Design Your Table Schema
The design of your table schema significantly impacts both write and query performance. Before writing data, it is crucial to understand the data types, scale, and common queries relevant to your business, then model the data accordingly. This document provides a comprehensive guide on GreptimeDB's data model and table schema design for various scenarios.
Understanding GreptimeDB's Data Model
Before proceeding, please review the GreptimeDB Data Model Documentation.
Basic Concepts
Cardinality
Cardinality: Refers to the number of unique values in a dataset. It can be classified as "high cardinality" or "low cardinality":
- Low Cardinality: Low cardinality columns usually have constant values.
The total number of unique values usually no more than 10 thousand.
For example,
namespace,cluster,http_methodare usually low cardinality. - High Cardinality: High cardinality columns contain a large number of unique values.
For example,
trace_id,span_id,user_id,uri,ip,uuid,request_id, table auto increment id, timestamps are usually high cardinality.
Column Types
In GreptimeDB, columns are categorized into three semantic types: Tag, Field, and Timestamp.
The timestamp usually represents the time of data sampling or the occurrence time of logs/events.
GreptimeDB uses the TIME INDEX constraint to identify the Timestamp column.
So the Timestamp column is also called the TIME INDEX column.
If you have multiple columns with timestamp data type, you can only define one as TIME INDEX and others as Field columns.
In GreptimeDB, tag columns are optional. The main purposes of tag columns include:
- Defining the ordering of data in storage.
GreptimeDB reuses the
PRIMARY KEYconstraint to define tag columns and the ordering of tags. Unlike traditional databases, GreptimeDB defines time-series by the primary key. Tables in GreptimeDB sort rows in the order of(primary key, timestamp). This improves the locality of data with the same tags. If there are no tag columns, GreptimeDB sorts rows by timestamp. - Identifying a unique time-series. When the table is not append-only, GreptimeDB can deduplicate rows by timestamp under the same time-series (primary key).
- Smoothing migration from other TSDBs that use tags or labels.
Primary key
Primary key is optional
Bad primary key or index may significantly degrade performance. Generally you can create an append-only table without a primary key since ordering data by timestamp is sufficient for many workloads. It can also serve as a baseline.
CREATE TABLE http_logs (
access_time TIMESTAMP TIME INDEX,
application STRING,
remote_addr STRING,
http_status STRING,
http_method STRING,
http_refer STRING,
user_agent STRING,
request_id STRING,
request STRING,
) with ('append_mode'='true');
The http_logs table is an example for storing HTTP server logs.
- The
'append_mode'='true'option creates the table as an append-only table. This ensures a log doesn't override another one with the same timestamp. - The table sorts logs by time so it is efficient to search logs by time.
When to use primary key
You can use primary key when there are suitable low cardinality columns and one of the following conditions is met:
- Most queries can benefit from the ordering.
- You need to deduplicate (including delete) rows by the primary key and time index.
For example, if you always only query logs of a specific application, you may set the application column as primary key (tag).
SELECT message FROM http_logs WHERE application = 'greptimedb' AND access_time > now() - '5 minute'::INTERVAL;
The number of applications is usually limited. Table http_logs_v2 uses application as the primary key.
It sorts logs by application so querying logs under the same application is faster as it only has to scan a small number of rows. Setting tags may also reduce disk space usage as it improves the locality of data.
CREATE TABLE http_logs_v2 (
access_time TIMESTAMP TIME INDEX,
application STRING,
remote_addr STRING,
http_status STRING,
http_method STRING,
http_refer STRING,
user_agent STRING,
request_id STRING,
request STRING,
PRIMARY KEY(application),
) with ('append_mode'='true');
In order to improve sort and deduplication speed under time-series workloads, GreptimeDB buffers and processes rows by time-series internally. So it doesn't need to compare the primary key for each row repeatedly. This can be a problem if the tag column has high cardinality:
- Performance degradation since the database can't batch rows efficiently.
- It may increase memory and CPU usage as the database has to maintain the metadata for each time-series.
- Deduplication may be too expensive.
So you must not use high cardinality column as the primary key or put too many columns in the primary key. Currently, the recommended number of values for the primary key is no more than 100 thousand. A long primary key will negatively affect the insert performance and enlarge the memory footprint. A primary key with no more than 5 columns is recommended.
Recommendations for tags:
- Low cardinality columns that occur in
WHERE/GROUP BY/ORDER BYfrequently. These columns usually remain constant. For example,namespace,cluster, or an AWSregion. - No need to set all low cardinality columns as tags since this may impact the performance of ingestion and querying.
- Typically use short strings and integers for tags, avoiding
FLOAT,DOUBLE,TIMESTAMP. - Never set high cardinality columns as tags if they change frequently.
For example,
trace_id,span_id,user_idmust not be used as tags. GreptimeDB works well if you set them as fields instead of tags.
Index
Besides primary key, you can also use index to accelerate specific queries on demand.
Inverted Index
GreptimeDB supports inverted index that may speed up filtering low cardinality columns.
When creating a table, you can specify the inverted index columns using the INVERTED INDEX clause.
For example, http_logs_v3 adds an inverted index for the http_method column.
CREATE TABLE http_logs_v3 (
access_time TIMESTAMP TIME INDEX,
application STRING,
remote_addr STRING,
http_status STRING,
http_method STRING INVERTED INDEX,
http_refer STRING,
user_agent STRING,
request_id STRING,
request STRING,
PRIMARY KEY(application),
) with ('append_mode'='true');
The following query can use the inverted index on the http_method column.
SELECT message FROM http_logs_v3 WHERE application = 'greptimedb' AND http_method = `GET` AND access_time > now() - '5 minute'::INTERVAL;
Inverted index supports the following operators:
=<<=>>=INBETWEEN~
Skipping Index
For high cardinality columns like trace_id, request_id, using a skipping index is more appropriate.
This method has lower storage overhead and resource usage, particularly in terms of memory and disk consumption.
Example:
CREATE TABLE http_logs_v4 (
access_time TIMESTAMP TIME INDEX,
application STRING,
remote_addr STRING,
http_status STRING,
http_method STRING INVERTED INDEX,
http_refer STRING,
user_agent STRING,
request_id STRING SKIPPING INDEX,
request STRING,
PRIMARY KEY(application),
) with ('append_mode'='true');
The following query can use the skipping index to filter the request_id column.
SELECT message FROM http_logs_v4 WHERE application = 'greptimedb' AND request_id = `25b6f398-41cf-4965-aa19-e1c63a88a7a9` AND access_time > now() - '5 minute'::INTERVAL;
However, note that the query capabilities of the skipping index are generally inferior to those of the inverted index. Skipping index can't handle complex filter conditions and may have a lower filtering performance on low cardinality columns. It only supports the equal operator.
Full-Text Index
For unstructured log messages that require tokenization and searching by terms, GreptimeDB provides full-text index.
For example, the raw_logs table stores unstructured logs in the message field.
CREATE TABLE IF NOT EXISTS `raw_logs` (
message STRING NULL FULLTEXT INDEX WITH(analyzer = 'English', case_sensitive = 'false'),
ts TIMESTAMP(9) NOT NULL,
TIME INDEX (ts),
) with ('append_mode'='true');
The message field is full-text indexed using the FULLTEXT INDEX option.
See fulltext column options for more information.
Storing and querying structured logs usually have better performance than unstructured logs with full-text index. It's recommended to use Pipeline to convert logs into structured logs.
When to use index
Index in GreptimeDB is flexible and powerful. You can create an index for any column, no matter if the column is a tag or a field. It's meaningless to create additional index for the timestamp column. Generally you don't need to create indexes for all columns. Maintaining indexes may introduce additional cost and stall ingestion. A bad index may occupy too much disk space and make queries slower.
You can use a table without additional index as a baseline. There is no need to create an index for the table if the query performance is already acceptable. You can create an index for a column when:
- The column occurs in the filter frequently.
- Filtering the column without an index isn't fast enough.
- There is a suitable index for the column.
The following table lists the suitable scenarios of all index types.
| Inverted Index | Full-Text Index | Skip Index | |
|---|---|---|---|
| Suitable Scenarios | - Filtering low cardinality columns | - Text content search | - Precise filtering high cardinality columns |
| Creation Method | - Specified using INVERTED INDEX | - Specified using FULLTEXT INDEX in column options | - Specified using SKIPPING INDEX in column options |
Deduplication
If deduplication is necessary, you can use the default table options, which sets the append_mode to false and enables deduplication.
CREATE TABLE IF NOT EXISTS system_metrics (
host STRING,
cpu_util DOUBLE,
memory_util DOUBLE,
disk_util DOUBLE,
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY(host),
TIME INDEX(ts)
);
GreptimeDB deduplicates rows by the same primary key and timestamp if the table isn't append-only.
For example, the system_metrics table removes duplicate rows by host and ts.
Data updating and merging
GreptimeDB supports two different strategies for deduplication: last_row and last_non_null.
You can specify the strategy by the merge_mode table option.
GreptimeDB uses an LSM Tree-based storage engine,
which does not overwrite old data in place but allows multiple versions of data to coexist.
These versions are merged during the query process.
The default merge behavior is last_row, meaning the most recently inserted row takes precedence.
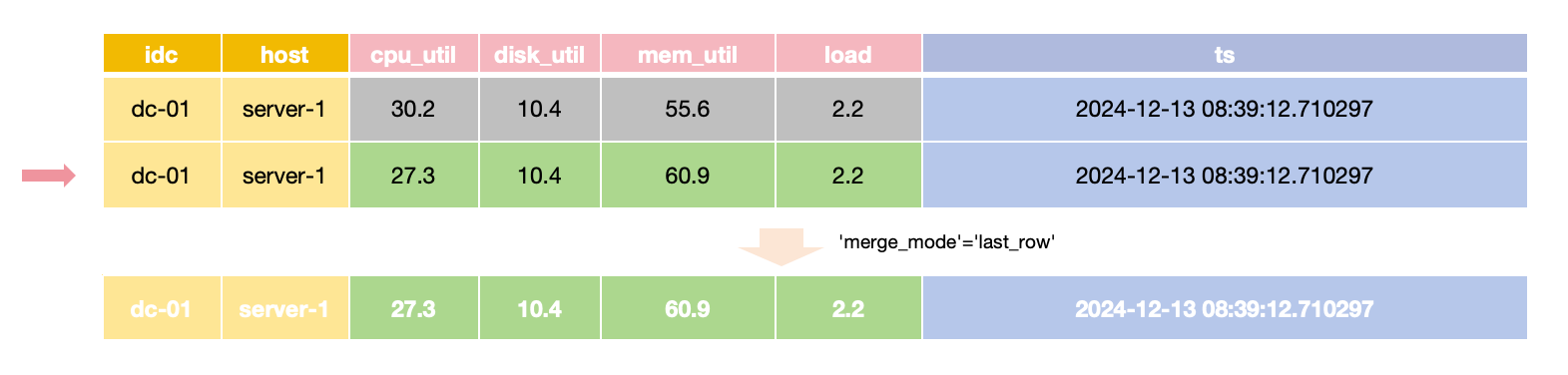
In last_row merge mode,
the latest row is returned for queries with the same primary key and time value,
requiring all Field values to be provided during updates.
For scenarios where only specific Field values need updating while others remain unchanged,
the merge_mode option can be set to last_non_null.
This mode retains the latest non-null value for each field during queries,
allowing updates to provide only the values that need to change.
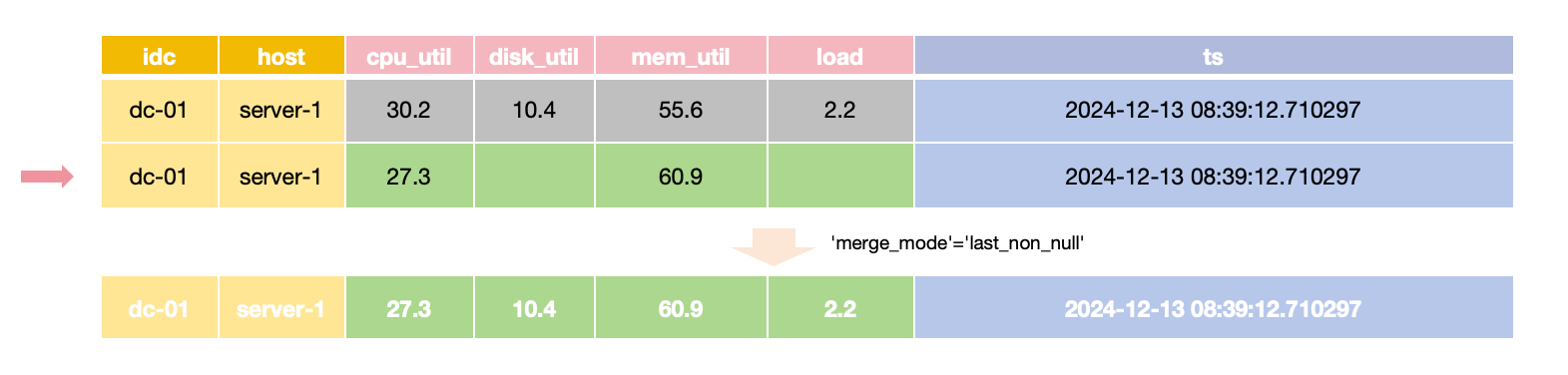
The last_non_null merge mode is the default for tables created automatically via the InfluxDB line protocol,
aligning with InfluxDB's update behavior.
The last_row merge mode doesn't have to check each individual field value so it is usually faster than the last_non_null mode.
Note that merge_mode cannot be set for Append-Only tables, as they do not perform merges.
When to use append-only tables
If you don't need the following features, you can use append-only tables:
- Deduplication
- Deletion
GreptimeDB implements DELETE via deduplicating rows so append-only tables don't support deletion now.
Deduplication requires more computation and restricts the parallelism of ingestion and querying.
Using append-only tables usually has better query performance.
Wide Table vs. Multiple Tables
In monitoring or IoT scenarios, multiple metrics are often collected simultaneously. We recommend placing metrics collected simultaneously into a single table to improve read/write throughput and data compression efficiency.
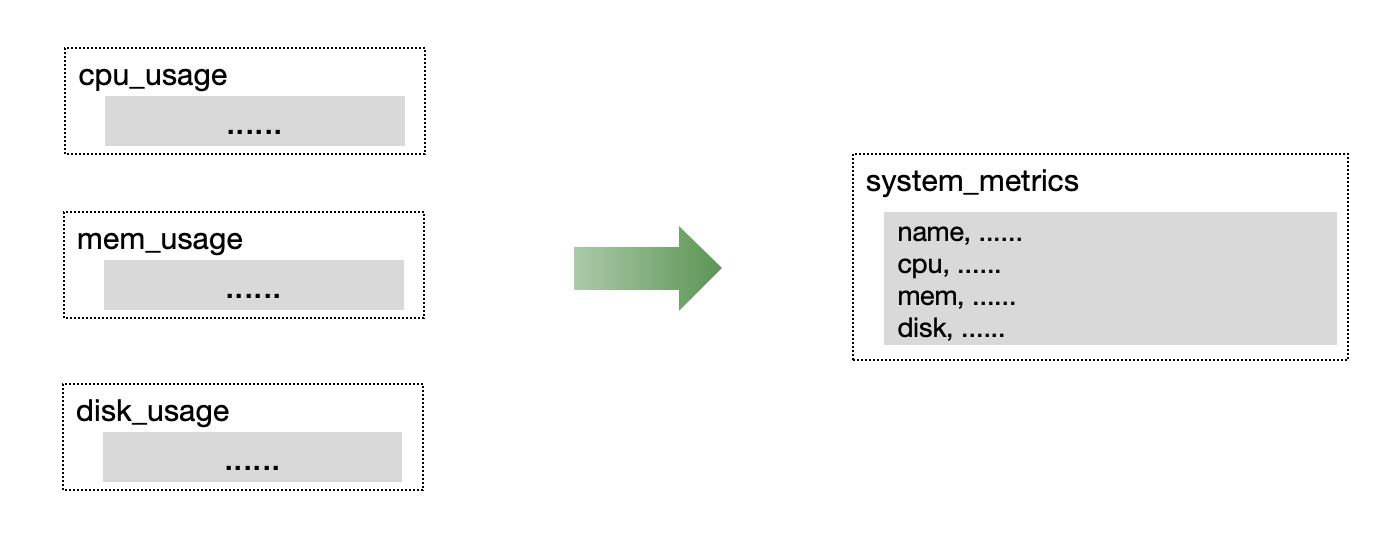
Although Prometheus uses single-value model for metrics, GreptimeDB's Prometheus Remote Storage protocol supports sharing a wide table for metrics at the underlying layer through the Metric Engine.
Distributed Tables
GreptimeDB supports partitioning data tables to distribute read/write hotspots and achieve horizontal scaling.
Two misunderstandings about distributed tables
As a time-series database, GreptimeDB automatically partitions data based on the TIME INDEX column at the storage layer. Therefore, it is unnecessary and not recommended for you to partition data by time (e.g., one partition per day or one table per week).
Additionally, GreptimeDB is a columnar storage database, so partitioning a table refers to horizontal partitioning by rows, with each partition containing all columns.
When to Partition and Determining the Number of Partitions
A table can utilize all the resources in the machine, especially during query. Partitioning a table may not always improve the performance:
- A distributed query plan isn't always as efficient as a local query plan.
- Distributed query may introduce additional data transmission across the network.
There is no need to partition a table unless a single machine isn't enough to serve the table. For example:
- There is not enough local disk space to store the data or to cache the data when using object stores.
- You need more CPU cores to improve the query performance or more memory for costly queries.
- The disk throughput becomes the bottleneck.
- The ingestion rate is larger than the throughput of a single node.
GreptimeDB releases a benchmark report with each major version update, detailing the ingestion throughput of a single partition. Use this report alongside your target scenario to estimate if the write volume approaches the single partition's limit.
To estimate the total number of partitions, consider the write throughput and reserve an additional 50% resource of CPU to ensure query performance and stability. Adjust this ratio as necessary. You can reserve more CPU cores if there are more queries.
Partitioning Methods
GreptimeDB employs expressions to define partitioning rules. For optimal performance, select partition keys that are evenly distributed, stable, and align with query conditions.
Examples include:
- Partitioning by the prefix of a trace id.
- Partitioning by data center name.
- Partitioning by business name.
The partition key should closely match the query conditions. For instance, if most queries target data from a specific data center, using the data center name as a partition key is appropriate. If the data distribution is not well understood, perform aggregate queries on existing data to gather relevant information.
For more details, refer to the table partition guide.