipeline 的最新版本;
- `msg_field`:`msg_field` 可指定包含原始日志数据的 JSON 字段名。比如在 Logstash 和 Filebeat 中,该字段通常为 `message`。如果用户指定了该参数,则 GreptimeDB 会尝试将该字段中的数据以 JSON 格式进行展开,如果展开失败,则该字段会被当成字符串进行处理。该配置选项目前仅在 URL 参数中生效。
### 鉴权 Header
关于鉴权 Header 的详细信息,请参考 [Authorization](/user-guide/protocols/http.md#鉴权) 文档。
## 使用方法
### 使用 HTTP API 写入数据
你可以创建一个 `request.json` 文件,其中包含如下内容:
```json
{"create": {"_index": "es_test", "_id": "1"}}
{"name": "John", "age": 30}
{"create": {"_index": "es_test", "_id": "2"}}
{"name": "Jane", "age": 25}
```
然后使用 `curl` 命令将该文件作为请求体发送至 GreptimeDB:
```bash
curl -XPOST http://localhost:4000/v1/elasticsearch/_bulk \
-H "Authorization: Basic {{authentication}}" \
-H "Content-Type: application/json" -d @request.json
```
我们可使用 `mysql` 客户端连接到 GreptimeDB,然后执行如下 SQL 语句来查看写入的数据:
```sql
SELECT * FROM es_test;
```
我们将可以看到如下结果:
```
mysql> SELECT * FROM es_test;
+------+------+----------------------------+
| age | name | greptime_timestamp |
+------+------+----------------------------+
| 30 | John | 2025-01-15 08:26:06.516665 |
| 25 | Jane | 2025-01-15 08:26:06.521510 |
+------+------+----------------------------+
2 rows in set (0.13 sec)
```
### Logstash
如果你正在使用 [Logstash](https://www.elastic.co/logstash) 来收集日志,可使用如下配置来将数据写入到 GreptimeDB:
```
output {
elasticsearch {
hosts => ["http://localhost:4000/v1/elasticsearch"]
index => "my_index"
parameters => {
"pipeline_name" => "my_pipeline"
"msg_field" => "message"
}
}
}
```
请关注以下与 GreptimeDB 相关的配置:
- `hosts`: 指定 GreptimeDB 的 Elasticsearch 协议的 HTTP 地址,即 `http://${db_host}:${db_http_port}/v1/elasticsearch`;
- `index`: 指定写入的表名;
- `parameters`: 指定写入的 URL 参数,上面的例子中指定了 `pipeline_name` 和 `msg_field` 两个参数;
### Filebeat
如果你正在使用 [Filebeat](https://github.com/elastic/beats/tree/main/filebeat) 来收集日志,可使用如下配置来将数据写入到 GreptimeDB:
```
output.elasticsearch:
hosts: ["http://localhost:4000/v1/elasticsearch"]
index: "my_index"
parameters:
pipeline_name: my_pipeline
msg_field: message
```
请关注以下与 GreptimeDB 相关的配置:
- `hosts`: 指定 GreptimeDB 的 Elasticsearch 协议的 HTTP 地址,即 `http://${db_host}:${db_http_port}/v1/elasticsearch`,可根据实际情况进行调整;
- `index`: 指定写入的表名;
- `parameters`: 指定写入的 URL 参数,上面的例子中指定了 `pipeline_name` 和 `msg_field` 两个参数;
### Telegraf
如果你正在使用 [Telegraf](https://github.com/influxdata/telegraf) 来收集日志,你可以使用其 Elasticsearch 插件来将数据写入到 GreptimeDB,如下所示:
```toml
[[outputs.elasticsearch]]
urls = [ "http://localhost:4000/v1/elasticsearch" ]
index_name = "test_table"
health_check_interval = "0s"
enable_sniffer = false
flush_interval = "1s"
manage_template = false
template_name = "telegraf"
overwrite_template = false
namepass = ["tail"]
[outputs.elasticsearch.headers]
"X-GREPTIME-DB-NAME" = "public"
"X-GREPTIME-PIPELINE-NAME" = "greptime_identity"
[[inputs.tail]]
files = ["/tmp/test.log"]
from_beginning = true
data_format = "value"
data_type = "string"
character_encoding = "utf-8"
interval = "1s"
pipe = false
watch_method = "inotify"
```
请关注以下与 GreptimeDB 相关的配置:
- `urls`: 指定 GreptimeDB 的 Elasticsearch 协议的 HTTP 地址,即 `http://${db_host}:${db_http_port}/v1/elasticsearch`;
- `index_name`: 指定写入的表名;
- `outputs.elasticsearch.header`: 指定写入的 HTTP Header,上面的例子中配置了 `X-GREPTIME-DB-NAME` 和 `X-GREPTIME-PIPELINE-NAME` 两个 HTTP Header;
---
## Fluent Bit
[Fluent Bit](http://fluentbit.io/) 是一个快速且轻量级的遥测代理,用于 Linux、macOS、Windows 和 BSD 系列操作系统的日志、指标和跟踪。Fluent Bit 专注于性能,允许从不同来源收集和处理遥测数据而不增加复杂性。
你可以将 Fluent Bit 数据转发到 GreptimeDB。本文档介绍如何配置 Fluent Bit 以将日志、指标和跟踪发送到 GreptimeDB。
## Http
使用 Fluent Bit 的 [HTTP 输出插件](https://docs.fluentbit.io/manual/pipeline/outputs/http),你可以将日志发送到 GreptimeDB。Http 接口目前支持日志的写入。
在配置 Fluent Bit 之前,请确保你已经了解[日志写入流程](/user-guide/logs/overview.md)和[如何使用 pipelines](/user-guide/logs/use-custom-pipelines.md)。
```
[OUTPUT]
Name http
Match *
Host greptimedb
Port 4000
Uri /v1/ingest?db=public&table=your_table&pipeline_name=greptime_identity
Format json
Json_date_key scrape_timestamp
Json_date_format iso8601
compress gzip
http_User
http_Passwd
```
- `uri`: **发送日志的端点。**
- `format`: 日志的格式,需要是 `json`。
- `json_date_key`: JSON 对象中包含时间戳的键。
- `json_date_format`: 时间戳的格式。
- `compress`: 使用的压缩方法,例如 `gzip`。
- `header`: 发送请求时的头部信息,例如用于认证的 `Authorization`。如果没有,不要增加 Authorization 头部。
- `http_user` 和 `http_passwd`: GreptimeDB 的 [认证凭据](/user-guide/deployments-administration/authentication/static.md)。
在 `uri` 参数中:
- `db` 是你要写入日志的数据库名称。
- `table` 是你要写入日志的表名称。
- `pipeline_name` 是你要用于处理日志的管道名称。
## OpenTelemetry
GreptimeDB 也可以配置为 OpenTelemetry 收集器。使用 Fluent Bit 的 [OpenTelemetry 输出插件](https://docs.fluentbit.io/manual/pipeline/outputs/opentelemetry),你可以将指标、日志和跟踪发送到 GreptimeDB。
```
[OUTPUT]
Name opentelemetry
Match *
Host 127.0.0.1
Port 4000
Metrics_uri /v1/otlp/v1/metrics
Logs_uri /v1/otlp/v1/logs
Traces_uri /v1/otlp/v1/traces
Log_response_payload True
Tls Off
Tls.verify Off
```
- `Metrics_uri`, `Logs_uri`, 和 `Traces_uri`: 发送指标、日志和跟踪的端点。
我们建议不要在一个 output 同时写入 metrics log 和 trace,因为我们的写入接口它们各自有一些特殊的 header 选项用于指定一些参数,我们建议一个为 metrics log 和 trace 单独创建一个 opentelemetry output 例如:
```
# Only for metrics
[OUTPUT]
Name opentelemetry
Alias opentelemetry_metrics
Match *
Host 127.0.0.1
Port 4000
Metrics_uri /v1/otlp/v1/metrics
Log_response_payload True
Tls Off
Tls.verify Off
# Only for logs
[OUTPUT]
Name opentelemetry
Alias opentelemetry_logs
Match *
Host 127.0.0.1
Port 4000
Logs_uri /v1/otlp/v1/logs
Log_response_payload True
Tls Off
Tls.verify Off
Header X-Greptime-Log-Table-Name ""
Header X-Greptime-Log-Pipeline-Name ""
Header X-Greptime-DB-Name ""
```
本示例中,使用的是 [OpenTelemetry OTLP/HTTP API](/user-guide/ingest-data/for-observability/opentelemetry.md#opentelemetry-collectors) 接口。如需更多信息,请参阅 [OpenTelemetry](/user-guide/ingest-data/for-observability/opentelemetry.md) 文档。
## Prometheus Remote Write
将 GreptimeDB 配置为远程写入目标:
```
[OUTPUT]
Name prometheus_remote_write
Match internal_metrics
Host 127.0.0.1
Port 4000
Uri /v1/prometheus/write?db=
Tls Off
http_user
http_passwd
```
- `Uri`: 发送指标的端点。
- `http_user` 和 `http_passwd`: GreptimeDB 的 [认证凭据](/user-guide/deployments-administration/authentication/static.md)。
在 `Uri` 参数中:
- `db` 是你要写入指标的数据库名称。
有关从 Prometheus 到 GreptimeDB 的数据模型转换的详细信息,请参阅 Prometheus Remote Write 指南中的[数据模型](/user-guide/ingest-data/for-observability/prometheus.md#data-model)部分。
---
## InfluxDB Line Protocol(For-observability)
请参考 [InfluxDB Line Protocol 文档](../for-iot/influxdb-line-protocol.md) 了解如何使用 InfluxDB Line Protocol 将数据写入到 GreptimeDB。
---
## Kafka(For-observability)
如果你使用 Kafka 或兼容 Kafka 的消息队列进行可观测性数据传输,可以直接将数据写入到 GreptimeDB 中。
这里我们使用 Vector 作为工具将数据从 Kafka 传输到 GreptimeDB。
## 指标
从 Kafka 写入指标到 GreptimeDB 时,消息应采用 InfluxDB 行协议格式。例如:
```txt
census,location=klamath,scientist=anderson bees=23 1566086400000000000
```
然后配置 Vector 使用 `influxdb` 解码器来处理这些消息。
```toml
[sources.metrics_mq]
# 指定源类型为 Kafka
type = "kafka"
# Kafka 的消费者组 ID
group_id = "vector0"
# 要消费消息的 Kafka 主题列表
topics = ["test_metric_topic"]
# 要连接的 Kafka 地址
bootstrap_servers = "kafka:9092"
# `influxdb` 表示消息应采用 InfluxDB 行协议格式
decoding.codec = "influxdb"
[sinks.metrics_in]
inputs = ["metrics_mq"]
# 指定接收器类型为 `greptimedb_metrics`
type = "greptimedb_metrics"
# GreptimeDB 服务器的端点
# 将 替换为实际的主机名或 IP 地址
endpoint = ":4001"
dbname = ""
username = ""
password = ""
tls = {}
```
有关 InfluxDB 行协议指标如何映射到 GreptimeDB 数据的详细信息,请参阅 InfluxDB 行协议文档中的[数据模型](/user-guide/ingest-data/for-iot/influxdb-line-protocol.md#数据模型)部分。
## 日志
开发人员通常处理两种类型的日志:JSON 日志和纯文本日志。
例如以下从 Kafka 发送的日志示例。
纯文本日志:
```txt
127.0.0.1 - - [25/May/2024:20:16:37 +0000] "GET /index.html HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
```
或 JSON 日志:
```json
{
"timestamp": "2024-12-23T10:00:00Z",
"level": "INFO",
"message": "Service started"
}
```
GreptimeDB 将这些日志转换为具有多个列的结构化数据,并自动创建必要的表。
Pipeline 在写入到 GreptimeDB 之前将日志处理为结构化数据。
不同的日志格式需要不同的 [Pipeline](/user-guide/logs/quick-start.md#write-logs-by-pipeline) 来解析,详情请继续阅读下面的内容。
### JSON 格式的日志
对于 JSON 格式的日志(例如 `{"timestamp": "2024-12-23T10:00:00Z", "level": "INFO", "message": "Service started"}`),
你可以使用内置的 [`greptime_identity`](/user-guide/logs/manage-pipelines.md#greptime_identity) pipeline 直接写入日志。
此 pipeline 根据 JSON 日志消息中的字段自动创建列。
你只需要配置 Vector 的 `transforms` 设置以解析 JSON 消息,并使用 `greptime_identity` pipeline,如以下示例所示:
```toml
[sources.logs_in]
type = "kafka"
# Kafka 的消费者组 ID
group_id = "vector0"
# 要消费消息的 Kafka 主题列表
topics = ["test_log_topic"]
# 要连接的 Kafka 代理地址
bootstrap_servers = "kafka:9092"
# 将日志转换为 JSON 格式
[transforms.logs_json]
type = "remap"
inputs = ["logs_in"]
source = '''
. = parse_json!(.message)
'''
[sinks.logs_out]
# 指定此接收器将接收来自 `logs_json` 源的数据
inputs = ["logs_json"]
# 指定接收器类型为 `greptimedb_logs`
type = "greptimedb_logs"
# GreptimeDB 服务器的端点
endpoint = "http://:4000"
compression = "gzip"
# 将 、 和 替换为实际值
dbname = ""
username = ""
password = ""
# GreptimeDB 中的表名,如果不存在,将自动创建
table = "demo_logs"
# 使用内置的 `greptime_identity` 管道
pipeline_name = "greptime_identity"
```
### 文本格式的日志
对于文本格式的日志,例如下面的访问日志格式,你需要创建自定义 pipeline 来解析它们:
```
127.0.0.1 - - [25/May/2024:20:16:37 +0000] "GET /index.html HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
```
#### 创建 pipeline
要创建自定义 pipeline,
请参阅[使用自定义 pipeline](/user-guide/logs/use-custom-pipelines.md)文档获取详细说明。
#### 写入数据
创建 pipeline 后,将其配置到 Vector 配置文件中的 `pipeline_name` 字段。
```toml
# sample.toml
[sources.log_mq]
# 指定源类型为 Kafka
type = "kafka"
# Kafka 的消费者组 ID
group_id = "vector0"
# 要消费消息的 Kafka 主题列表
topics = ["test_log_topic"]
# 要连接的 Kafka 地址
bootstrap_servers = "kafka:9092"
[sinks.sink_greptime_logs]
# 指定接收器类型为 `greptimedb_logs`
type = "greptimedb_logs"
# 指定此接收器将接收来自 `log_mq` 源的数据
inputs = [ "log_mq" ]
# 使用 `gzip` 压缩以节省带宽
compression = "gzip"
# GreptimeDB 服务器的端点
# 将 替换为实际的主机名或 IP 地址
endpoint = "http://:4000"
dbname = ""
username = ""
password = ""
# GreptimeDB 中的表名,如果不存在,将自动创建
table = "demo_logs"
# 你创建的自定义管道名称
pipeline_name = "your_custom_pipeline"
```
## Demo
有关数据转换和写入的可运行演示,请参阅 [Kafka Ingestion Demo](https://github.com/GreptimeTeam/demo-scene/tree/main/kafka-ingestion)。
---
## Loki
## 使用方法
### API
要通过原始 HTTP API 将日志发送到 GreptimeDB,请使用以下信息:
* **URL**: `http{s}:///v1/loki/api/v1/push`
* **Headers**:
* `X-Greptime-DB-Name`: ``
* `Authorization`: `Basic` 认证,这是一个 Base64 编码的 `:` 字符串。更多信息,请参考 [认证](https://docs.greptime.com/user-guide/deployments-administration/authentication/static/) 和 [HTTP API](https://docs.greptime.com/user-guide/protocols/http#authentication)。
* `X-Greptime-Log-Table-Name`: ``(可选)- 存储日志的表名。如果未提供,默认表名为 `loki_logs`。
请求使用二进制 protobuf 编码负载。定义的格式与 [logproto.proto](https://github.com/grafana/loki/blob/main/pkg/logproto/logproto.proto) 相同。
### 示例代码
[Grafana Alloy](https://grafana.com/docs/alloy/latest/) 是一个供应商中立的 OpenTelemetry (OTel) Collector 发行版。Alloy 独特地结合了社区中最好的开源可观测性信号。
它提供了一个 Loki 导出器,可以用来将日志发送到 GreptimeDB。以下是一个配置示例:
```
loki.source.file "greptime" {
targets = [
{__path__ = "/tmp/foo.txt"},
]
forward_to = [loki.write.greptime_loki.receiver]
}
loki.write "greptime_loki" {
endpoint {
url = "${GREPTIME_SCHEME:=http}://${GREPTIME_HOST:=greptimedb}:${GREPTIME_PORT:=4000}/v1/loki/api/v1/push"
headers = {
"x-greptime-db-name" = "${GREPTIME_DB:=public}",
"x-greptime-log-table-name" = "${GREPTIME_LOG_TABLE_NAME:=loki_demo_logs}",
}
}
external_labels = {
"job" = "greptime",
"from" = "alloy",
}
}
```
此配置从文件 `/tmp/foo.txt` 读取日志并将其发送到 GreptimeDB。日志存储在表 `loki_demo_logs` 中,并带有 label `job` 和 `from`。
更多信息,请参考 [Grafana Alloy loki.write 文档](https://grafana.com/docs/alloy/latest/reference/components/loki/loki.write/)。
你可以运行以下命令来检查表中的数据:
```sql
SELECT * FROM loki_demo_logs;
+----------------------------+------------------------+--------------+-------+----------+
| greptime_timestamp | line | filename | from | job |
+----------------------------+------------------------+--------------+-------+----------+
| 2024-11-25 11:02:31.256251 | Greptime is very cool! | /tmp/foo.txt | alloy | greptime |
+----------------------------+------------------------+--------------+-------+----------+
1 row in set (0.01 sec)
```
## 数据模型
Loki 日志数据模型根据以下规则映射到 GreptimeDB 数据模型:
**没有 label 的默认表结构:**
```sql
DESC loki_demo_logs;
+---------------------+---------------------+------+------+---------+---------------+
| Column | Type | Key | Null | Default | Semantic Type |
+---------------------+---------------------+------+------+---------+---------------+
| greptime_timestamp | TimestampNanosecond | PRI | NO | | TIMESTAMP |
| line | String | | YES | | FIELD |
| structured_metadata | Json | | YES | | FIELD |
+---------------------+---------------------+------+------+---------+---------------+
3 rows in set (0.00 sec)
```
- `greptime_timestamp`: 日志条目的时间戳
- `line`: 日志消息内容
- `structured_metadata`: 日志条目的结构化元数据,JSON 格式
如果 Loki 请求数据中含有 label,它们将作为 tag 添加到表结构中(如上例中的 `job` 和 `from`)。
**重要说明:**
- 所有 label 都被视为字符串类型的 tag
- 请不要尝试使用 SQL 预先创建表来指定 tag 列,这会导致类型不匹配和写入失败
### 表结构示例
以下是带有 label 的表结构示例:
```sql
DESC loki_demo_logs;
+---------------------+---------------------+------+------+---------+---------------+
| Column | Type | Key | Null | Default | Semantic Type |
+---------------------+---------------------+------+------+---------+---------------+
| greptime_timestamp | TimestampNanosecond | PRI | NO | | TIMESTAMP |
| line | String | | YES | | FIELD |
| structured_metadata | Json | | YES | | FIELD |
| filename | String | PRI | YES | | TAG |
| from | String | PRI | YES | | TAG |
| job | String | PRI | YES | | TAG |
+---------------------+---------------------+------+------+---------+---------------+
6 rows in set (0.00 sec)
```
```sql
SHOW CREATE TABLE loki_demo_logs\G
*************************** 1. row ***************************
Table: loki_demo_logs
Create Table: CREATE TABLE IF NOT EXISTS `loki_demo_logs` (
`greptime_timestamp` TIMESTAMP(9) NOT NULL,
`line` STRING NULL,
`filename` STRING NULL,
`from` STRING NULL,
`job` STRING NULL,
TIME INDEX (`greptime_timestamp`),
PRIMARY KEY (`filename`, `from`, `job`)
)
ENGINE=mito
WITH(
append_mode = 'true'
)
1 row in set (0.00 sec)
```
## 在 Loki Push API 中使用 pipeline
:::warning 实验性特性
此实验性功能可能存在预期外的行为,其功能未来可能发生变化。
:::
从 `v0.15` 版本开始,GreptimeDB 支持使用 pipeline 来处理 Loki Push 请求。
你可以简单地设置 HTTP 头 `x-greptime-pipeline-name` 为目标 pipeline 名称来启用 pipeline 处理。
**注意:** 当请求数据通过 pipeline 引擎时,GreptimeDB 会为 label 和元数据列名添加前缀:
- 每个 label 名前添加 `loki_label_` 前缀
- 每个结构化元数据名前添加 `loki_metadata_` 前缀
- 原始的 Loki 日志行被命名为 `loki_line`
### Pipeline 示例
以下是一个完整的示例,演示如何在 Loki Push API 中使用 Pipeline。
**步骤 1:准备日志文件**
假设我们有一个名为 `logs.json` 的日志文件,包含 JSON 格式的日志条目:
```json
{"timestamp":"2025-08-21 14:23:17.892","logger":"sdk.tool.DatabaseUtil","level":"ERROR","message":"Connection timeout exceeded for database pool","trace_id":"a7f8c92d1e4b4c6f9d2e5a8b3f7c1d9e","source":"application"}
{"timestamp":"2025-08-21 14:23:18.156","logger":"core.scheduler.TaskManager","level":"WARN","message":"Task queue capacity reached 85% threshold","trace_id":"b3e9f4a6c8d2e5f7a1b4c7d9e2f5a8b3","source":"scheduler"}
{"timestamp":"2025-08-21 14:23:18.423","logger":"sdk.tool.NetworkUtil","level":"INFO","message":"Successfully established connection to remote endpoint","trace_id":"c5d8e7f2a9b4c6d8e1f4a7b9c2e5f8d1","source":"network"}
```
每一行都是一个独立的 JSON 对象,包含日志信息。
**步骤 2:创建 Pipeline 配置**
以下是解析 JSON 日志条目的 pipeline 配置:
```yaml
# pipeline.yaml
version: 2
processors:
- vrl:
source: |
message = parse_json!(.loki_line)
target = {
"log_time": parse_timestamp!(message.timestamp, "%Y-%m-%d %T%.3f"),
"log_level": message.level,
"log_source": message.source,
"logger": message.logger,
"message": message.message,
"trace_id": message.trace_id,
}
. = target
transform:
- field: log_time
type: time, ms
index: timestamp
```
pipeline 的配置相对直观: 使用 `vrl` 处理器将日志行解析为 JSON 对象,然后将其中的字段提取到根目录。
`log_time` 在 transform 部分中被指定为时间索引,其他字段将由 pipeline 引擎自动推导,详见 [pipeline version 2](/reference/pipeline/pipeline-config.md#版本-2-中的-transform)。
请注意,输入字段名为 `loki_line`,它包含来自 Loki 的原始日志行。
**步骤 3:配置 Grafana Alloy**
准备一个 Alloy 配置文件来读取日志文件并将其发送到 GreptimeDB:
```
loki.source.file "greptime" {
targets = [
{__path__ = "/logs.json"},
]
forward_to = [loki.write.greptime_loki.receiver]
}
loki.write "greptime_loki" {
endpoint {
url = "http://127.0.0.1:4000/v1/loki/api/v1/push"
headers = {
"x-greptime-pipeline-name" = "pp",
}
}
external_labels = {
"job" = "greptime",
"from" = "alloy",
}
}
```
在 `greptime_loki` 中,通过 `x-greptime-pipeline-name` 的 HTTP 头来指示写入的数据需要被 pipeline 引擎处理。
**步骤 4:部署和运行**
1. 首先,启动你的 GreptimeDB 实例。参见[这里](/getting-started/installation/overview.md)快速启动。
2. [上传](/user-guide/logs/manage-pipelines.md#create-a-pipeline) pipeline 配置到数据库:
```bash
curl -X "POST" "http://localhost:4000/v1/pipelines/pp" -F "file=@pipeline.yaml"
```
3. 启动 Alloy Docker 容器来处理日志:
```shell
docker run --rm \
-v ./config.alloy:/etc/alloy/config.alloy \
-v ./logs.json:/logs.json \
--network host \
grafana/alloy:latest \
run --server.http.listen-addr=0.0.0.0:12345 --storage.path=/var/lib/alloy/data \
/etc/alloy/config.alloy
```
**步骤 5:验证结果**
日志处理完成后,您可以验证它们是否已成功摄取和解析。数据库日志将显示摄取活动。
使用 MySQL 客户端查询表以查看解析的日志数据:
```sql
mysql> show tables;
+-----------+
| Tables |
+-----------+
| loki_logs |
| numbers |
+-----------+
2 rows in set (0.00 sec)
mysql> select * from loki_logs limit 1 \G
*************************** 1. row ***************************
log_time: 2025-08-21 14:23:17.892000
log_level: ERROR
log_source: application
logger: sdk.tool.DatabaseUtil
message: Connection timeout exceeded for database pool
trace_id: a7f8c92d1e4b4c6f9d2e5a8b3f7c1d9e
1 row in set (0.01 sec)
```
此输出演示了 pipeline 引擎已成功解析原始 JSON 日志行,并将结构化数据提取到单独的列中。
有关 pipeline 配置和功能的更多详细信息,请参考[pipeline 文档](/reference/pipeline/pipeline-config.md)。
---
## OpenTelemetry Protocol (OTLP)
[OpenTelemetry](https://opentelemetry.io/) 是一个供应商中立的开源可观测性框架,用于检测、生成、收集和导出观测数据,例如 traces, metrics 和 logs。
OpenTelemetry Protocol (OTLP) 定义了观测数据在观测源和中间进程(例如收集器和观测后端)之间的编码、传输机制。
## OpenTelemetry Collectors
你可以很简单地将 GreptimeDB 配置为 OpenTelemetry 采集器写入的目标。
有关更多信息,请参阅 [OTel Collector](otel-collector.md) 和[Grafana Alloy](alloy.md) 示例。
## HTTP 基础端点
适用于所有信号类型的[HTTP 基础端点](https://opentelemetry.io/docs/languages/sdk-configuration/otlp-exporter/#otel_exporter_otlp_endpoint) URL:`http{s}:///v1/otlp`
当需要将多种信号类型(指标、日志和链路追踪)发送到同一目标数据库时,这个统一端点非常有用,可以简化你的 OpenTelemetry 配置。
## Metrics
GreptimeDB 通过原生支持 [OTLP/HTTP](https://opentelemetry.io/docs/specs/otlp/#otlphttp) 协议,可以作为后端存储服务来接收 OpenTelemetry 指标数据。
### OTLP/HTTP API
使用下面的信息通过 Opentelemetry SDK 库发送 Metrics 到 GreptimeDB:
- URL: `https:///v1/otlp/v1/metrics`
- Headers:
- `X-Greptime-DB-Name`: ``
- `Authorization`: `Basic` 认证,是 `:` 的 Base64 编码字符串。更多信息请参考 [鉴权](https://docs.greptime.cn/user-guide/deployments-administration/authentication/static/) 和 [HTTP API](https://docs.greptime.cn/user-guide/protocols/http#authentication)。
请求中使用 binary protobuf 编码 payload,因此你需要使用支持 `HTTP/protobuf` 的包。例如,在 Node.js 中,可以使用 [`exporter-trace-otlp-proto`](https://www.npmjs.com/package/@opentelemetry/exporter-trace-otlp-proto);在 Go 中,可以使用 [`go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracehttp`](https://pkg.go.dev/go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracehttp);在 Java 中,可以使用 [`io.opentelemetry:opentelemetry-exporter-otlp`](https://mvnrepository.com/artifact/io.opentelemetry/opentelemetry-exporter-otlp);在 Python 中,可以使用 [`opentelemetry-exporter-otlp-proto-http`](https://pypi.org/project/opentelemetry-exporter-otlp-proto-http/)。
:::tip 注意
包名可能会根据 OpenTelemetry 的发展发生变化,因此建议你参考 OpenTelemetry 官方文档以获取最新信息。
:::
请参考 Opentelementry 的官方文档获取它所支持的编程语言的更多信息。
### 示例代码
下面是一些编程语言设置请求的示例代码:
```ts
const auth = Buffer.from(`${username}:${password}`).toString('base64')
const exporter = new OTLPMetricExporter({
url: `https://${dbHost}/v1/otlp/v1/metrics`,
headers: {
Authorization: `Basic ${auth}`,
'X-Greptime-DB-Name': db,
},
timeoutMillis: 5000,
})
```
```Go
auth := base64.StdEncoding.EncodeToString([]byte(fmt.Sprintf("%s:%s", *username, *password)))
exporter, err := otlpmetrichttp.New(
context.Background(),
otlpmetrichttp.WithEndpoint(*dbHost),
otlpmetrichttp.WithURLPath("/v1/otlp/v1/metrics"),
otlpmetrichttp.WithHeaders(map[string]string{
"X-Greptime-DB-Name": *dbName,
"Authorization": "Basic " + auth,
}),
otlpmetrichttp.WithTimeout(time.Second*5),
)
```
```Java
String endpoint = String.format("https://%s/v1/otlp/v1/metrics", dbHost);
String auth = username + ":" + password;
String b64Auth = new String(Base64.getEncoder().encode(auth.getBytes()));
OtlpHttpMetricExporter exporter = OtlpHttpMetricExporter.builder()
.setEndpoint(endpoint)
.addHeader("X-Greptime-DB-Name", db)
.addHeader("Authorization", String.format("Basic %s", b64Auth))
.setTimeout(Duration.ofSeconds(5))
.build();
```
```python
auth = f"{username}:{password}"
b64_auth = base64.b64encode(auth.encode()).decode("ascii")
endpoint = f"https://{host}/v1/otlp/v1/metrics"
exporter = OTLPMetricExporter(
endpoint=endpoint,
headers={"Authorization": f"Basic {b64_auth}", "X-Greptime-DB-Name": db},
timeout=5)
```
关于示例代码,请参考 Opentelementry 的官方文档获取它所支持的编程语言获取更多信息。
### 兼容 Prometheus
从 `v0.16` 开始,GreptimeDB 为 OTLP 指标写入引入了一种 Prometheus 兼容模式。
如果指标以这种兼容模式写入,你可以像查询 Prometheus 原生指标一样使用 PromQL 直接查询这些指标。
如果你之前没有使用过 OTLP 指标写入,那么 GreptimeDB 会默认使用新的兼容模式。
否则,GreptimeDB 会对已经存在的表保留原有的数据模型,只有对新创建的指标表使用兼容模式写入。
GreptimeDB 会首先对数据进行预处理,包括:
1. 将指标名(表名)和标签名转换成 Prometheus 风格的命名(例如:将 `.` 替换为 `_`)。具体信息请参考[这里](https://opentelemetry.io/docs/specs/otel/compatibility/prometheus_and_openmetrics/#metric-metadata-1)
以下是一些转换示例:
| OTLP 指标 / 属性 | OTLP 类型 / 单位 | Prometheus 等效名称 |
| :--- | :--- | :--- |
| `cache.hit_ratio` | Gauge / `1` | `cache_hit_ratio` |
| `memory.usage` | Gauge / `By` | `memory_usage_bytes` |
| `queue.length` | Gauge / `{item}` | `queue_length` |
| `http.server.request.duration` | Histogram / `s` | `http_server_request_duration_seconds` |
| `rpc.server.duration` | Histogram / `ms` | `rpc_server_duration_seconds` |
| `http.client.request.size` | Sum (Monotonic) / `By` | `http_client_request_size_bytes_total` |
| `system.network.io` | Sum (Monotonic) / `By` | `system_network_io_bytes_total` |
| `http.status_code` (属性) | - | `http_status_code` |
| `service.name` (属性) | - | `service_name` |
2. 默认丢弃一些 resource 属性和全部的 scope 属性。默认保存的 resource 属性列表可以参考[这里](https://prometheus.io/docs/guides/opentelemetry/#promoting-resource-attributes)。你可以通过配置项对这个行为进行调整
注意: OTLP 的 `Sum` 和 `Histogram` 指标的数据可能是增量时序(delta temporality)类型的。
GreptimeDB 将会直接保存它们,不会进行累计值(cumulative value)的计算。
参考[这里](https://grafana.com/blog/2023/09/26/opentelemetry-metrics-a-guide-to-delta-vs.-cumulative-temporality-trade-offs/)获取更多背景信息。
你可以通过设置 HTTP 请求头来调整预处理的行为。以下是选项列表:
1. `x-greptime-otlp-metric-promote-all-resource-attrs`: 保存所有 resource 资源。默认是 `false`。
2. `x-greptime-otlp-metric-promote-resource-attrs`: 如果不保存所有 resource 资源,需要保存的资源名称列表,用 `;` 连接。
3. `x-greptime-otlp-metric-ignore-resource-attrs`: 如果保存所有的 resource 资源,需要丢弃的资源名称列表,用 `;` 连接。
4. `x-greptime-otlp-metric-promote-scope-attrs`: 是否需要保存 scope 资源。默认是 `false`。
### 数据模型
兼容 Prometheus 的 OTLP 指标数据模型按照下方的规则被映射到 GreptimeDB 数据模型中:
- Metric 的名称将被作为 GreptimeDB 表的名称,当表不存在时会自动创建。
- 只有特定 resource 属性会被默认保留。详情和配置选项见上一小节。属性在 GreptimeDB 表中会被作为 tag 列。
- 参考 [Prometheus 数据模型](./prometheus.md#数据模型)了解更多数据模型信息。
- ExponentialHistogram 暂时未被支持。
如果你在 `v0.16` 之前使用 OTLP 指标,那么数据将以非兼容模式保存。以下是数据模型在映射上的差别:
- 所有的 Attribute,包含 resource 级别、scope 级别和 data_point 级别,都被作为 GreptimeDB 表的 tag 列。
- Summary 类型的每个 quantile 被作为单独的数据列,列名 `greptime_pxx`,其中 xx 是 quantile 的数据,如 90 / 99 等。
## Logs
GreptimeDB 是能够通过 [OTLP/HTTP](https://opentelemetry.io/docs/specs/otlp/#otlphttp) 协议原生地消费 OpenTelemetry 日志。
### OTLP/HTTP API
要通过 OpenTelemetry SDK 库将 OpenTelemetry 日志发送到 GreptimeDB,请使用以下信息:
- **URL:** `https:///v1/otlp/v1/logs`
- **Headers:**
- `X-Greptime-DB-Name`: ``
- `Authorization`: `Basic` 认证,这是一个 Base64 编码的 `:` 字符串。更多信息,请参考 [鉴权](/user-guide/deployments-administration/authentication/static.md) 和 [HTTP API](/user-guide/protocols/http.md#鉴权)。
- `X-Greptime-Log-Table-Name`: ``(可选)- 存储日志的表名。如果未提供,默认表名为 `opentelemetry_logs`。
- `X-Greptime-Log-Extract-Keys`: ``(可选)- 从属性中提取对应 key 的值到表的顶级字段。key 应以逗号(`,`)分隔。例如,`key1,key2,key3` 将从属性中提取 `key1`、`key2` 和 `key3`,并将它们提升到日志的顶层,设置为标签。如果提取的字段类型是数组、浮点数或对象,将返回错误。如果提供了 pipeline name,此设置将被忽略。
- `X-Greptime-Log-Pipeline-Name`: ``(可选)- 处理日志的 pipeline 名称。如果未提供,将使用 `X-Greptime-Log-Extract-Keys` 来处理日志。
- `X-Greptime-Log-Pipeline-Version`: ``(可选)- 处理日志的 pipeline 的版本。如果未提供,将使用 pipeline 的最新版本。
请求使用二进制 protobuf 编码负载,因此您需要使用支持 `HTTP/protobuf` 的包。
:::tip 提示
包名可能会根据 OpenTelemetry 的更新而变化,因此我们建议您参考官方 OpenTelemetry 文档以获取最新信息。
:::
有关 OpenTelemetry SDK 的更多信息,请参考您首选编程语言的官方文档。
### 示例代码
请参考 [OpenTelemetry Collector 文档](otel-collector.md)中的示例代码,里面包含了如何将 OpenTelemetry 日志发送到 GreptimeDB。
也可参考 [Alloy 文档](alloy.md#日志)中的示例代码,了解如何将 OpenTelemetry 日志发送到 GreptimeDB。
### 数据模型
OTLP 日志数据模型根据以下规则映射到 GreptimeDB 数据模型:
默认表结构:
```sql
+-----------------------+---------------------+------+------+---------+---------------+
| Column | Type | Key | Null | Default | Semantic Type |
+-----------------------+---------------------+------+------+---------+---------------+
| timestamp | TimestampNanosecond | PRI | NO | | TIMESTAMP |
| trace_id | String | | YES | | FIELD |
| span_id | String | | YES | | FIELD |
| severity_text | String | | YES | | FIELD |
| severity_number | Int32 | | YES | | FIELD |
| body | String | | YES | | FIELD |
| log_attributes | Json | | YES | | FIELD |
| trace_flags | UInt32 | | YES | | FIELD |
| scope_name | String | PRI | YES | | TAG |
| scope_version | String | | YES | | FIELD |
| scope_attributes | Json | | YES | | FIELD |
| scope_schema_url | String | | YES | | FIELD |
| resource_attributes | Json | | YES | | FIELD |
| resource_schema_url | String | | YES | | FIELD |
+-----------------------+---------------------+------+------+---------+---------------+
14 rows in set (0.00 sec)
```
- 您可以使用 `X-Greptime-Log-Table-Name` 指定存储日志的表名。如果未提供,默认表名为 `opentelemetry_logs`。
- 所有属性,包括资源属性、范围属性和日志属性,将作为 JSON 列存储在 GreptimeDB 表中。
- 日志的时间戳将用作 GreptimeDB 中的时间戳索引,列名为 `timestamp`。建议使用 `time_unix_nano` 作为时间戳列。如果未提供 `time_unix_nano`,将使用 `observed_time_unix_nano`。
### Append-only 模式
通过此接口创建的表,默认为[Append-only 模式](/user-guide/deployments-administration/performance-tuning/design-table.md#何时使用-append-only-表)。
## Traces
GreptimeDB 支持直接写入 OpenTelemetry 协议的 traces 数据,并内置 OpenTelemetry 的 traces 的表模型来让用户方便地查询和分析 traces 数据。
### OTLP/HTTP API
你可以使用 [OpenTelemetry SDK](https://opentelemetry.io/docs/languages/) 或其他类似的技术方案来为应用添加 traces 数据。你还可以用 [OpenTelemetry Collector](https://opentelemetry.io/docs/collector/) 来收集 traces 数据,并使用 GreptimeDB 作为后端存储。
要通过 OpenTelemetry SDK 库将 OpenTelemetry 的 traces 数据发送到 GreptimeDB,请使用以下信息:
- URL: `http{s}:///v1/otlp/v1/traces`
- Headers:
- `Content-Type`: 应配置为 `application/x-protobuf`
- `Authorization`: `Basic` 认证。
- `X-Greptime-DB-Name`: ``
- `X-Greptime-Trace-Table-Name`: ``(可选)- 存储 traces 的表名。如果未提供,默认表名为 `opentelemetry_traces`。
- `X-Greptime-Pipeline-Name`: `greptime_trace_v1`(必选)- 处理 traces 的 pipeline 名称。
GreptimeDB 会通过 **HTTP 协议** 接受 **protobuf 编码的 traces 数据**。
### 示例代码
你可以直接将 OpenTelemetry traces 数据发送到 GreptimeDB,也可以使用 OpenTelemetry Collector 来收集 traces 数据,并使用 GreptimeDB 作为后端存储,请参考 [OpenTelemetry Collector 文档](/user-guide/traces/read-write.md#opentelemetry-collector)中的示例代码,了解如何将 OpenTelemetry traces 数据发送到 GreptimeDB。
### 数据模型
GreptimeDB 将 OTLP traces 数据模型映射到表结构。默认情况下,Trace 数据存储在 `opentelemetry_traces` 表中。
```sql
+------------------------------------+---------------------+------+------+---------+---------------+
| Column | Type | Key | Null | Default | Semantic Type |
+------------------------------------+---------------------+------+------+---------+---------------+
| timestamp | TimestampNanosecond | PRI | NO | | TIMESTAMP |
| timestamp_end | TimestampNanosecond | | YES | | FIELD |
| duration_nano | UInt64 | | YES | | FIELD |
| parent_span_id | String | | YES | | FIELD |
| trace_id | String | | YES | | FIELD |
| span_id | String | | YES | | FIELD |
| span_kind | String | | YES | | FIELD |
| span_name | String | | YES | | FIELD |
| span_status_code | String | | YES | | FIELD |
| span_status_message | String | | YES | | FIELD |
| trace_state | String | | YES | | FIELD |
| scope_name | String | | YES | | FIELD |
| scope_version | String | | YES | | FIELD |
| service_name | String | PRI | YES | | TAG |
| span_attributes.net.sock.peer.addr | String | | YES | | FIELD |
| span_attributes.peer.service | String | | YES | | FIELD |
| span_events | Json | | YES | | FIELD |
| span_links | Json | | YES | | FIELD |
+------------------------------------+---------------------+------+------+---------+---------------+
```
- 每一行代表一个单一的 span。
- `service_name` 用作 **Tag**(**主键**的一部分)。
- `timestamp` 用作 **时间索引**(Time Index)。
- Resource Attributes 和 Span Attributes 将被自动展平为单独的列。
- 注意:`resource_attributes.service.name` 被排除在打平之外,因为它已经存储在 `service_name` 列中。
- `span_events` 和 `span_links` 默认存储为 `JSON` 数据类型。
有关数据模型和辅助表的更多详细信息,请参阅 [Trace 数据模型](/user-guide/traces/data-model.md)。
注意:
1. `greptime_trace_v1` 处理方式默认通过 `trace_id` 字段将数据切分成不同的分区以提升性能。**请确保 `trace_id` 的第一个字符是分布均匀的**。
2. 在非测试的场合下,可以通过设置 `ttl` 以避免持久化数据量过大。通过设置 `x-greptime-hints: ttl=7d` HTTP 请求头,在创建 trace 表时会添加一个 7 天的 `ttl` 表选项。见[此文档](/reference/sql/create.md#表选项)了解更多关于表选项 `ttl` 的信息。
### 辅助表
GreptimeDB 会自动创建辅助表(例如 `opentelemetry_traces_services` 和 `opentelemetry_traces_operations`),以便于搜索服务和操作。详情请参阅[辅助表](/user-guide/traces/data-model.md#辅助表)。
### Append-only 模式
通过此接口创建的表,默认为[Append-only 模式](/user-guide/deployments-administration/performance-tuning/design-table.md#何时使用-append-only-表)。
---
## OTel Collector
[OpenTelemetry Collector](https://opentelemetry.io/docs/collector/) 提供了一种与供应商无关的 OTEL 实现,用于接收、处理和导出可观测数据。它可以作为数据的中间层,将数据从不同的源发送到 GreptimeDB。
以下是使用 OpenTelemetry Collector 将数据发送到 GreptimeDB 的配置示例。
```yaml
extensions:
basicauth/client:
client_auth:
username:
password:
receivers:
otlp:
protocols:
grpc:
endpoint: 0.0.0.0:4317
http:
endpoint: 0.0.0.0:4318
exporters:
otlphttp/traces:
endpoint: 'http://127.0.0.1:4000/v1/otlp'
# auth:
# authenticator: basicauth/client
headers:
# x-greptime-db-name: ''
x-greptime-pipeline-name: 'greptime_trace_v1'
tls:
insecure: true
otlphttp/logs:
endpoint: 'http://127.0.0.1:4000/v1/otlp'
# auth:
# authenticator: basicauth/client
headers:
# x-greptime-db-name: ''
# x-greptime-log-table-name: ''
# x-greptime-pipeline-name: ''
tls:
insecure: true
otlphttp/metrics:
endpoint: 'http://127.0.0.1:4000/v1/otlp'
# auth:
# authenticator: basicauth/client
headers:
# x-greptime-db-name: ''
tls:
insecure: true
service:
# extensions: [basicauth/client]
pipelines:
traces:
receivers: [otlp]
exporters: [otlphttp/traces]
logs:
receivers: [otlp]
exporters: [otlphttp/logs]
metrics:
receivers: [otlp]
exporters: [otlphttp/metrics]
```
在上面的配置中,我们定义了一个接收器 `otlp`,它可以接收来自 OpenTelemetry 的数据。我们还定义了三个导出器 `otlphttp/traces`、`otlphttp/logs` 和 `otlphttp/metrics`,它们将数据发送到 GreptimeDB 的 OTLP 路径。
在 otlphttp 协议的基础上,我们增加了一些 header 用来指定一些参数,比如 `x-greptime-pipeline-name` 和 `x-greptime-log-table-name`:
* `x-greptime-pipeline-name` 用来指定要使用的 pipeline 名称
* `x-greptime-log-table-name` 用来指定数据将要写入 GreptimeDB 的表名。
如果你在 GreptimeDB 设置了[鉴权](/user-guide/deployments-administration/authentication/overview.md)。则需要使用 `basicauth/client` 扩展来处理基本的身份验证。
这里我们强烈建议使用不同的导出器来分别处理 traces、logs 和 metrics 数据,一方面是因为 GreptimeDB 会支持一些特定的 header 来自定义一些处理流程,另一方面也可以做好数据隔离。
关于 OpenTelemetry 协议的更多信息,请阅读[文档](/user-guide/ingest-data/for-observability/opentelemetry.md)。
---
## 可观测场景数据写入
在可观测性场景中,实时监控和分析系统性能的能力至关重要。
GreptimeDB 与领先的可观测性工具无缝集成,为你提供系统健康和性能指标的全面视图。
- [在 GreptimeDB 中存储万亿级日志,并快速获得分析结果](/user-guide/logs/overview.md).
- [Prometheus Remote Write](prometheus.md):将 GreptimeDB 作为 Prometheus 的远程存储,适用于实时监控和警报。
- [Vector](vector.md):将 GreptimeDB 用作 Vector 的接收端,适用于复杂的数据流水线和多样化的数据源。
- [OpenTelemetry](opentelemetry.md):将 telemetry 数据收集并导出到 GreptimeDB,以获取详细的可观测性洞察。
- [InfluxDB Line Protocol](influxdb-line-protocol.md):一种广泛使用的时间序列数据协议,便于从 InfluxDB 迁移到 GreptimeDB。该文档同样介绍了 Telegraf 的集成方式。
- [Loki](loki.md):一种广泛使用的日志写入协议,便于从 Loki 迁移到 GreptimeDB。本文档还介绍了 Alloy 集成方法。
---
## Prometheus
GreptimeDB 可以作为 Prometheus 的长期存储解决方案,提供无缝集成体验。
## 配置 Remote Write
### Prometheus 配置文件
要将 GreptimeDB 集成到 Prometheus 中,
请按照以下步骤更新你的 [Prometheus 配置文件](https://prometheus.io/docs/prometheus/latest/configuration/configuration/#configuration-file)(`prometheus.yml`):
```yaml
remote_write:
- url: http://localhost:4000/v1/prometheus/write?db=public
# 如果启用了身份验证,请取消注释并设置鉴权信息
# basic_auth:
# username: greptime_user
# password: greptime_pwd
remote_read:
- url: http://localhost:4000/v1/prometheus/read?db=public
# 如果启用了身份验证,请取消注释并设置鉴权信息
# basic_auth:
# username: greptime_user
# password: greptime_pwd
```
- URL 中的 host 和 port 表示 GreptimeDB 服务器。在此示例中,服务器运行在 `localhost:4000` 上。你可以将其替换为你自己的服务器地址。有关 GreptimeDB 中 HTTP 协议的配置,请参阅 [协议选项](/user-guide/deployments-administration/configuration.md#protocol-options)。
- URL 中的 `db` 参数表示要写入的数据库。它是可选的。默认情况下,数据库设置为 `public`。
- `basic_auth` 是身份鉴权配置。如果 GreptimeDB 启用了鉴权,请填写用户名和密码。请参阅 [鉴权认证文档](/user-guide/deployments-administration/authentication/overview.md)。
### Grafana Alloy 配置文件
如果你使用 Grafana Alloy,请在 Alloy 配置文件(`config.alloy`)中配置 Remote Write。有关更多信息,请参阅 [Alloy 文档](alloy.md#prometheus-remote-write)。
### Vector 配置文件
如果你使用 Vector ,请在 Vector 配置文件(`vector.toml`)中配置 Remote Write。有关更多信息,请参阅 [Vector 文档](vector.md#使用-prometheus-remote-write-协议).
## 数据模型
在 GreptimeDB 的[数据模型](/user-guide/concepts/data-model.md)中,数据被组织成具有 tag、time index 和 field 的表。
GreptimeDB 可以被视为多值数据模型,自动将多个 Prometheus 指标分组到相应的表中。
这样可以实现高效的数据管理和查询。
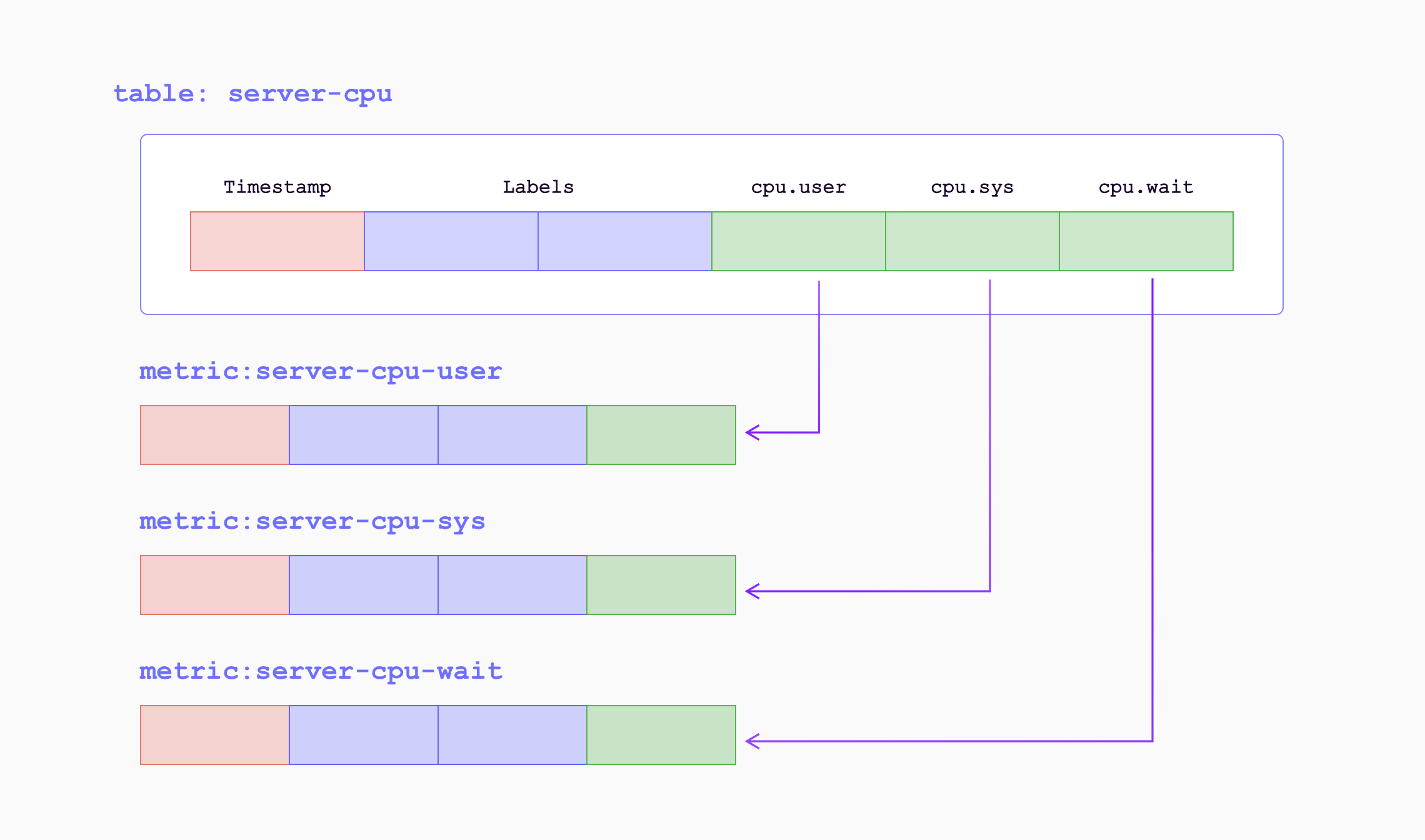
当指标通过远程写入端点写入 GreptimeDB 时,它们将被转换为以下形式:
| Sample Metrics | In GreptimeDB | GreptimeDB Data Types |
| -------------- | ------------------------- | --------------------- |
| Name | Table (Auto-created) Name | String |
| Value | Column (Field) | Double |
| Timestamp | Column (Time Index) | Timestamp |
| Label | Column (Tag) | String |
例如,以下 Prometheus 指标:
```txt
prometheus_remote_storage_samples_total{instance="localhost:9090", job="prometheus",
remote_name="648f0c", url="http://localhost:4000/v1/prometheus/write"} 500
```
将被转换为表 `prometheus_remote_storage_samples_total` 中的一行:
| Column | Value | Column Data Type |
| :----------------- | :------------------------------------------ | :----------------- |
| instance | localhost:9090 | String |
| job | prometheus | String |
| remote_name | 648f0c | String |
| url | `http://localhost:4000/v1/prometheus/write` | String |
| greptime_value | 500 | Double |
| greptime_timestamp | The sample's unix timestamp | Timestamp |
## 通过使用 metric engine 提高效率
Prometheus Remote Write 写入数据的方式经常会创建大量的小表,这些表在 GreptimeDB 中被归类为逻辑表。
然而,拥有大量的小表对于数据存储和查询性能来说是低效的。
为了解决这个问题,GreptimeDB 引入了 [metric engine](/contributor-guide/datanode/metric-engine.md) 功能,将逻辑表表示的数据存储在单个物理表中。
这种方法减少了存储开销并提高了列式压缩效率。
GreptimeDB 默认启用 metric engine,你不需要指定任何额外的配置。
默认情况下,使用的物理表为 `greptime_physical_table`。
如果你想使用特定的物理表,可以在 Remote Write URL 中指定 `physical_table` 参数。
如果指定的物理表不存在,它将被自动创建。
```yaml
remote_write:
- url: http://localhost:4000/v1/prometheus/write?db=public&physical_table=greptime_physical_table
```
虽然数据被存储在物理表中,但查询可以在逻辑表上执行以提供从指标角度的直观视角。
例如,当成功写入数据时,你可以使用以下命令显示逻辑表:
```sql
show tables;
```
```sql
+---------------------------------------------------------------+
| Tables |
+---------------------------------------------------------------+
| prometheus_remote_storage_enqueue_retries_total |
| prometheus_remote_storage_exemplars_pending |
| prometheus_remote_storage_read_request_duration_seconds_count |
| prometheus_rule_group_duration_seconds |
| ...... |
+---------------------------------------------------------------+
```
物理表本身也可以进行查询。
它包含了所有逻辑表的列,方便进行多表连接分析和计算。
要查看物理表的 schema,请使用 `DESC TABLE` 命令:
```sql
DESC TABLE greptime_physical_table;
```
物理表包含了所有逻辑表的列:
```sql
+--------------------+----------------------+------+------+---------+---------------+
| Column | Type | Key | Null | Default | Semantic Type |
+--------------------+----------------------+------+------+---------+---------------+
| greptime_timestamp | TimestampMillisecond | PRI | NO | | TIMESTAMP |
| greptime_value | Float64 | | YES | | FIELD |
| __table_id | UInt32 | PRI | NO | | TAG |
| __tsid | UInt64 | PRI | NO | | TAG |
| device | String | PRI | YES | | TAG |
| instance | String | PRI | YES | | TAG |
| job | String | PRI | YES | | TAG |
| error | String | PRI | YES | | TAG |
...
```
你可以使用 `SELECT` 语句根据需要从物理表中过滤数据。
例如,根据逻辑表 A 的 `device` 条件和逻辑表 B 的 `job` 条件来过滤数据:
```sql
SELECT *
FROM greptime_physical_table
WHERE greptime_timestamp > "2024-08-07 03:27:26.964000"
AND device = "device1"
AND job = "job1";
```
### 在 GreptimeDB 集群上使用 metric engine
在使用 Prometheus remote write 写入 GreptimeDB 集群时,用户可能注意到集群中只有
一 个 datanode 承载写入压力,其他节点没有流量。这是由于在默认配置下,集群中只有
一个 metric engine 物理表,且该表只有一个分区。承载此分区的节点将承担所有写入流
量。
为什么我们没有创建更多的分区呢?[GreptimeDB 的表分
区](/user-guide/deployments-administration/manage-data/table-sharding.md)基于预
定义的分区列。然而在 Prometheus 生态中并没有普遍存在的列(Prometheus 中的标签)
适合作为默认分区列。
因此,我们推荐用户基于自己的数据模型创建分区规则。例如,在监控 Kubernetes 集群的
场景下,`namespace` 可能是一个比较好的分区键。这个分区键应当具备一定的基数用于区
分数据。并且我们推荐用户在初始时创建 datanode 数量大约 2 倍至 3 倍的分区数量,为日后
集群扩容负载均衡做准备。
以下是一个分区的物理表例子:
```sql
CREATE TABLE greptime_physical_table (
greptime_timestamp TIMESTAMP(3) NOT NULL,
greptime_value DOUBLE NULL,
namespace STRING PRIMARY KEY,
TIME INDEX (greptime_timestamp),
)
PARTITION ON COLUMNS (namespace) (
namespace <'g',
namespace >= 'g' AND namespace < 'n',
namespace >= 'n' AND namespace < 't',
namespace >= 't'
)
ENGINE = metric
with (
"physical_metric_table" = "",
);
```
注意这里用户并不需要手动指定所有可能的主键(标签),metric engine 将会自动添加。
只有涉及到分区规则的列需要进行提前指定。
## 特殊标签
:::warning 实验性特性
此实验性功能可能存在预期外的行为,其功能未来可能发生变化。
:::
一般来说,一次 Remote write 请求的全部数据会以同样的配置项被写入到数据库中,例如,开启 metric engine 后使用的同一个物理表配置。
即使指标的数量在增长,所有的逻辑表(即指标们)都会保存到同一张物理表中。
对于写入这可能是没问题的。但是对于需要查询一小部分指标的场景,这种设置可能会拖慢查询速度,因为所有的指标都聚集在一张物理表上,而数据库需要对全表的数据进行扫描。
如果你可以预见大量的数据写入和每次只需查询小部分指标的场景,那么可以在写入时对存储位置进行划分以减缓后续查询的压力。
对于一个 Remote write 请求中的每个指标,这种精细的控制可以通过写入时的配置项来达成。
从 `v0.15` 开始,GreptimeDB 新增了对特殊标签的支持。
这些标签(与它们的值)会在解析阶段被转换成写入时的配置项,使请求内的单个指标可以被更精细地控制。
这些标签不是互斥的,它们可以通过组合的方式达成更多样化的控制选择。
以下是指标特殊标签的一个示例,注意这不是实际的数据模型。
| `__name__` | `x_greptime_database` | `x_greptime_physical_table` | `pod_name_label` | `__normal_label_with_underscore_prefix__` | `timestamp` | `value` |
|--------------------|-------------------------|-------------------------------|-----------------------|---------------------------------------------|---------------------------|-----------|
| `some_metric_name` | `public` | `p_1` | `random_k8s_pod_name` | `true` | `2025-06-17 16:31:52.000` | `12.1` |
上述特殊标签只是在 Prometheus 中的普通有效标签。
GreptimeDB 可以识别一些标签的名称,并将它们转换成写入时的配置项。
就像自定义的 HTTP header 一样,你可以通过设定一些有效的 HTTP header 键值对来指示后续的操作,只是这些 header 键值对在特定的程序之外不起任何作用。
以下是所有 GreptimeDB 支持的标签名称:
- `x_greptime_database`
- `x_greptime_physical_table`
### 设置标签
如何将标签设置到指标上,与你所使用的收集指标并发送到数据库的工具(或者代码)相关。
如果你使用 Prometheus 从源获取指标并使用 Remote write 将他们发送到 GreptimeDB 中,可以在全局设定中增加 `external_labels` 的配置。
参考这个[文档](https://prometheus.io/docs/prometheus/latest/configuration/configuration/#configuration-file)。
对于其他的收集工具也是一样的。对于你所使用的工具,你可能需要查找相应的设置。
### `x_greptime_database`
这个选项决定指标数据会被保存到哪个数据库中,该数据库需要被提前创建好(例如通过 `create database xxx` SQL 语句)。
一般来说,同样的技术栈会产生同样名称的指标。
例如你有两个 Kubernetes 集群,但是运行了不同的应用,然后通过一个指标收集工具同时收集两个集群的指标。
这两个集群会产生名称一样但是标签和值完全不同的指标。
如果这些指标被写入到同一个数据库中,那么在使用 Grafana 大盘浏览这些指标的时候,就需要对大盘的每个图表手动设置标签值,才能区分集群进行查看。
这样既繁琐又低效。
在这种情况下,你可以在写入时将指标保存到两个不同的数据库中,然后使用两个大盘分别浏览这些指标。
### `x_greptime_physical_table`
如果指标通过 metric engine 进行存储,那么每个指标的逻辑表背后是一张物理表。
默认下,所有的指标都使用同一张物理表。
随着指标数量的增长,这张物理表会变成一张超级宽表。如果指标的写入频率不同,那么物理表的数据将会是稀疏的。
在全量指标数据集中查找一个特定的指标或者标签将会消耗大量时间,因为数据库需要扫描所有不相关的数据。
这种场景下,将指标写入到不同的物理表可以减轻单一物理表的压力,这对通过写入频率来聚合指标的场景非常有用。
注意,指标的逻辑表在创建时就与物理表一一关联。在同一数据库下为同一指标设定不同的物理表不会生效。
## 在 Remote write 中使用 pipeline
:::warning 实验性特性
此实验性功能可能存在预期外的行为,其功能未来可能发生变化。
:::
从 `v0.15` 开始,GreptimeDB 支持在 Prometheus Remote Write 协议入口使用 pipeline 处理数据。
你可以通过在 HTTP header 中将 `x-greptime-pipeline-name` 的值设置为需要执行的 pipeline 名称来使用 pipeline 处理流程。
以下是一个非常简单的 pipeline 配置例子,使用 `vrl` 处理器来对每个指标增加一个 `source` 标签:
```YAML
version: 2
processors:
- vrl:
source: |
.source = "local_laptop"
.
transform:
- field: greptime_timestamp
type: time, ms
index: timestamp
```
结果如下所示
```
mysql> select * from `go_memstats_mcache_inuse_bytes`;
+----------------------------+----------------+--------------------+---------------+--------------+
| greptime_timestamp | greptime_value | instance | job | source |
+----------------------------+----------------+--------------------+---------------+--------------+
| 2025-07-11 07:42:03.064000 | 1200 | node_exporter:9100 | node-exporter | local_laptop |
| 2025-07-11 07:42:18.069000 | 1200 | node_exporter:9100 | node-exporter | local_laptop |
+----------------------------+----------------+--------------------+---------------+--------------+
2 rows in set (0.01 sec)
```
更多配置详情请参考 [pipeline 相关文档](/reference/pipeline/pipeline-config.md)。
## 性能优化
默认情况下,metric engine 会自动创建一个名为 `greptime_physical_table` 的物理表。
为了优化性能,你可以选择创建一个具有自定义配置的物理表。
### 启用跳数索引
默认情况下,metric engine 不会为列创建索引。你可以通过设置 `index.type` 为 `skipping` 来设置索引类型。
创建一个带有跳数索引的物理表。所有自动添加的列都将应用跳数索引。
```sql
CREATE TABLE greptime_physical_table (
greptime_timestamp TIMESTAMP(3) NOT NULL,
greptime_value DOUBLE NULL,
TIME INDEX (greptime_timestamp),
)
engine = metric
with (
"physical_metric_table" = "",
"index.type" = "skipping"
);
```
有关更多配置,请参阅 [create table](/reference/sql/create.md#create-table) 部分。
## VictoriaMetrics Remote Write
VictoriaMetrics 对 Prometheus 远程写入协议进行了轻微修改,以实现更好的压缩效果。
当你使用 `vmagent` 将数据发送到兼容的后端时,该协议会被自动启用。
GreptimeDB 也支持这个变种。只需将 GreptimeDB 的 Remote Write URL 配置为 `vmagent`。
例如,如果你在本地安装了 GreptimeDB:
```shell
vmagent -remoteWrite.url=http://localhost:4000/v1/prometheus/write
```
---
## Vector
:::tip 注意
本文档基于 Vector v0.49.0 版本编写。
以下的所有示例配置均基于此版本。对于各个 sink 的 host 和 port 配置请根据自己 GreptimeDB 实例的实际情况进行调整。
下文中的所有 port 值均为默认值。
:::
Vector 是高性能的可观测数据管道。
它原生支持 GreptimeDB 指标数据接收端。
通过 Vector,你可以从各种来源接收指标数据,包括 Prometheus、OpenTelemetry、StatsD 等。
GreptimeDB 可以作为 Vector 的 Sink 组件来接收指标数据。
## 写入指标数据
GreptimeDB 支持多种指标数据写入方式,包括:
- 使用 [`greptimedb_metrics` sink](https://vector.dev/docs/reference/configuration/sinks/greptimedb_metrics/)
- 使用 InfluxDB 行协议格式将指标数据写入 GreptimeDB
- 使用 Prometheus Remote Write 协议将指标数据写入 GreptimeDB
### 使用 `greptimedb_metrics` sink
#### 示例
以下是一个使用 `greptimedb_metrics` sink 写入宿主机指标的示例配置:
```toml
# sample.toml
[sources.in]
type = "host_metrics"
[sinks.my_sink_id]
inputs = ["in"]
type = "greptimedb_metrics"
endpoint = ":4001"
dbname = ""
username = ""
password = ""
new_naming = true
```
Vector 使用 gRPC 与 GreptimeDB 进行通信,因此 Vector sink 的默认端口是 `4001`。
如果你在使用 [自定义配置](/user-guide/deployments-administration/configuration.md#configuration-file) 启动 GreptimeDB 时更改了默认的 gRPC 端口,请使用你自己的端口。
如有更多需求请前往 [Vector GreptimeDB Configuration](https://vector.dev/docs/reference/configuration/sinks/greptimedb_metrics/) 查看更多配置项。
#### 数据模型
我们使用这样的规则将 Vector 指标存入 GreptimeDB:
- 使用 `_` 作为 GreptimeDB 的表名,例如 `host_cpu_seconds_total`;
- 将指标中的时间戳作为 GreptimeDB 的时间索引,默认列名 `ts`;
- 指标所关联的 tag 列将被作为 GreptimeDB 的 tag 字段;
- Vector 的指标,和其他指标类似,有多种子类型:
- Counter 和 Gauge 类型的指标,数值直接被存入 `val` 列;
- Set 类型,我们将集合的数据个数存入 `val` 列;
- Distribution 类型,各个百分位数值点分别存入 `pxx` 列,其中 xx 是 quantile 数值,此外我们还会记录 `min/max/avg/sum/count` 列;
- AggregatedHistoragm 类型,每个 bucket 的数值将被存入 `bxx` 列,其中 xx 是 bucket 数值的上限,此外我们还会记录 `sum/count` 列;
- AggregatedSummary 类型,各个百分位数值点分别存入 `pxx` 列,其中 xx 是 quantile 数值,此外我们还会记录 `sum/count` 列;
- Sketch 类型,各个百分位数值点分别存入 `pxx` 列,其中 xx 是 quantile 数值,此外我们还会记录 `min/max/avg/sum` 列;
### 使用 InfluxDB 行协议格式
可以使用 `influx` sink 来写入指标数据。我们推荐使用 v2 版本的 InfluxDB 行协议格式。
以下是一个使用 `influx` sink 写入宿主机指标的示例配置:
```toml
# sample.toml
[sources.my_source_id]
type = "internal_metrics"
[sinks.my_sink_id]
type = "influxdb_metrics"
inputs = [ "my_source_id" ]
bucket = "public"
endpoint = "http://:4000/v1/influxdb"
org = ""
token = ""
```
上述配置使用的是 InfluxDB 行协议的 v2 版本。Vector 会根据 TOML 配置中的字段来判断 InfluxDB 协议的版本,所以请务必确保配置中存在 `bucket`、`org` 和 `token` 字段。具体字段的解释如下:
- `type`: InfluxDB 行协议的值为 `influxdb_metrics`.
- `bucket`: GreptimeDB 中的 database 名称。
- `org`: GreptimeDB 中的组织名称(需置空)。
- `token`: 用于身份验证的令牌(需置空)。由于 Influx 行协议的 token 有特殊形式,必须以 `Token ` 开头。这和 GreptimeDB 的鉴权方式有所不同,且目前不兼容。如果使用的是含有鉴权的 GreptimeDB 实例,请使用 `greptimedb_metrics`。
更多细节请参考 [InfluxDB Line Protocol 文档](../for-iot/influxdb-line-protocol.md) 了解如何使用 InfluxDB Line Protocol 将数据写入到 GreptimeDB。
### 使用 Prometheus Remote Write 协议
以下是一个使用 Prometheus Remote Write 协议写入宿主机指标的示例配置:
```toml
# sample.toml
[sources.my_source_id]
type = "internal_metrics"
[sinks.prometheus_remote_write]
type = "prometheus_remote_write"
inputs = [ "my_source_id" ]
endpoint = "http://:4000/v1/prometheus/write?db="
compression = "snappy"
auth = { strategy = "basic", username = "", password = "" }
```
## 写入日志数据
GreptimeDB 支持多种日志数据写入方式,包括:
- 使用 [`greptimedb_logs` sink](https://vector.dev/docs/reference/configuration/sinks/greptimedb_logs/) 将日志数据写入 GreptimeDB。
- 使用 Loki 协议将日志数据写入 GreptimeDB。
我们强烈建议所有的用户使用 `greptimedb_logs` sink 来写入日志数据,因为它是为 GreptimeDB 优化的,能够更好地支持 GreptimeDB 的特性。
并且推荐开启各种协议的压缩功能,以提高数据传输效率。
### 使用 `greptimedb_logs` sink (推荐)
```toml
# sample.toml
[sources.my_source_id]
type = "demo_logs"
count = 10
format = "apache_common"
interval = 1
[sinks.my_sink_id]
type = "greptimedb_logs"
inputs = [ "my_source_id" ]
compression = "gzip"
dbname = "public"
endpoint = "http://:4000"
extra_headers = { "skip_error" = "true" }
pipeline_name = "greptime_identity"
table = ""
username = ""
password = ""
[sinks.my_sink_id.extra_params]
source = "vector"
x-greptime-pipeline-params = "max_nested_levels=10"
```
此示例展示了如何使用 `greptimedb_logs` sink 将生成的 demo 日志数据写入 GreptimeDB。更多信息请参考 [Vector greptimedb_logs sink](https://vector.dev/docs/reference/configuration/sinks/greptimedb_logs/) 文档。
### 使用 Loki 协议
#### 示例
```toml
[sources.generate_syslog]
type = "demo_logs"
format = "syslog"
count = 100
interval = 1
[transforms.remap_syslog]
inputs = ["generate_syslog"]
type = "remap"
source = """
.labels = {
"host": .host,
"service": .service,
}
.structured_metadata = {
"source_type": .source_type
}
"""
[sinks.my_sink_id]
type = "loki"
inputs = ["remap_syslog"]
compression = "snappy"
endpoint = "http://:4000"
out_of_order_action = "accept"
path = "/v1/loki/api/v1/push"
encoding = { codec = "raw_message" }
labels = { "*" = "{{labels}}" }
structured_metadata = { "*" = "{{structured_metadata}}" }
auth = {strategy = "basic", user = "", password = ""}
```
上述配置为使用 Loki 协议将日志数据写入 GreptimeDB。具体的配置项说明如下:
- `compression`:设置了数据传输时的压缩算法,这里使用了 `snappy`。
- `endpoint`:指定了 Loki 的接收地址。
- `out_of_order_action`:设置了如何处理乱序的日志,这里选择了 `accept`,表示接受乱序日志。GreptimeDB 支持乱序日志的写入。
- `path`:指定了 Loki 的 API 路径。
- `encoding`:设置了数据的编码方式,这里使用了 `raw_message`。
- `labels`:指定了日志的标签,这里将 `labels` 的内容映射为 `{{labels}}`。即 remap_syslog 中的 `labels` 字段。
- `structured_metadata`:指定了结构化元数据,这里将 `structured_metadata` 的内容映射为 `{{structured_metadata}}`。即 remap_syslog 中的 `structured_metadata` 字段。
关于 `labels` 和 `structured_metadata` 的含义,请参考 [Loki 文档](https://grafana.com/docs/loki/latest/get-started/labels/bp-labels/)。
对于 loki 协议,`labels` 默认会使用时序场景下的 Tag 类型,请注意这部分字段不要使用高基数字段。
`structured_metadata` 将会整体存储为一个 json 字段。
请注意,由于 Vector 的配置里不允许设置 header 所以无法指定 pipeline。
如果需要使用 pipeline 功能,请考虑使用 `greptimedb_logs` sink。
---
## 写入数据
GreptimeDB 支持自动生成表结构和灵活的数据写入方法,
使你能够轻松地根据特定场景写入数据。
## 自动生成表结构
GreptimeDB 支持无 schema 写入,即在数据写入时自动创建表格并添加必要的列。
这种能力确保你无需事先手动定义 schema,从而更容易管理和集成各种数据源。
此功能适用于所有协议和集成,除了 [SQL](./for-iot/sql.md)。
## 推荐的数据写入方法
GreptimeDB 支持针对特定场景的各种数据写入方法,以确保最佳性能和集成灵活性。
- [可观测场景](./for-observability/overview.md):适用于实时监控和警报。
- [物联网场景](./for-iot/overview.md):适用于实时数据和复杂的物联网基础设施。
## 下一步
- [查询数据](/user-guide/query-data/overview.md): 学习如何通过查询 GreptimeDB 数据库来探索数据。
- [管理数据](/user-guide/manage-data/overview.md): 学习如何更新和删除数据等,确保数据完整性和高效的数据管理。
---
## Grafana Alloy(Integrations)
你可以将 GreptimeDB 设置为 Grafana Alloy 的数据接收端。
更多信息,请参考[通过 Grafana Alloy 写入数据](/user-guide/ingest-data/for-observability/alloy.md)指南。
---
## Coroot
Coroot 是一个开源的 APM 和可观测性工具,
是 DataDog 和 NewRelic 的替代方案。
预定义的仪表板具备指标、日志、链路追踪、持续性能分析
和基于 SLO 的告警功能。
GreptimeDB 可以配置为 Coroot 中的 Prometheus 数据存储。
要将 GreptimeDB 集成到 Coroot 中,
需要在 Coroot 仪表板中导航到 Settings,
选择 Prometheus 配置,然后输入以下信息:
- Prometheus URL: `http{s}:///v1/prometheus`
- 如果你在 GreptimeDB 上[启用了身份验证](/user-guide/deployments-administration/authentication/static.md),请勾选 HTTP basic auth 并输入 GreptimeDB 用户名和密码。如果没有启用身份认证,保留未勾选状态即可。
- Remote Write URL: `http{s}:///v1/prometheus/write?db=`
## 示例配置
如果你的 GreptimeDB 被部署在 `localhost`,HTTP 服务端口为 `4000`,已启用身份验证,
并且使用默认数据库 `public`,
请使用以下配置:
- Prometheus URL: `http://localhost:4000/v1/prometheus`
- 启用 HTTP basic auth 选项并输入 GreptimeDB 用户名和密码
- Remote Write URL: `http://localhost:4000/v1/prometheus/write?db=public`
下图是 Coroot 的配置示例:
配置保存成功后,
你就可以开始使用 Coroot 监控实例了。
下图展示了使用 GreptimeDB 作为数据源的 Coroot 仪表板示例:
---
## DBeaver
[DBeaver](https://dbeaver.io/) 是一个免费、开源且跨平台的数据库工具,支持所有流行的数据库。
由于其易用性和丰富的功能集,它在开发人员和数据库管理员中非常受欢迎。
你可以使用 DBeaver 通过 MySQL Driver 连接到 GreptimeDB。
点击 DBeaver 工具栏中的“New Database Connection”按钮,以创建 GreptimeDB 的新连接。
选择 MySQL 并点击“下一步”以配置连接。
如果你还没有安装 MySQL Driver,请先安装。
接下来输入以下连接信息:
- Connect by Host
- Host:如果 GreptimeDB 运行在本机,则为 `localhost`
- Port:如果使用默认的 GreptimeDB 配置,则为 `4002`
- Database:`public`,你也可以使用你创建的其他数据库名称
- 如果你的 GreptimeDB 启用了身份验证,请输入 username 和 password,否则留空
点击“Test Connection”以验证连接设置,然后点击“Finish”以保存连接。
有关 MySQL 与 GreptimeDB 交互的更多信息,请参阅 [MySQL 协议文档](/user-guide/protocols/mysql.md)。
---
## EMQX(Integrations)
GreptimeDB 可以作为 EMQX 的数据系统。
更多信息请参考 [通过 EMQX 写入数据](/user-guide/ingest-data/for-iot/emqx.md) 指南。
---
## Fluent Bit(Integrations)
你可以将 GreptimeDB 设置为 Fluent Bit 的数据接收端。
更多信息,请参考[通过 Fluent Bit 写入数据](../ingest-data/for-observability/fluent-bit.md)指南。
---
## Grafana
GreptimeDB 服务可以配置为 [Grafana 数据源](https://grafana.com/docs/grafana/latest/datasources/add-a-data-source/)。
你可以选择使用以下三个数据源之一连接 GreptimeDB 与 Grafana:GreptimeDB、Prometheus 或 MySQL。
## GreptimeDB 数据源插件
[GreptimeDB 数据源插件(v2.x)](https://github.com/GreptimeTeam/greptimedb-grafana-datasource)基于 ClickHouse 插件开发并附加了特定于 GreptimeDB 的功能。
该插件完美适配了 GreptimeDB 的数据模型,
从而提供了更好的用户体验。
### 安装
GreptimeDB 数据源插件目前仅支持在本地 Grafana 中的安装,
在安装插件前请确保 Grafana 已经安装并运行。
你可以任选以下一种安装方式:
- 下载安装包并解压到相关目录:从[发布页面](https://github.com/GreptimeTeam/greptimedb-grafana-datasource/releases/latest/)获取最新版本,解压文件到你的 [grafana 插件目录](https://grafana.com/docs/grafana/latest/setup-grafana/configure-grafana/#plugins)。
- 使用 Grafana Cli 下载并安装:
```shell
grafana cli --pluginUrl https://github.com/GreptimeTeam/greptimedb-grafana-datasource/releases/latest/download/info8fcc-greptimedb-datasource.zip plugins install info8fcc
```
- 使用我们 [预构建的 Grafana 镜
像](https://hub.docker.com/r/greptime/grafana-greptimedb),已经提前包含了
GreptimeDB 数据源插件 `docker run -p 3000:3000
greptime/grafana-greptimedb:latest`
注意,安装插件后可能需要重新启动 Grafana 服务器。
### Connection 配置
在 Grafana 中单击 Add data source 按钮,选择 GreptimeDB 作为类型。
在 GreptimeDB server URL 中填写以下地址:
```txt
http://:4000
```
在 Auth 部分中单击 basic auth,并在 Basic Auth Details 中填写 GreptimeDB 的用户名和密码。未设置可留空:
- User: ``
- Password: ``
然后单击 Save & Test 按钮以测试连接。
### 基础查询设置
在进行所有类型查询选择前,需要先设置要查询的数据库和表
| 设置项 | 对应值 |
|-----------|-------------|
| Database| 选择数据库
| Table | 选择表格

---
### Table 查询
当查询结果不包含`时间列`时可以选择 `Table` 类型进行查询
| 设置项 | 对应值 |
|-----------|-------------|
| Columns | 选择要查询的列,可多选
| Filters | 设置筛选条件
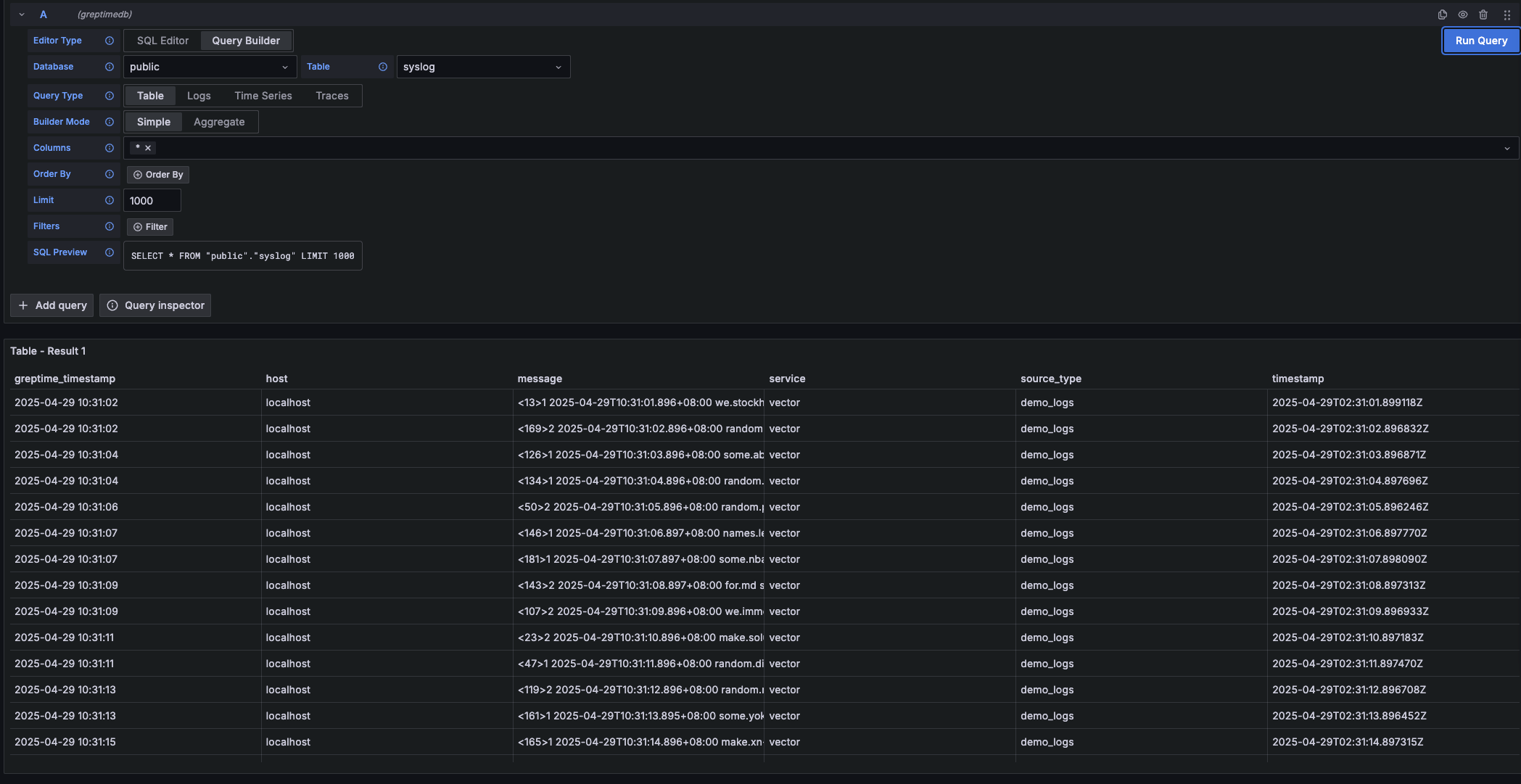
---
### Metrics 查询
当查询结果包含`时间列`和`数值列`时可以选择 `Time Series` 类型进行查询
| 主要设置项 | 对应值 |
|-----------|-------------|
| Time | 选择时间列
| Columns | 选择数值列
---
### Logs 查询
当要查询 Logs 数据时选择 `Logs` 类型进行查询
* Logs: 对日志数据进行查询。需要设置 `Time` 列和 `Message` 列。
| 主要设置项 | 对应值 |
|-----------|--------------------|
| Time | 选择时间列
| Message | 选择日志内容列
| Log Level| 日志等级(非必填)
#### logs Context 查询
根据日志行的 context 列的值进行近似时间范围查询
* 需要先设置 context 相关的列。
* 然后查询的时候包含 context 相关列。
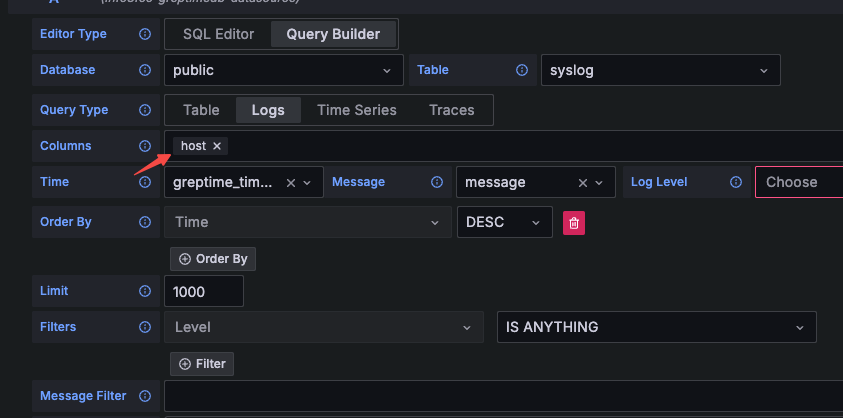
---
### Traces 查询
当要查询 Traces 数据时选择 `Traces` 类型进行查询
| 主要设置项 | 对应值 |
|-----------|---------------------|
| Trace Model | 选择 `Trace Search` 以查询 Trace 列表
| Trace Id Column | 初始值 `trace_id`
| Span Id Column | 初始值 `span_id`
| Parent Span ID Column | 初始值 `parent_span_id`
| Service Name Column | 初始值 `service_name`
| Operation Name Column | 初始值 `span_name`
| Start Time Column | 初始值 `timestamp`
| Duration Time Column | 初始值 `duration_nano`
| Duration Unit | 初始值 `nano_seconds`
| Tags Column | 可多选,对应以 `span_attributes` 开头的列
| Service Tags Column| 可多选,对应以 `resource_attributes` 开头的列
## Prometheus 数据源
单击 Add data source 按钮,然后选择 Prometheus 作为类型。
在 HTTP 中填写 Prometheus server URL
```txt
http://:4000/v1/prometheus
```
在 Auth 部分中单击 basic auth,并在 Basic Auth Details 中填写 GreptimeDB 的用户名和密码:
- User: ``
- Password: ``
在 Custom HTTP Headers 部分中点击 Add header:
- Header: `x-greptime-db-name`
- Value: ``
然后单击 Save & Test 按钮以测试连接。
有关如何使用 PromQL 查询数据,请参阅 [Prometheus 查询语言](/user-guide/query-data/promql.md)文档。
## MySQL 数据源
单击 Add data source 按钮,然后选择 MySQL 作为类型。在 MySQL Connection 中填写以下信息:
- Host: `:4002`
- Database: ``
- User: ``
- Password: ``
- Session timezone: `UTC`
然后单击 Save & Test 按钮以测试连接。
注意目前我们只能使用 raw SQL 创建 Grafana Panel。由于时间戳数据类型的区别,Grafana
的 SQL Builder 暂时无法选择时间戳字段。
关于如何用 SQL 查询数据,请参考[使用 SQL 查询数据](/user-guide/query-data/sql.md)文档。
---
## Kafka(Integrations)
你可以使用 Vector 作为从 Kafka 到 GreptimeDB 的数据传输工具。
请前往[通过 Kafka 写入数据](/user-guide/ingest-data/for-observability/kafka.md)了解更多信息。
---
## Model Context Protocol (MCP)
:::warning 实验性功能
GreptimeDB MCP Server 目前处于实验阶段并在积极开发中。API 和功能可能会在没有通知的情况下发生变化。请在生产环境中谨慎使用。
:::
[GreptimeDB MCP Server](https://github.com/GreptimeTeam/greptimedb-mcp-server) 提供了模型上下文协议的实现,使 Claude 等 AI 助手能够安全地探索和分析您的 GreptimeDB 数据库。
查看我们的[演示视频和文章](https://mp.weixin.qq.com/s/gbTuMLoG4b151Hs8KCSGxg),了解 MCP Server 的实际应用效果,更直观地理解其功能。
## 什么是 MCP?
模型上下文协议(MCP)是一种标准协议,允许 AI 助手与外部数据源和工具进行交互。通过 GreptimeDB MCP Server,您可以让 AI 助手实现:
- 列出和探索数据库表
- 读取表数据和模式
- 执行 SQL 查询
- 通过自然语言分析时序数据
## 安装
使用 pip 安装 GreptimeDB MCP Server:
```bash
pip install greptimedb-mcp-server
```
## 配置
MCP 服务器可以通过环境变量或命令行参数进行配置。主要配置选项包括:
- 数据库连接设置(主机、端口、用户名、密码)
- 数据库名称
- 时区设置
### 示例:Claude Desktop 集成
要与 Claude Desktop 集成,请在您的 `claude_desktop_config.json` 中添加以下配置:
```json
{
"mcpServers": {
"greptimedb": {
"command": "python",
"args": ["-m", "greptimedb_mcp_server"],
"env": {
"GREPTIMEDB_HOST": "localhost",
"GREPTIMEDB_PORT": "4002",
"GREPTIMEDB_USERNAME": "your_username",
"GREPTIMEDB_PASSWORD": "your_password",
"GREPTIMEDB_DATABASE": "your_database"
}
}
}
}
```
## 了解更多
有关详细的配置选项、高级用法和故障排除,请参阅 [GreptimeDB MCP Server 文档](https://github.com/GreptimeTeam/greptimedb-mcp-server)。
:::note
GreptimeDB MCP Server 是一个仍在开发中的实验性项目。在处理敏感数据时请谨慎使用。
:::
---
## Metabase
[Metabase](https://github.com/metabase/metabase) 是一个用 Clojure 编写的开源 BI
工具,可以通过社区维护的数据库驱动将 GreptimeDB 添加到 Metabase。
## 安装
从 [发布
页](https://github.com/greptimeteam/greptimedb-metabase-driver/releases/latest/)
下载最新的驱动插件文件 `greptimedb.metabase-driver.jar`,并将文件拷贝到 Metabase
的工作目录下 `plugins/` 目录中(如果不存在需要创建 `plugins/`)。当 Metabase 启
动时,会自动检测到插件。
## 添加 GreptimeDB 数据库
选择 *设置* / *管理员设置* / *数据库*, 点击 *添加数据库* 按钮并选择 GreptimeDB
作为 *数据库类型*.
进一步添加其他数据库信息:
- 端口请填写 GreptimeDB 的 Postgres 协议端口 `4003`。
- 如果没有开启[认证](/user-guide/deployments-administration/authentication/overview.md),用户名和密码字段
是可选的。
- 默认填写 `public` 作为 *数据库名*。如果是使用 GreptimeCloud 的实例,可以从控制
台复制数据库名称。
---
## MindsDB
[MindsDB](https://mindsdb.com/) 是一个开源的机器学习平台,使开发人员能够轻松地将
先进的机器学习能力与现有数据库集成。
使用 MindsDB 扩展,你的 GreptimeDB 实例可以开箱即用。
你可以使用 MySQL 协议将 GreptimeDB 配置为 MindsDB 中的数据源:
```sql
CREATE DATABASE greptime_datasource
WITH ENGINE = 'greptimedb',
PARAMETERS = {
"host": "",
"port": 4002,
"database": "",
"user": "",
"password": "",
"ssl": True
};
```
- `` 是你的 GreptimeDB 实例的主机名或 IP 地址。
- `` 是你想要连接的数据库名称。
- `` 和 `` 是你 [GreptimeDB 的鉴权信息](/user-guide/deployments-administration/authentication/static.md)。
MindsDB 是许多机器学习功能的优秀门户,包括您存储在我们实例中的时间序列数据的时间序列预测。
访问 [MindsDB docs](https://docs.mindsdb.com/what-is-mindsdb) 了解更多。
---
## 工具集成
GreptimeDB 可以与流行的数据写入、查询和可视化工具无缝集成。
本章节提供了将 GreptimeDB 与以下工具集成的指导:
---
## Prometheus(Integrations)
## Remote Write
GreptimeDB 可以用作 Prometheus 的远程存储后端。
详细信息请参考[使用 Prometheus Remote Write 写入数据](/user-guide/ingest-data/for-observability/prometheus.md)。
## Prometheus Query Language (PromQL)
GreptimeDB 支持使用 Prometheus 查询语言 (PromQL) 来查询数据。
更多信息请参考[使用 PromeQL 查询数据](/user-guide/query-data/promql.md)。
---
## Streamlit
[Streamlit](https://streamlit.io/) 是一种更快的构建和分享数据应用的方式。
可以基于 GreptimeDB 构建基于 Streamlit 的数据应用。
你需要创建一个 SQL 连接在应用程序中使用 GreptimeDB 数据。
由于 GreptimeDB 的 [MySQL 协议兼容性](/user-guide/protocols/mysql.md),你可以在连接时将 GreptimeDB 视为 MySQL。
以下是从 Streamlit 连接到 GreptimeDB 的示例代码片段:
```python
st.title('GreptimeDB Streamlit 演示')
conn = st.connection("greptimedb", type="sql", url="mysql://:@:4002/")
df = conn.query("SELECT * FROM ...")
```
- `` 是 GreptimeDB 实例的主机名或 IP 地址。
- `` 是要连接的数据库的名称。
- `` 和 `` 是 [GreptimeDB 鉴权认证信息](/user-guide/deployments-administration/authentication/static.md)。
创建连接后,你可以对 GreptimeDB 实例运行 SQL 查询。结果集会自动转换为 Pandas dataframe,就像在 Streamlit 中使用普通数据源一样。
---
## Superset
[Apache Superset](https://superset.apache.org) 是开源的 BI 工具,用 Python 编写。
以下内容可以帮助你把 GreptimeDB 作为 Superset 的数据源。
## 安装
### 用 Docker Compose 运行 Superset
[Docker compose](https://superset.apache.org/docs/installation/docker-compose)
是 Superset 的推荐使用方式。在这种运行方式下,需要在 Superset 代码目录下的
`docker/` 中添加一个 `requirements-local.txt`。
并将 GreptimeDB 依赖加入到 `requirements-local.txt`:
```txt
greptimedb-sqlalchemy
```
启动 Supertset 服务:
```bash
docker compose -f docker-compose-non-dev.yml up
```
### 本地运行 Superset
假如你通过 [Pypi 包安装和运行
Superset](https://superset.apache.org/docs/installation/pypi),需要将 GreptimeDB
的依赖安装到相同的 Python 环境。
```bash
pip install greptimedb-sqlalchemy
```
## 添加 GreptimeDB 数据库
准备添加,选择 *设置* / *数据库连接*.
添加数据库,并在支持的数据库列表中选择 *GreptimeDB*。
根据 SQLAlchemy URI 的规范,填写以下格式的数据库连接地址。
```
greptimedb://:@:/
```
- 如果没有启动[认证](/user-guide/deployments-administration/authentication/overview.md),可以忽略
`:@` 部分。
- 默认端口 `4003` (我们用 PostgresSQL 协议通信)。
- 默认数据库 `public`。如果是使用 GreptimeCloud 实例,可以从控制台复制数据库名称。
---
## Telegraf
请参考 InfluxDB 行协议文档中的 [Telegraf 部分](/user-guide/ingest-data/for-iot/influxdb-line-protocol.md#telegraf) 了解如何使用 Telegraf 向 GreptimeDB 写入数据。
---
## Vector(Integrations)
请前往[使用 Vector 写入数据](/user-guide/ingest-data/for-observability/vector.md)查看如何使用 Vector 将数据传输到 GreptimeDB。
---
## 全文搜索
本文档详细介绍如何利用 GreptimeDB 的查询语言对日志数据进行高效搜索和分析。
GreptimeDB 支持通过 SQL 语句灵活查询数据。本节将介绍特定的搜索功能和查询语句,帮助你提升日志查询效率。
## 使用 `matches_term` 函数进行精确匹配
在 SQL 查询中,你可以使用 `matches_term` 函数执行精确的词语/短语匹配,这在日志分析中尤其实用。`matches_term` 函数支持对 `String` 类型列进行精确匹配。你也可以使用 `@@` 操作符作为 `matches_term` 的简写形式。下面是一个典型示例:
```sql
-- 使用 matches_term 函数
SELECT * FROM logs WHERE matches_term(message, 'error') OR matches_term(message, 'fail');
-- 使用 @@ 操作符(matches_term 的简写形式)
SELECT * FROM logs WHERE message @@ 'error' OR message @@ 'fail';
```
`matches_term` 函数专门用于精确匹配,使用方式如下:
- `text`:需要进行匹配的文本列,该列应包含 `String` 类型的文本数据。
- `term`:要匹配的词语或短语,遵循以下规则:
- 区分大小写
- 匹配项必须由非字母数字字符(包括空格、标点符号等)或文本开头/结尾界定
- 支持完整词语匹配和短语匹配
## 查询语句示例
### 简单词语匹配
`matches_term` 函数执行精确词语匹配,这意味着它只会匹配由非字母数字字符或文本开头/结尾界定的完整词语。这对于在日志中查找特定的错误消息或状态码特别有用。
```sql
-- 使用 matches_term 函数
SELECT * FROM logs WHERE matches_term(message, 'error');
-- 使用 @@ 操作符
SELECT * FROM logs WHERE message @@ 'error';
```
此查询将返回所有 `message` 列中包含完整词语 "error" 的记录。该函数确保你不会得到部分匹配或词语内的匹配。
匹配和不匹配的示例:
- ✅ "An error occurred!" - 匹配,因为 "error" 是一个完整词语
- ✅ "Critical error: system failure" - 匹配,因为 "error" 由空格和冒号界定
- ✅ "error-prone" - 匹配,因为 "error" 由连字符界定
- ❌ "errors" - 不匹配,因为 "error" 是更大词语的一部分
- ❌ "error123" - 不匹配,因为 "error" 后面跟着数字
- ❌ "errorLogs" - 不匹配,因为 "error" 是驼峰命名词语的一部分
### 多关键词搜索
你可以使用 `OR` 运算符组合多个 `matches_term` 条件来搜索包含多个关键词中任意一个的日志。当你想要查找可能包含不同错误变体或不同类型问题的日志时,这很有用。
```sql
-- 使用 matches_term 函数
SELECT * FROM logs WHERE matches_term(message, 'critical') OR matches_term(message, 'error');
-- 使用 @@ 操作符
SELECT * FROM logs WHERE message @@ 'critical' OR message @@ 'error';
```
此查询将查找包含完整词语 "critical" 或 "error" 的日志。每个词语都是独立匹配的,结果包括匹配任一条件的日志。
匹配和不匹配的示例:
- ✅ "critical error: system failure" - 匹配两个词语
- ✅ "An error occurred!" - 匹配 "error"
- ✅ "critical failure detected" - 匹配 "critical"
- ❌ "errors" - 不匹配,因为 "error" 是更大词语的一部分
- ❌ "critical_errors" - 不匹配,因为词语是更大词语的一部分
### 排除条件搜索
你可以使用 `NOT` 运算符与 `matches_term` 结合来从搜索结果中排除某些词语。当你想要查找包含一个词语但不包含另一个词语的日志时,这很有用。
```sql
-- 使用 matches_term 函数
SELECT * FROM logs WHERE matches_term(message, 'error') AND NOT matches_term(message, 'critical');
-- 使用 @@ 操作符
SELECT * FROM logs WHERE message @@ 'error' AND NOT message @@ 'critical';
```
此查询将查找包含词语 "error" 但不包含词语 "critical" 的日志。这对于过滤掉某些类型的错误或专注于特定的错误类别特别有用。
匹配和不匹配的示例:
- ✅ "An error occurred!" - 匹配,因为它包含 "error" 但不包含 "critical"
- ❌ "critical error: system failure" - 不匹配,因为它包含两个词语
- ❌ "critical failure detected" - 不匹配,因为它包含 "critical"
### 多条件必要搜索
你可以使用 `AND` 运算符要求日志消息中必须存在多个词语。这对于查找包含特定词语组合的日志很有用。
```sql
-- 使用 matches_term 函数
SELECT * FROM logs WHERE matches_term(message, 'critical') AND matches_term(message, 'error');
-- 使用 @@ 操作符
SELECT * FROM logs WHERE message @@ 'critical' AND message @@ 'error';
```
此查询将查找同时包含完整词语 "critical" 和 "error" 的日志。两个条件都必须满足,日志才会包含在结果中。
匹配和不匹配的示例:
- ✅ "critical error: system failure" - 匹配,因为它包含两个词语
- ❌ "An error occurred!" - 不匹配,因为它只包含 "error"
- ❌ "critical failure detected" - 不匹配,因为它只包含 "critical"
### 短语匹配
`matches_term` 函数也可以匹配精确的短语,包括带空格的短语。这对于查找包含多个词语的特定错误消息或状态更新很有用。
```sql
-- 使用 matches_term 函数
SELECT * FROM logs WHERE matches_term(message, 'system failure');
-- 使用 @@ 操作符
SELECT * FROM logs WHERE message @@ 'system failure';
```
此查询将查找包含精确短语 "system failure" 的日志。整个短语必须完全匹配,包括词语之间的空格。
匹配和不匹配的示例:
- ✅ "Alert: system failure detected" - 匹配,因为短语被正确界定
- ✅ "system failure!" - 匹配,因为短语被正确界定
- ❌ "system-failure" - 不匹配,因为词语由连字符而不是空格分隔
- ❌ "system failure2023" - 不匹配,因为短语后面跟着数字
### 不区分大小写匹配
虽然 `matches_term` 默认区分大小写,但你可以通过在匹配前将文本转换为小写来实现不区分大小写的匹配。
```sql
-- 使用 matches_term 函数
SELECT * FROM logs WHERE matches_term(lower(message), 'warning');
-- 使用 @@ 操作符
SELECT * FROM logs WHERE lower(message) @@ 'warning';
```
此查询将查找包含词语 "warning" 的日志,无论其大小写如何。`lower()` 函数在匹配前将整个消息转换为小写。
匹配和不匹配的示例:
- ✅ "Warning: high temperature" - 匹配,因为大小写转换后匹配
- ✅ "WARNING: system overload" - 匹配,因为大小写转换后匹配
- ❌ "warned" - 不匹配,因为它是不同的词语
- ❌ "warnings" - 不匹配,因为它是不同的词语
---
## 管理 Pipeline
在 GreptimeDB 中,每个 `pipeline` 是一个数据处理单元集合,用于解析和转换写入的日志内容。本文档旨在指导你如何创建和删除 Pipeline,以便高效地管理日志数据的处理流程。
有关 Pipeline 的具体配置,请阅读 [Pipeline 配置](/reference/pipeline/pipeline-config.md)。
## 鉴权
在使用 HTTP API 进行 Pipeline 管理时,你需要提供有效的鉴权信息。
请参考[鉴权](/user-guide/protocols/http.md#鉴权)文档了解详细信息。
## 上传 Pipeline
GreptimeDB 提供了专用的 HTTP 接口用于创建 Pipeline。
假设你已经准备好了一个 Pipeline 配置文件 pipeline.yaml,使用以下命令上传配置文件,其中 `test` 是你指定的 Pipeline 的名称:
```shell
## 上传 pipeline 文件。test 为 Pipeline 的名称
curl -X "POST" "http://localhost:4000/v1/pipelines/test" \
-H "Authorization: Basic {{authentication}}" \
-F "file=@pipeline.yaml"
```
你可以在所有 Database 中使用创建的 Pipeline。
## Pipeline 版本
你可以使用相同的名称上传多个版本的 pipeline。
每次你使用现有名称上传 pipeline 时,都会自动创建一个新版本。
你可以在[写入日志](/reference/pipeline/write-log-api.md#http-api)、[查询](#查询-pipeline)或[删除](#删除-pipeline) pipeline 时指定要使用的版本。
如果未指定版本,默认使用最后上传的版本。
成功上传 pipeline 后,响应将包含版本信息:
```json
{"name":"nginx_pipeline","version":"2024-06-27 12:02:34.257312110Z"}
```
版本是 UTC 格式的时间戳,表示 pipeline 的创建时间。
此时间戳作为每个 pipeline 版本的唯一标识符。
## 删除 Pipeline
可以使用以下 HTTP 接口删除 Pipeline:
```shell
## test 为 Pipeline 的名称
curl -X "DELETE" "http://localhost:4000/v1/pipelines/test?version=2024-06-27%2012%3A02%3A34.257312110Z" \
-H "Authorization: Basic {{authentication}}"
```
上面的例子中,我们删除了名为 `test` 的 Pipeline。`version` 参数是必须的,用于指定要删除的 Pipeline 的版本号。
## 查询 Pipeline
可以使用以下 HTTP 接口查询 Pipeline:
```shell
## test 是 Pipeline 的名称,该查询将返回最新版本的 Pipeline。
curl "http://localhost:4000/v1/pipelines/test" \
-H "Authorization: Basic {{authentication}}"
```
```shell
## 如果你想查询某个 Pipeline 的历史版本,可以在 URL 中添加 `version` 参数
curl "http://localhost:4000/v1/pipelines/test?version=2025-04-01%2006%3A58%3A31.335251882%2B0000" \
-H "Authorization: Basic {{authentication}}"
```
如果这个 pipeline 存在,输出会如下所示:
```json
{
"pipelines": [
{
"name": "test",
"version": "2025-04-01 06:58:31.335251882",
"pipeline": "version: 2\nprocessors:\n - dissect:\n fields:\n - message\n patterns:\n - '%{ip_address} - - [%{timestamp}] \"%{http_method} %{request_line}\" %{status_code} %{response_size} \"-\" \"%{user_agent}\"'\n ignore_missing: true\n - date:\n fields:\n - timestamp\n formats:\n - \"%d/%b/%Y:%H:%M:%S %z\"\n - select:\n type: exclude\n fields:\n - message\n\ntransform:\n - fields:\n - ip_address\n type: string\n index: inverted\n tag: true\n - fields:\n - status_code\n type: int32\n index: inverted\n tag: true\n - fields:\n - request_line\n - user_agent\n type: string\n index: fulltext\n - fields:\n - response_size\n type: int32\n - fields:\n - timestamp\n type: time\n index: timestamp\n"
}
],
"execution_time_ms": 7
}
```
在上面的输出中,`pipeline` 字段是 YAML 格式的字符串。
你可以使用 [`jq -r`](https://jqlang.org/) 以更易读的方式展示它:
```shell
curl "http://localhost:4000/v1/pipelines/test?version=2025-04-01%2006%3A58%3A31.335251882%2B0000" \
-H "Authorization: Basic {{authentication}}" \
| jq -r '.pipelines[0].pipeline'
```
```yml
version: 2
processors:
- dissect:
fields:
- message
patterns:
- '%{ip_address} - - [%{timestamp}] "%{http_method} %{request_line}" %{status_code} %{response_size} "-" "%{user_agent}"'
ignore_missing: true
- date:
fields:
- timestamp
formats:
- "%d/%b/%Y:%H:%M:%S %z"
- select:
type: exclude
fields:
- message
transform:
- fields:
- ip_address
type: string
index: inverted
tag: true
- fields:
- status_code
type: int32
index: inverted
tag: true
- fields:
- request_line
- user_agent
type: string
index: fulltext
- fields:
- response_size
type: int32
- fields:
- timestamp
type: time
index: timestamp
```
或者使用 SQL 来查询 Pipeline:
```sql
SELECT * FROM greptime_private.pipelines;
```
请注意,如果你使用 MySQL 或者 PostgreSQL 协议作为连接 GreptimeDB 的方式,查询出来的 Pipeline 时间信息精度可能有所不同,可能会丢失纳秒级别的精度。
为了解决这个问题,可以将 `created_at` 字段强制转换为 timestamp 来查看 Pipeline 的创建时间。例如,下面的查询将 `created_at` 以 `bigint` 的格式展示:
```sql
SELECT name, pipeline, created_at::bigint FROM greptime_private.pipelines;
```
查询结果如下:
```
name | pipeline | greptime_private.pipelines.created_at
------+-----------------------------------+---------------------------------------
test | processors: +| 1719489754257312110
| - date: +|
| field: time +|
| formats: +|
| - "%Y-%m-%d %H:%M:%S%.3f"+|
| ignore_missing: true +|
| +|
| transform: +|
| - fields: +|
| - id1 +|
| - id2 +|
| type: int32 +|
| - fields: +|
| - type +|
| - logger +|
| type: string +|
| index: inverted +|
| - fields: +|
| - log +|
| type: string +|
| index: fulltext +|
| - field: time +|
| type: time +|
| index: timestamp +|
| |
(1 row)
```
然后可以使用程序将 SQL 结果中的 bigint 类型的时间戳转换为时间字符串。
```shell
timestamp_ns="1719489754257312110"; readable_timestamp=$(TZ=UTC date -d @$((${timestamp_ns:0:10}+0)) +"%Y-%m-%d %H:%M:%S").${timestamp_ns:10}Z; echo "Readable timestamp (UTC): $readable_timestamp"
```
输出:
```shell
Readable timestamp (UTC): 2024-06-27 12:02:34.257312110Z
```
输出的 `Readable timestamp (UTC)` 即为 Pipeline 的创建时间同时也是版本号。
## 问题调试
首先,请参考 [快速入门示例](/user-guide/logs/quick-start.md#使用-pipeline-写入日志)来查看 Pipeline 正确的执行情况。
### 调试创建 Pipeline
在创建 Pipeline 的时候你可能会遇到错误,例如使用如下配置创建 Pipeline:
```bash
curl -X "POST" "http://localhost:4000/v1/pipelines/test" \
-H "Content-Type: application/x-yaml" \
-H "Authorization: Basic {{authentication}}" \
-d $'processors:
- date:
field: time
formats:
- "%Y-%m-%d %H:%M:%S%.3f"
ignore_missing: true
- gsub:
fields:
- message
pattern: "\\\."
replacement:
- "-"
ignore_missing: true
transform:
- fields:
- message
type: string
- field: time
type: time
index: timestamp
'
```
Pipeline 配置存在错误。`gsub` processor 期望 `replacement` 字段为字符串,但当前配置提供了一个数组。因此,该 Pipeline 创建失败,并显示以下错误消息:
```json
{"error":"Failed to parse pipeline: 'replacement' must be a string"}
```
因此,你需要修改 `gsub` processor 的配置,将 `replacement` 字段的值更改为字符串类型。
```bash
curl -X "POST" "http://localhost:4000/v1/pipelines/test" \
-H "Content-Type: application/x-yaml" \
-H "Authorization: Basic {{authentication}}" \
-d $'processors:
- date:
field: time
formats:
- "%Y-%m-%d %H:%M:%S%.3f"
ignore_missing: true
- gsub:
fields:
- message
pattern: "\\\."
replacement: "-"
ignore_missing: true
transform:
- fields:
- message
type: string
- field: time
type: time
index: timestamp
'
```
此时 Pipeline 创建成功,可以使用 `dryrun` 接口测试该 Pipeline。
### 调试日志写入
我们可以使用 `dryrun` 接口测试 Pipeline。我们将使用错误的日志数据对其进行测试,其中消息字段的值为数字格式,会导致 Pipeline 在处理过程中失败。
**此接口仅仅用于测试 Pipeline 的处理结果,不会将日志写入到 GreptimeDB 中。**
```bash
curl -X "POST" "http://localhost:4000/v1/pipelines/_dryrun?pipeline_name=test" \
-H "Content-Type: application/json" \
-H "Authorization: Basic {{authentication}}" \
-d $'{"message": 1998.08,"time":"2024-05-25 20:16:37.217"}'
```
输出:
```json
{"error":"Processor gsub: expect string value, but got Float(1998.08)"}
```
输出显示 Pipeline 处理失败,因为 `gsub` Processor 期望的是字符串类型,而不是浮点数类型。我们需要修改日志数据的格式,确保 Pipeline 能够正确处理。
我们再将 message 字段的值修改为字符串类型,然后再次测试该 Pipeline。
```bash
curl -X "POST" "http://localhost:4000/v1/pipelines/_dryrun?pipeline_name=test" \
-H "Content-Type: application/json" \
-H "Authorization: Basic {{authentication}}" \
-d $'{"message": "1998.08","time":"2024-05-25 20:16:37.217"}'
```
此时 Pipeline 处理成功,输出如下:
```json
[
{
"rows": [
[
{
"data_type": "STRING",
"key": "message",
"semantic_type": "FIELD",
"value": "1998-08"
},
{
"data_type": "TIMESTAMP_NANOSECOND",
"key": "time",
"semantic_type": "TIMESTAMP",
"value": 1716668197217000000
}
]
],
"schema": [
{
"column_type": "FIELD",
"data_type": "STRING",
"fulltext": false,
"name": "message"
},
{
"column_type": "TIMESTAMP",
"data_type": "TIMESTAMP_NANOSECOND",
"fulltext": false,
"name": "time"
}
],
"table_name": "dry_run"
}
]
```
可以看到,`1998.08` 字符串中的 `.` 已经被替换为 `-`,Pipeline 处理成功。
## 从 Pipeline 配置生成表的建表语句
使用 Pipeline 时,GreptimeDB 默认会在首次数据写入时自动创建目标表。
但是,你可能希望预先手动创建表以添加自定义表选项,例如添加分区规则以获得更好的性能。
虽然自动创建的表结构对于给定的 Pipeline 配置是确定的,
但根据配置手动编写表的建表语句可能会很繁琐。`/ddl` API 简化了这一过程。
对于现有的 Pipeline,你可以使用 `/v1/pipelines/{pipeline_name}/ddl` 来生成建表语句。
此 API 会检查 Pipeline 配置中的 transform 定义并推断出相应的表结构。
你可以在第一次写入数据之前使用此 API 来生成基础的建表语句,进行参数调整并手动建表。
常见的调整选项包括:
- 增加[数据分区规则](/user-guide/deployments-administration/manage-data/table-sharding.md)
- 调整[索引的参数](/user-guide/manage-data/data-index.md)
- 增加其他[表选项](/reference/sql/create.md#表选项)
以下是演示如何使用此 API 的示例。考虑以下 Pipeline 配置:
```YAML
# pipeline.yaml
processors:
- dissect:
fields:
- message
patterns:
- '%{ip_address} - %{username} [%{timestamp}] "%{http_method} %{request_line} %{protocol}" %{status_code} %{response_size}'
ignore_missing: true
- date:
fields:
- timestamp
formats:
- "%d/%b/%Y:%H:%M:%S %z"
transform:
- fields:
- timestamp
type: time
index: timestamp
- fields:
- ip_address
type: string
index: skipping
- fields:
- username
type: string
tag: true
- fields:
- http_method
type: string
index: inverted
- fields:
- request_line
type: string
index: fulltext
- fields:
- protocol
type: string
- fields:
- status_code
type: int32
index: inverted
tag: true
- fields:
- response_size
type: int64
on_failure: default
default: 0
- fields:
- message
type: string
```
首先,使用以下命令将 Pipeline 上传到数据库:
```bash
curl -X "POST" "http://localhost:4000/v1/pipelines/pp" -F "file=@pipeline.yaml"
```
然后,使用以下命令查询表的建表语句:
```bash
curl -X "GET" "http://localhost:4000/v1/pipelines/pp/ddl?table=test_table"
```
API 返回以下 JSON 格式的输出:
```JSON
{
"sql": {
"sql": "CREATE TABLE IF NOT EXISTS `test_table` (\n `timestamp` TIMESTAMP(9) NOT NULL,\n `ip_address` STRING NULL SKIPPING INDEX WITH(false_positive_rate = '0.01', granularity = '10240', type = 'BLOOM'),\n `username` STRING NULL,\n `http_method` STRING NULL INVERTED INDEX,\n `request_line` STRING NULL FULLTEXT INDEX WITH(analyzer = 'English', backend = 'bloom', case_sensitive = 'false', false_positive_rate = '0.01', granularity = '10240'),\n `protocol` STRING NULL,\n `status_code` INT NULL INVERTED INDEX,\n `response_size` BIGINT NULL,\n `message` STRING NULL,\n TIME INDEX (`timestamp`),\n PRIMARY KEY (`username`, `status_code`)\n)\nENGINE=mito\nWITH(\n append_mode = 'true'\n)"
},
"execution_time_ms": 3
}
```
格式化响应中的 `sql` 字段后,你可以看到推断出的表结构:
```SQL
CREATE TABLE IF NOT EXISTS `test_table` (
`timestamp` TIMESTAMP(9) NOT NULL,
`ip_address` STRING NULL SKIPPING INDEX WITH(false_positive_rate = '0.01', granularity = '10240', type = 'BLOOM'),
`username` STRING NULL,
`http_method` STRING NULL INVERTED INDEX,
`request_line` STRING NULL FULLTEXT INDEX WITH(analyzer = 'English', backend = 'bloom', case_sensitive = 'false', false_positive_rate = '0.01', granularity = '10240'),
`protocol` STRING NULL,
`status_code` INT NULL INVERTED INDEX,
`response_size` BIGINT NULL,
`message` STRING NULL,
TIME INDEX (`timestamp`),
PRIMARY KEY (`username`, `status_code`)
)
ENGINE=mito
WITH(
append_mode = 'true'
)
```
你可以将推断出的表的建表语句作为起点。
根据你的需求自定义建表语句后,在通过 Pipeline 写入数据之前手动执行它。
**注意事项:**
1. 该 API 仅从 Pipeline 配置推断表结构;它不会检查表是否已存在。
2. 该 API 不考虑表后缀。如果你在 Pipeline 配置中使用 `dispatcher`、`table_suffix` 或表后缀 hint,你需要手动调整表名。
---
## 日志
GreptimeDB 提供了专为满足现代可观测需求而设计的日志管理解决方案,
它可以和主流日志收集器无缝集成,
提供了灵活的使用 pipeline 转换日志的功能
和包括全文搜索的查询功能。
核心功能点包括:
- **统一存储**:将日志与指标和 Trace 数据一起存储在单个数据库中
- **Pipeline 处理数据**:使用可自定义的 pipeline 转换和丰富原始日志,支持多种日志收集器和格式
- **高级查询**:基于 SQL 的分析,并具有全文搜索功能
- **实时数据处理**:实时处理和查询日志以进行监控和警报
## 日志收集流程

上图展示了日志收集的整体架构,
它包括四阶段流程:日志源、日志收集器、Pipeline 处理和在存储到 GreptimeDB 中。
### 日志源
日志源是基础设施中产生日志数据的基础层。
GreptimeDB 支持从各种源写入数据以满足全面的可观测性需求:
- **应用程序**:来自微服务架构、Web 应用程序、移动应用程序和自定义软件组件的应用程序级日志
- **IoT 设备**:来自物联网生态系统的设备日志、传感器事件日志和运行状态日志
- **基础设施**:云平台日志、容器编排日志(Kubernetes、Docker)、负载均衡器日志以及网络基础设施组件日志
- **系统组件**:操作系统日志、内核事件、系统守护进程日志以及硬件监控日志
- **自定义源**:特定于你环境或应用程序的任何其他日志源
### 日志收集器
日志收集器负责高效地从各种源收集日志数据并转发到存储后端。
GreptimeDB 可以与行业标准的日志收集器无缝集成,
包括 Vector、Fluent Bit、Apache Kafka、OpenTelemetry Collector 等。
GreptimeDB 作为这些收集器的 sink 后端,
提供强大的数据写入能力。
在写入过程中,GreptimeDB 的 pipeline 系统能够实时转换和丰富日志数据,
确保在存储前获得最佳的结构和质量。
### Pipeline 处理
GreptimeDB 的 pipeline 机制将原始日志转换为结构化、可查询的数据:
- **解析**:从非结构化日志消息中提取结构化数据
- **转换**:使用额外的上下文和元数据丰富日志
- **索引**:配置必要的索引以提升查询性能,例如全文索引、时间索引等
### 存储日志到 GreptimeDB
通过 pipeline 处理后,日志存储在 GreptimeDB 中,支持灵活的分析和可视化:
- **SQL 查询**:使用熟悉的 SQL 语法分析日志数据
- **基于时间的分析**:利用时间序列功能进行时间分析
- **全文搜索**:在日志消息中执行高级文本搜索
- **实时分析**:实时查询日志进行监控和告警
## 快速开始
你可以使用内置的 `greptime_identity` pipeline 快速开始日志写入。更多信息请参考[快速开始](./quick-start.md)指南。
## 集成到日志收集器
GreptimeDB 与各种日志收集器无缝集成,提供全面的日志记录解决方案。集成过程包括以下关键步骤:
1. **选择合适的日志收集器**:根据你的基础设施要求、数据源和性能需求选择收集器
2. **分析输出格式**:了解你选择的收集器产生的日志格式和结构
3. **配置 Pipeline**:在 GreptimeDB 中创建和配置 pipeline 来解析、转换和丰富传入的日志数据
4. **存储和查询**:在 GreptimeDB 中高效存储处理后的日志,用于实时分析和监控
要成功将你的日志收集器与 GreptimeDB 集成,你需要:
- 首先了解 pipeline 在 GreptimeDB 中的工作方式
- 然后在你的日志收集器中配置 sink 设置,将数据发送到 GreptimeDB
请参考以下指南获取将 GreptimeDB 集成到日志收集器的详细说明:
- [Vector](/user-guide/ingest-data/for-observability/vector.md#using-greptimedb_logs-sink-recommended)
- [Kafka](/user-guide/ingest-data/for-observability/kafka.md#logs)
- [Fluent Bit](/user-guide/ingest-data/for-observability/fluent-bit.md#http)
- [OpenTelemetry Collector](/user-guide/ingest-data/for-observability/otel-collector.md)
- [Loki](/user-guide/ingest-data/for-observability/loki.md#using-pipeline-with-loki-push-api)
## 了解更多关于 Pipeline 的信息
- [使用自定义 Pipeline](./use-custom-pipelines.md):解释如何创建和使用自定义 pipeline 进行日志写入。
- [管理 Pipeline](./manage-pipelines.md):解释如何创建和删除 pipeline。
## 查询日志
- [全文搜索](./fulltext-search.md):使用 GreptimeDB 查询语言有效搜索和分析日志数据的指南。
## 参考
- [内置 Pipeline](/reference/pipeline/built-in-pipelines.md):GreptimeDB 为日志写入提供的内置 pipeline 详细信息。
- [写入日志的 API](/reference/pipeline/write-log-api.md):描述向 GreptimeDB 写入日志的 HTTP API。
- [Pipeline 配置](/reference/pipeline/pipeline-config.md):提供 GreptimeDB 中 pipeline 各项具体配置的信息。
---
## GreptimeDB Logs 快速上手
# 快速入门
本指南将引导你完成使用 GreptimeDB 日志服务的基本步骤。
你将学习如何使用内置的 `greptime_identity` pipeline 写入日志并集成日志收集器。
GreptimeDB 提供了强大的基于 pipeline 的日志写入系统。
你可以使用内置的 `greptime_identity` pipeline 快速写入 JSON 格式的日志,
该 pipeline 具有以下特点:
- 自动处理从 JSON 到表列的字段映射
- 如果表不存在则自动创建表
- 灵活支持变化的日志结构
- 需要最少的配置即可开始使用
## 直接通过 HTTP 写入日志
GreptimeDB 日志写入最简单的方法是通过使用 `greptime_identity` pipeline 发送 HTTP 请求。
例如,你可以使用 `curl` 发送带有 JSON 日志数据的 POST 请求:
```shell
curl -X POST \
"http://localhost:4000/v1/ingest?db=public&table=demo_logs&pipeline_name=greptime_identity" \
-H "Content-Type: application/json" \
-H "Authorization: Basic {{authentication}}" \
-d '[
{
"timestamp": "2024-01-15T10:30:00Z",
"level": "INFO",
"service": "web-server",
"message": "用户登录成功",
"user_id": 12345,
"ip_address": "192.168.1.100"
},
{
"timestamp": "2024-01-15T10:31:00Z",
"level": "ERROR",
"service": "database",
"message": "连接超时",
"error_code": 500,
"retry_count": 3
}
]'
```
关键参数包括:
- `db=public`:目标数据库名称(你的数据库名称)
- `table=demo_logs`:目标表名称(如果不存在则自动创建)
- `pipeline_name=greptime_identity`:使用 `greptime_identity` pipeline 进行 JSON 处理
- `Authorization` 头:使用 base64 编码的 `username:password` 进行基本身份验证,请参阅 [HTTP 鉴权指南](/user-guide/protocols/http.md#authentication)
成功的请求返回:
```json
{
"output": [{"affectedrows": 2}],
"execution_time_ms": 15
}
```
成功写入日志后,
相应的表 `demo_logs` 会根据 JSON 字段自动创建相应的列,其 schema 如下:
```sql
+--------------------+---------------------+------+------+---------+---------------+
| Column | Type | Key | Null | Default | Semantic Type |
+--------------------+---------------------+------+------+---------+---------------+
| greptime_timestamp | TimestampNanosecond | PRI | NO | | TIMESTAMP |
| ip_address | String | | YES | | FIELD |
| level | String | | YES | | FIELD |
| message | String | | YES | | FIELD |
| service | String | | YES | | FIELD |
| timestamp | String | | YES | | FIELD |
| user_id | Int64 | | YES | | FIELD |
| error_code | Int64 | | YES | | FIELD |
| retry_count | Int64 | | YES | | FIELD |
+--------------------+---------------------+------+------+---------+---------------+
```
## 与日志收集器集成
对于生产环境,
你通常会使用日志收集器自动将日志转发到 GreptimeDB。
以下是如何配置 Vector 使用 `greptime_identity` pipeline 向 GreptimeDB 发送日志的示例:
```toml
[sinks.my_sink_id]
type = "greptimedb_logs"
dbname = "public"
endpoint = "http://:4000"
pipeline_name = "greptime_identity"
table = ""
username = ""
password = ""
# 根据需要添加其他配置
```
关键配置参数包括:
- `type = "greptimedb_logs"`:指定 GreptimeDB 日志接收器
- `dbname`:目标数据库名称
- `endpoint`:GreptimeDB HTTP 端点
- `pipeline_name`:使用 `greptime_identity` pipeline 进行 JSON 处理
- `table`:目标表名称(如果不存在则自动创建)
- `username` 和 `password`:HTTP 基本身份验证的凭证
有关 Vector 配置和选项的详细信息,
请参阅 [Vector 集成指南](/user-guide/ingest-data/for-observability/vector.md#使用-greptimedb_logs-sink-推荐)。
## 下一步
你已成功写入了第一批日志,以下是推荐的后续步骤:
- **了解更多关于内置 Pipeline 的行为**:请参阅[内置 Pipeline](/reference/pipeline/built-in-pipelines.md)指南,了解可用的内置 pipeline 及其配置的详细信息
- **与流行的日志收集器集成**:有关将 GreptimeDB 与 Fluent Bit、Fluentd 等各种日志收集器集成的详细说明,请参阅[日志概览](./overview.md)中的[集成到日志收集器](./overview.md#集成到日志收集器)部分
- **使用自定义 Pipeline**:要了解使用自定义 pipeline 进行高级日志处理和转换的信息,请参阅[使用自定义 Pipeline](./use-custom-pipelines.md)指南
---
## 使用自定义 Pipeline
基于你的 pipeline 配置,
GreptimeDB 能够将日志自动解析和转换为多列的结构化数据,
当内置 pipeline 无法处理特定的文本日志格式时,
你可以创建自定义 pipeline 来定义如何根据你的需求解析和转换日志数据。
## 识别你的原始日志格式
在创建自定义 pipeline 之前,了解原始日志数据的格式至关重要。
如果你正在使用日志收集器且不确定日志格式,
有两种方法可以检查你的日志:
1. **阅读收集器的官方文档**:配置你的收集器将数据输出到控制台或文件以检查日志格式。
2. **使用 `greptime_identity` pipeline**:使用内置的 `greptime_identity` pipeline 将示例日志直接写入到 GreptimeDB 中。
`greptime_identity` pipeline 将整个文本日志视为单个 `message` 字段,方便你直接看到原始日志的内容。
一旦了解了要处理的日志格式,
你就可以创建自定义 pipeline。
本文档使用以下 Nginx 访问日志条目作为示例:
```txt
127.0.0.1 - - [25/May/2024:20:16:37 +0000] "GET /index.html HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
```
## 创建自定义 Pipeline
GreptimeDB 提供 HTTP 接口用于创建 pipeline。
以下是创建方法。
首先,创建一个示例 pipeline 配置文件来处理 Nginx 访问日志,
将其命名为 `pipeline.yaml`:
```yaml
version: 2
processors:
- dissect:
fields:
- message
patterns:
- '%{ip_address} - - [%{timestamp}] "%{http_method} %{request_line}" %{status_code} %{response_size} "-" "%{user_agent}"'
ignore_missing: true
- date:
fields:
- timestamp
formats:
- "%d/%b/%Y:%H:%M:%S %z"
- select:
type: exclude
fields:
- message
- vrl:
source: |
.greptime_ttl = "7d"
.
transform:
- fields:
- ip_address
type: string
index: inverted
tag: true
- fields:
- status_code
type: int32
index: inverted
tag: true
- fields:
- request_line
- user_agent
type: string
index: fulltext
- fields:
- response_size
type: int32
- fields:
- timestamp
type: time
index: timestamp
```
上面的 pipeline 配置使用 [version 2](/reference/pipeline/pipeline-config.md#transform-in-version-2) 格式,
包含 `processors` 和 `transform` 部分来结构化你的日志数据:
**Processors**:用于在转换前预处理日志数据:
- **数据提取**:`dissect` 处理器使用 pattern 匹配来解析 `message` 字段并提取结构化数据,包括 `ip_address`、`timestamp`、`http_method`、`request_line`、`status_code`、`response_size` 和 `user_agent`。
- **时间戳处理**:`date` 处理器使用格式 `%d/%b/%Y:%H:%M:%S %z` 解析提取的 `timestamp` 字段并将其转换为适当的时间戳数据类型。
- **字段选择**:`select` 处理器从最终输出中排除原始 `message` 字段,同时保留所有其他字段。
- **表选项**:`vrl` 处理器根据提取的字段设置表选项,例如向表名添加后缀和设置 TTL。`greptime_ttl = "7d"` 配置表数据的保存时间为 7 天。
**Transform**:定义如何转换和索引提取的字段:
- **字段转换**:每个提取的字段都转换为适当的数据类型并根据需要配置相应的索引。像 `http_method` 这样的字段在没有提供显式配置时保留其默认数据类型。
- **索引策略**:
- `ip_address` 和 `status_code` 使用倒排索引作为标签进行快速过滤
- `request_line` 和 `user_agent` 使用全文索引以获得最佳文本搜索能力
- `timestamp` 是必需的时间索引列
有关 pipeline 配置选项的详细信息,
请参考 [Pipeline 配置](/reference/pipeline/pipeline-config.md) 文档。
## 上传 Pipeline
执行以下命令上传 pipeline 配置:
```shell
curl -X "POST" \
"http://localhost:4000/v1/pipelines/nginx_pipeline" \
-H 'Authorization: Basic {{authentication}}' \
-F "file=@pipeline.yaml"
```
成功执行后,将创建一个名为 `nginx_pipeline` 的 pipeline 并返回以下结果:
```json
{"name":"nginx_pipeline","version":"2024-06-27 12:02:34.257312110Z"}.
```
你可以为同一个 pipeline 名称创建多个版本。
所有 pipeline 都存储在 `greptime_private.pipelines` 表中。
参考[查询 Pipeline](manage-pipelines.md#查询-pipeline) 来查看 pipeline 数据。
## 使用 Pipeline 写入日志
以下示例使用 `nginx_pipeline` pipeline 将日志写入 `custom_pipeline_logs` 表来格式化和转换日志消息:
```shell
curl -X POST \
"http://localhost:4000/v1/ingest?db=public&table=custom_pipeline_logs&pipeline_name=nginx_pipeline" \
-H "Content-Type: application/json" \
-H "Authorization: Basic {{authentication}}" \
-d '[
{
"message": "127.0.0.1 - - [25/May/2024:20:16:37 +0000] \"GET /index.html HTTP/1.1\" 200 612 \"-\" \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\""
},
{
"message": "192.168.1.1 - - [25/May/2024:20:17:37 +0000] \"POST /api/login HTTP/1.1\" 200 1784 \"-\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36\""
},
{
"message": "10.0.0.1 - - [25/May/2024:20:18:37 +0000] \"GET /images/logo.png HTTP/1.1\" 304 0 \"-\" \"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:89.0) Gecko/20100101 Firefox/89.0\""
},
{
"message": "172.16.0.1 - - [25/May/2024:20:19:37 +0000] \"GET /contact HTTP/1.1\" 404 162 \"-\" \"Mozilla/5.0 (iPhone; CPU iPhone OS 14_0 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0 Mobile/15E148 Safari/604.1\""
}
]'
```
命令执行成功后将返回以下输出:
```json
{"output":[{"affectedrows":4}],"execution_time_ms":79}
```
`custom_pipeline_logs` 表内容根据 pipeline 配置自动创建:
```sql
+-------------+-------------+-------------+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------------+---------------+---------------------+
| ip_address | http_method | status_code | request_line | user_agent | response_size | timestamp |
+-------------+-------------+-------------+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------------+---------------+---------------------+
| 10.0.0.1 | GET | 304 | /images/logo.png HTTP/1.1 | Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:89.0) Gecko/20100101 Firefox/89.0 | 0 | 2024-05-25 20:18:37 |
| 127.0.0.1 | GET | 200 | /index.html HTTP/1.1 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 | 612 | 2024-05-25 20:16:37 |
| 172.16.0.1 | GET | 404 | /contact HTTP/1.1 | Mozilla/5.0 (iPhone; CPU iPhone OS 14_0 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0 Mobile/15E148 Safari/604.1 | 162 | 2024-05-25 20:19:37 |
| 192.168.1.1 | POST | 200 | /api/login HTTP/1.1 | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36 | 1784 | 2024-05-25 20:17:37 |
+-------------+-------------+-------------+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------------+---------------+---------------------+
```
有关日志写入 API 端点 `/ingest` 的更详细信息,
包括附加参数和配置选项,
请参考[日志写入 API](/reference/pipeline/write-log-api.md) 文档。
## 查询日志
我们使用 `custom_pipeline_logs` 表作为示例来查询日志。
### 通过 tag 查询日志
通过 `custom_pipeline_logs` 中的多个 tag 列,
你可以灵活地通过 tag 查询数据。
例如,查询 `status_code` 为 200 且 `http_method` 为 GET 的日志。
```sql
SELECT * FROM custom_pipeline_logs WHERE status_code = 200 AND http_method = 'GET';
```
```sql
+------------+-------------+----------------------+---------------------------------------------------------------------------------------------------------------------+---------------+---------------------+-------------+
| ip_address | status_code | request_line | user_agent | response_size | timestamp | http_method |
+------------+-------------+----------------------+---------------------------------------------------------------------------------------------------------------------+---------------+---------------------+-------------+
| 127.0.0.1 | 200 | /index.html HTTP/1.1 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 | 612 | 2024-05-25 20:16:37 | GET |
+------------+-------------+----------------------+---------------------------------------------------------------------------------------------------------------------+---------------+---------------------+-------------+
1 row in set (0.02 sec)
```
### 全文搜索
对于文本字段 `request_line` 和 `user_agent`,你可以使用 `matches_term` 函数来搜索日志。
还记得我们在[创建 pipeline](#create-a-pipeline) 时为这两列创建了全文索引。
这带来了高性能的全文搜索。
例如,查询 `request_line` 列包含 `/index.html` 或 `/api/login` 的日志。
```sql
SELECT * FROM custom_pipeline_logs WHERE matches_term(request_line, '/index.html') OR matches_term(request_line, '/api/login');
```
```sql
+-------------+-------------+----------------------+--------------------------------------------------------------------------------------------------------------------------+---------------+---------------------+-------------+
| ip_address | status_code | request_line | user_agent | response_size | timestamp | http_method |
+-------------+-------------+----------------------+--------------------------------------------------------------------------------------------------------------------------+---------------+---------------------+-------------+
| 127.0.0.1 | 200 | /index.html HTTP/1.1 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 | 612 | 2024-05-25 20:16:37 | GET |
| 192.168.1.1 | 200 | /api/login HTTP/1.1 | Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36 | 1784 | 2024-05-25 20:17:37 | POST |
+-------------+-------------+----------------------+--------------------------------------------------------------------------------------------------------------------------+---------------+---------------------+-------------+
2 rows in set (0.00 sec)
```
你可以参考[全文搜索](fulltext-search.md) 文档了解 `matches_term` 函数的详细用法。
## 使用 Pipeline 的好处
使用 pipeline 处理日志带来了结构化的数据和自动的字段提取,
这使得查询和分析更加高效。
你也可以在没有 pipeline 的情况下直接将日志写入数据库,
但这种方法限制了高性能分析能力。
### 直接插入日志(不使用 Pipeline)
为了比较,你可以创建一个表来存储原始日志消息:
```sql
CREATE TABLE `origin_logs` (
`message` STRING FULLTEXT INDEX,
`time` TIMESTAMP TIME INDEX
) WITH (
append_mode = 'true'
);
```
使用 `INSERT` 语句将日志插入表中。
注意你需要为每个日志手动添加时间戳字段:
```sql
INSERT INTO origin_logs (message, time) VALUES
('127.0.0.1 - - [25/May/2024:20:16:37 +0000] "GET /index.html HTTP/1.1" 200 612 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"', '2024-05-25 20:16:37.217'),
('192.168.1.1 - - [25/May/2024:20:17:37 +0000] "POST /api/login HTTP/1.1" 200 1784 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36"', '2024-05-25 20:17:37.217'),
('10.0.0.1 - - [25/May/2024:20:18:37 +0000] "GET /images/logo.png HTTP/1.1" 304 0 "-" "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:89.0) Gecko/20100101 Firefox/89.0"', '2024-05-25 20:18:37.217'),
('172.16.0.1 - - [25/May/2024:20:19:37 +0000] "GET /contact HTTP/1.1" 404 162 "-" "Mozilla/5.0 (iPhone; CPU iPhone OS 14_0 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0 Mobile/15E148 Safari/604.1"', '2024-05-25 20:19:37.217');
```
### 表结构比较:Pipeline 转换后 vs 原始日志
在上面的示例中,表 `custom_pipeline_logs` 是通过使用 pipeline 写入日志自动创建的,
而表 `origin_logs` 是通过直接写入日志创建的。
让我们看一看这两个表之间的差异。
```sql
DESC custom_pipeline_logs;
```
```sql
+---------------+---------------------+------+------+---------+---------------+
| Column | Type | Key | Null | Default | Semantic Type |
+---------------+---------------------+------+------+---------+---------------+
| ip_address | String | PRI | YES | | TAG |
| status_code | Int32 | PRI | YES | | TAG |
| request_line | String | | YES | | FIELD |
| user_agent | String | | YES | | FIELD |
| response_size | Int32 | | YES | | FIELD |
| timestamp | TimestampNanosecond | PRI | NO | | TIMESTAMP |
| http_method | String | | YES | | FIELD |
+---------------+---------------------+------+------+---------+---------------+
7 rows in set (0.00 sec)
```
```sql
DESC origin_logs;
```
```sql
+---------+----------------------+------+------+---------+---------------+
| Column | Type | Key | Null | Default | Semantic Type |
+---------+----------------------+------+------+---------+---------------+
| message | String | | YES | | FIELD |
| time | TimestampMillisecond | PRI | NO | | TIMESTAMP |
+---------+----------------------+------+------+---------+---------------+
```
以上表结构显示了关键差异:
`custom_pipeline_logs` 表(使用 pipeline 创建)自动将日志数据结构化为多列:
- `ip_address`、`status_code` 作为索引标签用于快速过滤
- `request_line`、`user_agent` 具有全文索引用于文本搜索
- `response_size`、`http_method` 作为常规字段
- `timestamp` 作为时间索引
`origin_logs` 表(直接插入)将所有内容存储在单个 `message` 列中。
### 为什么使用 Pipeline?
建议使用 pipeline 方法将日志消息拆分为多列,
这具有明确查询特定列中特定值的优势。
有几个关键原因使得基于列的匹配查询比全文搜索更优越:
- **性能**:基于列的查询通常比全文搜索更快
- **存储效率**:GreptimeDB 的列式存储能更好地压缩结构化数据;标签的倒排索引比全文索引消耗更少的存储空间
- **查询简单性**:基于标签的查询更容易编写、理解和调试
## 下一步
- **全文搜索**:阅读[全文搜索](fulltext-search.md) 指南,了解 GreptimeDB 中的高级文本搜索功能和查询技术
- **Pipeline 配置**:阅读 [Pipeline 配置](/reference/pipeline/pipeline-config.md) 文档,了解更多关于为各种日志格式和处理需求创建和自定义 pipeline 的信息
---
## 数据索引
GreptimeDB 提供了多种索引机制来提升查询性能。作为数据库中的核心组件,索引通过建立高效的数据检索路径,显著优化了数据的查询操作。
## 概述
在 GreptimeDB 中,索引是在表创建时定义的,其设计目的是针对不同的数据类型和查询模式来优化查询性能。目前支持的索引类型包括:
- 倒排索引(Inverted Index)
- 跳数索引(Skipping Index)
- 全文索引(Fulltext Index)
需要说明的是,本章节重点讨论数据值索引。虽然主键(PRIMARY KEY)和 TIME INDEX 也在某种程度上具有索引的特性,但不在本章讨论范围内。
## 索引类型
### 倒排索引
倒排索引主要用于优化 Tag 列的查询效率。它通过在唯一值和对应数据行之间建立映射关系,实现对特定标签值的快速定位。
Tag 列不会被自动建立倒排索引,
你需要考虑以下使用场景手动为 Tag 列建立倒排索引:
- 基于标签值的数据查询
- 字符串列的过滤操作
- Tag 列的精确查询
示例:
```sql
CREATE TABLE monitoring_data (
host STRING INVERTED INDEX,
`region` STRING PRIMARY KEY INVERTED INDEX,
cpu_usage DOUBLE,
`timestamp` TIMESTAMP TIME INDEX,
);
```
需要注意的是,当列的基数非常大时,倒排索引可能会带来较高的维护成本,导致内存占用增加和索引体积膨胀。这种情况下,建议考虑使用跳数索引作为替代方案。
### 跳数索引
跳数索引是专为列式存储系统(如 GreptimeDB)优化设计的索引类型。它通过维护数据块内值域范围的元数据,使查询引擎能够在进行范围查询时快速跳过不相关的数据块。与其他索引相比,跳数索引的存储开销相对较小。
**适用场景:**
- 数据分布稀疏的场景,例如日志中的 MAC 地址
- 在大规模数据集中查询出现频率较低的值
示例:
```sql
CREATE TABLE sensor_data (
`domain` STRING PRIMARY KEY,
device_id STRING SKIPPING INDEX,
temperature DOUBLE,
`timestamp` TIMESTAMP TIME INDEX,
);
```
跳数索引支持 `WITH` 选项:
* `type`: 索引类型,目前仅支持 `BLOOM` 类型。
* `granularity`: (适用于 `BLOOM` 类型)每个过滤器覆盖的数据块大小。粒度越小,过滤效果越好,但索引大小会增加。默认为 `10240`。
* `false_positive_rate`: (适用于 `BLOOM` 类型)错误识别块的概率。该值越低,准确性越高(过滤效果越好),但索引大小会增加。该值为介于 `0` 和 `1` 之间的浮点数。默认为 `0.01`。
例如:
```sql
CREATE TABLE sensor_data (
`domain` STRING PRIMARY KEY,
device_id STRING SKIPPING INDEX WITH(type='BLOOM', granularity=1024, false_positive_rate=0.01),
temperature DOUBLE,
`timestamp` TIMESTAMP TIME INDEX,
);
```
然而,跳数索引无法处理复杂的过滤条件,并且其过滤性能通常不如倒排索引或全文索引。
### 全文索引
全文索引专门用于优化字符串列的文本搜索操作。它支持基于词的匹配和文本搜索功能,能够实现对文本内容的高效检索。你可以使用灵活的关键词、短语或模式匹配来查询文本数据。
**适用场景:**
- 文本内容搜索
- 模式匹配查询
- 大规模文本过滤
示例:
```sql
CREATE TABLE logs (
`message` STRING FULLTEXT INDEX,
`level` STRING PRIMARY KEY,
`timestamp` TIMESTAMP TIME INDEX,
);
```
#### 配置选项
在创建或修改全文索引时,您可以使用 `FULLTEXT INDEX WITH` 指定以下选项:
- `analyzer`:设置全文索引的语言分析器
- 支持的值:`English`、`Chinese`
- 默认值:`English`
- 注意:由于中文文本分词的复杂性,中文分析器构建索引需要的时间显著更长。建议仅在中文文本搜索是主要需求时使用。
- `case_sensitive`:决定全文索引是否区分大小写
- 支持的值:`true`、`false`
- 默认值:`false`
- 注意:设置为 `true` 可能会略微提高区分大小写查询的性能,但会降低不区分大小写查询的性能。此设置不会影响 `matches_term` 查询的结果。
- `backend`:设置全文索引的后端实现
- 支持的值:`bloom`、`tantivy`
- 默认值:`bloom`
- `granularity`:(适用于 `bloom` 后端)每个过滤器覆盖的数据块大小。粒度越小,过滤效果越好,但索引大小会增加。
- 支持的值:正整数
- 默认值:`10240`
- `false_positive_rate`:(适用于 `bloom` 后端)错误识别块的概率。该值越低,准确性越高(过滤效果越好),但索引大小会增加。该值为介于 `0` 和 `1` 之间的浮点数。
- 支持的值:介于 `0` 和 `1` 之间的浮点数
- 默认值:`0.01`
#### 后端选择
GreptimeDB 提供两种全文索引后端用于高效日志搜索:
1. **Bloom 后端**
- 最适合:通用日志搜索
- 特点:
- 使用 Bloom 过滤器进行高效过滤
- 存储开销较低
- 在不同查询模式下性能稳定
- 限制:
- 对于高选择性查询稍慢
- 存储成本示例:
- 原始数据:约 10GB
- Bloom 索引:约 1GB
2. **Tantivy 后端**
- 最适合:高选择性查询(如 TraceID 等唯一值)
- 特点:
- 使用倒排索引实现快速精确匹配
- 对高选择性查询性能优异
- 限制:
- 存储开销较高(接近原始数据大小)
- 对低选择性查询性能较慢
- 存储成本示例:
- 原始数据:约 10GB
- Tantivy 索引:约 10GB
#### 性能对比
下表显示了不同查询方法之间的性能对比(以 Bloom 为基准):
| 查询类型 | 高选择性(如 TraceID) | 低选择性(如 "HTTP") |
|------------|----------------------------------|--------------------------------|
| LIKE | 慢 50 倍 | 1 倍 |
| Tantivy | 快 5 倍 | 慢 5 倍 |
| Bloom | 1 倍(基准) | 1 倍(基准) |
主要观察结果:
- 对于高选择性查询(如唯一值),Tantivy 提供最佳性能
- 对于低选择性查询,Bloom 提供更稳定的性能
- Bloom 在存储方面比 Tantivy 有明显优势(测试案例中为 1GB vs 10GB)
#### 配置示例
**创建带全文索引的表**
```sql
-- 使用 Bloom 后端(大多数情况推荐)
CREATE TABLE logs (
timestamp TIMESTAMP(9) TIME INDEX,
`message` STRING FULLTEXT INDEX WITH (
backend = 'bloom',
analyzer = 'English',
case_sensitive = 'false'
)
);
-- 使用 Tantivy 后端(用于高选择性查询)
CREATE TABLE logs (
timestamp TIMESTAMP(9) TIME INDEX,
`message` STRING FULLTEXT INDEX WITH (
backend = 'tantivy',
analyzer = 'English',
case_sensitive = 'false'
)
);
```
**修改现有表**
```sql
-- 在现有列上启用全文索引
ALTER TABLE monitor
MODIFY COLUMN load_15
SET FULLTEXT INDEX WITH (
analyzer = 'English',
case_sensitive = 'false',
backend = 'bloom'
);
-- 更改全文索引配置
ALTER TABLE logs
MODIFY COLUMN message
SET FULLTEXT INDEX WITH (
analyzer = 'English',
case_sensitive = 'false',
backend = 'tantivy'
);
```
## 修改索引
你可以随时通过`ALTER TABLE`语句来更改列的索引类型,阅读[文档](/reference/sql/alter#alter-table)以获取更多信息。
## 最佳实践
1. 根据实际的数据特征和查询模式选择合适的索引类型
2. 只为频繁出现在 WHERE 子句中的列创建索引
3. 在查询性能、写入性能和资源消耗之间寻找平衡
4. 定期监控索引使用情况并持续优化索引策略
## 性能考虑
索引虽然能够显著提升查询性能,但也会带来一定开销:
- 需要额外的存储空间维护索引结构
- 索引维护会影响数据刷新和压缩性能
- 索引缓存会占用系统内存
建议根据具体应用场景和性能需求,合理规划索引策略。
---
## 管理数据(Manage-data)
## 更新数据
### 使用相同的 tag 和 time index 更新数据
更新操作可以通过插入操作来实现。
如果某行数据具有相同的 tag 和 time index,旧数据将被新数据替换,这意味着你只能更新 field 类型的列。
想要更新数据,只需使用与现有数据相同的 tag 和 time index 插入新数据即可。
有关列类型的更多信息,请参阅[数据模型](/user-guide/concepts/data-model.md)。
:::warning 注意
尽管更新操作的性能与插入数据相同,过多的更新可能会对查询性能产生负面影响。
:::
#### 更新表中的所有字段
在更新数据时,默认情况下所有字段都将被新值覆盖,
而 [InfluxDB 行协议](/user-guide/protocols/influxdb-line-protocol.md) 除外,它只会[更新表中的部分字段](#更新表中的部分字段)。
以下示例使用 SQL 演示了更新表中所有字段的行为。
假设你有一个名为 `monitor` 的表,具有以下 schema。
`host` 列表示 tag,`ts` 列表示 time index。
```sql
CREATE TABLE monitor (
host STRING,
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP() TIME INDEX,
cpu FLOAT64,
memory FLOAT64,
PRIMARY KEY(host)
);
```
向 `monitor` 表中插入一行新数据:
```sql
INSERT INTO monitor (host, ts, cpu, memory)
VALUES ("127.0.0.1", "2024-07-11 20:00:00", 0.8, 0.1);
```
检查表中的数据:
```sql
SELECT * FROM monitor;
```
```sql
+-----------+---------------------+------+--------+
| host | ts | cpu | memory |
+-----------+---------------------+------+--------+
| 127.0.0.1 | 2024-07-11 20:00:00 | 0.8 | 0.1 |
+-----------+---------------------+------+--------+
1 row in set (0.00 sec)
```
要更新数据,你可以使用与现有数据相同的 `host` 和 `ts` 值,并将新的 `cpu` 值设置为 `0.5`:
```sql
INSERT INTO monitor (host, ts, cpu, memory)
-- 与现有数据相同的标签 `127.0.0.1` 和相同的时间索引 2024-07-11 20:00:00
VALUES ("127.0.0.1", "2024-07-11 20:00:00", 0.5, 0.1);
```
新数据将为:
```sql
SELECT * FROM monitor;
```
```sql
+-----------+---------------------+------+--------+
| host | ts | cpu | memory |
+-----------+---------------------+------+--------+
| 127.0.0.1 | 2024-07-11 20:00:00 | 0.5 | 0.1 |
+-----------+---------------------+------+--------+
1 row in set (0.01 sec)
```
当使用默认的合并策略时,
如果在 `INSERT INTO` 语句中省略了某列,
它们将被默认值覆盖。
例如:
```sql
INSERT INTO monitor (host, ts, cpu)
VALUES ("127.0.0.1", "2024-07-11 20:00:00", 0.5);
```
`monitor` 表中 `memory` 列的默认值为 `NULL`。因此,新数据将为:
```sql
SELECT * FROM monitor;
```
```sql
+-----------+---------------------+------+--------+
| host | ts | cpu | memory |
+-----------+---------------------+------+--------+
| 127.0.0.1 | 2024-07-11 20:00:00 | 0.5 | NULL |
+-----------+---------------------+------+--------+
1 row in set (0.01 sec)
```
### 更新表中的部分字段
默认情况下, [InfluxDB 行协议](/user-guide/protocols/influxdb-line-protocol.md) 支持此种更新策略。
你还可以使用 SQL 在创建表时通过指定 `merge_mode` 选项为 `last_non_null` 来启用此行为。
示例如下:
```sql
CREATE TABLE monitor (
host STRING,
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP() TIME INDEX,
cpu FLOAT64,
memory FLOAT64,
PRIMARY KEY(host)
) WITH ('merge_mode'='last_non_null');
```
```sql
INSERT INTO monitor (host, ts, cpu, memory)
VALUES ("127.0.0.1", "2024-07-11 20:00:00", 0.8, 0.1);
```
要更新 `monitor` 表中的特定字段,
你可以只插入带有要更新的字段的新数据。
例如:
```sql
INSERT INTO monitor (host, ts, cpu)
VALUES ("127.0.0.1", "2024-07-11 20:00:00", 0.5);
```
这将更新 `cpu` 字段,同时保持 `memory` 字段不变。
结果将为:
```sql
+-----------+---------------------+------+--------+
| host | ts | cpu | memory |
+-----------+---------------------+------+--------+
| 127.0.0.1 | 2024-07-11 20:00:00 | 0.5 | 0.1 |
+-----------+---------------------+------+--------+
```
请注意, `last_non_null` 无法将旧值更新为 `NULL`。
例如:
```sql
INSERT INTO monitor (host, ts, cpu, memory)
VALUES ("127.0.0.1", "2024-07-11 20:00:01", 0.8, 0.1);
```
```sql
INSERT INTO monitor (host, ts, cpu)
VALUES ("127.0.0.1", "2024-07-11 20:00:01", NULL);
```
不会更新任何内容:
```sql
+-----------+---------------------+------+--------+
| host | ts | cpu | memory |
+-----------+---------------------+------+--------+
| 127.0.0.1 | 2024-07-11 20:00:01 | 0.8 | 0.1 |
+-----------+---------------------+------+--------+
```
有关 `merge_mode` 选项的更多信息,请参阅 [CREATE TABLE](/reference/sql/create.md#创建带有-merge-模式的表) 语句。
### 通过创建带有 `append_mode` 选项的表来避免更新数据
在创建表时,GreptimeDB 支持 `append_mode` 选项,该选项始终将新数据插入表中。
当你想要保留所有历史数据(例如日志)时十分有用。
你只能使用 SQL 创建带有 `append_mode` 选项的表。
成功创建表后,所有[写入数据的协议](/user-guide/ingest-data/overview.md)都将在表中始终插入新数据。
例如,你可以创建一个带有 `append_mode` 选项的 `app_logs` 表,如下所示。
`host` 和 `log_level` 列表示 tag,`ts` 列表示 time index。
```sql
CREATE TABLE app_logs (
ts TIMESTAMP TIME INDEX,
host STRING,
api_path STRING FULLTEXT INDEX,
log_level STRING,
`log` STRING FULLTEXT INDEX,
PRIMARY KEY (host, log_level)
) WITH ('append_mode'='true');
```
向 `app_logs` 表中插入一行新数据:
```sql
INSERT INTO app_logs (ts, host, api_path, log_level, `log`)
VALUES ('2024-07-11 20:00:10', 'host1', '/api/v1/resource', 'ERROR', 'Connection timeout');
```
检查表中的数据:
```sql
SELECT * FROM app_logs;
```
输出将为:
```sql
+---------------------+-------+------------------+-----------+--------------------+
| ts | host | api_path | log_level | log |
+---------------------+-------+------------------+-----------+--------------------+
| 2024-07-11 20:00:10 | host1 | /api/v1/resource | ERROR | Connection timeout |
+---------------------+-------+------------------+-----------+--------------------+
1 row in set (0.01 sec)
```
你可以插入具有相同 tag 和 time index 的新数据:
```sql
INSERT INTO app_logs (ts, host, api_path, log_level, `log`)
-- 与现有数据相同的标签 `host1` 和 `ERROR`,相同的时间索引 2024-07-11 20:00:10
VALUES ('2024-07-11 20:00:10', 'host1', '/api/v1/resource', 'ERROR', 'Connection reset');
```
然后,你将在表中找到两行数据:
```sql
SELECT * FROM app_logs;
```
```sql
+---------------------+-------+------------------+-----------+--------------------+
| ts | host | api_path | log_level | log |
+---------------------+-------+------------------+-----------+--------------------+
| 2024-07-11 20:00:10 | host1 | /api/v1/resource | ERROR | Connection reset |
| 2024-07-11 20:00:10 | host1 | /api/v1/resource | ERROR | Connection timeout |
+---------------------+-------+------------------+-----------+--------------------+
2 rows in set (0.01 sec)
```
## 删除数据
你可以通过指定 tag 和 time index 来有效地删除数据。
未指定 tag 和 time index 进行删除数据不高效,因为它需要两个步骤:查询数据,然后按 tag 和 time index 进行删除。
有关列类型的更多信息,请参阅[数据模型](/user-guide/concepts/data-model.md)。
:::warning 警告
过多的删除可能会对查询性能产生负面影响。
:::
只能使用 SQL 删除数据。
例如,要从 `monitor` 表中删除具有 tag `host` 和 time index `ts` 的行:
```sql
DELETE FROM monitor WHERE host='127.0.0.2' AND ts=1667446798450;
```
输出将为:
```sql
Query OK, 1 row affected (0.00 sec)
```
有关 `DELETE` 语句的更多信息,请参阅 [SQL DELETE](/reference/sql/delete.md)。
## 删除表中的所有数据
要删除表中的所有数据,可以使用 SQL 中的 `TRUNCATE TABLE` 语句。
例如,要清空 `monitor` 表:
```sql
TRUNCATE TABLE monitor;
```
有关 `TRUNCATE TABLE` 语句的更多信息,请参阅 [SQL TRUNCATE TABLE](/reference/sql/truncate.md) 文档。
## 使用 TTL 策略保留数据
Time to Live (TTL) 允许你设置定期删除表中数据的策略,
你可以使用 TTL 自动删除数据库中的过期数据。
设置 TTL 策略具有以下好处:
- 通过清理过期数据来降低存储成本。
- 减少数据库在某些查询中需要扫描的行数,从而提高查询性能。
> 请注意,因 TTL 策略而过期的数据,并不是在 TTL 到期时立刻删除的,而是发生在 compaction 时。compaction 是一个后台任务。
> 如果你在测试 TTL 策略,查询过期数据之前请确保 flush 和 compaction 都已触发过了。
> 你可以使用我们的 ”[ADMIN](/reference/sql/admin.md)“ 函数来手动触发。
你可以在创建每个表时设置 TTL。
例如,以下 SQL 语句创建了一个名为 `monitor` 的表,并设置了 7 天的 TTL 策略:
```sql
CREATE TABLE monitor (
host STRING,
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP() TIME INDEX,
cpu FLOAT64,
memory FLOAT64,
PRIMARY KEY(host)
) WITH ('ttl'='7d');
```
你还可以创建数据库级别的 TTL 策略。
例如,以下 SQL 语句创建了一个名为 `test` 的数据库,并设置了 7 天的 TTL 策略:
```sql
CREATE DATABASE test WITH ('ttl'='7d');
```
你可以同时为 table 和 database 设置 TTL 策略。
如果 table 有自己的 TTL 策略,则该策略将优先于 database 的 TTL 策略,
否则 database 的 TTL 策略将被应用于 table。
`'ttl'` 参数的值可以是持续时间(例如 `1hour 12min 5s`)、`instant` 或 `forever`。有关详细信息,请参阅 [CREATE](/reference/sql/create.md#创建指定-ttl-的表) 语句的文档。
使用 [`ALTER`](/reference/sql/alter.md#修改表的参数) 来修改现有表或数据库的 TTL:
```sql
-- 针对表
ALTER TABLE monitor SET 'ttl'='1 month';
-- 针对数据库
ALTER DATABASE test SET 'ttl'='1 month';
```
如果你想移除 TTL 策略,可以使用如下 SQL 语句:
```sql
-- 针对表移除 'ttl' 设置
ALTER TABLE monitor UNSET 'ttl';
-- 针对数据库移除 'ttl' 设置
ALTER DATABASE test UNSET 'ttl';
```
有关 TTL 策略的更多信息,请参阅 [CREATE](/reference/sql/create.md) 语句。
## 更多数据管理操作
有关更高级的数据管理操作,例如基本表操作、表分片和 Region 迁移,请参阅 Administration 部分的[数据管理](/user-guide/deployments-administration/manage-data/overview.md)。
---
## 从 ClickHouse 迁移
本指南详细介绍如何将业务平滑迁移自 ClickHouse 到 GreptimeDB,涵盖迁移前的准备、数据模型调整、表结构重构、双写保障以及数据导出与导入的具体方法,帮助实现系统的无缝切换。
## 迁移前须知
- **兼容性**
虽然 GreptimeDB 支持 SQL 协议,但与 ClickHouse 在数据建模、索引设计和压缩机制等方面存在根本差异。请查阅 [SQL 兼容性](/reference/sql/compatibility.md) 文档以及官方[建模建议](/user-guide/deployments-administration/performance-tuning/design-table.md),在迁移过程中重构表结构与数据流。
- **数据模型差异**
ClickHouse 属于通用大数据分析引擎,GreptimeDB 则重点优化时序、指标及日志可观测场景。两者在数据模型、索引体系与压缩算法等方面均有差别,模型设计时需充分考虑业务场景及兼容性。
---
## 重新设计数据模型与表结构
### 时间索引
- ClickHouse 的表未必有 time index 字段,迁移时需明确选择业务主要的时间字段作为时间索引,并在 GreptimeDB 建表时指定,如日志记录时间/链路追踪时间等。
- 时间精度(秒、毫秒、微秒等)应按实际需求选定,且一旦设定不可更改。
### 主键与宽表建议
- 主键:类似 ClickHouse 的 `order by`,去掉时间戳列;但不建议包含 log_id、user_id 或 UUID 等高基数字段,以避免主键膨胀、写放大和低效查询。
- 宽表 vs 多表:同一个观测点采集多种指标时建议采用宽表,有助于提升批量写入效率和压缩比。
### 索引规划
- 倒排索引:为低基数列建立索引,提高筛选效率。
- 跳数索引:按需使用,适用于稀疏值或大表中偶尔查询的特定值。
- 全文索引:按需使用,适用于字符串字段的文本检索,避免在高基数或高变动字段上建立无用索引。
- 更多信息详见[数据索引](/user-guide/manage-data/data-index.md)。
### 表分区
ClickHouse 通过 `PARTITION BY` 语法支持分区,GreptimeDB 提供类似能力,语法不同,请参阅[表分片](/user-guide/deployments-administration/manage-data/table-sharding.md)文档。
### TTL
GreptimeDB 支持通过表选项 `ttl` 设置生命周期,详见[使用 TTL 策略管理数据存储](/user-guide/manage-data/overview.md#使用-ttl-策略保留数据)。
### 表结构举例
ClickHouse 表:
```sql
CREATE TABLE example (
timestamp DateTime,
host String,
app String,
metric String,
value Float64
) ENGINE = MergeTree()
TTL timestamp + INTERVAL 30 DAY
ORDER BY (timestamp, host, app, metric);
````
GreptimeDB 推荐表结构:
```sql
CREATE TABLE example (
`timestamp` TIMESTAMP NOT NULL,
host STRING,
app STRING INVERTED INDEX,
metric STRING INVERTED INDEX,
`value` DOUBLE,
PRIMARY KEY (host, app, metric),
TIME INDEX (`timestamp`)
) with(ttl='30d');
```
> 主键及时间索引的选型应结合业务数据量及查询场景慎重设计。如果 host 基数很大(如百万级监控主机),可不做主键,改为跳数索引。
### 典型日志表迁移
> GreptimeDB 已内置 otel 日志建模方案,操作详见[官方文档](/user-guide/ingest-data/for-observability/opentelemetry.md#logs)。
ClickHouse 日志表结构:
```sql
CREATE TABLE logs
(
timestamp DateTime,
host String,
service String,
log_level String,
log_message String,
trace_id String,
span_id String,
INDEX inv_idx(log_message) TYPE ngrambf_v1(4, 1024, 1, 0) GRANULARITY 1
) ENGINE = MergeTree
ORDER BY (timestamp, host, service);
```
推荐的 GreptimeDB 表结构:
- 时间索引:`timestamp`(根据日志频率选定精度)
- 主键:`host`, `service`(常用过滤/聚合字段)
- 字段列:`log_message`, `trace_id`, `span_id`(高基数、唯一标识或原始内容)
```sql
CREATE TABLE logs (
`timestamp` TIMESTAMP NOT NULL,
host STRING,
service STRING,
log_level STRING,
log_message STRING FULLTEXT INDEX WITH (
backend = 'bloom',
analyzer = 'English',
case_sensitive = 'false'
),
trace_id STRING SKIPPING INDEX,
span_id STRING SKIPPING INDEX,
PRIMARY KEY (host, service),
TIME INDEX (`timestamp`)
);
```
**说明:**
- `host` 和 `service` 作为常用过滤项列入主键,如主机数量非常多,可移出主键,改为跳数索引。
- `log_message` 作为原始文本内容建立全文索引。**若要全文索引生效,查询时 SQL 语法也需调整,详见[日志检索文档](/user-guide/logs/fulltext-search.md)**。
- `trace_id` 和 `span_id` 通常为高基数字段,建议仅做跳数索引。
### 典型链路表迁移
> GreptimeDB 已内置 otel 链路建模方案,详见[官方文档](/user-guide/ingest-data/for-observability/opentelemetry.md#traces)。
ClickHouse 链路表结构设计:
```sql
CREATE TABLE traces (
timestamp DateTime,
trace_id String,
span_id String,
parent_span_id String,
service String,
operation String,
duration UInt64,
status String,
tags Map(String, String)
) ENGINE = MergeTree()
ORDER BY (timestamp, trace_id, span_id);
```
GreptimeDB 推荐表结构:
- 时间索引:`timestamp`(采集/起始时间)
- 主键:`service`, `operation`(常用过滤/聚合属性)
- 字段列:`trace_id`, `span_id`, `parent_span_id`, `duration`, `tags`(高基数或 Map 字段)
```sql
CREATE TABLE traces (
`timestamp` TIMESTAMP NOT NULL,
service STRING,
operation STRING,
`status` STRING,
trace_id STRING SKIPPING INDEX,
span_id STRING SKIPPING INDEX,
parent_span_id STRING SKIPPING INDEX,
duration DOUBLE,
tags STRING, -- 如为结构化 JSON 可原样存储,必要时用 Pipeline 展开字段
PRIMARY KEY (service, operation),
TIME INDEX (`timestamp`)
);
```
**说明:**
- `service` 与 `operation` 作为主键,便于链路调度和按服务聚合。
- `trace_id`、`span_id`、`parent_span_id` 用跳数索引,不作为主键。
- 高基数字段仅作普通字段,便于写入效率;`tags` 推荐用字符串或 json,复杂属性可结合 [ETL Pipeline](/user-guide/logs/quick-start.md#使用-pipeline-写入日志) 展开。
- 若业务量极大可考虑多表分区(如多服务场景区分)。
双写保障迁移策略
--------
迁移期间,为避免数据丢失和写入不一致,建议采用双写:
- 应用需同时写入 ClickHouse 和 GreptimeDB,双系统并行。
- 通过日志和校验对比数据,可保证一致性,数据无误后再切换全部流量。
历史数据导出与导入
---------
1. **迁移前开启双写** 应用同时写入 ClickHouse 和 GreptimeDB,校验数据一致性,减少数据缺失风险。
2. **从 ClickHouse 导出数据** 利用 ClickHouse 命令将数据导出为 CSV、TSV、Parquet 等格式样例:
```sh
clickhouse client --query="SELECT * FROM example INTO OUTFILE 'example.csv' FORMAT CSVWithNames"
```
导出的 CSV 内容类似:
```csv
"timestamp","host","app","metric","value"
"2024-04-25 10:00:00","host01","nginx","cpu_usage",12.7
"2024-04-25 10:00:00","host02","redis","cpu_usage",8.4
...
```
3. **导入数据到 GreptimeDB**
> 需先在 GreptimeDB 创建好目标表。
支持 SQL 命令批量导入,或用 [REST API](/reference/http-endpoints.md#协议端点) 分批导入大数据量。 可用 [`COPY FROM` 命令](/reference/sql/copy.md#copy-from):
```sql
COPY example FROM "/path/to/example.csv" WITH (FORMAT = 'CSV');
```
或转换为标准 INSERT 语句分批导入。
验证与流量切换
-------
- 导入完成后,使用 GreptimeDB 查询接口与 ClickHouse 进行数据对比。
- 校验数据及监控无误后,可正式切换业务写入到 GreptimeDB,并关闭双写。
常见问题与优化建议
---------
### SQL/类型不兼容怎么办?
迁移前需梳理所有查询 SQL 并按官方文档 ([SQL 查询](/user-guide/query-data/sql.md)、[日志检索](/user-guide/logs/fulltext-search.md)) 重写或翻译不兼容语法和类型。
### 如何高效批量导入大规模数据?
大表或历史全量数据建议分分区/分片导出导入,并密切监控速度和进度。
### 高基数字段如何处理?
避免作为主键,直接存为字段,必要时分表拆分。
### 宽表如何规划?
每个监控对象(采集端)建议聚合到单表,如 `host_metrics` 专表存储服务器所有指标。
如果您需要更详细的迁移方案或示例脚本,请提供具体表结构和数据量信息。[GreptimeDB 官方社区](https://github.com/orgs/GreptimeTeam/discussions)将为您提供进一步支持。欢迎加入 [Greptime Slack](http://greptime.com/slack) 交流。
---
## 从 InfluxDB 迁移
```shell
curl -X POST 'http://{{host}}:4000/v1/influxdb/api/v2/write?db={{db-name}}' \
-H 'authorization: token {{greptime_user:greptimedb_password}}' \
-d 'census,location=klamath,scientist=anderson bees=23 1566086400000000000'
```
```shell
curl 'http://{{host}}:4000/v1/influxdb/write?db={{db-name}}&u={{greptime_user}}&p={{greptimedb_password}}' \
-d 'census,location=klamath,scientist=anderson bees=23 1566086400000000000'
```
有关详细的配置说明,请参考 [通过 Telegraf 写入数据](/user-guide/ingest-data/for-iot/influxdb-line-protocol.md#telegraf) 文档。
```js
'use strict'
/** @module write
**/
/** Environment variables **/
const url = 'http://:4000/v1/influxdb'
const token = ':'
const org = ''
const bucket = ''
const influxDB = new InfluxDB({ url, token })
const writeApi = influxDB.getWriteApi(org, bucket)
writeApi.useDefaultTags({ region: 'west' })
const point1 = new Point('temperature')
.tag('sensor_id', 'TLM01')
.floatField('value', 24.0)
writeApi.writePoint(point1)
```
```python
from influxdb_client.client.write_api import SYNCHRONOUS
bucket = ""
org = ""
token = ":"
url="http://:4000/v1/influxdb"
client = influxdb_client.InfluxDBClient(
url=url,
token=token,
org=org
)
# Write script
write_api = client.write_api(write_options=SYNCHRONOUS)
p = influxdb_client.Point("my_measurement").tag("location", "Prague").field("temperature", 25.3)
write_api.write(bucket=bucket, org=org, record=p)
```
```go
bucket := ""
org := ""
token := ":"
url := "http://:4000/v1/influxdb"
client := influxdb2.NewClient(url, token)
writeAPI := client.WriteAPIBlocking(org, bucket)
p := influxdb2.NewPoint("stat",
map[string]string{"unit": "temperature"},
map[string]interface{}{"avg": 24.5, "max": 45},
time.Now())
writeAPI.WritePoint(context.Background(), p)
client.Close()
```
```java
private static String url = "http://:4000/v1/influxdb";
private static String org = "";
private static String bucket = "";
private static char[] token = ":".toCharArray();
public static void main(final String[] args) {
InfluxDBClient influxDBClient = InfluxDBClientFactory.create(url, token, org, bucket);
WriteApiBlocking writeApi = influxDBClient.getWriteApiBlocking();
Point point = Point.measurement("temperature")
.addTag("location", "west")
.addField("value", 55D)
.time(Instant.now().toEpochMilli(), WritePrecision.MS);
writeApi.writePoint(point);
influxDBClient.close();
}
```
```php
$client = new Client([
"url" => "http://:4000/v1/influxdb",
"token" => ":",
"bucket" => "",
"org" => "",
"precision" => InfluxDB2\Model\WritePrecision::S
]);
$writeApi = $client->createWriteApi();
$dateTimeNow = new DateTime('NOW');
$point = Point::measurement("weather")
->addTag("location", "Denver")
->addField("temperature", rand(0, 20))
->time($dateTimeNow->getTimestamp());
$writeApi->write($point);
```
推荐使用 Grafana 可视化 GreptimeDB 数据,
请参考 [Grafana 文档](/user-guide/integrations/grafana.md) 了解如何配置 GreptimeDB。
```shell
for file in data.*; do
curl -i --retry 3 \
-X POST "http://${GREPTIME_HOST}:4000/v1/influxdb/write?db=${GREPTIME_DB}&u=${GREPTIME_USERNAME}&p=${GREPTIME_PASSWORD}" \
--data-binary @${file}
sleep 1
done
```
---
## 从 Loki 迁移
本指南介绍如何将 Loki 日志写入迁移到 GreptimeDB。
GreptimeDB 支持 Loki Push API 写入日志,因此现有的 Loki 兼容写入端通常只需少量配置变更即可将日志发送到 GreptimeDB。
GreptimeDB 的 Loki 兼容端点用于日志写入。
对于查询和仪表盘,请使用 GreptimeDB SQL、[全文检索](/user-guide/logs/fulltext-search.md)、[GreptimeDB Dashboard](/getting-started/installation/greptimedb-dashboard.md) 以及 [Grafana 集成](/user-guide/integrations/grafana.md),而不是 LogQL。
## 迁移前须知
请先检查当前 Loki 部署,并决定日志在 GreptimeDB 中的存储方式:
* 梳理所有向 Loki 写入日志的组件,例如 Grafana Alloy、OpenTelemetry Collector、Promtail、Fluent Bit、Vector 或自定义客户端。
* 规划目标 GreptimeDB 数据库和表名。如果没有提供表名 Header,GreptimeDB 会将 Loki 日志写入 `loki_logs`。
* 检查 Loki stream labels。GreptimeDB 会将 labels 存储为标签列,因此应避免使用 request ID、user ID、trace ID 等高基数字段作为 label。
* 确认是否只需要保存原始日志行,还是需要使用 GreptimeDB Pipeline 将日志行解析为结构化列。
* 规划历史数据迁移。GreptimeDB 不会直接导入 Loki chunk 或 index 文件;请通过原始日志源、归档文件或导出的记录,将历史日志重放到 GreptimeDB 的日志写入 API。
对于新的采集器配置,推荐使用 [Grafana Alloy](/user-guide/integrations/alloy.md)。
如果仍在使用已有的 Loki 兼容客户端,可以通过修改 Loki Push URL 并添加 GreptimeDB Header,将其重定向到 GreptimeDB。
## 迁移步骤
### 配置 GreptimeDB Loki 端点
将 Loki Push 请求发送到:
```text
http{s}://:4000/v1/loki/api/v1/push
```
使用以下 GreptimeDB 专用 Header:
| Header | 是否必需 | 说明 |
| --- | --- | --- |
| `X-Greptime-DB-Name` | 否 | 目标数据库名,默认值为 `public`。 |
| `X-Greptime-Log-Table-Name` | 否 | 目标日志表名,默认值为 `loki_logs`。 |
| `Authorization` | 取决于部署 | 使用 Base64 编码的 `:` 进行 Basic 认证。 |
| `X-Greptime-Pipeline-Name` 或 `X-Greptime-Log-Pipeline-Name` | 否 | 在写入前用于解析 Loki 条目的 Pipeline 名称。 |
GreptimeDB 接受与 Loki 相同的 Push 请求体格式:
* `Content-Type: application/x-protobuf`:Snappy 压缩的 Loki `PushRequest`。
* `Content-Type: application/json`:包含顶层 `streams` 数组的 JSON 请求体。
以下 JSON 请求可用于快速检查连通性:
```bash
curl -X POST "http://localhost:4000/v1/loki/api/v1/push" \
-H "Content-Type: application/json" \
-H "X-Greptime-DB-Name: public" \
-H "X-Greptime-Log-Table-Name: loki_demo_logs" \
--data-raw '{
"streams": [
{
"stream": {
"job": "api",
"env": "prod"
},
"values": [
["1731748568804293888", "request completed", {"trace_id": "abc"}]
]
}
]
}'
```
### 双写 Loki 和 GreptimeDB
迁移期间,请同时写入 Loki 和 GreptimeDB,直到完成写入、保留策略、仪表盘和告警验证。
以下 Alloy 示例保留现有 Loki sink,并新增一个 GreptimeDB Loki 兼容 sink:
```hcl
loki.source.file "app" {
targets = [
{__path__ = "/var/log/app/*.log"},
]
forward_to = [loki.process.app.receiver]
file_match {
enabled = true
}
}
loki.process "app" {
forward_to = [
loki.write.existing_loki.receiver,
loki.write.greptimedb.receiver,
]
stage.static_labels {
values = {
job = "app",
env = "prod",
}
}
}
loki.write "existing_loki" {
endpoint {
url = "http://loki:3100/loki/api/v1/push"
}
}
loki.write "greptimedb" {
endpoint {
url = "http://greptimedb:4000/v1/loki/api/v1/push"
headers = {
"X-Greptime-DB-Name" = "public",
"X-Greptime-Log-Table-Name" = "loki_app_logs",
}
basic_auth {
username = ""
password = ""
}
}
}
```
如果你的采集器已经配置了 Loki 输出,迁移初期请先保持 labels 和处理阶段不变。
只修改 GreptimeDB sink 的 URL、数据库 Header、表名 Header 和认证配置。
该示例遵循 [Grafana Alloy 指南](/user-guide/ingest-data/for-observability/alloy.md)中的 Loki 组件模式:`loki.source.file` 读取文件,`loki.process` 在 Loki pipeline 中保留 label 处理,`loki.write.endpoint` 则承载 GreptimeDB URL、自定义 Header 以及可选的 Basic 认证配置。
由于该示例在 `__path__` 中使用了 glob 匹配模式,`file_match` 会启用 Alloy 内置的文件发现能力,将该模式展开为实际匹配的文件。如果你使用的是明确的文件路径,可以省略 `file_match`。
### 验证直接写入的数据模型
不使用 Pipeline 时,GreptimeDB 会将 Loki 条目存储在原始日志表中:
| Loki 数据 | GreptimeDB 列 |
| --- | --- |
| Entry timestamp | `greptime_timestamp` 时间索引 |
| Log line | `line` 字段列 |
| Structured metadata | `structured_metadata` JSON 字段列 |
| Stream labels | 字符串标签列 |
直接写入时,请让 GreptimeDB 在首次写入时自动创建表。
不要通过 SQL 预先创建直接写入表来指定 label 列。
Labels 是动态的,会成为自动生成表结构中的标签列。
如果需要自定义表结构,请使用 Pipeline,并根据 Pipeline 配置创建表。
使用 SQL 验证写入结果:
```sql
DESC loki_app_logs;
SELECT greptime_timestamp, line, job, env, structured_metadata
FROM loki_app_logs
ORDER BY greptime_timestamp DESC
LIMIT 10;
```
也可以检查该表是否被识别为 Loki 日志数据:
```sql
SELECT table_schema, table_name, signal_type, source
FROM information_schema.table_semantics
WHERE table_name = 'loki_app_logs';
```
也可以打开 `http://:4000/dashboard` 访问 [GreptimeDB Dashboard](/getting-started/installation/greptimedb-dashboard.md),并使用 Log View 查询写入的日志。
### 使用 Pipeline 解析 Loki 日志行
如果 Loki 日志行包含 JSON、logfmt、Nginx access logs 或其他需要展开为可查询列的结构化格式,请使用 GreptimeDB Pipeline。
如果使用 AI 编码代理来创建 Pipeline,可以为它提供 [`greptimedb-pipeline` Skill](/faq-and-others/vibecoding.md#greptimedb-skills),帮助它生成、dry-run 并迭代 Pipeline 配置。
当请求中包含 `X-Greptime-Pipeline-Name` 或 `X-Greptime-Log-Pipeline-Name` 时,GreptimeDB 会将每条 Loki 条目按以下输入字段送入 Pipeline:
| Pipeline 输入字段 | 说明 |
| --- | --- |
| `greptime_timestamp` | Loki 条目的时间戳。 |
| `loki_line` | 原始 Loki 日志行。 |
| `loki_label_` | Loki stream label 值。 |
| `loki_metadata_` | Loki structured metadata 值。 |
例如,假设 Alloy 读取以下 ZooKeeper 日志文件:
```text
2015-08-25 11:23:58,959 - WARN [LearnerHandler-/10.10.34.11:45441:Leader@574] - Committing zxid 0xf00000000 from /10.10.34.13:2888 not first!
2015-08-25 11:23:58,960 - WARN [LearnerHandler-/10.10.34.11:45441:Leader@576] - First is 0x0
2015-08-25 11:23:58,960 - INFO [LearnerHandler-/10.10.34.11:45441:Leader@598] - Have quorum of supporters; starting up and setting last processed zxid: 0xf00000000
2015-08-25 11:26:27,891 - INFO [/10.10.34.13:3888:QuorumCnxManager$Listener@493] - Received connection request /10.10.34.12:57513
2015-08-25 11:26:27,897 - INFO [WorkerReceiver[myid=3]:FastLeaderElection@542] - Notification: 2 (n.leader), 0xd0000001b (n.zxid), 0x1 (n.round), LOOKING (n.state), 2 (n.sid), 0xd (n.peerEPoch), LEADING (my state)
2015-08-25 11:26:27,898 - INFO [WorkerReceiver[myid=3]:FastLeaderElection@542] - Notification: 3 (n.leader), 0xd0000001b (n.zxid), 0x3 (n.round), LOOKING (n.state), 2 (n.sid), 0xe (n.peerEPoch), LEADING (my state)
2015-08-25 11:26:28,138 - INFO [LearnerHandler-/10.10.34.12:38330:LearnerHandler@263] - Follower sid: 2 : info : org.apache.zookeeper.server.quorum.QuorumPeer$QuorumServer@7761c32f
2015-08-25 11:26:28,159 - INFO [LearnerHandler-/10.10.34.12:38330:LearnerHandler@318] - Synchronizing with Follower sid: 2 maxCommittedLog=0x0 minCommittedLog=0x0 peerLastZxid=0xd0000001b
2015-08-25 11:26:28,159 - INFO [LearnerHandler-/10.10.34.12:38330:LearnerHandler@395] - Sending SNAP
2015-08-25 11:26:28,159 - INFO [LearnerHandler-/10.10.34.12:38330:LearnerHandler@419] - Sending snapshot last zxid of peer is 0xd0000001b zxid of leader is 0xf00000000sent zxid of db as 0xf00000000
```
创建一个 Pipeline,提取 ZooKeeper 时间戳、日志级别、线程、源码行号和消息:
```yaml
# zk_pipeline.yaml
version: 2
processors:
- regex:
fields:
- loki_line, zk
patterns:
- '^(?\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2},\d{3}) - (?[A-Z]+)\s+\[(?.*)@(?\d+)\] - (?.*)$'
ignore_missing: true
- date:
fields:
- zk_timestamp
formats:
- "%Y-%m-%d %H:%M:%S,%3f"
timezone: "UTC"
- select:
fields:
- zk_timestamp
- zk_level
- zk_thread
- zk_source_line
- zk_message
- loki_label_job
- loki_label_env
transform:
- field: zk_timestamp
type: time
index: timestamp
- fields:
- zk_level
- loki_label_job
- loki_label_env
type: string
tag: true
- field: zk_thread
type: string
index: inverted
- field: zk_source_line
type: int32
- field: zk_message
type: string
index: fulltext
```
示例日志中的时间戳没有包含时区。请将 `timezone` 设置为日志生产端使用的时区。
上传 Pipeline:
```bash
curl -X POST "http://localhost:4000/v1/pipelines/zk_logs" \
-F "file=@zk_pipeline.yaml"
```
然后在 GreptimeDB Loki sink 中添加 Pipeline Header:
```hcl
loki.write "greptimedb" {
endpoint {
url = "http://greptimedb:4000/v1/loki/api/v1/push"
headers = {
"X-Greptime-DB-Name" = "public",
"X-Greptime-Log-Table-Name" = "loki_zookeeper_logs",
"X-Greptime-Pipeline-Name" = "zk_logs",
}
}
}
```
Alloy 通过该 sink 发送 ZooKeeper 日志文件后,GreptimeDB 会先应用该 Pipeline,再将处理后的行写入 `loki_zookeeper_logs`。
通过 Pipeline 写入后,可以查询结构化列:
```sql
SELECT
zk_timestamp,
loki_label_job AS job,
loki_label_env AS env,
zk_level,
zk_thread,
zk_source_line,
zk_message
FROM loki_zookeeper_logs
WHERE zk_level = 'WARN'
ORDER BY zk_timestamp DESC
LIMIT 10;
```
如需在解析后的 message 字段上使用全文检索,请参阅[全文检索](/user-guide/logs/fulltext-search.md)。
### 迁移历史日志
完整迁移历史日志时,应将数据重放到 GreptimeDB,而不是复制 Loki 存储文件。
常见做法包括:
* 使用 Alloy、Vector、Fluent Bit 或自定义脚本,从原始日志文件或对象存储归档中重放日志。
* 将选定的 Loki 查询结果导出为按行分隔的记录,转换为 Loki Push JSON 后写入 GreptimeDB。
* 仅回填切换后必须可查询的保留窗口,并通过双写覆盖新增数据。
回填时,请保留原始纳秒时间戳,以便 GreptimeDB 保留事件发生时间。
建议按有限时间范围分批导入,便于验证和重试。
### 切换读写流量
在停止写入 Loki 之前,请验证:
* 每个重要 service、namespace 和 environment 的最新日志都已写入 GreptimeDB。
* 同一时间窗口内的行数或抽样记录与 Loki 匹配。
* GreptimeDB 保留策略满足日志保留要求。
* 仪表盘和告警已从 LogQL 改写为 SQL 或 GreptimeDB 日志查询。
* 常用检索列已经具备全文索引或跳数索引。
验证完成后,从采集器配置中移除 Loki sink,仅保留 GreptimeDB sink 作为日志目的端。
## 故障排查
### 不支持的 Content-Type
Loki protobuf Push 客户端请设置 `Content-Type` 为 `application/x-protobuf`;JSON 请求请设置为 `application/json`。
### Protobuf decode 或 Snappy 错误
Loki protobuf Push 请求体必须经过 Snappy 压缩。
不要发送未经过 Snappy 压缩的原始 protobuf 字节。
### GreptimeDB 中缺少 labels
请检查 `loki.write` 之前的采集器处理阶段。
只有发送请求时仍保留在 Loki stream 上的 labels 才会成为 GreptimeDB 标签列。
### 表结构不匹配
对于 Loki 直接写入,请让 GreptimeDB 自动创建表。
如果需要自定义表结构,请使用 Pipeline,并根据 Pipeline 配置生成或创建表。
## 相关文档
* [Loki 协议](/user-guide/ingest-data/for-observability/loki.md)
* [Grafana Alloy](/user-guide/ingest-data/for-observability/alloy.md)
* [管理 Pipeline](/user-guide/logs/manage-pipelines.md)
* [全文检索](/user-guide/logs/fulltext-search.md)
---
## 从 MySQL 迁移
本文档将指引您完成从 MySQL 迁移到 GreptimeDB。
## 在开始迁移之前
请注意,尽管 GreptimeDB 支持 MySQL 的协议,并不意味着 GreptimeDB 实现了 MySQL
的所有功能。你可以参考
- [ANSI 兼容性](/reference/sql/compatibility.md)查看在 GreptimeDB 中使用 SQL 的约束。
- [数据建模指南](/user-guide/deployments-administration/performance-tuning/design-table.md)创建合适的表结构。
- [数据索引指南](/user-guide/manage-data/data-index.md)用于索引规划。
## 迁移步骤
### 在 GreptimeDB 中创建数据库和表
在从 MySQL 迁移数据之前,你首先需要在 GreptimeDB 中创建相应的数据库和表。
由于 GreptimeDB 有自己的 SQL 语法用于创建表,因此你不能直接重用 MySQL 生成的建表 SQL。
当你为 GreptimeDB 编写创建表的 SQL 时,首先请了解其“[数据模型](/user-guide/concepts/data-model.md)”。然后,在创建表的
SQL 中请考虑以下几点:
1. 由于 time index 列在表创建后无法更改,所以你需要仔细选择 time index
列。时间索引最好设置为数据生成时的自然时间戳,因为它提供了查询数据的最直观方式,以及最佳的查询性能。例如,在 IOT
场景中,你可以使用传感器采集数据时的时间作为 time index;或者在可观测场景中使用事件的发生时间。
2. 不建议在此迁移过程中另造一个时间戳用作时间索引,例如使用 `DEFAULT current_timestamp()` 创建的新列。也不建议使用具有随机时间戳的列。
3. 选择合适的 time index 精度也至关重要。和 time index 的选择一样,一旦表创建完毕,time index
的精度就无法变更了。请根据你的数据集在[这里](/reference/sql/data-types.md#与-mysql-和-postgresql-兼容的数据类型)找到最适合的时间戳类型。
4. 仅在真正需要时才选择主键。GreptimeDB 中的主键与 MySQL 中的主键不同。仅在以下情况下才应使用主键:
- 大部分查询可以受益于排序。
- 您需要通过主键和时间索引来删除重复行(包括删除)。 通常会被查询。标签列中的值是附加到收集源的标签,通常用于描述这些源的特定特征。标签列会被索引,从而使对它们的查询具有高性能。
否则,设置主键是可选的,并且可能会损害性能。阅读[主键](/user-guide/deployments-administration/performance-tuning/design-table.md#主键)了解详情。
最后,请参阅“[CREATE](/reference/sql/create.md)” SQL 文档,了解有关选择合适的数据类型和“ttl”或“compaction”选项等的更多详细信息。
5. 选择合适的索引以加快查询速度。
- 倒排索引:非常适合按低基数列进行过滤,并快速查找具有特定值的行。
- 跳数索引:适用于稀疏数据。
- 全文索引:可以在大型文本列中实现高效的关键字和模式搜索。
有关详细信息和最佳实践,请参阅[数据索引](/user-guide/manage-data/data-index.md) 文档。
### 双写 GreptimeDB 和 MySQL
双写 GreptimeDB 和 MySQL 是迁移过程中防止数据丢失的有效策略。通过使用 MySQL 的客户端库(JDBC + 某个 MySQL
驱动),你可以建立两个客户端实例 —— 一个用于 GreptimeDB,另一个用于 MySQL。有关如何使用 SQL 将数据写入
GreptimeDB,请参考[写入数据](/user-guide/ingest-data/for-iot/sql.md)部分。
若无需保留所有历史数据,你可以双写一段时间以积累业务所需的最新数据,然后停止向 MySQL 写入数据并仅使用
GreptimeDB。如果需要完整迁移所有历史数据,请按照接下来的步骤操作。
### 从 MySQL 导出数据
[mysqldump](https://dev.mysql.com/doc/refman/8.4/en/mysqldump.html) 是一个常用的、从 MySQL 导出数据的工具。使用
mysqldump,我们可以从 MySQL 中导出后续可直接导入到 GreptimeDB 的数据。例如,如果我们想要从 MySQL 导出两个数据库 `db1` 和
`db2`,我们可以使用以下命令:
```bash
mysqldump -h127.0.0.1 -P3306 -umysql_user -p --compact -cnt --skip-extended-insert --databases db1 db2 > /path/to/output.sql
```
替换 `-h`、`-P` 和 `-u` 参数为 MySQL 服务的正确值。`--databases` 参数用于指定要导出的数据库。输出将写入
`/path/to/output.sql` 文件。
`/path/to/output.sql` 文件应该具有如下内容:
```plaintext
~ ❯ cat /path/to/output.sql
USE `db1`;
INSERT INTO `foo` (`ts`, `a`, `b`) VALUES (1,'hello',1);
INSERT INTO ...
USE `db2`;
INSERT INTO `foo` (`ts`, `a`, `b`) VALUES (2,'greptime',2);
INSERT INTO ...
```
### 将数据导入 GreptimeDB
[MySQL Command-Line Client](https://dev.mysql.com/doc/refman/8.4/en/mysql.html) 可用于将数据导入
GreptimeDB。继续上面的示例,假设数据导出到文件 `/path/to/output.sql`,那么我们可以使用以下命令将数据导入 GreptimeDB:
```bash
mysql -h127.0.0.1 -P4002 -ugreptime_user -p -e "source /path/to/output.sql"
```
替换 `-h`、`-P` 和 `-u` 参数为你的 GreptimeDB 服务的值。`source` 命令用于执行 `/path/to/output.sql` 文件中的 SQL
命令。若需要进行 debug,添加 `-vvv` 以查看详细的执行结果。
总结一下,数据迁移步骤如下图所示:
数据迁移完成后,你可以停止向 MySQL 写入数据,并继续使用 GreptimeDB!
如果您需要更详细的迁移方案或示例脚本,请提供具体的表结构和数据量信息。[GreptimeDB 官方社区](https://github.com/orgs/GreptimeTeam/discussions)将为您提供进一步的支持。欢迎加入 [Greptime Slack](http://greptime.com/slack) 社区交流。
---
## 从 PostgreSQL 迁移
本文档将指引您完成从 PostgreSQL 迁移到 GreptimeDB。
## 在开始迁移之前
请注意,尽管 GreptimeDB 支持 PostgreSQL 的协议,并不意味着 GreptimeDB 实现了 PostgreSQL
的所有功能。你可以参考
- [ANSI 兼容性](/reference/sql/compatibility.md)查看在 GreptimeDB 中使用 SQL 的约束。
- [数据建模指南](/user-guide/deployments-administration/performance-tuning/design-table.md)创建合适的表结构。
- [数据索引指南](/user-guide/manage-data/data-index.md)用于索引规划。
## 迁移步骤
### 在 GreptimeDB 中创建数据库和表
在从 PostgreSQL 迁移数据之前,你首先需要在 GreptimeDB 中创建相应的数据库和表。
由于 GreptimeDB 有自己的 SQL 语法用于创建表,因此你不能直接重用 PostgreSQL 生成的建表 SQL。
当你为 GreptimeDB 编写创建表的 SQL 时,首先请了解其“[数据模型](/user-guide/concepts/data-model.md)”。然后,在创建表的
SQL 中请考虑以下几点:
1. 由于 time index 列在表创建后无法更改,所以你需要仔细选择 time index
列。时间索引最好设置为数据生成时的自然时间戳,因为它提供了查询数据的最直观方式,以及最佳的查询性能。例如,在 IOT
场景中,你可以使用传感器采集数据时的时间作为 time index;或者在可观测场景中使用事件的发生时间。
2. 不建议在此迁移过程中另造一个时间戳用作时间索引,例如使用 `DEFAULT current_timestamp()` 创建的新列。也不建议使用具有随机时间戳的列。
3. 选择合适的 time index 精度也至关重要。和 time index 的选择一样,一旦表创建完毕,time index
的精度就无法变更了。请根据你的数据集在[这里](/reference/sql/data-types.md#与-mysql-和-postgresql-兼容的数据类型)找到最适合的时间戳类型。
4. 仅在真正需要时才选择主键。GreptimeDB 中的主键与 PosgreSQL 中的主键不同。仅在以下情况下才应使用主键:
- 大部分查询可以受益于排序。
- 您需要通过主键和时间索引来删除重复行(包括删除)。 通常会被查询。标签列中的值是附加到收集源的标签,通常用于描述这些源的特定特征。标签列会被索引,从而使对它们的查询具有高性能。
否则,设置主键是可选的,并且可能会损害性能。阅读[主键](/user-guide/deployments-administration/performance-tuning/design-table.md#主键)了解详情。
最后,请参阅“[CREATE](/reference/sql/create.md)” SQL 文档,了解有关选择合适的数据类型和“ttl”或“compaction”选项等的更多详细信息。
5. 选择合适的索引以加快查询速度。
- 倒排索引:非常适合按低基数列进行过滤,并快速查找具有特定值的行。
- 跳数索引:适用于稀疏数据。
- 全文索引:可以在大型文本列中实现高效的关键字和模式搜索。
有关详细信息和最佳实践,请参阅[数据索引](/user-guide/manage-data/data-index.md) 文档。
### 双写 GreptimeDB 和 PostgreSQL
双写 GreptimeDB 和 PostgreSQL 是迁移过程中防止数据丢失的有效策略。通过使用 PostgreSQL 的客户端库(JDBC + 某个 PostgreSQL
驱动),你可以建立两个客户端实例 —— 一个用于 GreptimeDB,另一个用于 PostgreSQL。有关如何使用 SQL 将数据写入
GreptimeDB,请参考[写入数据](/user-guide/ingest-data/for-iot/sql.md)部分。
若无需保留所有历史数据,你可以双写一段时间以积累业务所需的最新数据,然后停止向 PostgreSQL 写入数据并仅使用
GreptimeDB。如果需要完整迁移所有历史数据,请按照接下来的步骤操作。
### 从 PostgreSQL 导出数据
[pg_dump](https://www.postgresql.org/docs/current/app-pgdump.html) 是一个常用的、从 PostgreSQL 导出数据的工具。使用
pg_dump,我们可以从 PostgreSQL 中导出后续可直接导入到 GreptimeDB 的数据。例如,如果我们想要从 PostgreSQL 的 database
`postgres` 中导出以 `db` 开头的 schema,我们可以使用以下命令:
```bash
pg_dump -h127.0.0.1 -p5432 -Upostgres -ax --column-inserts -n 'db*' postgres | grep -v "^SE" > /path/to/output.sql
```
替换 `-h`、`-p` 和 `-U` 参数为 PostgreSQL 服务的正确值。`-n` 参数用于指定要导出的 schema。数据库 `postgres` 被放在了 `pg_dump` 命令的最后。注意这里我们将
pg_dump 的输出经过了一个特殊的 `grep` 命令以过滤掉不需要的 `SET` 和 `SELECT` 行。最终输出将写入 `/path/to/output.sql`
文件。
`/path/to/output.sql` 文件应该具有如下内容:
```plaintext
~ ❯ cat /path/to/output.sql
--
-- PostgreSQL database dump
--
-- Dumped from database version 16.4 (Debian 16.4-1.pgdg120+1)
-- Dumped by pg_dump version 16.4
--
-- Data for Name: foo; Type: TABLE DATA; Schema: db1; Owner: postgres
--
INSERT INTO db1.foo (ts, a) VALUES ('2024-10-31 00:00:00', 1);
INSERT INTO db1.foo (ts, a) VALUES ('2024-10-31 00:00:01', 2);
INSERT INTO db1.foo (ts, a) VALUES ('2024-10-31 00:00:01', 3);
INSERT INTO ...
--
-- Data for Name: foo; Type: TABLE DATA; Schema: db2; Owner: postgres
--
INSERT INTO db2.foo (ts, b) VALUES ('2024-10-31 00:00:00', '1');
INSERT INTO db2.foo (ts, b) VALUES ('2024-10-31 00:00:01', '2');
INSERT INTO db2.foo (ts, b) VALUES ('2024-10-31 00:00:01', '3');
INSERT INTO ...
--
-- PostgreSQL database dump complete
--
```
### 将数据导入 GreptimeDB
”[psql -- PostgreSQL interactive terminal](https://www.postgresql.org/docs/current/app-psql.html)“可用于将数据导入
GreptimeDB。继续上面的示例,假设数据导出到文件 `/path/to/output.sql`,那么我们可以使用以下命令将数据导入 GreptimeDB:
```bash
psql -h127.0.0.1 -p4003 -d public -f /path/to/output.sql
```
替换 `-h` 和 `-p` 参数为你的 GreptimeDB 服务的值。psql 命令中的 `-d` 参数用于指定数据库,该参数不能省略,`-d` 的值 `public` 是 GreptimeDB 默认使用的数据库。你还可以添加 `-a` 以查看详细的执行结果,或使用 `-s` 进入单步执行模式。
总结一下,数据迁移步骤如下图所示:
数据迁移完成后,你可以停止向 PostgreSQL 写入数据,并继续使用 GreptimeDB!
如果您需要更详细的迁移方案或示例脚本,请提供具体的表结构和数据量信息。[GreptimeDB 官方社区](https://github.com/orgs/GreptimeTeam/discussions)将为您提供进一步的支持。欢迎加入 [Greptime Slack](http://greptime.com/slack) 社区交流。
---
## 从 Prometheus 迁移
有关 Prometheus 将数据写入 GreptimeDB 的配置信息,请参阅 [Remote Write](/user-guide/ingest-data/for-observability/prometheus.md#配置-remote-write) 文档。
有关使用 Prometheus 查询语言在 GreptimeDB 中查询数据的详细信息,请参阅 PromQL 文档中的 [HTTP API](/user-guide/query-data/promql.md#prometheus-的-http-api) 部分。
要在 Grafana 中将 GreptimeDB 添加为 Prometheus 数据源,请参阅 [Grafana](/user-guide/integrations/grafana#prometheus-数据源) 的集成文档。
---
## 迁移到 GreptimeDB
你可以从多种数据库和可观测系统迁移到 GreptimeDB,例如 InfluxDB、MySQL、PostgreSQL、Prometheus、Loki 等。
---
## 用户指南
欢迎使用 GreptimeDB 用户指南。
GreptimeDB 是用于指标、事件和日志的统一可观测性数据库,
可提供从边缘到云的任何规模的实时洞察。
## 理解 GreptimeDB 的概念
在深入了解 GreptimeDB 之前,
建议先熟悉数据模型、关键概念和功能。
请参阅 [概念文档](./concepts/overview.md)。
## 根据你的使用场景写入数据
GreptimeDB 支持[多种协议](./protocols/overview.md)和[集成工具](./integrations/overview.md),
以便根据你的需求写入数据。
### 可观测性指标场景
如果你计划将 GreptimeDB 用于存储可观测性指标、日志和链路追踪,
请参阅[可观测性文档](./ingest-data/for-observability/overview.md)。
该文档解释了如何使用 Otel-Collector, Vector、Kafka、Prometheus 和 InfluxDB 行协议等工具导入数据。
对于日志存储解决方案,
请参考 [日志文档](./logs/overview.md)。
该文档详细说明了如何使用 Pipeline 写入结构化的文本日志。
对于链路追踪(trace)存储解决方案,
请参考 [trace 文档](./traces/overview.md)。
该文档解释了使用 OpenTelemetry 导入数据以及使用 Jaeger 查询数据的方法。
### 物联网和边缘计算场景
对于物联网和边缘计算场景,
[物联网文档](./ingest-data/for-iot/overview.md)提供了从多种来源导入数据的全面指导。
## 查询数据以获取洞察
GreptimeDB 提供了强大的[数据查询](./query-data/overview.md)功能。
### SQL 支持
你可以使用 SQL 进行范围查询、聚合等操作。
有关详细说明,请参阅 [SQL 查询文档](./query-data/sql.md)。
### Prometheus 查询语言 (PromQL)
GreptimeDB 支持使用 PromQL 查询数据。
请参考 [PromQL 文档](./query-data/promql.md) 以获取指导。
### 流计算
对于实时数据处理和分析,GreptimeDB 提供了[流计算](./flow-computation/overview.md),
支持对数据流进行复杂计算。
## 使用索引加速查询
倒排索引、跳数索引和全文索引等索引可以显著提升查询性能。
有关如何有效使用这些索引的更多信息,请参阅[数据索引文档](./manage-data/data-index.md)。
## 从其他数据库迁移到 GreptimeDB
你可以轻松从其他数据库迁移数据到 GreptimeDB,
请按照[迁移文档](./migrate-to-greptimedb/overview.md)中的分步说明进行操作。
## 管理和部署 GreptimeDB
当你准备好部署 GreptimeDB 时,
请查阅[部署及管理文档](/user-guide/deployments-administration/overview.md)获取有关服务端部署和管理的详细指南。
---
## Elasticsearch(Protocols)
请参考[使用 Elasticsearch 协议写入数据](/user-guide/ingest-data/for-observability/elasticsearch.md)获取详细信息。
---
## gRPC
GreptimeDB 提供了 [gRPC SDK](/user-guide/ingest-data/for-iot/grpc-sdks/overview.md),用于高效和高性能的数据摄入。
如果没有适用于你的编程语言的 SDK,你可以按照贡献者指南[创建自己的 SDK](/contributor-guide/how-to/how-to-write-sdk.md)。
---
## HTTP API
GreptimeDB 提供了 HTTP API 用于与数据库进行交互。如需查看完整的 API 端点列表,请查看 [HTTP Endpoints](/reference/http-endpoints.md)。
## Base URL
API Base URL 是 `http(s)://{{host}}:{{port}}/`。
- 对于在本地机器上运行的 GreptimeDB 实例,Base URL 是 `http://localhost:4000/`,默认端口配置为 `4000`。你可以在[配置文件](/user-guide/deployments-administration/configuration.md#protocol-options)中更改服务的 host 和 port。
- 对于 GreptimeCloud,Base URL 是 `https://{{host}}/`。你可以在 GreptimeCloud 控制台的 "Connection Information" 中找到 host。
在以下内容中,我们使用 `http://{{API-host}}/` 作为 Base URL 来演示 API。
## 通用 Headers
### 鉴权
假设你已经正确设置了数据库[鉴权](/user-guide/deployments-administration/authentication/overview.md),
GreptimeDB 支持 HTTP API 中内置的 `Basic` 鉴权机制。要设置鉴权,请按照以下步骤操作:
1. 使用 `` 格式和 `Base64` 算法对用户名和密码进行编码。
2. 将编码后的凭据附加到下列 HTTP 请求头之一中:
- `Authorization : Basic `
- `x-greptime-auth : Basic `
以下是一个示例。如果要使用用户名 `greptime_user` 和密码 `greptime_pwd` 连接到 GreptimeDB,请使用以下命令:
```shell
curl -X POST \
-H 'Authorization: Basic Z3JlcHRpbWVfdXNlcjpncmVwdGltZV9wd2Q=' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d 'sql=show tables' \
http://localhost:4000/v1/sql
```
在此示例中,`Z3JlcHRpbWVfdXNlcjpncmVwdGltZV9wd2Q=` 表示 `greptime_user:greptime_pwd` 的 Base64 编码值。请确保用自己配置的用户名和密码替换它,并使用 Base64 进行编码。
:::tip 注意
InfluxDB 使用自己的鉴权格式,请参阅 [InfluxDB](./influxdb-line-protocol.md) 获取详细信息。
:::
### 请求超时设置
GreptimeDB 支持在 HTTP 请求中使用 `X-Greptime-Timeout` 请求头,用于指定数据库服务器中运行的请求超时时间。
例如,以下请求为查询设置了 `120s` 的超时时间:
```bash
curl -X POST \
-H 'Authorization: Basic {{authentication}}' \
-H 'X-Greptime-Timeout: 120s' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d 'sql=show tables' \
http://localhost:4000/v1/sql
```
### Hints
GreptimeDB 支持在 HTTP 请求中使用 `x-greptime-hints` 请求头来传递影响请求行为的键值对。
这些 hints 主要用于在数据写入时[自动建表](/user-guide/ingest-data/overview.md#自动生成表结构)的场景下设置表选项。
格式为逗号分隔的 `key=value` 对:
```
x-greptime-hints: key1=value1, key2=value2
```
支持的 hints:
| Hint | 类型 | 默认值 | 说明 |
| --- | --- | --- | --- |
| `auto_create_table` | Boolean | `true` | 插入数据时,如果表不存在是否自动创建。 |
| `ttl` | 时间字符串 | 无 | 设置表的[数据过期时间](/user-guide/manage-data/overview.md#使用-ttl-策略保留数据),例如 `7d`、`24h`。过期数据将被自动清理。 |
| `append_mode` | Boolean | `false` | 启用表的 [append-only 模式](/reference/sql/create.md#创建-append-only-表),该模式禁用按主键去重,支持重复行。 |
| `merge_mode` | String | 无 | 设置表的 [merge 模式](/reference/sql/create.md#创建带有-merge-模式的表),例如 `last_non_null`、`last_row`。 |
| `physical_table` | String | 无 | 指定 [metric 引擎](/contributor-guide/datanode/metric-engine.md)的物理表名。 |
| `skip_wal` | Boolean | `false` | 跳过表的 WAL(Write-Ahead Log)写入。 |
| `sst_format` | String | 无 | 设置表的 SST(Sorted String Table)文件格式。可选值:`flat`、`primary_key`。 |
例如,以下请求为自动创建的表设置 TTL 和 append 模式:
```bash
curl -X POST \
-H 'Authorization: Basic {{authentication}}' \
-H 'x-greptime-hints: ttl=7d, append_mode=true' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d 'sql=INSERT INTO my_table VALUES (...)' \
http://localhost:4000/v1/sql
```
## Admin APIs
:::tip 注意
这些 API 在 GreptimeCloud 中无法使用。
:::
请参考 [Admin APIs 接口](/reference/http-endpoints.md#管理-api)文档以获取更多信息。
## POST SQL 语句
要通过 HTTP API 向 GreptimeDB 服务器提交 SQL 语句,请使用以下格式:
```shell
curl -X POST \
-H 'Authorization: Basic {{authentication}}' \
-H 'X-Greptime-Timeout: {{timeout}}' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d 'sql={{SQL-statement}}' \
http://{{API-host}}/v1/sql
```
### Headers
- [`Authorization`](#鉴权)
- [`X-Greptime-Timeout`](#请求超时设置)
- `Content-Type`: `application/x-www-form-urlencoded`.
- `X-Greptime-Timezone`: 当前 SQL 查询的时区。可选。请参阅[时区](#时区)。
### Query string parameters
- `db`: 数据库名称。可选。如果未提供,将使用默认数据库 `public`。
- `format`: 输出格式。可选。默认为 `greptimedb_v1` 的 JSON 格式。
除了默认的 JSON 格式外,HTTP API 还允许你通过提供 `format` 查询参数来自定义输出格式,值如下:
- `influxdb_v1`: [influxdb 查询
API](https://docs.influxdata.com/influxdb/v1/tools/api/#query-http-endpoint)
兼容格式。附加参数:
- `epoch`: `[ns,u,µ,ms,s,m,h]`,返回指定精度的时间戳
- `csv`: 以逗号分隔值格式输出
- `csvWithNames`: 以逗号分隔值格式输出,包含列名标题
- `csvWithNamesAndTypes`: 以逗号分隔值格式输出,包含列名和数据类型标题
- `arrow`: [Arrow IPC
格式](https://arrow.apache.org/docs/python/feather.html)。此接口输出流式格式。附加参数:
- `compression`: `zstd` 或 `lz4`,默认:无压缩
- `table`: 控制台输出的 ASCII 表格格式
- `null`: 简洁的纯文本输出,仅显示行数和执行时间,用于评估查询性能。
### Body
- `sql`: SQL 语句。必填。
### 响应
响应是一个 JSON 对象,包含以下字段:
- `output`: SQL 执行结果,请参阅下面的示例以了解详细信息。
- `execution_time_ms`: 语句的执行时间(毫秒)。
### 示例
#### `INSERT` 语句
例如,要向数据库 `public` 的 `monitor` 表中插入数据,请使用以下命令:
```shell
curl -X POST \
-H 'Authorization: Basic {{authorization if exists}}' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d 'sql=INSERT INTO monitor VALUES ("127.0.0.1", 1667446797450, 0.1, 0.4), ("127.0.0.2", 1667446798450, 0.2, 0.3), ("127.0.0.1", 1667446798450, 0.5, 0.2)' \
http://localhost:4000/v1/sql?db=public
```
Response 包含受影响的行数:
```shell
{"output":[{"affectedrows":3}],"execution_time_ms":11}
```
#### `SELECT` 语句
你还可以使用 HTTP API 执行其他 SQL 语句。例如,从 `monitor` 表中查询数据:
```shell
curl -X POST \
-H 'Authorization: Basic {{authorization if exists}}' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d "sql=SELECT * FROM monitor" \
http://localhost:4000/v1/sql?db=public
```
Response 包含 JSON 格式的查询数据:
```json
{
"output": [
{
"records": {
"schema": {
"column_schemas": [
{
"name": "host",
"data_type": "String"
},
{
"name": "ts",
"data_type": "TimestampMillisecond"
},
{
"name": "cpu",
"data_type": "Float64"
},
{
"name": "memory",
"data_type": "Float64"
}
]
},
"rows": [
[
"127.0.0.1",
1720728000000,
0.5,
0.1
]
],
"total_rows": 1
}
}
],
"execution_time_ms": 7
}
```
Response 包含以下字段:
- `output`: 执行结果。
- `records`: 查询结果。
- `schema`: 结果的 schema,包括每列的 schema。
- `rows`: 查询结果的行,每行是一个包含 schema 中对应列值的数组。
- `execution_time_ms`: 语句的执行时间(毫秒)。
#### 时区
GreptimeDB 支持 HTTP 请求中的 `X-Greptime-Timezone` header。
它用于为当前 SQL 查询指定时区。
例如,以下请求使用时区 `+1:00` 进行查询:
```bash
curl -X POST \
-H 'Authorization: Basic {{authentication}}' \
-H 'X-Greptime-Timezone: +1:00' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d 'sql=SHOW VARIABLES time_zone;' \
http://localhost:4000/v1/sql
```
查询后的结果为:
```json
{
"output": [
{
"records": {
"schema": {
"column_schemas": [
{
"name": "TIME_ZONE",
"data_type": "String"
}
]
},
"rows": [
[
"+01:00"
]
]
}
}
],
"execution_time_ms": 27
}
```
有关时区如何影响数据的写入和查询,请参考[写入数据](/user-guide/ingest-data/for-iot/sql.md#time-zone)和[查询数据](/user-guide/query-data/sql.md#时区)部分中的 SQL 文档。
#### 使用 `table` 格式输出查询数据
你可以在查询字符串参数中使用 `table` 格式,以 ASCII 表格格式获取输出。
```shell
curl -X POST \
-H 'Authorization: Basic {{authorization if exists}}' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d "sql=SELECT * FROM monitor" \
http://localhost:4000/v1/sql?db=public&format=table
```
输出
```
┌─host────────┬─ts────────────┬─cpu─┬─memory─┐
│ "127.0.0.1" │ 1667446797450 │ 0.1 │ 0.4 │
│ "127.0.0.1" │ 1667446798450 │ 0.5 │ 0.2 │
│ "127.0.0.2" │ 1667446798450 │ 0.2 │ 0.3 │
└─────────────┴───────────────┴─────┴────────┘
```
#### 使用 `csvWithNames` 格式输出查询数据
```shell
curl -X POST \
-H 'Authorization: Basic {{authorization if exists}}' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d "sql=SELECT * FROM monitor" \
http://localhost:4000/v1/sql?db=public&format=csvWithNames
```
输出:
```csv
host,ts,cpu,memory
127.0.0.1,1667446797450,0.1,0.4
127.0.0.1,1667446798450,0.5,0.2
127.0.0.2,1667446798450,0.2,0.3
```
将 `format` 改为 `csvWithNamesAndTypes`:
```shell
curl -X POST \
-H 'Authorization: Basic {{authorization if exists}}' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d "sql=SELECT * FROM monitor" \
http://localhost:4000/v1/sql?db=public&format=csvWithNamesAndTypes
```
输出:
```csv
host,ts,cpu,memory
String,TimestampMillisecond,Float64,Float64
127.0.0.1,1667446797450,0.1,0.4
127.0.0.1,1667446798450,0.5,0.2
127.0.0.2,1667446798450,0.2,0.3
```
#### 使用 `influxdb_v1` 格式输出查询数据
你可以在查询字符串参数中使用 `influxdb_v1` 格式,以 InfluxDB 查询 API 兼容格式获取输出。
```shell
curl -X POST \
-H 'Authorization: Basic {{authorization if exists}}' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d "sql=SELECT * FROM monitor" \
http://localhost:4000/v1/sql?db=public&format=influxdb_v1&epoch=ms
```
```json
{
"results": [
{
"statement_id": 0,
"series": [
{
"name": "",
"columns": [
"host",
"ts",
"cpu",
"memory"
],
"values": [
["127.0.0.1", 1667446797450, 0.1, 0.4],
["127.0.0.1", 1667446798450, 0.5, 0.2],
["127.0.0.2", 1667446798450, 0.2, 0.3]
]
}
]
}
],
"execution_time_ms": 2
}
```
### 使用 GreptimeDB 的 SQL 方言解析 SQL
为了解析和理解使用 GreptimeDB SQL 方言编写的查询(例如在仪表盘等工具里,为了更好的用户体验,提前解析 SQL 获取表名等),您可以使用 `/v1/sql/parse` 接口来获取 SQL 查询的结构化结果:
```shell
curl -X POST \
-H 'Authorization: Basic {{authorization if exists}}' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-d "sql=SELECT * FROM monitor" \
http://localhost:4000/v1/sql/parse
```
```json
[
{
"Query": {
"inner": {
"with": null,
"body": {
"Select": {
"select_token": {
"token": {
"Word": {
"value": "SELECT",
"quote_style": null,
"keyword": "SELECT"
}
},
"span": {
"start": {
"line": 1,
"column": 1
},
"end": {
"line": 1,
"column": 7
}
}
},
"optimizer_hint": null,
"distinct": null,
"select_modifiers": null,
"top": null,
"top_before_distinct": false,
"projection": [
{
"Wildcard": {
"wildcard_token": {
"token": "Mul",
"span": {
"start": {
"line": 1,
"column": 8
},
"end": {
"line": 1,
"column": 9
}
}
},
"opt_ilike": null,
"opt_exclude": null,
"opt_except": null,
"opt_replace": null,
"opt_rename": null
}
}
],
"exclude": null,
"into": null,
"from": [
{
"relation": {
"Table": {
"name": [
{
"Identifier": {
"value": "monitor",
"quote_style": null,
"span": {
"start": {
"line": 1,
"column": 15
},
"end": {
"line": 1,
"column": 22
}
}
}
}
],
"alias": null,
"args": null,
"with_hints": [],
"version": null,
"with_ordinality": false,
"partitions": [],
"json_path": null,
"sample": null,
"index_hints": []
}
},
"joins": []
}
],
"lateral_views": [],
"prewhere": null,
"selection": null,
"connect_by": [],
"group_by": {
"Expressions": [
[],
[]
]
},
"cluster_by": [],
"distribute_by": [],
"sort_by": [],
"having": null,
"named_window": [],
"qualify": null,
"window_before_qualify": false,
"value_table_mode": null,
"flavor": "Standard"
}
},
"order_by": null,
"limit_clause": null,
"fetch": null,
"locks": [],
"for_clause": null,
"settings": null,
"format_clause": null,
"pipe_operators": []
},
"hybrid_cte": null
}
}
]
```
## POST PromQL 查询
### API 返回 Prometheus 查询结果格式
GreptimeDB 兼容 Prometheus 查询语言 (PromQL),可以用于查询 GreptimeDB 中的数据。
有关所有兼容的 API,请参阅 [Prometheus 查询语言](/user-guide/query-data/promql#prometheus-http-api) 文档。
### API 返回 GreptimeDB JSON 格式
GreptimeDB 同样暴露了一个自己的 HTTP API 用于 PromQL 查询,即在当前的 API 路径 `/v1` 的后方拼接 `/promql`。
该接口的返回值是 GreptimeDB 的 JSON 格式,而不是 Prometheus 的格式。
如下示例:
```shell
curl -X GET \
-H 'Authorization: Basic {{authorization if exists}}' \
-G \
--data-urlencode 'query=avg(system_metrics{idc="idc_a"})' \
--data-urlencode 'start=1667446797' \
--data-urlencode 'end=1667446799' \
--data-urlencode 'step=1s' \
'http://localhost:4000/v1/promql?db=public'
```
接口中的参数和 Prometheus' HTTP API 的 [`range_query`](https://prometheus.io/docs/prometheus/latest/querying/api/#range-queries) 接口相似:
- `db=`:在使用 GreptimeDB 进行鉴权操作时必填,如果使用的是 `public` 数据库则可以忽略该参数。注意这个参数需要被设置在 query param 中,或者通过 `--header 'x-greptime-db-name: '` 设置在 HTTP 请求头中。
- `query=`:必填。Prometheus 表达式查询字符串。
- `start=`:必填。开始时间戳,包含在内。它用于设置 `TIME INDEX` 列中的时间范围。
- `end=`:必填。结束时间戳,包含在内。它用于设置 `TIME INDEX` 列中的时间范围。
- `step=`:必填。查询步长,可以使用持续时间格式或秒数的浮点数。
- `format`: 输出格式。可选。默认为 `greptimedb_v1` 的 JSON 格式。
除了默认的 JSON 格式外,HTTP API 还允许你通过提供 `format` 查询参数来自定义输出格式,值如下:
- `influxdb_v1`: [influxdb 查询
API](https://docs.influxdata.com/influxdb/v1/tools/api/#query-http-endpoint)
兼容格式。附加参数:
- `epoch`: `[ns,u,µ,ms,s,m,h]`,返回指定精度的时间戳
- `csv`: 以逗号分隔值格式输出
- `csvWithNames`: 以逗号分隔值格式输出,包含列名标题
- `csvWithNamesAndTypes`: 以逗号分隔值格式输出,包含列名和数据类型标题
- `arrow`: [Arrow IPC
格式](https://arrow.apache.org/docs/python/feather.html)。附加参数:
- `compression`: `zstd` 或 `lz4`,默认:无压缩
- `table`: 控制台输出的 ASCII 表格格式
- `null`: 简洁的纯文本输出,仅显示行数和执行时间,用于评估查询性能。
以下是每种参数的类型的示例:
- rfc3339
- `2015-07-01T20:11:00Z` (default to seconds resolution)
- `2015-07-01T20:11:00.781Z` (with milliseconds resolution)
- `2015-07-02T04:11:00+08:00` (with timezone offset)
- unix timestamp
- `1435781460` (default to seconds resolution)
- `1435781460.781` (with milliseconds resolution)
- duration
- `1h` (1 hour)
- `5d1m` (5 days and 1 minute)
- `2` (2 seconds)
- `2s` (also 2 seconds)
结果格式与 [Post SQL 语句](#post-sql-语句)中描述的 `/sql` 接口相同。
```json
{
"output": [
{
"records": {
"schema": {
"column_schemas": [
{
"name": "ts",
"data_type": "TimestampMillisecond"
},
{
"name": "AVG(system_metrics.cpu_util)",
"data_type": "Float64"
},
{
"name": "AVG(system_metrics.memory_util)",
"data_type": "Float64"
},
{
"name": "AVG(system_metrics.disk_util)",
"data_type": "Float64"
}
]
},
"rows": [
[
1667446798000,
80.1,
70.3,
90
],
[
1667446799000,
80.1,
70.3,
90
]
]
}
}
],
"execution_time_ms": 5
}
```
## Post Influxdb line protocol 数据
```shell
curl -X POST \
-H 'Authorization: token {{username:password}}' \
-d '{{Influxdb-line-protocol-data}}' \
http://{{API-host}}/v1/influxdb/api/v2/write?precision={{time-precision}}
```
```shell
curl -X POST \
-d '{{Influxdb-line-protocol-data}}' \
http://{{API-host}}/v1/influxdb/write?u={{username}}&p={{password}}&precision={{time-precision}}
```
### Headers
- `Authorization`: **与其他 API 不同**,InfluxDB 行协议 API 使用 InfluxDB 鉴权格式。对于 V2 协议,Authorization 是 `token {{username:password}}`。
### Query string parameters
- `u`: 用户名。可选。它是 V1 的鉴权用户名。
- `p`: 密码。可选。它是 V1 的鉴权密码。
- `db`: 数据库名称。可选。默认值是 `public`。
- `precision`: 定义请求体中提供的时间戳的精度。请参考用户指南中的 [InfluxDB 行协议](/user-guide/ingest-data/for-iot/influxdb-line-protocol.md)文档。
### Body
InfluxDB 行协议数据点。请参考 [InfluxDB 行协议](https://docs.influxdata.com/influxdb/v1/write_protocols/line_protocol_tutorial/#syntax) 文档。
### 示例
请参考用户指南中的 [InfluxDB 行协议](/user-guide/ingest-data/for-iot/influxdb-line-protocol.md)。
## 管理 Pipeline 的 API
在将日志写入 GreptimeDB 时,你可以使用 HTTP API 来管理 Pipeline。
请参考 [管理 Pipeline](/user-guide/logs/manage-pipelines.md) 文档。
---
## InfluxDB Line Protocol(Protocols)
## 写入数据
请参考[写入数据](/user-guide/ingest-data/for-iot/influxdb-line-protocol.md)文档来了解如何使用 InfluxDB Line Protocol 向 GreptimeDB 写入数据。
## HTTP API
请参考 [HTTP API](http.md#post-influxdb-line-protocol-数据) 文档来了解 Influxdb Line Protocol 的接口详情。
## PING
GreptimeDB 同样支持 InfluxDB 的 `ping` 和 `health` API。
使用 `curl` 请求 `ping` API:
```shell
curl -i "127.0.0.1:4000/v1/influxdb/ping"
```
```shell
HTTP/1.1 204 No Content
date: Wed, 22 Feb 2023 02:29:44 GMT
```
Use `curl` to request `health` API.
```shell
curl -i "127.0.0.1:4000/v1/influxdb/health"
```
```shell
HTTP/1.1 200 OK
content-length: 0
date: Wed, 22 Feb 2023 02:30:46 GMT
```
---
## Loki(Protocols)
请参考[使用 Loki 协议写入数据](/user-guide/ingest-data/for-observability/loki.md)获取详细信息。
---
## MySQL
## 连接数据库
你可以通过 MySQL 连接到 GreptimeDB,端口为 `4002`。
```shell
mysql -h -P 4002 -u -p
```
- 请参考[鉴权认证](/user-guide/deployments-administration/authentication/overview.md) 来设置 GreptimeDB 的用户名和密码。
- 如果你想使用其他端口连接 MySQL,请参考配置文档中的[协议选项](/user-guide/deployments-administration/configuration.md#协议选项)。
## 管理表
请参考[表管理](/user-guide/deployments-administration/manage-data/basic-table-operations.md)。
## 写入数据
请参考[写入数据](/user-guide/ingest-data/for-iot/sql.md).
## 查询数据
请参考[查询数据](/user-guide/query-data/sql.md).
## 时区
GreptimeDB 的 MySQL 协议接口遵循原始 MySQL 服务器的 [时区处理方式](https://dev.mysql.com/doc/refman/8.0/en/time-zone-support.html)。
默认情况下,MySQL 使用服务器的时区来处理时间戳。要覆盖这一行为,可以使用 SQL 语句 `SET time_zone = '';` 来为当前会话设置 `time_zone` 变量。`time_zone` 的值可以是:
- 服务器的时区:`SYSTEM`。
- UTC 的偏移量,例如 `+08:00`。
- 任何时区的命名,例如 `Europe/Berlin`。
一些 MySQL 客户端,例如 Grafana 的 MySQL 数据源,允许你为当前会话设置时区。想要知道当前设定的时区,可以通过 SQL 语句 `SELECT @@time_zone;` 来查询。
你可以使用 `SELECT` 来查看当前的时区设置。例如:
```sql
SELECT @@system_time_zone, @@time_zone;
```
结果显示系统时区和会话时区都设置为 `UTC`:
```SQL
+--------------------+-------------+
| @@system_time_zone | @@time_zone |
+--------------------+-------------+
| UTC | UTC |
+--------------------+-------------+
```
将会话时区更改为 `+1:00`:
```SQL
SET time_zone = '+1:00'
```
你可以看到系统时区和会话时区之间的差异:
```SQL
SELECT @@system_time_zone, @@time_zone;
+--------------------+-------------+
| @@system_time_zone | @@time_zone |
+--------------------+-------------+
| UTC | +01:00 |
+--------------------+-------------+
```
有关时区如何影响数据的插入和查询,请参考 [写入数据](/user-guide/ingest-data/for-iot/sql.md#时区) 和 [查询数据](/user-guide/query-data/sql.md#时区) 中的 SQL 文档。
## 查询超时
可以通过 SQL 语句 `SET max_execution_time = ` 或 `SET MAX_EXECUTION_TIME = ` 为当前会话设置 `max_execution_time` 变量,该变量指定**只读语句**执行的最大时间(以毫秒为单位)。如果查询的执行时间超过指定时间,服务器将终止该查询。
例如,将最大执行时间设置为 10 秒:
```SQL
SET max_execution_time=10000;
```
---
## OpenTelemetry (OTLP)
GreptimeDB 可以通过 [OTLP/HTTP](https://opentelemetry.io/docs/specs/otlp/#otlphttp) 协议写入 OpenTelemetry 指标。
请参考[使用 OpenTelemetry 写入数据](/user-guide/ingest-data/for-observability/opentelemetry.md)文档获取详细信息。
---
## OpenTSDB(Protocols)
请参考[使用 OpenTSDB 写入数据](/user-guide/ingest-data/for-iot/opentsdb.md)获取详细信息。
---
## 协议
---
## PostgreSQL
## 连接数据库
你可以通过端口 `4003` 使用 PostgreSQL 连接到 GreptimeDB。
只需在命令中添加 `-U` 参数,后跟你的用户名和密码。以下是一个示例:
```shell
psql -h -p 4003 -U -d public
```
- 请参考[鉴权认证](/user-guide/deployments-administration/authentication/overview.md) 来设置 GreptimeDB 的用户名和密码。
- 如果你想使用其他端口连接 PostgreSQL,请参考配置文档中的[协议选项](/user-guide/deployments-administration/configuration.md#协议选项)。
## 管理表
请参考[管理表](/user-guide/deployments-administration/manage-data/basic-table-operations.md)。
## 写入数据
请参考[写入数据](/user-guide/ingest-data/for-iot/sql.md).
## 读取数据
请参考 [读取数据](../query-data/sql.md).
## 时区
GreptimeDB 的 PostgreSQL 协议遵循原始 PostgreSQL 的 [时区处理方式](https://www.postgresql.org/docs/current/datatype-datetime.html#DATATYPE-TIMEZONES)。
默认情况下,PostgreSQL 使用服务器的时区来处理时间戳。
你可以使用 SQL 语句 `SET TIMEZONE TO '';` 为当前会话设置 `time_zone` 变量来覆盖服务器时区。
`time_zone` 的值可以是:
- 时区的全称,例如 `America/New_York`。
- 时区的缩写,例如 `PST`。
- UTC 的偏移量,例如 `+08:00`。
你可以使用 `SHOW` 来查看当前的时区设置。例如:
```sql
SHOW VARIABLES time_zone;
```
```sql
TIME_ZONE
-----------
UTC
```
将会话时区更改为 `+1:00`:
```SQL
SET TIMEZONE TO '+1:00'
```
有关时区如何影响数据的插入和查询,请参考[写入数据](/user-guide/ingest-data/for-iot/sql.md#时区)和[查询数据](/user-guide/query-data/sql.md#时区)中的 SQL 文档。
## 外部数据
利用 Postgres 的 [FDW 扩
展](https://www.postgresql.org/docs/current/postgres-fdw.html),GreptimeDB 可以
被配置为 Postgres 的外部数据服务。这使得我们可以用 Postgres 服务器上无缝地查询
GreptimeDB 里的时序数据,并且可以利用 join 查询同时关联两边的数据。
举个例子,类似设备信息类的物联网元数据,通常存储在 Postgres 这样的关系型数据库中。
现在我们可以利用这个功能,先在 Postgres 利用关系查询过滤出满足条件的设备 ID,然
后直接关联的 GreptimeDB 承载的外部表上查询设备的时序数据。
### 配置
首先要确保 GreptimeDB 打开了 Postgres 协议,并且她可以被 Postgres 服务器访问到。
在 Postgres 上开启 fdw 扩展。
```sql
CREATE EXTENSION postgres_fdw;
```
将 GreptimeDB 添加为远程服务器。
```sql
CREATE SERVER greptimedb
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (host 'greptimedb_host', dbname 'public', port '4003');
```
把 Postgres 用户映射到 GreptimeDB 上。这一步是必须步骤。如果你没有在 GreptimeDB
开源版本上启用认证,这里可以填写任意的认证信息。
```sql
CREATE USER MAPPING FOR postgres
SERVER greptimedb
OPTIONS (user 'greptime', password '...');
```
在 Postgres 创建与 GreptimeDB 映射的外部表。这一步是为了告知 Postgres 相应表的数
据结构。注意需要将 GreptimeDB 的数据类型映射到 Postgres 类型上。
对于这样的 GreptimeDB 表:
```sql
CREATE TABLE grpc_latencies (
ts TIMESTAMP TIME INDEX,
host STRING,
method_name STRING,
latency DOUBLE,
PRIMARY KEY (host, method_name)
) with('append_mode'='true');
CREATE TABLE app_logs (
ts TIMESTAMP TIME INDEX,
host STRING,
api_path STRING FULLTEXT INDEX,
log_level STRING,
log STRING FULLTEXT INDEX,
PRIMARY KEY (host, log_level)
) with('append_mode'='true');
```
其 Postgres 外部表定义如下:
```sql
CREATE FOREIGN TABLE ft_grpc_latencies (
ts TIMESTAMP,
host VARCHAR,
method_name VARCHAR,
latency DOUBLE precision
)
SERVER greptimedb
OPTIONS (table_name 'grpc_latencies');
CREATE FOREIGN TABLE ft_app_logs (
ts TIMESTAMP,
host VARCHAR,
api_path VARCHAR,
log_level VARCHAR,
log VARCHAR
)
SERVER greptimedb
OPTIONS (table_name 'app_logs');
```
为了帮助用户生成这些语句,我们在 GreptimeDB 里增强了 `SHOW CREATE TABLE` 来直接
输出可执行的语句。
```sql
SHOW CREATE TABLE grpc_latencies FOR postgres_foreign_table;
```
注意在输出的语句中你需要把服务器名 `greptimedb` 替换为之前在 `CREATE SERVER` 语句
里使用的名字。
### 执行查询
至此你可以通过 Postgres 发起查询。并且可以使用一些同时存在于 GreptimeDB 和
Postgres 上的函数,如 `date_trunc` 等。
```sql
SELECT * FROM ft_app_logs ORDER BY ts DESC LIMIT 100;
SELECT
date_trunc('MINUTE', ts) as t,
host,
avg(latency),
count(latency)
FROM ft_grpc_latencies GROUP BY host, t;
```
## 语句执行超时
你可以通过 SQL 语句 `SET statement_timeout = ` 或 `SET STATEMENT_TIMEOUT = ` 为当前会话设置 `statement_timeout` 变量,该变量指定语句执行的最大时间(以毫秒为单位)。如果语句的执行时间超过指定时间,服务器将终止该语句。
例如,将最大执行时间设置为 10 秒:
```SQL
SET statement_timeout=10000;
```
---
## 公共表表达式(CTE)
CTE 与 [视图](./view.md) 类似,它们帮助您简化查询的复杂性,将长而复杂的 SQL 语句分解,并提高可读性和可重用性。
您已经在 [快速开始](/getting-started/quick-start.md#关联-metricslogs-和-traces) 文档中阅读了一个 CTE 的例子。
## 什么是公共表表达式(CTE)?
公共表表达式 (CTE) 是可以在 `SELECT`、`INSERT`、`UPDATE` 或 `DELETE` 语句中引用的临时结果集。CTE 有助于将复杂的查询分解成更可读的部分,并且可以在同一个查询中多次引用。
## CTE 的基本语法
CTE 通常使用 `WITH` 关键字定义。基本语法如下:
```sql
WITH cte_name [(column1, column2, ...)] AS (
QUERY
)
SELECT ...
FROM cte_name;
```
## 示例解释
接下来,我们将通过一个完整的示例来演示如何使用 CTE,包括数据准备、CTE 创建和使用。
### 步骤 1:创建示例数据
假设我们有以下两个表:
- `grpc_latencies`:包含 gRPC 请求延迟数据。
- `app_logs`:包含应用程序日志信息。
```sql
CREATE TABLE grpc_latencies (
ts TIMESTAMP TIME INDEX,
host VARCHAR(255),
latency FLOAT,
PRIMARY KEY(host),
);
INSERT INTO grpc_latencies VALUES
('2023-10-01 10:00:00', 'host1', 120),
('2023-10-01 10:00:00', 'host2', 150),
('2023-10-01 10:00:05', 'host1', 130);
CREATE TABLE app_logs (
ts TIMESTAMP TIME INDEX,
host VARCHAR(255),
`log` TEXT,
log_level VARCHAR(50),
PRIMARY KEY(host, log_level),
);
INSERT INTO app_logs VALUES
('2023-10-01 10:00:00', 'host1', 'Error on service', 'ERROR'),
('2023-10-01 10:00:00', 'host2', 'All services OK', 'INFO'),
('2023-10-01 10:00:05', 'host1', 'Error connecting to DB', 'ERROR');
```
### 步骤 2:定义和使用 CTE
我们将创建两个 CTE 来分别计算第 95 百分位延迟和错误日志的数量。
```sql
WITH
metrics AS (
SELECT
ts,
host,
approx_percentile_cont(0.95) WITHIN GROUP (ORDER BY latency) RANGE '5s' AS p95_latency
FROM
grpc_latencies
ALIGN '5s' FILL PREV
),
logs AS (
SELECT
ts,
host,
COUNT(*) RANGE '5s' AS num_errors
FROM
app_logs
WHERE
log_level = 'ERROR'
ALIGN '5s' BY (host)
)
SELECT
metrics.ts,
metrics.host,
metrics.p95_latency,
COALESCE(logs.num_errors, 0) AS num_errors
FROM
metrics
LEFT JOIN logs ON metrics.host = logs.host AND metrics.ts = logs.ts
ORDER BY
metrics.ts;
```
输出:
```sql
+---------------------+-------+-------------+------------+
| ts | host | p95_latency | num_errors |
+---------------------+-------+-------------+------------+
| 2023-10-01 10:00:00 | host2 | 150 | 0 |
| 2023-10-01 10:00:00 | host1 | 120 | 1 |
| 2023-10-01 10:00:05 | host1 | 130 | 1 |
+---------------------+-------+-------------+------------+
```
### 详细说明
1. **定义 CTEs**:
- `metrics`:
```sql
metrics AS (
SELECT
ts,
host,
approx_percentile_cont(0.95) WITHIN GROUP (ORDER BY latency) RANGE '5s' AS p95_latency
FROM
grpc_latencies
ALIGN '5s' FILL PREV
),
```
这里我们使用[范围查询](/user-guide/query-data/sql.md#按时间窗口聚合数据)计算每个 `host` 在每个 5 秒时间窗口内的第 95 百分位延迟。
- `logs`:
```sql
logs AS (
SELECT
ts,
host,
COUNT(*) RANGE '5s' AS num_errors
FROM
app_logs
WHERE
log_level = 'ERROR'
ALIGN '5s' BY (host)
)
```
同样地,我们计算每个 `host` 在每个 5 秒时间窗口内的错误日志数量。
2. **使用 CTEs**:
在最终的查询部分:
```sql
SELECT
metrics.ts,
metrics.host,
metrics.p95_latency,
COALESCE(logs.num_errors, 0) AS num_errors
FROM
metrics
LEFT JOIN logs ON metrics.host = logs.host AND metrics.ts = logs.ts
ORDER BY
metrics.ts;
```
我们对两个 CTE 结果集进行左连接,以获得最终的综合分析结果。
## 在 CTE 中使用 TQL
GreptimeDB 支持在 CTE 中使用 [TQL](/reference/sql/tql.md)(Telemetry 查询语言),将 PromQL 的时序计算能力与 SQL 强大的后处理能力(过滤、JOIN、聚合等)相结合。
### 基本语法
```sql
WITH cte_name AS (
TQL EVAL (start, end, step) promql_expression AS value_alias
)
SELECT * FROM cte_name;
```
### 关键点
1. **列名**:
- 时间索引列名取决于表结构(例如,自定义表使用 `ts`,Prometheus 远程写入的默认使用 `greptime_timestamp`)
- 值的列名取决于 PromQL 表达式,可能无法预测,因此更推荐使用 TQL 中的 `AS` 进行值别名以确保可预测的值列名:`TQL EVAL (...) expression AS my_value`
- **重要**:一般情况下不建议在 CTE 定义中使用列别名(如 `WITH cte_name (ts, val) AS (...)`),因为 TQL EVAL 结果的列数量和顺序可能变化,特别是在 Prometheus 场景中标签可能动态添加或删除。更适合在结果列稳定的场景使用,例如简单的 `CREATE FLOW` TQL CTE。
2. **支持的命令**:CTE 中仅支持 `TQL EVAL`。不能在 CTE 中使用 `TQL ANALYZE` 和 `TQL EXPLAIN`。
3. **回溯参数**:可选的第四个参数控制回溯持续时间(默认:5 分钟)。
4. **在 `CREATE FLOW` 中使用 TQL CTE**:GreptimeDB 支持在 `CREATE FLOW` 中写 `WITH ... AS (TQL EVAL ...)`,但只支持最简单的形式:单个 TQL CTE,后面紧跟 `SELECT * FROM `。Flow 定义里不支持额外 SQL CTE、过滤、JOIN 或自定义列投影。
### 示例
以下示例使用 Kubernetes 监控指标来演示实际用例。
#### 使用 SQL 过滤 TQL 结果
此示例使用 PromQL 计算每个 Pod 的 CPU 使用率,然后使用 SQL 过滤和排序结果:
```sql
WITH cpu_usage AS (
TQL EVAL (now() - interval '1' hour, now(), '5m')
sum by (namespace, pod) (rate(container_cpu_usage_seconds_total{container!=""}[5m]))
AS cpu_cores
)
SELECT
greptime_timestamp as ts,
namespace,
pod,
cpu_cores
FROM cpu_usage
WHERE cpu_cores > 0.5
ORDER BY cpu_cores DESC;
```
#### 关联多个指标
此示例展示了 PromQL 单独无法实现的能力:关联不同指标进行分析。它将 CPU 使用率与请求速率关联,以分析资源效率:
```sql
WITH
cpu_data AS (
TQL EVAL (now() - interval '1' hour, now(), '5m')
sum by (pod) (rate(container_cpu_usage_seconds_total{container!=""}[5m]))
AS cpu_cores
),
request_data AS (
TQL EVAL (now() - interval '1' hour, now(), '5m')
sum by (pod) (rate(http_requests_total[5m]))
AS req_per_sec
)
SELECT
c.greptime_timestamp as ts,
c.pod,
c.cpu_cores,
r.req_per_sec
FROM cpu_data c
JOIN request_data r
ON c.greptime_timestamp = r.greptime_timestamp
AND c.pod = r.pod
WHERE r.req_per_sec > 1;
```
在 JOIN 多个 TQL CTE 时,请确保:
- `by (...)` 子句包含匹配的维度
- JOIN 条件包含时间戳和标签列
## 总结
通过 CTE,您可以将复杂的 SQL 查询分解为更易于管理和理解的部分。在本示例中,我们分别创建了两个 CTE 来计算第 95 百分位延迟和错误日志的数量,然后将它们合并到最终查询中进行分析。CTE 中的 TQL 支持通过将 PromQL 风格的查询与 SQL 处理无缝集成来扩展这种能力。阅读更多关于 [WITH](/reference/sql/with.md) 和 [TQL](/reference/sql/tql.md) 的内容。
更多 TQL + CTE 示例请参阅博客文章[当 PromQL 遇上 SQL:用混合查询解锁 Kubernetes 监控分析](https://greptime.cn/blogs/2026-01-08-tql-alias-k8s-monitoring)。
---
## Jaeger 查询(实验功能)
:::warning
Jaeger 查询接口目前仍处于实验阶段,在未来的版本中可能会有所调整。
:::
GreptimeDB 目前支持以下 [Jaeger](https://www.jaegertracing.io/) 查询接口:
- `/api/services`: 获取所有 Service。
- `/api/operations?service={service}`: 获取指定 Service 的所有 Operations。
- `/api/services/{service}/operations`: 获取指定 Service 的所有 Operations。
- `/api/traces`: 根据查询参数获取 traces 数据。
你可以使用 Grafana 的 [Jaeger 插件](https://grafana.com/docs/grafana/latest/datasources/jaeger/)(推荐) 或者 [Jaeger UI](https://github.com/jaegertracing/jaeger-ui) 来查询 GreptimeDB 中的 traces 数据。当你在使用 Jaeger UI 的时候,可将 `packages/jaeger-ui/vite.config.mts` 的 `proxyConfig` 配置为 GreptimeDB 的地址,比如:
```ts
const proxyConfig = {
target: 'http://localhost:4000/v1/jaeger',
secure: false,
changeOrigin: true,
ws: true,
xfwd: true,
};
```
目前 GreptimeDB 对 Jaeger 协议接口在 `/v1/jaeger` 路径下。
## 快速开始
我们将以 Grafana 中使用 Jaeger 插件为例,介绍如何查询 GreptimeDB 中的 traces 数据。在开始之前,请确保你已经正常启动了 GreptimeDB。
### 启动应用生成 traces 数据并写入 GreptimeDB
你可以参考 [OpenTelemetry 官方文档](https://opentelemetry.io/docs/languages/) 来选择任意你熟悉的编程语言来生成 traces 并将其写入到 GreptimeDB 中。你也可以参考[配置 OpenTelemetry Collector](/user-guide/traces/read-write.md#opentelemetry-collector) 文档。
### 配置 Jaeger 插件
1. 打开 Grafana,添加 Jaeger 数据源:
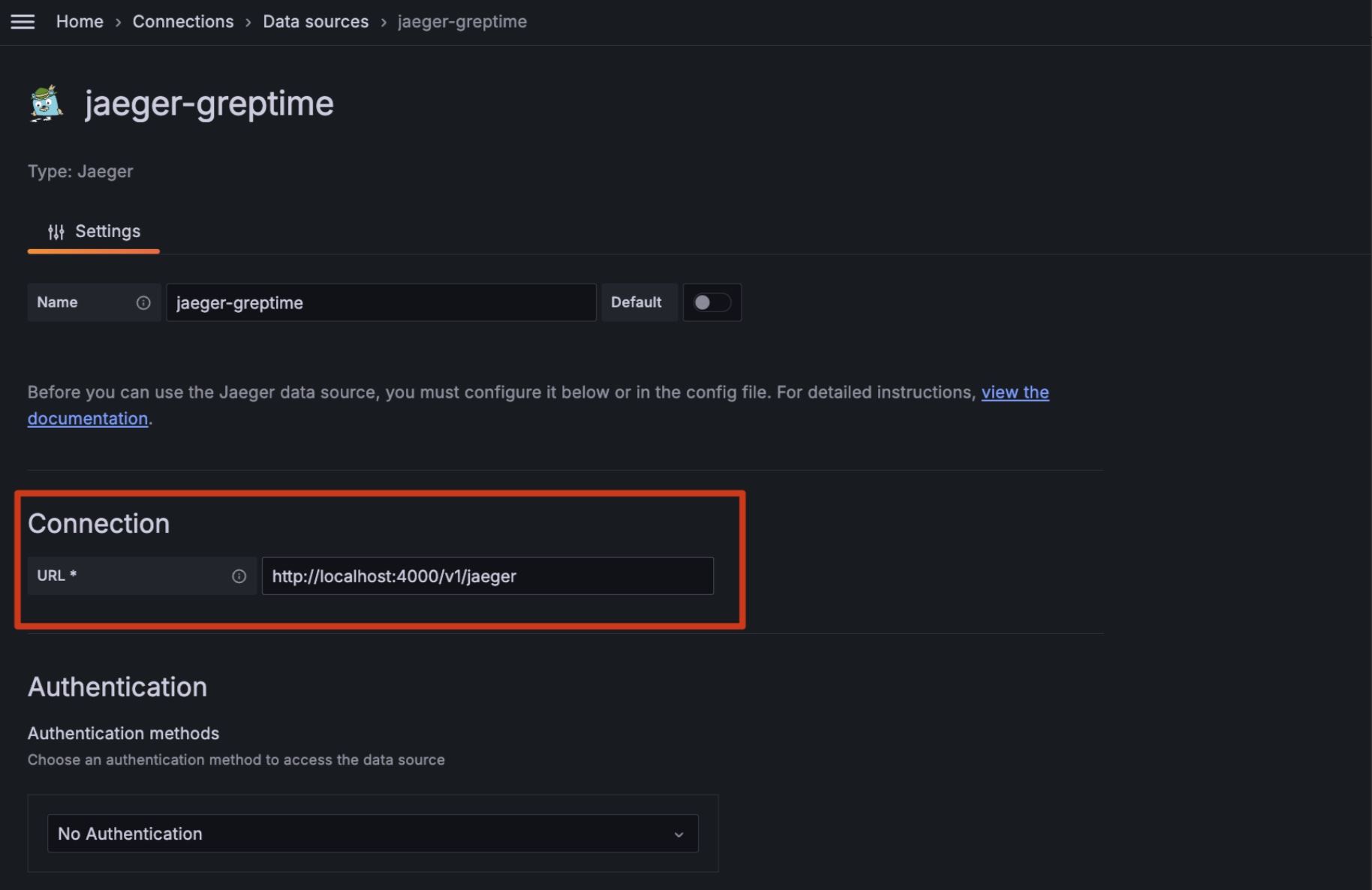
2. 根据实际情况,填写 Jaeger 地址,然后 **Save and Test** 即可。比如:
```
http://localhost:4000/v1/jaeger
```
3. 使用 Jaeger Explore 来查看数据:
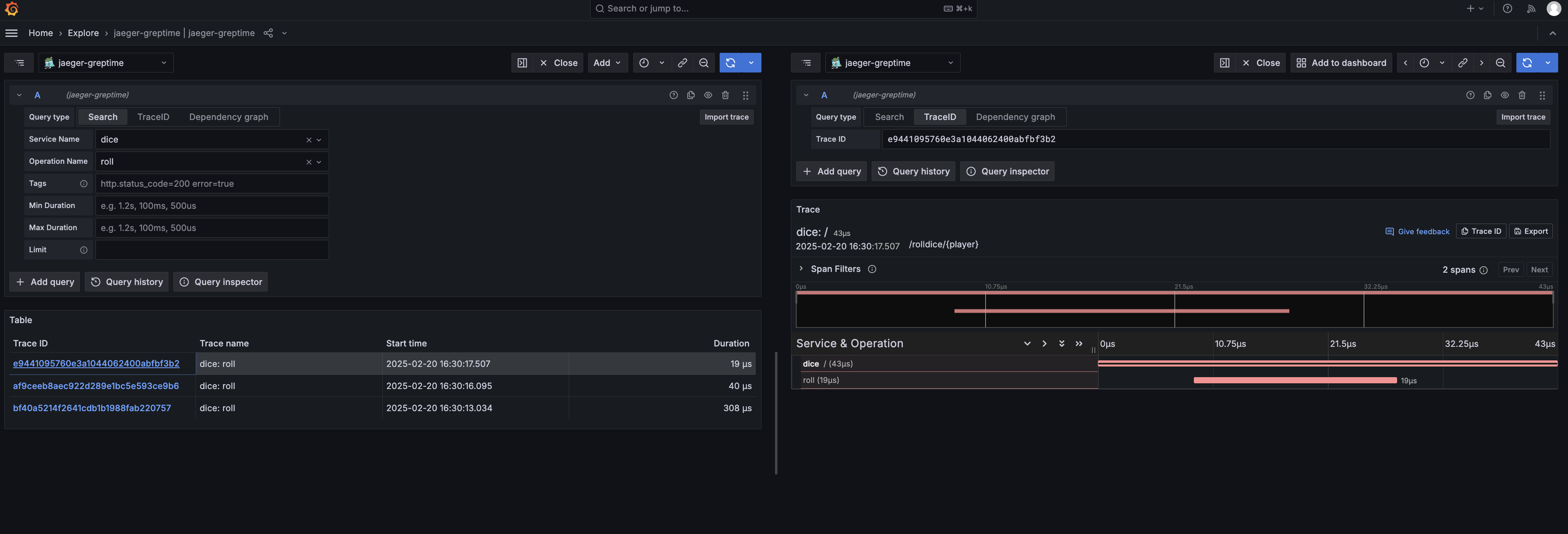
### 自定义数据表
GreptimeDB 的 Jaeger 兼容接口默认使用 `opentelemetry_traces` 表作为其数据源。如
果用户使用了其他表,可以通过 HTTP 头 `x-greptime-trace-table-name` 进行设置。
Grafana 用户可以在数据源的配置界面进行设置。
---
## 日志查询(实验功能)
:::warning
日志查询接口目前仍处于实验阶段,在未来的版本中可能会有所调整。
:::
GreptimeDB 提供了一个专门用于查询日志数据的 HTTP 接口。通过这个功能,你可以使用简单的查询界面来搜索和处理日志记录。这是对 GreptimeDB 现有功能(如 SQL 查询和 Flow 计算)的补充。你仍然可以像之前一样使用已有的工具和工作流程来查询日志数据。
## 接口地址
```http
POST /v1/logs
```
## 请求头
- [认证](/user-guide/protocols/http.md#authentication)
- `Content-Type`: `application/json`
## 请求格式
请求体应为 JSON 格式(在实验阶段可能会随补丁版本有所变化)。关于最新的请求格式,请参考[源代码实现](https://github.com/GreptimeTeam/greptimedb/blob/main/src/log-query/src/log_query.rs):
## 响应格式
此接口的响应格式与 SQL 查询接口相同。详情请参阅 [SQL 查询响应格式](/user-guide/protocols/http/#response)。
## 使用限制
- 最大结果数量:1000 条记录
- 仅支持包含时间戳和字符串列的表格
## 使用示例
以下示例展示了如何使用日志查询接口来查询日志数据(请注意,在实验性阶段这个例子可能会失效):
```shell
curl -X "POST" "http://localhost:4000/v1/logs" \
-H "Authorization: Basic {{authentication}}" \
-H "Content-Type: application/json" \
-d $'
{
"table": {
"catalog_name": "greptime",
"schema_name": "public",
"table_name": "my_logs"
},
"time_filter": {
"start": "2025-01-23"
},
"limit": {
"fetch": 1
},
"columns": [
"message"
],
"filters": [
{
"column_name": "message",
"filters": [
{
"Contains": "production"
}
]
}
],
"context": "None",
"exprs": []
}
'
```
在这个查询中,我们在 `greptime.public.my_logs` 表中搜索 `message` 字段包含 `production` 的日志记录。我们还设定了时间过滤条件,只获取 `2025-01-23` 当天的日志,并将结果限制为仅返回 1 条记录。
响应结果类似于以下内容:
```json
{
"output": [
{
"records": {
"schema": {
"column_schemas": [
{
"name": "message",
"data_type": "String"
}
]
},
"rows": [
[
"Everything is in production"
]
],
"total_rows": 1
}
}
],
"execution_time_ms": 30
}
```
---
## 查询数据
## 查询语言
- [SQL](./sql.md)
- [PromQL](promql.md)
- [Log Query](./log-query.md) (实验性功能)
从 v0.9 开始,GreptimeDB 开始支持查询视图和公共表表达式(CTE),用于简化查询语句:
* [View](./view.md)
* [公共表表达式(CTE)](./cte.md)
## 推荐的查询库
由于 GreptimeDB 使用 SQL 作为主要查询语言,并支持 [MySQL](/user-guide/protocols/mysql.md) 和 [PostgreSQL](/user-guide/protocols/postgresql.md) 协议,
你可以使用支持 MySQL 或 PostgreSQL 的成熟 SQL Driver 来查询数据。
有关更多信息,请参考[SQL 工具](/reference/sql-tools.md)文档。
## 查询外部数据
GreptimeDB 具有查询外部数据文件的能力,更多信息请参考[查询外部数据](./query-external-data.md)文档。
---
## Prometheus Query Language
GreptimeDB 可以作为 Grafana 中 Prometheus 的替代品,因为 GreptimeDB 支持 PromQL(Prometheus Query Language)。GreptimeDB 在 Rust 中重新实现了 PromQL,并通过接口将能力开放,包括 Prometheus 的 HTTP API、GreptimeDB 的 HTTP API 和 SQL 接口。
## Prometheus 的 HTTP API
GreptimeDB 实现了兼容 Prometheus 的一系列 API,通过 `/v1/prometheus` 路径对外提
供服务:
- Instant queries `/api/v1/query`
- Range queries `/api/v1/query_range`
- Series `/api/v1/series`
- Label names `/api/v1/labels`
- Label values `/api/v1/label//values`
这些接口的输入和输出与原生的 Prometheus HTTP API 相同,用户可以把 GreptimeDB 当
作 Prometheus 的直接替换。例如,在 Grafana 中我们可以设置
`http://localhost:4000/v1/prometheus/` 作为其 Prometheus 数据源的地址。
访问 [Prometheus 文档](https://prometheus.io/docs/prometheus/latest/querying/api)
获得更详细的说明。
你可以通过设置 HTTP 请求的 `db` 参数来指定 GreptimeDB 中的数据库名。
例如,以下查询将返回 `public` 数据库中 `process_cpu_seconds_total` 指标的 CPU 使用率:
```shell
curl -X POST \
-H 'Authorization: Basic {{authorization if exists}}' \
--data-urlencode 'query=irate(process_cpu_seconds_total[1h])' \
--data-urlencode 'start=2024-11-24T00:00:00Z' \
--data-urlencode 'end=2024-11-25T00:00:00Z' \
--data-urlencode 'step=1h' \
'http://localhost:4000/v1/prometheus/api/v1/query_range?db=public'
```
如果你使用启用了身份验证的 GreptimeDB,则需要 Authorization header,请参阅[鉴权](/user-guide/protocols/http.md#鉴权)。
该 API 的查询字符串参数与原始 [Prometheus API](https://prometheus.io/docs/prometheus/latest/querying/api/#range-queries) 的查询字符串参数相同。
你需要在 HTTP 的 query param 设置 `db` 参数,或者通过 `--header 'x-greptime-db-name: '` 设置在 HTTP 请求头中。
输出格式与 Prometheus API 完全兼容:
```json
{
"status": "success",
"data": {
"resultType": "matrix",
"result": [
{
"metric": {
"job": "node",
"instance": "node_exporter:9100",
"__name__": "process_cpu_seconds_total"
},
"values": [
[
1732618800,
"0.0022222222222222734"
],
[
1732622400,
"0.0009999999999999788"
],
[
1732626000,
"0.0029999999999997585"
],
[
1732629600,
"0.002222222222222175"
]
]
}
]
}
}
```
## SQL
GreptimeDB 还扩展了 SQL 语法以支持 PromQL。可以用 `TQL`(Time-series Query Language)为关键字开始写入参数和进行查询。该语法如下:
```sql
TQL [EVAL|EVALUATE] (, , )
```
`` 指定查询开始时间范围,`` 指定查询结束时间。 `` 识别查询步幅。它们均可为无引号数字(表示``和``的 UNIX 时间戳,以及``的秒数持续时间),或带引号的字符串(表示``和``的 RFC3339 时间戳,以及``的字符串格式的持续时间)。
例如:
```sql
TQL EVAL (1676738180, 1676738780, '10s') sum(some_metric)
```
你可以在所有支持 SQL 的地方编写上述命令,包括 GreptimeDB HTTP API、SDK、PostgreSQL 和 MySQL 客户端等。
## GreptimeDB 的扩展
### 指定数值列
基于表模型,GreptimeDB 支持在单个表(或在 Prometheus 中称为指标)中查询多个字段。默认情况下,查询将应用于每个值字段 (field)。或者也可以使用特殊的过滤器 `__field__` 来查询特定的字段:
```promql
metric{__field__="field1"}
```
反选或正则表达式也都支持
```promql
metric{__field__!="field1"}
metric{__field__=~"field_1|field_2"}
metric{__field__!~"field_1|field_2"}
```
### 指定数据库
不同于 Prometheus,GreptimeDB 包含数据库概念。如果要进行跨数据库的 PromQL 查询,
可以使用 `__database__` 来指定数据库名称。
```promql
metric{__database__="mydatabase"}
```
注意 `__database__` 仅支持 `=` 匹配。
## 局限
尽管 GreptimeDB 支持丰富的数据类型,但 PromQL 的实现仍然局限于以下类型:
- timestamp: `Timestamp`
- tag: `String`
- value: `Double`
GreptimeDB 目前已实现了大部分(超过 90%)的 PromQL 功能。您可以在下方查看详细的兼容性列表,或者通过此 [issue](https://github.com/GreptimeTeam/greptimedb/issues/1042) 了解我们最新的功能支持情况。
选择器引用不存在的列时,其行为与 Prometheus 一致:不报错且选择器会被静默忽略。但若 `__name__` 选择器引用了不存在的指标(或等效形式),GreptimeDB 则会报告错误。
支持字符串和浮点数,与 PromQL 的[规则](https://prometheus.io/docs/prometheus/latest/querying/basics/#literals)相同。
### 选择器
Instant 选择器和 Range 选择器均已支持。需要注意的是,在 Prometheus 和 GreptimeDB 中,指标名称的标签匹配有一个特殊限制:不支持反向匹配(例如 `{__name__!="request_count"}`)。但其他匹配方式,如等值匹配和正则匹配都是完全支持的。
时间区间和时间偏移修饰符均已支持,但目前尚未支持 `@` 修饰符。
当选择不存在的列时,它们将被视为一个所有值都为 `""` 的列。该行为与 Prometheus 和 VictoriaMetrics 一致。
### 时间精度
PromQL 的时间戳精度受制于查询语法的限制,最高只支持毫秒级精度的计算。然而,GreptimeDB 支持存储微秒和纳秒等高精度时间。在使用 PromQL 进行计算时,这些高精度时间将被隐式转换为毫秒精度进行计算。
### Binary
- 支持:
| Operator |
| :------- |
| add |
| sub |
| mul |
| div |
| mod |
| eqlc |
| neq |
| gtr |
| lss |
| gte |
| lte |
| power |
| atan2 |
| and |
| or |
| unless |
- 不支持:
无
### Aggregators
- 支持:
| Aggregator | Example |
| :----------- | :------------------------------------------- |
| sum | `sum by (foo)(metric)` |
| avg | `avg by (foo)(metric)` |
| min | `min by (foo)(metric)` |
| max | `max by (foo)(metric)` |
| stddev | `stddev by (foo)(metric)` |
| stdvar | `stdvar by (foo)(metric)` |
| topk | `topk(3, rate(instance_cpu_time_ns[5m]))` |
| bottomk | `bottomk(3, rate(instance_cpu_time_ns[5m]))` |
| count_values | `count_values("version", build_version)` |
| count | `count (metric)` |
| quantile | `quantile(0.9, cpu_usage)` |
- 不支持:
| Aggregator | Progress |
| :--------- | :------- |
| count | TBD |
| grouping | TBD |
### Instant Functions
- 支持:
| Function | Example |
| :----------------- | :-------------------------------- |
| abs | `abs(metric)` |
| ceil | `ceil(metric)` |
| exp | `exp(metric)` |
| ln | `ln(metric)` |
| log2 | `log2(metric)` |
| log10 | `log10(metric)` |
| sqrt | `sqrt(metric)` |
| acos | `acos(metric)` |
| asin | `asin(metric)` |
| atan | `atan(metric)` |
| sin | `sin(metric)` |
| cos | `cos(metric)` |
| tan | `tan(metric)` |
| acosh | `acosh(metric)` |
| asinh | `asinh(metric)` |
| atanh | `atanh(metric)` |
| sinh | `sinh(metric)` |
| cosh | `cosh(metric)` |
| scalar | `scalar(metric)` |
| tanh | `tanh(metric)` |
| timestamp | `timestamp()` |
| sort | `sort(http_requests_total)` |
| sort_desc | `sort_desc(http_requests_total)` |
| histogram_quantile | `histogram_quantile(phi, metric)` |
| predicate_linear | `predict_linear(metric, 120)` |
| absent | `absent(nonexistent{job="myjob"})`|
| sgn | `sgn(metric)` |
| pi | `pi()` |
| deg | `deg(metric)` |
| rad | `rad(metric)` |
| floor | `floor(metric)` |
| clamp | `clamp(metric, 0, 12)` |
| clamp_max | `clamp_max(metric, 12)` |
| clamp_min | `clamp_min(metric, 0)` |
- 不支持:
| Function | Progress |
| :------------------------- | :------- |
| *other multiple input fns* | TBD |
### Range Functions
- 支持:
| Function | Example |
| :----------------- | :----------------------------- |
| idelta | `idelta(metric[5m])` |
| \_over_time | `count_over_time(metric[5m])` |
| stddev_over_time | `stddev_over_time(metric[5m])` |
| stdvar_over_time | `stdvar_over_time(metric[5m])` |
| changes | `changes(metric[5m])` |
| delta | `delta(metric[5m])` |
| rate | `rate(metric[5m])` |
| deriv | `deriv(metric[5m])` |
| increase | `increase(metric[5m])` |
| irate | `irate(metric[5m])` |
| reset | `reset(metric[5m])` |
- 不支持:
无
### Label 及其他函数
- 支持:
| Function | Example |
| :------------ | :------------------------------------------------------------------------------------------------ |
| label_join | `label_join(up{job="api-server",src1="a",src2="b",src3="c"}, "foo", ",", "src1", "src2", "src3")` |
| label_replace | `label_replace(up{job="api-server",service="a:c"}, "foo", "$1", "service", "(.*):.*")` |
| sort_by_label | `sort_by_label(metric, "foo", "bar")` |
| sort_by_label_desc | `sort_by_label_desc(metric, "foo", "bar")` |
- 不支持:
无
---
## 查询外部数据
## 对文件进行查询
目前,我们支持 `Parquet`、`CSV`、`ORC` 和 `NDJson` 格式文件的查询。
以 [Taxi Zone Lookup Table](https://d37ci6vzurychx.cloudfront.net/misc/taxi+_zone_lookup.csv) 数据为例。
```bash
curl "https://d37ci6vzurychx.cloudfront.net/misc/taxi+_zone_lookup.csv" -o /tmp/taxi+_zone_lookup.csv
```
创建一个外部表:
```sql
CREATE EXTERNAL TABLE taxi_zone_lookup with (location='/tmp/taxi+_zone_lookup.csv',format='csv');
```
检查外部表的组织和结构:
```sql
DESC TABLE taxi_zone_lookup;
```
```sql
+--------------------+----------------------+------+------+--------------------------+---------------+
| Column | Type | Key | Null | Default | Semantic Type |
+--------------------+----------------------+------+------+--------------------------+---------------+
| LocationID | Int64 | | YES | | FIELD |
| Borough | String | | YES | | FIELD |
| Zone | String | | YES | | FIELD |
| service_zone | String | | YES | | FIELD |
| greptime_timestamp | TimestampMillisecond | PRI | NO | 1970-01-01 00:00:00+0000 | TIMESTAMP |
+--------------------+----------------------+------+------+--------------------------+---------------+
4 rows in set (0.00 sec)
```
:::tip 注意
在这里,你可能会注意到出现了一个 `greptime_timestamp` 列,这个列作为表的时间索引列,在文件中并不存在。这是因为在创建外部表时,我们没有指定时间索引列,`greptime_timestamp` 列被自动添加作为时间索引列,并且默认值为 `1970-01-01 00:00:00+0000`。你可以在 [create](/reference/sql/create.md#create-external-table) 文档中查找更多详情。
:::
现在就可以查询外部表了:
```sql
SELECT `Zone`, `Borough` FROM taxi_zone_lookup LIMIT 5;
```
```sql
+-------------------------+---------------+
| Zone | Borough |
+-------------------------+---------------+
| Newark Airport | EWR |
| Jamaica Bay | Queens |
| Allerton/Pelham Gardens | Bronx |
| Alphabet City | Manhattan |
| Arden Heights | Staten Island |
+-------------------------+---------------+
```
## 对目录进行查询
首先下载一些数据:
```bash
mkdir /tmp/external
curl "https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2022-01.parquet" -o /tmp/external/yellow_tripdata_2022-01.parquet
curl "https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2022-02.parquet" -o /tmp/external/yellow_tripdata_2022-02.parquet
```
验证下载情况:
```bash
ls -l /tmp/external
total 165368
-rw-r--r-- 1 wenyxu wheel 38139949 Apr 28 14:35 yellow_tripdata_2022-01.parquet
-rw-r--r-- 1 wenyxu wheel 45616512 Apr 28 14:36 yellow_tripdata_2022-02.parquet
```
创建外部表
```sql
CREATE EXTERNAL TABLE yellow_tripdata with(location='/tmp/external/',format='parquet');
```
执行查询:
```sql
SELECT count(*) FROM yellow_tripdata;
```
```sql
+-----------------+
| COUNT(UInt8(1)) |
+-----------------+
| 5443362 |
+-----------------+
1 row in set (0.48 sec)
```
```sql
SELECT * FROM yellow_tripdata LIMIT 5;
```
```sql
+----------+----------------------+-----------------------+-----------------+---------------+------------+--------------------+--------------+--------------+--------------+-------------+-------+---------+------------+--------------+-----------------------+--------------+----------------------+-------------+---------------------+
| VendorID | tpep_pickup_datetime | tpep_dropoff_datetime | passenger_count | trip_distance | RatecodeID | store_and_fwd_flag | PULocationID | DOLocationID | payment_type | fare_amount | extra | mta_tax | tip_amount | tolls_amount | improvement_surcharge | total_amount | congestion_surcharge | airport_fee | greptime_timestamp |
+----------+----------------------+-----------------------+-----------------+---------------+------------+--------------------+--------------+--------------+--------------+-------------+-------+---------+------------+--------------+-----------------------+--------------+----------------------+-------------+---------------------+
| 1 | 2022-02-01 00:06:58 | 2022-02-01 00:19:24 | 1 | 5.4 | 1 | N | 138 | 252 | 1 | 17 | 1.75 | 0.5 | 3.9 | 0 | 0.3 | 23.45 | 0 | 1.25 | 1970-01-01 00:00:00 |
| 1 | 2022-02-01 00:38:22 | 2022-02-01 00:55:55 | 1 | 6.4 | 1 | N | 138 | 41 | 2 | 21 | 1.75 | 0.5 | 0 | 6.55 | 0.3 | 30.1 | 0 | 1.25 | 1970-01-01 00:00:00 |
| 1 | 2022-02-01 00:03:20 | 2022-02-01 00:26:59 | 1 | 12.5 | 1 | N | 138 | 200 | 2 | 35.5 | 1.75 | 0.5 | 0 | 6.55 | 0.3 | 44.6 | 0 | 1.25 | 1970-01-01 00:00:00 |
| 2 | 2022-02-01 00:08:00 | 2022-02-01 00:28:05 | 1 | 9.88 | 1 | N | 239 | 200 | 2 | 28 | 0.5 | 0.5 | 0 | 3 | 0.3 | 34.8 | 2.5 | 0 | 1970-01-01 00:00:00 |
| 2 | 2022-02-01 00:06:48 | 2022-02-01 00:33:07 | 1 | 12.16 | 1 | N | 138 | 125 | 1 | 35.5 | 0.5 | 0.5 | 8.11 | 0 | 0.3 | 48.66 | 2.5 | 1.25 | 1970-01-01 00:00:00 |
+----------+----------------------+-----------------------+-----------------+---------------+------------+--------------------+--------------+--------------+--------------+-------------+-------+---------+------------+--------------+-----------------------+--------------+----------------------+-------------+---------------------+
5 rows in set (0.11 sec)
```
:::tip 注意
查询结果中包含 `greptime_timestamp` 列的值,尽管它在原始文件中并不存在。这个列的所有值均为 `1970-01-01 00:00:00+0000`,这是因为我们在创建外部表时,自动添加列 `greptime_timestamp`,并且默认值为 `1970-01-01 00:00:00+0000`。你可以在 [create](/reference/sql/create.md#create-external-table) 文档中查找更多详情。
:::
---
## SQL(Query-data)
GreptimeDB 在查询数据时支持完整的 `SQL` 语法。
在这篇文档中,我们将使用 `monitor` 表中的数据作为示例来演示如何查询数据。关于如何创建 `monitor` 表格并向其中插入数据,请参考[表管理](/user-guide/deployments-administration/manage-data/basic-table-operations.md#创建表)和[写入数据](/user-guide/ingest-data/for-iot/sql.md)。
## 基础查询
通过 `SELECT` 语句来查询数据。例如,下面的查询返回 `monitor` 表中的所有数据:
```sql
SELECT * FROM monitor;
```
查询结果如下:
```sql
+-----------+---------------------+------+--------+
| host | ts | cpu | memory |
+-----------+---------------------+------+--------+
| 127.0.0.1 | 2022-11-03 03:39:57 | 0.1 | 0.4 |
| 127.0.0.1 | 2022-11-03 03:39:58 | 0.5 | 0.2 |
| 127.0.0.2 | 2022-11-03 03:39:58 | 0.2 | 0.3 |
+-----------+---------------------+------+--------+
3 rows in set (0.00 sec)
```
`SELECT` 字段列表中也支持使用函数。
例如,你可以使用 `count()` 函数来获取表中的总行数:
```sql
SELECT count(*) FROM monitor;
```
```sql
+-----------------+
| COUNT(UInt8(1)) |
+-----------------+
| 3 |
+-----------------+
```
使用函数 `avg()` 返回某个字段的平均值:
```sql
SELECT avg(cpu) FROM monitor;
```
```sql
+---------------------+
| AVG(monitor.cpu) |
+---------------------+
| 0.26666666666666666 |
+---------------------+
1 row in set (0.00 sec)
```
你还可以只返回函数的结果,例如从时间戳中提取一年中的第几天。
SQL 语句中的 `DOY` 是 `day of the year` 的缩写:
```sql
SELECT date_part('DOY', '2021-07-01 00:00:00');
```
结果:
```sql
+----------------------------------------------------+
| date_part(Utf8("DOY"),Utf8("2021-07-01 00:00:00")) |
+----------------------------------------------------+
| 182 |
+----------------------------------------------------+
1 row in set (0.003 sec)
```
时间函数的参数和结果与 SQL 客户端的时区保持一致。
例如,当客户端的时区设置为 `+08:00` 时,下面两个查询的结果是相同的:
```sql
select to_unixtime('2024-01-02 00:00:00');
select to_unixtime('2024-01-02 00:00:00+08:00');
```
请参考 [SELECT](/reference/sql/select.md) 和 [Functions](/reference/sql/functions/overview.md) 获取更多信息。
## 限制返回的行数
时间序列数据通常是海量的。
为了节省带宽和提高查询性能,你可以使用 `LIMIT` 语句来限制 `SELECT` 语句返回的行数。
例如,下面的查询限制返回的行数为 10:
```sql
SELECT * FROM monitor LIMIT 10;
```
## 过滤数据
你可以使用 `WHERE` 子句来过滤 `SELECT` 语句返回的行。
时序数据库中常见的场景是按照标签或时间索引来过滤数据。
例如,按照标签 `host` 来过滤数据:
```sql
SELECT * FROM monitor WHERE host='127.0.0.1';
```
按照时间索引 `ts` 来过滤数据,返回 `2022-11-03 03:39:57` 之后的数据:
```sql
SELECT * FROM monitor WHERE ts > '2022-11-03 03:39:57';
```
你可以使用 `AND` 关键字来组合多个约束条件:
```sql
SELECT * FROM monitor WHERE host='127.0.0.1' AND ts > '2022-11-03 03:39:57';
```
### 使用时间索引过滤数据
按照时间索引来过滤数据是时序数据库的一个关键特性。
当处理 Unix 时间值时,数据库会默认将其类型认定为相关列的值类型。
例如,当 `monitor` 表中的 `ts` 列的值类型为 `TimestampMillisecond` 时,
你可以使用下面的查询来过滤数据:
Unix 时间值 `1667446797000` 表示一个以毫秒为单位的时间戳。
```sql
SELECT * FROM monitor WHERE ts > 1667446797000;
```
当处理时间精度为非默认类型的 Unix 时间值时,你需要使用 `::` 语法来指定时间的类型。
这样可以确保数据库正确地识别时间的类型。
例如 `1667446797` 表示一个以秒为单位的时间戳,不是 `ts` 列默认的毫秒时间戳。
你需要使用 `::TimestampSecond` 语法来指定它的类型为 `TimestampSecond` 来告知数据库 `1667446797` 应该被视为以秒为单位的时间戳。
```sql
SELECT * FROM monitor WHERE ts > 1667446797::TimestampSecond;
```
请参考[数据类型](/reference/sql/data-types.md#日期和时间类型) 获取更多时间类型。
对于标准的 `RFC3339` 或 `ISO8601` 字符串,由于其具备明确的精度,你可以直接在过滤条件中使用它们:
```sql
SELECT * FROM monitor WHERE ts > '2022-07-25 10:32:16.408';
```
你还可以使用时间函数来过滤数据。
例如,使用 `now()` 函数和 `INTERVAL` 关键字来获取最近 5 分钟的数据:
```sql
SELECT * FROM monitor WHERE ts >= now() - '5 minutes'::INTERVAL;
```
请参考 [Functions](/reference/sql/functions/overview.md) 获取更多时间函数信息。
### 时区
GreptimeDB 的 SQL 客户端会根据本地时区解释不带时区信息的字符串时间戳。
例如,当客户端时区为 `+08:00` 时,下面的两个查询是相同的:
```sql
SELECT * FROM monitor WHERE ts > '2022-07-25 10:32:16.408';
SELECT * FROM monitor WHERE ts > '2022-07-25 10:32:16.408+08:00';
```
查询结果中的时间戳列值会根据客户端时区格式化。
例如,下面的代码展示了相同的 `ts` 值在客户端时区 `UTC` 和 `+08:00` 下的结果: