数据持久化与索引
与所有类似 LSMT 的存储引擎一样,MemTables 中的数据被持久化到耐久性存储,例如本地磁盘文件系统或对象存储服务。GreptimeDB 采用 Apache Parquet 作为其持久文件格式。
SST 文件格式
Parquet 是一种提供快速数据查询的开源列式存储格式,已经被许多项目采用,例如 Delta Lake。
Parquet 具有层次结构,类似于“行组 - 列-数据页”。Parquet 文件中的数据被水平分区为行组(row group),在其中相同列的所有值一起存储以形成数据页(data pages)。数据页是最小的存储单元。这种结构极大地提高了性能。
首先,数据按列聚集,这使得文件扫描更加高效,特别是当查询只涉及少数列时,这在分析系统中非常常见。
其次,相同列的数据往往是同质的(比如具备近似的值),这有助于在采用字典和 Run-Length Encoding(RLE)等技术进行压缩。
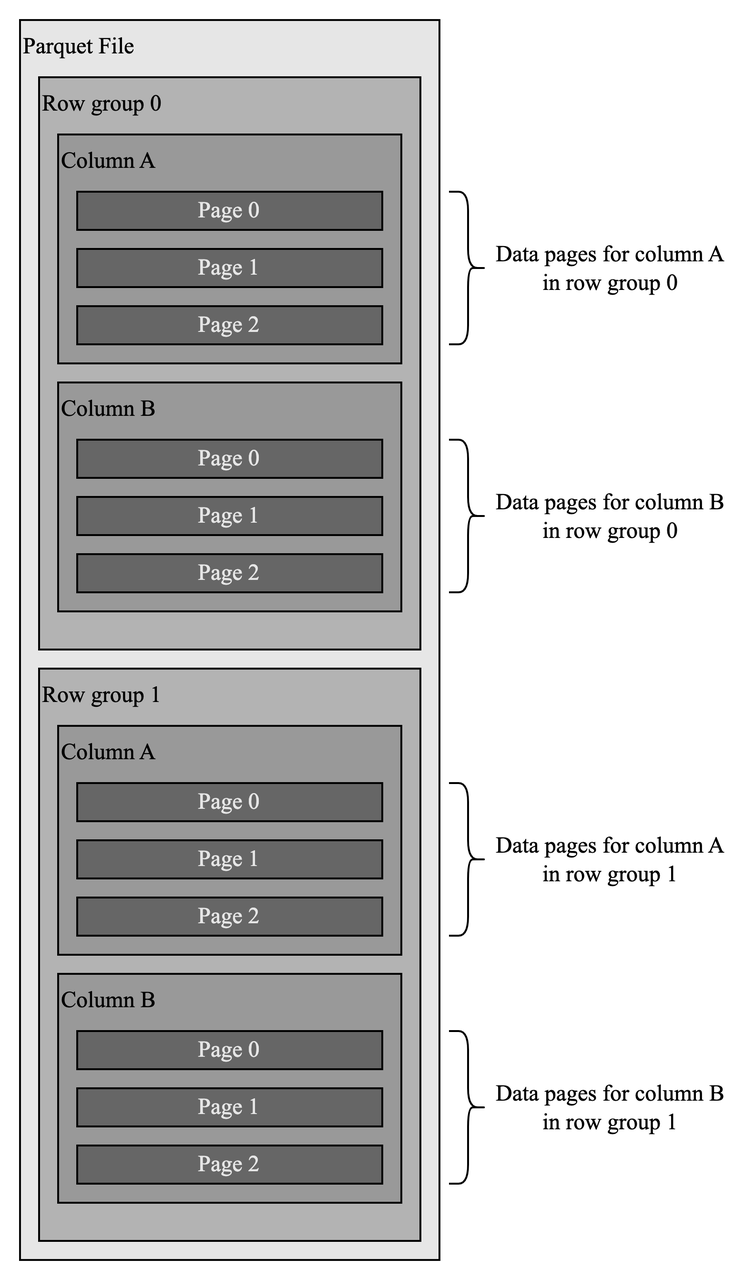
数据持久化
GreptimeDB 提供了 storage.flush.global_write_buffer_size 的配置项来设置全局的 Memtable 大小阈值。当数据库所有 MemTable 中的数据量之和达到阈值时将自动触发持久化操作,将 MemTable 的数据 flush 到 SST 文件中。
SST 文件中的索引数据
Apache Parquet 文件格式在列块和数据页的头部提供了内置的统计信息,用于剪枝和跳过。
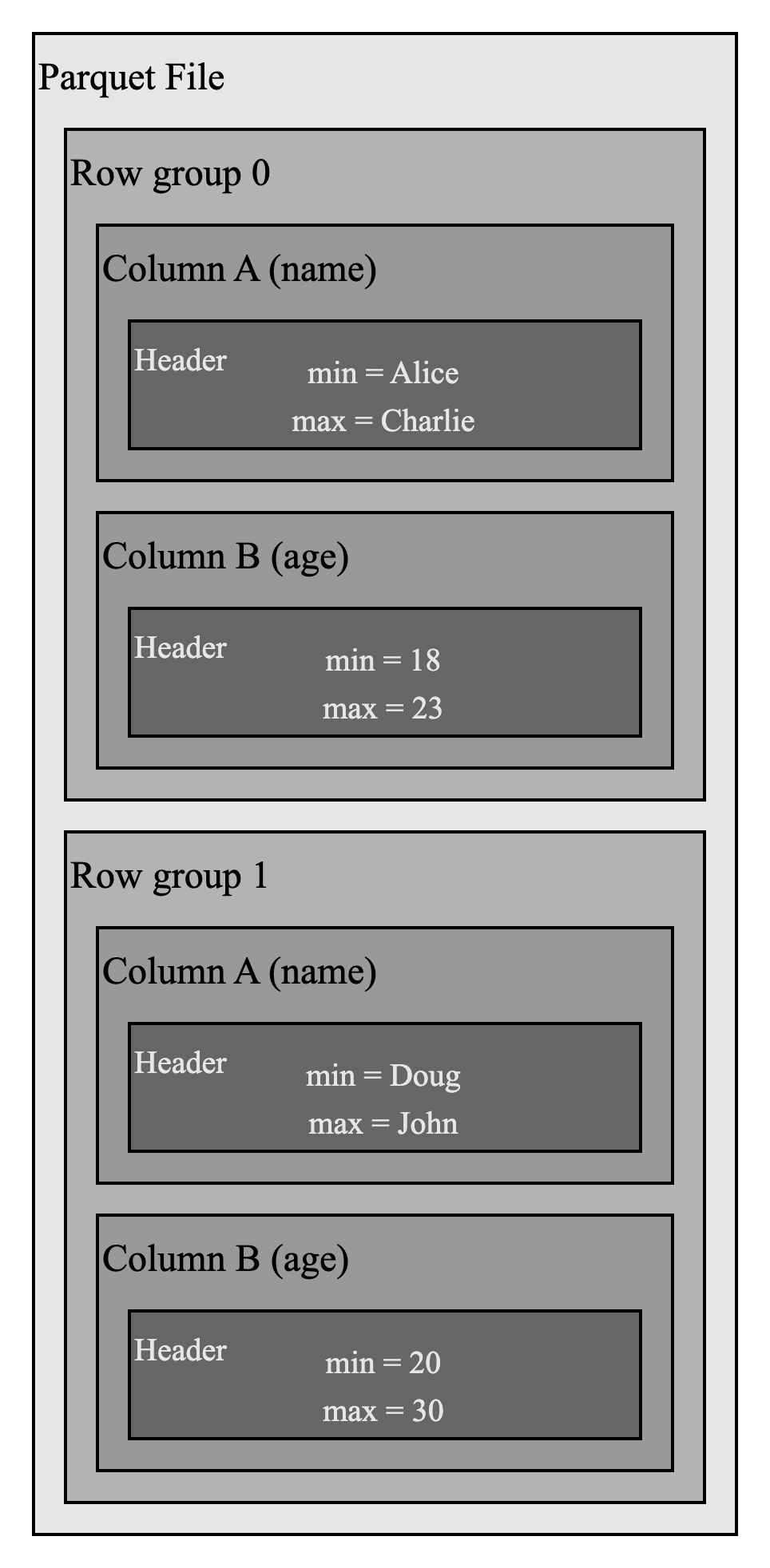
例如,在上述 Parquet 文件中,如果你想要过滤 name 等于 Emily 的行,你可以轻松跳过行组 0,因为 name 字段的最大值是 Charlie。这些统计信息减少了 IO 操作。
索引文件
对于每个 SST 文件,GreptimeDB 不但维护 SST 文件内部索引,还会单独生成一个文件用于存储针对该 SST 文件的索引结构。
索引文件采用 Puffin 格式,这种格式具有较大的灵活性,能够存储更多的元数据,并支持更多的索引结构。

目前,倒排索引是 GreptimeDB 第一个支持的单独索引结构,以 Blob 的形式存储在索引文件中。
倒排索引
在 v0.7 版本中,GreptimeDB 引入了倒排索引(Inverted Index)来加速查询。
倒排索引是一种常见的用于全文搜索的索引结构,它将文档中的每个单词映射到包含该单词的文档列表,GreptimeDB 把这项源自于搜索引擎的技术应用到了时间序列数据库中。
搜索引擎和时间序列数据库虽然运行在不同的领域,但是应用的倒排索引技术背后的原理是相似的。这种相似性需要一些概念上的调整:
- 单词:在 GreptimeDB 中,指时间线的列值。
- 文档:在 GreptimeDB 中,指包含多个时间线的数据段。
倒排索引的引入,使得 GreptimeDB 可以跳过不符合查询条件的数据段,从而提高扫描效率。
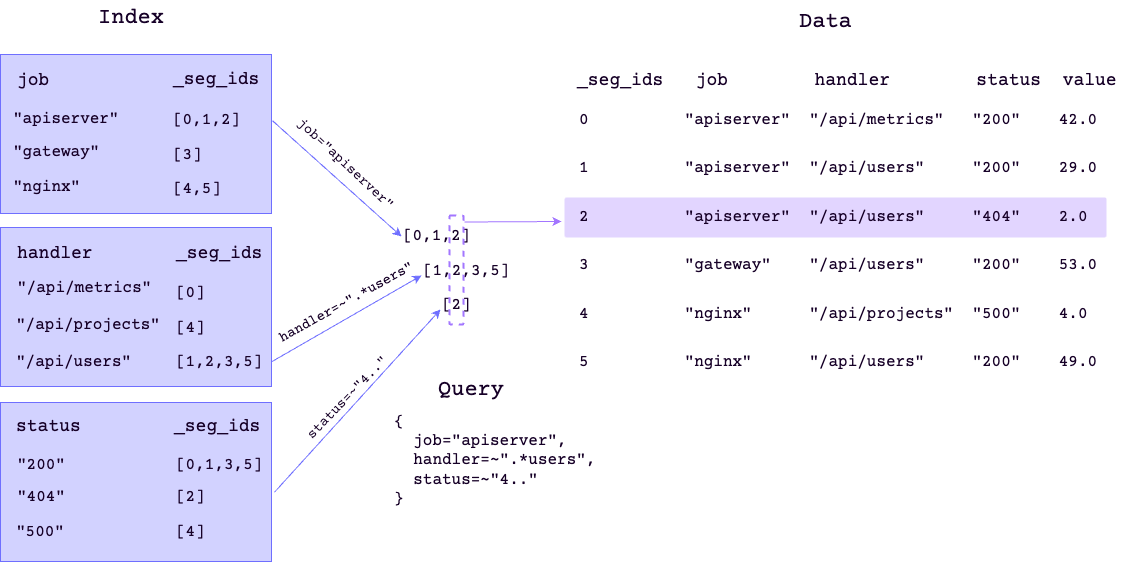
例如,上述查询使用倒排索引来定位数据段,数据段满足条件:job 等于 apiserver,handler 符合正则匹配 .*users 及 status 符合正则匹配 4..,然后扫描这些数据段以产生满足所有条件的最终结果,从而显着减少 IO 操作的次数。
倒排索引格式

GreptimeDB 按列构建倒排索引,每个倒排索引包含一个 FST 和多个 Bitmap。
FST(Finite State Transducer)允许 GreptimeDB 以紧凑的格式存储列值到 Bitmap 位置的映射,并且提供了优秀的搜索性能和支持复杂搜索(例如正则表达式匹配);Bitmap 则维护了数据段 ID 列表,每个位表示一个数据段。
索引数据段
GreptimeDB 把一个 SST 文件分割成多个索引数据段,每个数据段包含相同行数的数据。这种分段的目的是通过只扫描符合查询条件的数据段来优化查询性能。
例如,当数据段的行数为 1024,如果查询条件应用倒排索引后,得到的数据段列表为 [0, 2],那么只需扫描 SST 文件中的第 0 和第 2 个数据段(即第 0 行到第 1023 行和第 2048 行到第 3071 行)即可。
数据段的行数由引擎选项 index.inverted_index.segment_row_count 控制,默认为 1024。较小的值意味着更精确的索引,往往会得到更好的查询性能,但会增加索引存储成本。通过调整该选项,可以在存储成本和查询性能之间进行权衡。
统一数据访问层:OpenDAL
GreptimeDB 使用 OpenDAL 提供统一的数据访问层,因此,存储引擎无需与不同的存储 API 交互,数据可以无缝迁移到基于云的存储,如 AWS S3。