Why GreptimeDB
GreptimeDB is an open-source observability database built for cloud-native environments. Our core developers have extensive experience building observability platforms, and GreptimeDB embodies their best practices in the following key areas:
Unified Processing for Observability Data
GreptimeDB unifies the processing of metrics, logs, and traces through:
- A consistent data model that treats all observability data as timestamped wide events with context
- Native support for both SQL and PromQL queries
- Built-in stream processing capabilities (Flow) for real-time aggregation and analytics
- Seamless correlation analysis across different types of observability data (read the SQL example for detailed info)
It replaces complex legacy data stacks with a high-performance single solution.

Cost-Effective with Object Storage
GreptimeDB leverages cloud object storage (like AWS S3 and Azure Blob Storage etc.) as its storage layer, dramatically reducing costs compared to traditional storage solutions. Its optimized columnar storage and advanced compression algorithms achieve up to 50x cost efficiency, while the pay-as-you-go model (via GreptimeCloud) ensures you only pay for what you use.
High Performance
As for performance optimization, GreptimeDB utilizes different techniques such as LSM Tree, data sharding, and kafka-based WAL design, to handle large workloads of observability data ingestion.
GreptimeDB is written in pure Rust for superior performance and reliability. The powerful and fast query engine is powered by vectorized execution and distributed parallel processing (thanks to Apache DataFusion), and combined with indexing capabilities such as inverted index, skipping index, and full-text index. GreptimeDB combines smart indexing and Massively Parallel Processing (MPP) to boost pruning and filtering.
GreptimeDB achieves 1 billion cold runs #1 in JSONBench! Read more benchmark reports.
Elastic Scaling with Kubernetes
Built from the ground up for Kubernetes, GreptimeDB features a disaggregated storage and compute architecture that enables true elastic scaling:
- Independent scaling of storage and compute resources
- Unlimited horizontal scalability through Kubernetes
- Resource isolation between different workloads (ingestion, querying, compaction)
- Automatic failover and high availability
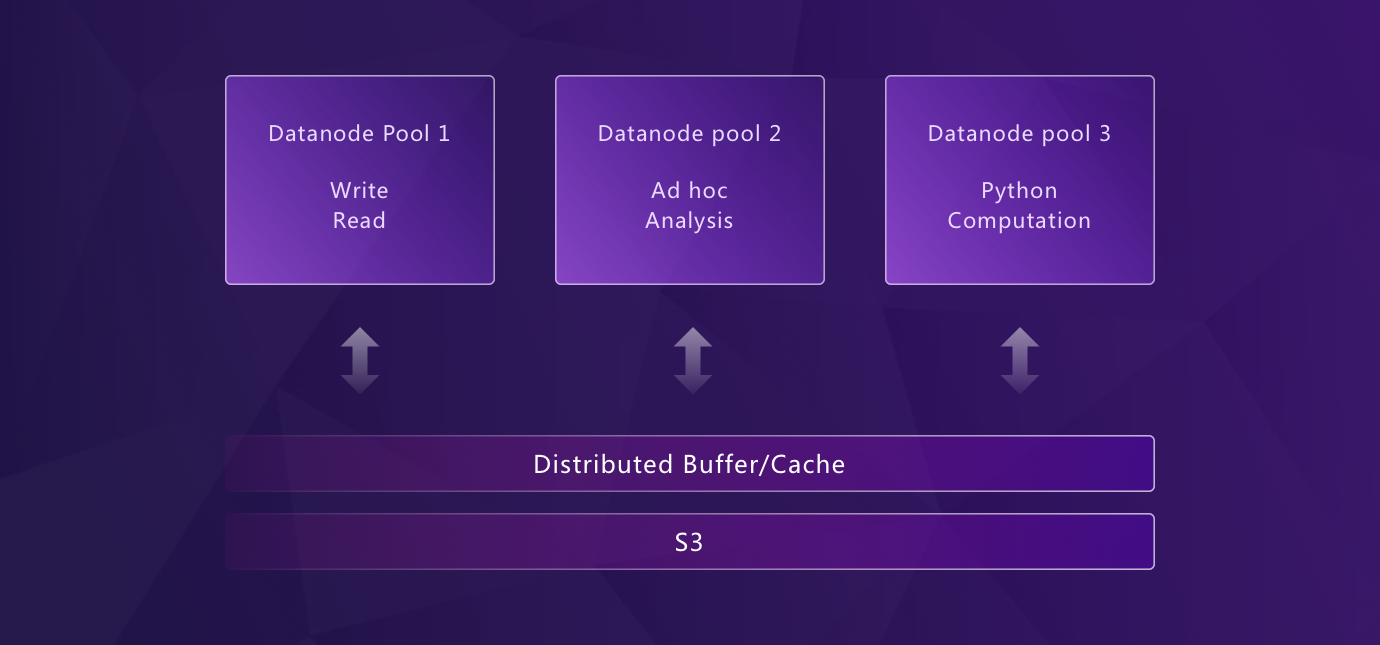
Flexible Architecture: From Edge to Cloud
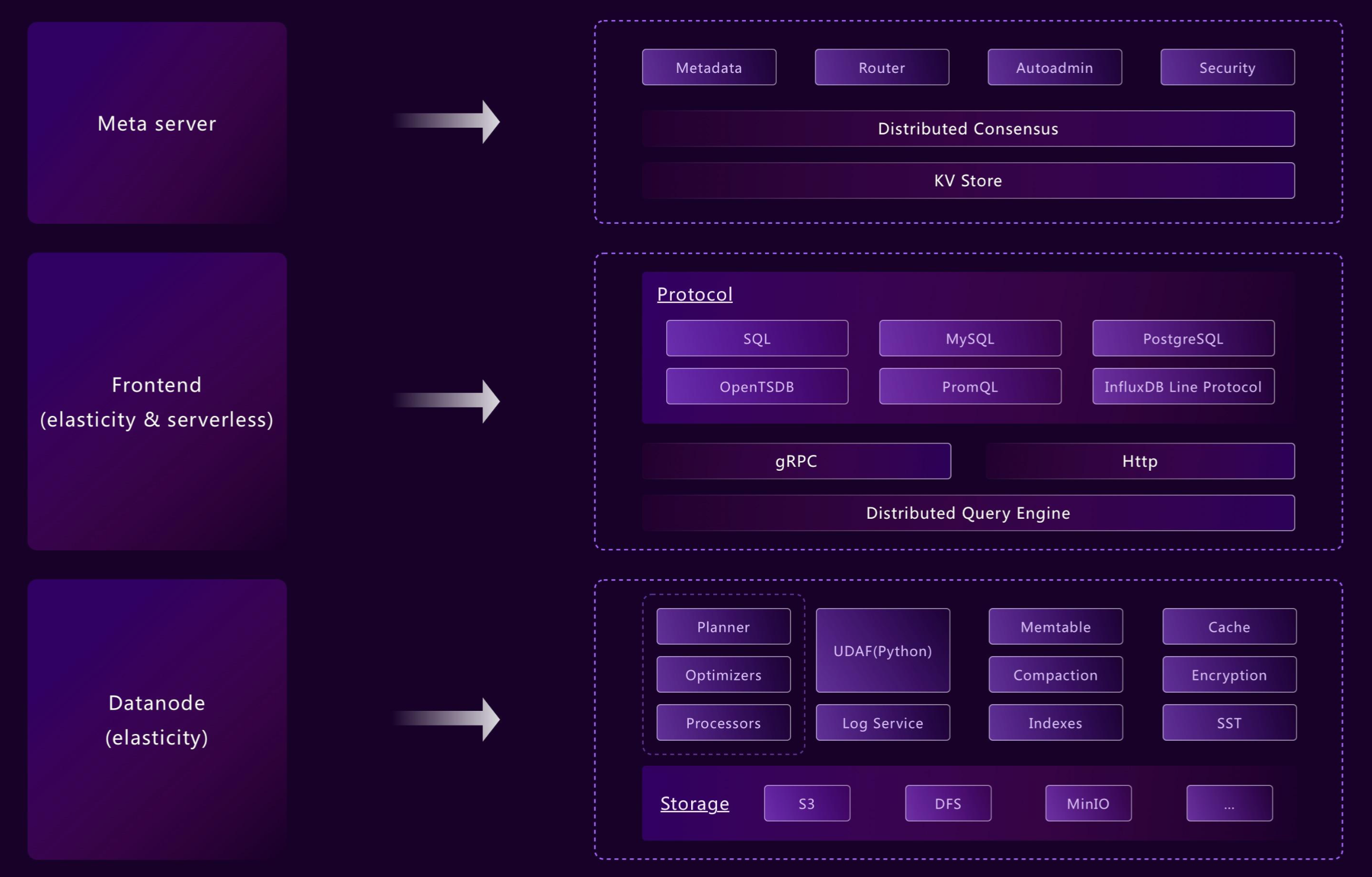
GreptimeDB’s modularized architecture allows different components to operate independently or in unison as needed. Its flexible design supports a wide variety of deployment scenarios, from edge devices to cloud environments, while still using consistent APIs for operations. For example:
- Frontend, datanode, and metasrv can be merged into a standalone binary
- Components like WAL or indexing can be enabled or disabled per table
This flexibility ensures that GreptimeDB meets deployment requirements for edge-to-cloud solutions, like the Edge-Cloud Integrated Solution.
From embedded and standalone deployments to cloud-native clusters, GreptimeDB adapts to various environments easily.
Easy to Use
Easy to Deploy and Maintain
GreptimeDB simplifies deployment and maintenance with tools like:
- K8s Operator
- Command-line Tool
- Embedded Dashboard
For an even simpler experience, check out the fully managed GreptimeCloud.
Easy to Integrate
GreptimeDB supports multiple data ingestion protocols, making integration with existing observability stacks seamless:
- Database protocols: MySQL, PostgreSQL
- Time-series protocols: InfluxDB, OpenTSDB, Prometheus RemoteStorage
- Observability protocols: OpenTelemetry, Loki, ElasticSearch
- gRPC with SDKs: Java, Go, Erlang, etc.
For data querying, GreptimeDB provides:
- SQL: For real-time queries, analytics, and database management
- PromQL: Native support for real-time metrics querying and Grafana integration
- Python (Planned): For in-database UDFs and DataFrame operations
GreptimeDB integrates seamlessly with your observability stack while maintaining high performance and flexibility.
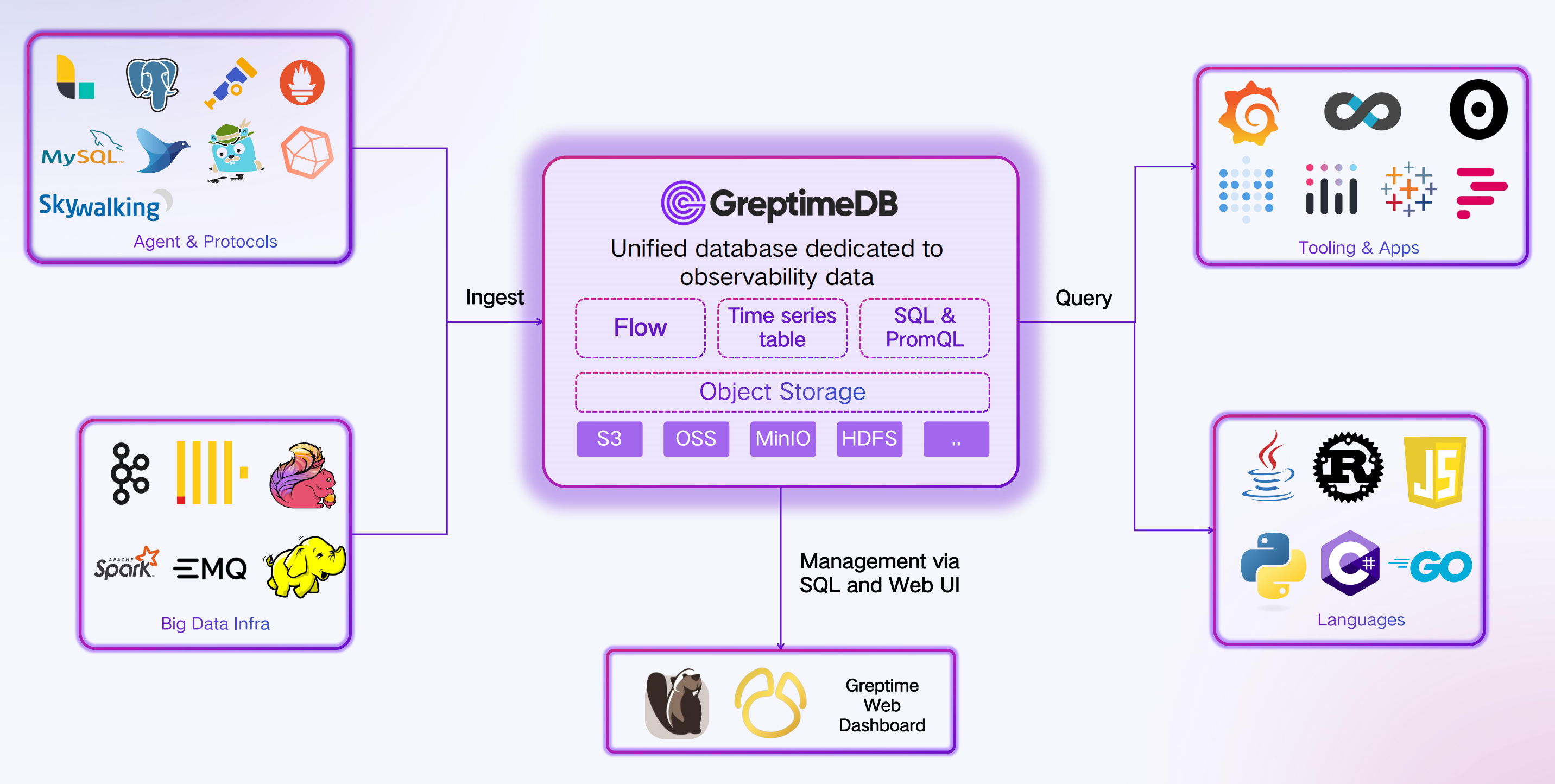
Simple Data Model with Automatic Schema
GreptimeDB introduces a new data model that combines time-series and relational models:
- Data is represented as a table with rows and columns
- Metrics, logs, and traces map to columns with a time index for timestamps
- Schema is created dynamically and new columns are added automatically as data is ingested
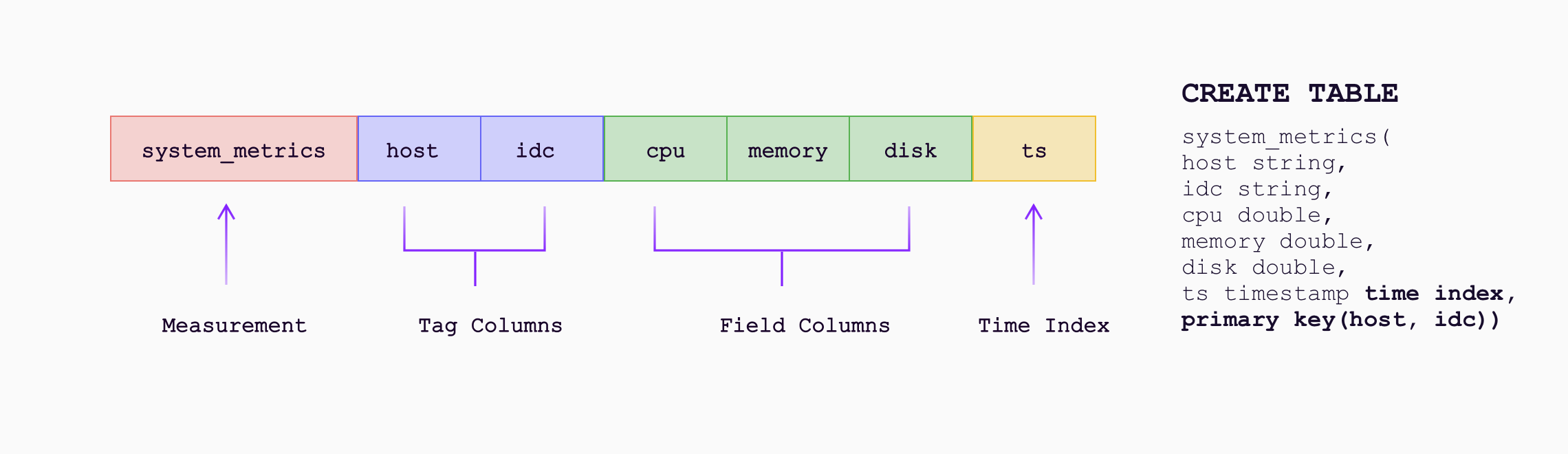
However, our definition of schema is not mandatory, but rather leans towards the schema-less approach of databases like MongoDB. Tables will be created automatically and dynamically as data is written, and newly appearing columns (Tag and Field) will be added automatically. For a more detailed explanation, please read the Data Model.
For more details, explore our blogs: