Data Persistence and Indexing
Similar to all LSMT-like storage engines, data in MemTables is persisted to durable storage, for example, the local disk file system or object storage service. GreptimeDB adopts Apache Parquet as its persistent file format.
SST File Format
Parquet is an open source columnar format that provides fast data querying and has already been adopted by many projects, such as Delta Lake.
Parquet has a hierarchical structure like "row groups-columns-data pages". Data in a Parquet file is horizontally partitioned into row groups, in which all values of the same column are stored together to form a data page. Data page is the minimal storage unit. This structure greatly improves performance.
First, clustering data by column makes file scanning more efficient, especially when only a few columns are queried, which is very common in analytical systems.
Second, data of the same column tends to be homogeneous which helps with compression when apply techniques like dictionary and Run-Length Encoding (RLE).
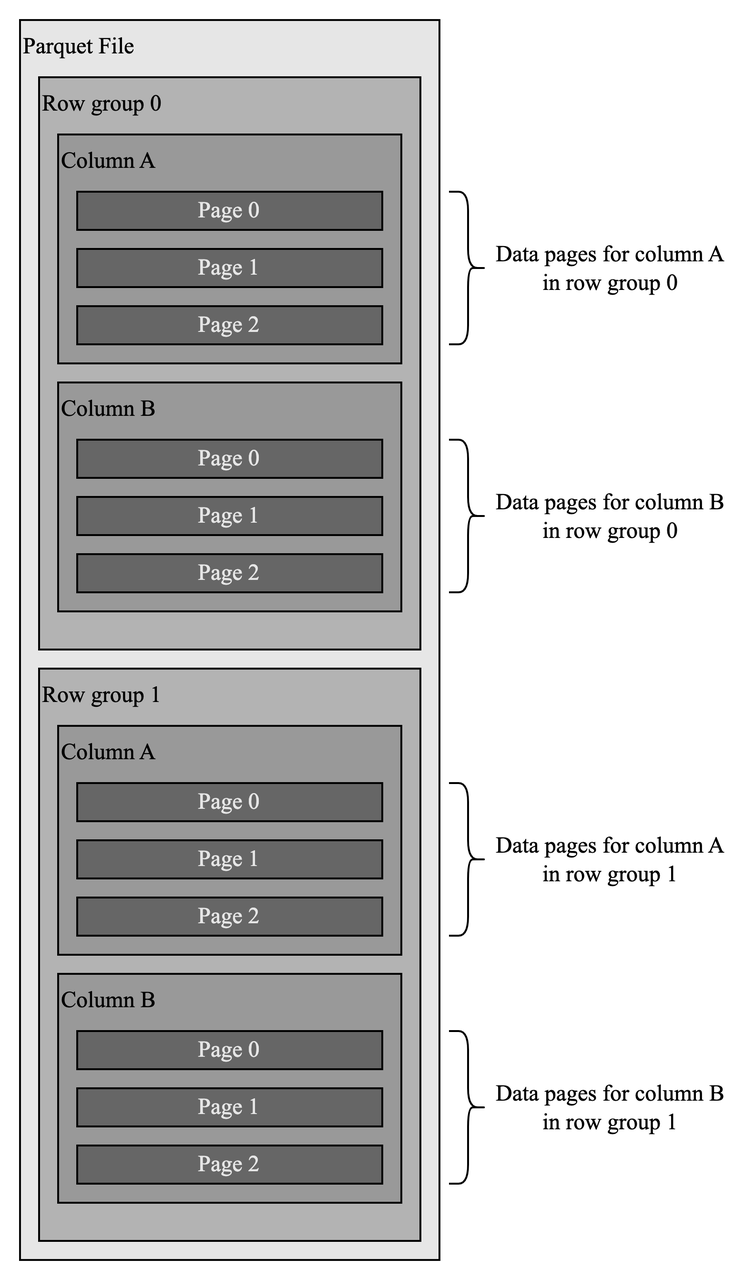
Data Persistence
GreptimeDB provides a configuration item storage.flush.global_write_buffer_size, which is flush threshold of the total memory usage for all MemTables.
When the size of data buffered in MemTables reaches that threshold, GreptimeDB will pick MemTables and flush them to SST files.
Indexing Data in SST Files
Apache Parquet file format provides inherent statistics in headers of column chunks and data pages, which are used for pruning and skipping.
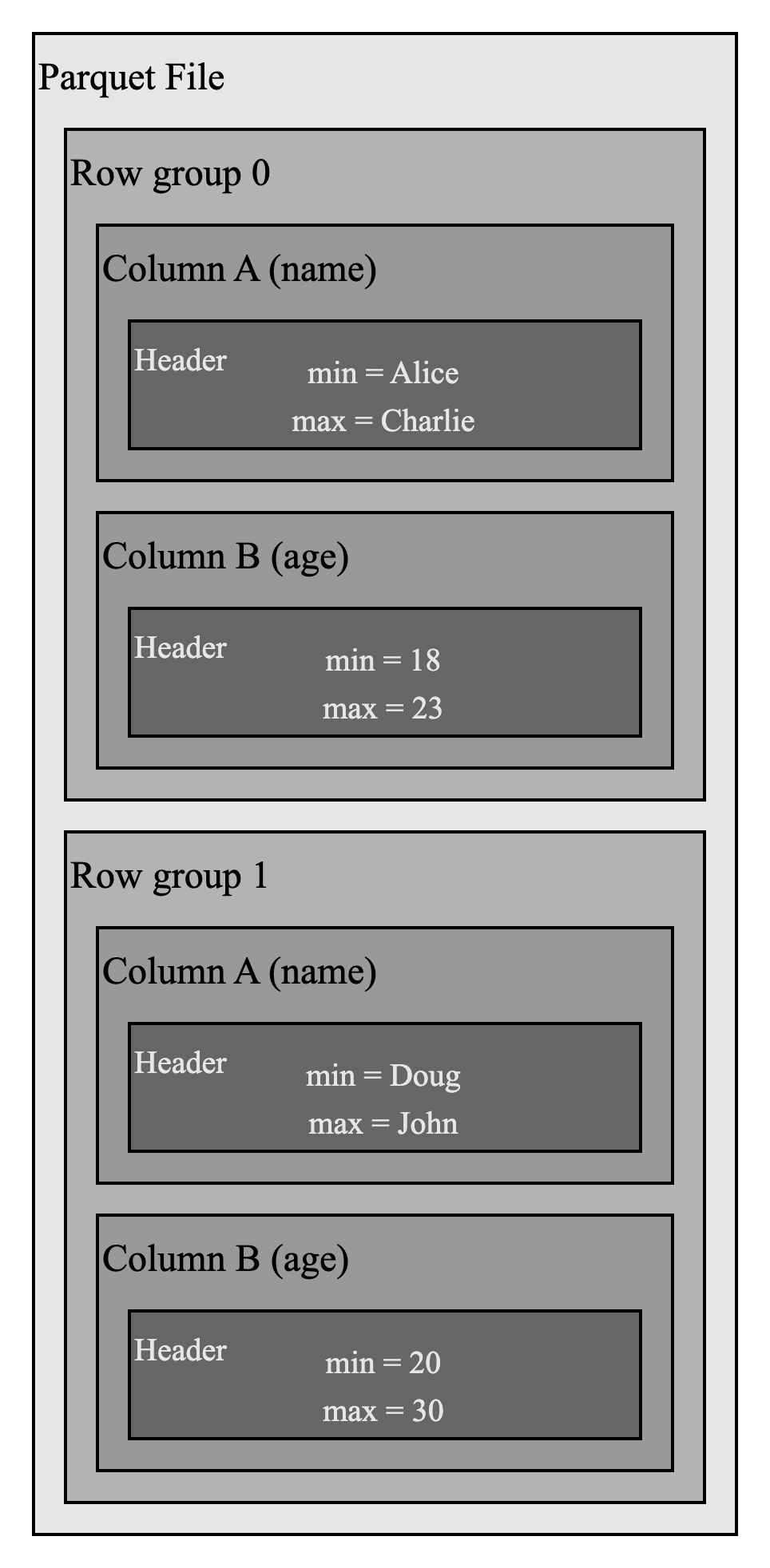
For example, in the above Parquet file, if you want to filter rows where name = Emily, you can easily skip row group 0 because the max value for name field is Charlie. This statistical information reduces IO operations.
Index Files
For each SST file, GreptimeDB not only maintains an internal index but also generates a separate file to store the index structures specific to that SST file.
The index files utilize the Puffin format, which offers significant flexibility, allowing for the storage of additional metadata and supporting a broader range of index structures.
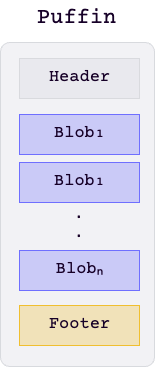
Currently, the inverted index is the first supported index structure, and it is stored within the index file as a Blob.
Inverted Index
In version 0.7, GreptimeDB introduced the inverted index to accelerate queries.
The inverted index is a common index structure used for full-text searches, mapping each word in the document to a list of documents containing that word. Greptime has adopted this technology, which originates from search engines, for use in the time series databases.
Search engines and time series databases operate in separate domains, yet the principle behind the applied inverted index technology is similar. This similarity requires some conceptual adjustments:
- Term: In GreptimeDB, it refers to the column value of the time series.
- Document: In GreptimeDB, it refers to the data segment containing multiple time series.
The inverted index enables GreptimeDB to skip data segments that do not meet query conditions, thus improving scanning efficiency.
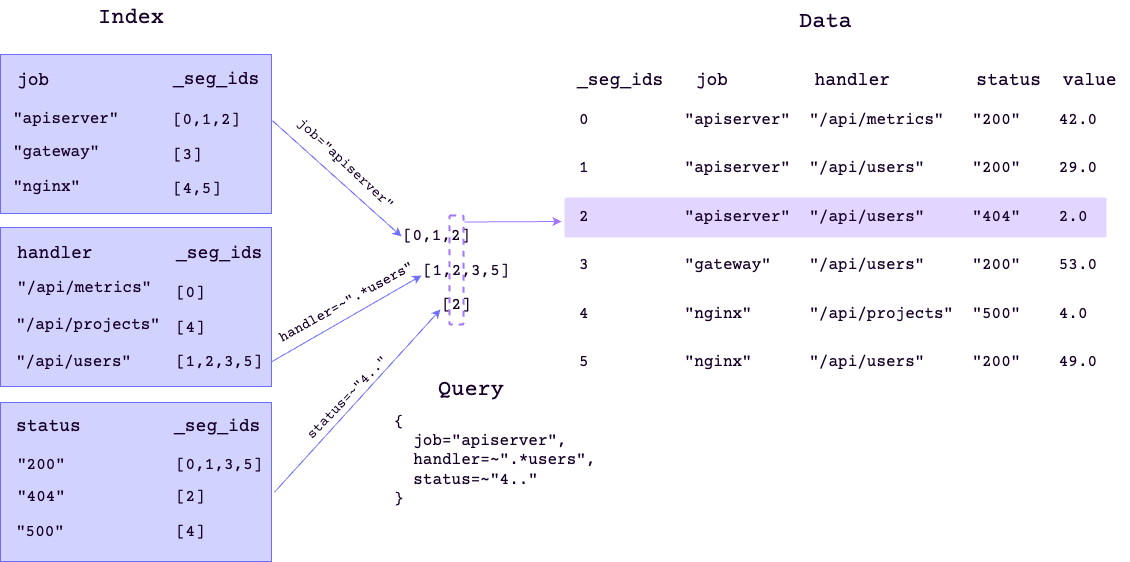
For instance, the query above uses the inverted index to identify data segments where job equals apiserver, handler matches the regex .*users, and status matches the regex 4.... It then scans these data segments to produce the final results that meet all conditions, significantly reducing the number of IO operations.
Inverted Index Format
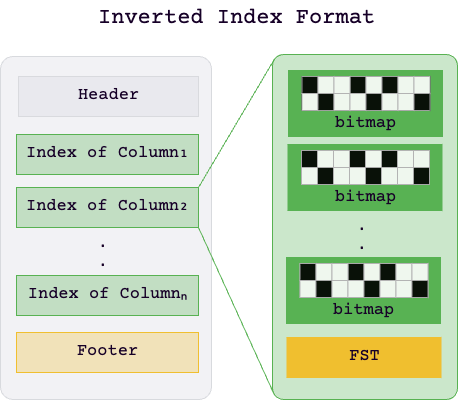
GreptimeDB builds inverted indexes by column, with each inverted index consisting of an FST and multiple Bitmaps.
The FST (Finite State Transducer) enables GreptimeDB to store mappings from column values to Bitmap positions in a compact format and provides excellent search performance and supports complex search capabilities (such as regular expression matching). The Bitmaps maintain a list of data segment IDs, with each bit representing a data segment.
Index Data Segments
GreptimeDB divides an SST file into multiple indexed data segments, with each segment housing an equal number of rows. This segmentation is designed to optimize query performance by scanning only the data segments that match the query conditions.
For example, if a data segment contains 1024 rows and the list of data segments identified through the inverted index for the query conditions is [0, 2], then only the 0th and 2nd data segments in the SST file—from rows 0 to 1023 and 2048 to 3071, respectively—need to be scanned.
The number of rows in a data segment is controlled by the engine option index.inverted_index.segment_row_count, which defaults to 1024. A smaller value means more precise indexing and often results in better query performance but increases the cost of index storage. By adjusting this option, a balance can be struck between storage costs and query performance.
Unified Data Access Layer: OpenDAL
GreptimeDB uses OpenDAL to provide a unified data access layer, thus, the storage engine does not need to interact with different storage APIs, and data can be migrated to cloud-based storage like AWS S3 seamlessly.