数据建模指南
表结构设计将极大影响写入和查询性能。 在写入数据之前,你需要了解业务中涉及到的数据类型、数据规模以及常用查询, 并根据这些数据特征进行数据建模。 本文档将详细介绍 GreptimeDB 的数据模型使用指南,以及常见场景的表结构设计方式。
了解 GreptimeDB 的数据模型
在阅读本文档之前,请先阅读 GreptimeDB 数据模型文档。
基本概念
基数(Cardinality):指数据集中唯一值的数量。可以分为"高基数"和"低基数":
- 低基数(Low Cardinality):低基数列通常具有固定值。
唯一值的总数通常不超过1万个。
例如,
namespace、cluster、http_method通常是低基数的。 - 高基数(High Cardinality):高基数列包含大量的唯一值。
例如,
trace_id、span_id、user_id、uri、ip、uuid、request_id、表的自增 ID,时间戳通常是高基数的。
列类型
在 GreptimeDB 中,列被分为三种语义类型:Tag、Field 和 Timestamp。
时间戳通常表示数据采样的时间或日志/事件发生的时间。
GreptimeDB 使用 TIME INDEX 约束来标识 Timestamp 列。
因此,Timestamp 列也被称为 TIME INDEX 列。
如果你有多个时间戳数据类型的列,你只能将其中一个定义为 TIME INDEX,其他的定义为 Field 列。
在 GreptimeDB 中,Tag 列是可选的。Tag 列的主要用途包括:
- 定义存储时数据的排序方式。
GreptimeDB 使用
PRIMARY KEY约束来定义 tag 列和 tag 的排序顺序。 与传统数据库不同,GreptimeDB 的主键是用来定义时间序列的。 GreptimeDB 中的表按照(primary key, timestamp)的顺序对行进行排序。 这提高了具有相同 tag 数据的局部性。 如果没有定义 tag 列,GreptimeDB 按时间戳对行进行排序。 - 唯一标识一个时间序列。 当表不是 append-only 模式时,GreptimeDB 根据时间戳在同一时间序列(主键)下去除重复行。
- 便于从使用 label 或 tag 的其他时序数据库迁移。
主键
主键是可选的
错误的主键或索引可能会显著降低性能。 通常,你可以创建一个没有主键的仅追加表,因为对于许多场景来说,按时间戳排序数据已经有不错测性能了。 这也可以作为性能基准。
CREATE TABLE http_logs (
access_time TIMESTAMP TIME INDEX,
application STRING,
remote_addr STRING,
http_status STRING,
http_method STRING,
http_refer STRING,
user_agent STRING,
request_id STRING,
request STRING,
) with ('append_mode'='true');
http_logs 表是存储 HTTP 服务器日志的示例。
'append_mode'='true'选项将表创建为仅追加表。 这确保一个日志不会覆盖另一个具有相同时间戳的日志。- 该表按时间对日志进行排序,因此按时间搜索日志效率很高。
何时使用主键
当有适合的低基数列且满足以下条件之一时,可以使用主键:
- 大多数查询可以从排序中受益。
- 你需要通过主键和时间索引对行进行去重(包括删除)。
例如,如果你总是只查询特定应用程序的日志,可以将 application 列设为主键(tag)。
SELECT message FROM http_logs WHERE application = 'greptimedb' AND access_time > now() - '5 minute'::INTERVAL;
应用程序的数量通常是有限的。表 http_logs_v2 使用 application 作为主键。
它按应用程序对日志进行排序,因此查询同一应用程序下的日志速度更快,因为它只需要扫描少量行。设置 tag 还能减少磁盘空间,因为它提高了数据的局部性,对压缩更友好。
CREATE TABLE http_logs_v2 (
access_time TIMESTAMP TIME INDEX,
application STRING,
remote_addr STRING,
http_status STRING,
http_method STRING,
http_refer STRING,
user_agent STRING,
request_id STRING,
request STRING,
PRIMARY KEY(application),
) with ('append_mode'='true');
为了提高时序场景下的排序和去重速度,GreptimeDB 内部按时间序列缓冲和处理行。 因此,它不需要反复比较每行的主键。 如果 tag 列具有高基数,这可能会成为问题:
- 由于数据库无法有效地批处理行,性能可能会降低。
- 由于数据库必须为每个时间序列维护元数据,可能会增加内存和 CPU 使用率。
- 去重可能会变得过于昂贵。
因此,不能将高基数列作为主键,或在主键中放入过多列。目前,主键值的推荐数量不超过 10 万。过长的主键将对插入性能产生负面影响并增加内存占用。主键最好不超过 5 个列。
选取 tag 列的建议:
- 在
WHERE/GROUP BY/ORDER BY中频繁出现的低基数列。 这些列通常很少变化。 例如,namespace、cluster或 AWSregion。 - 无需将所有低基数列设为 tag,因为这可能影响写入和查询性能。
- 通常对 tag 使用短字符串和整数,避免
FLOAT、DOUBLE、TIMESTAMP。 - 如果高基数列经常变化,切勿将其设为 tag。
例如,
trace_id、span_id、user_id绝不能用作 tag。 如果将它们设为 field 而非 tag,GreptimeDB 可以有很不错的性能。
索引
除了主键外,你还可以使用倒排索引按需加速特定查询。
GreptimeDB 支持倒排索引,可以加速对低基数列的过滤。
创建表时,可以使用 INVERTED INDEX 子句指定倒排索引列。
例如,http_logs_v3 为 http_method 列添加了倒排索引。
CREATE TABLE http_logs_v3 (
access_time TIMESTAMP TIME INDEX,
application STRING,
remote_addr STRING,
http_status STRING,
http_method STRING INVERTED INDEX,
http_refer STRING,
user_agent STRING,
request_id STRING,
request STRING,
PRIMARY KEY(application),
) with ('append_mode'='true');
以下查询可以使用 http_method 列上的倒排索引。
SELECT message FROM http_logs_v3 WHERE application = 'greptimedb' AND http_method = `GET` AND access_time > now() - '5 minute'::INTERVAL;
倒排索引支持以下运算符:
=<<=>>=INBETWEEN~
跳数索引
对于高基数列如 trace_id、request_id,使用跳数索引更为合适。
这种方法的存储开销更低,资源使用量更少,特别是在内存和磁盘消耗方面。
示例:
CREATE TABLE http_logs_v4 (
access_time TIMESTAMP TIME INDEX,
application STRING,
remote_addr STRING,
http_status STRING,
http_method STRING INVERTED INDEX,
http_refer STRING,
user_agent STRING,
request_id STRING SKIPPING INDEX,
request STRING,
PRIMARY KEY(application),
) with ('append_mode'='true');
以下查询可以使用跳数索引过滤 request_id 列。
SELECT message FROM http_logs_v4 WHERE application = 'greptimedb' AND request_id = `25b6f398-41cf-4965-aa19-e1c63a88a7a9` AND access_time > now() - '5 minute'::INTERVAL;
然而,请注意跳数索引的查询功能通常不如倒排索引丰富。 跳数索引无法处理复杂的过滤条件,在低基数列上可能有较低的过滤性能。它只支持等于运算符。
全文索引
对于需要分词和按术语搜索的非结构化日志消息,GreptimeDB 提供了全文索引。
例如,raw_logs 表在 message 字段中存储非结构化日志。
CREATE TABLE IF NOT EXISTS `raw_logs` (
message STRING NULL FULLTEXT INDEX WITH(analyzer = 'English', case_sensitive = 'false'),
ts TIMESTAMP(9) NOT NULL,
TIME INDEX (ts),
) with ('append_mode'='true');
message 字段使用 FULLTEXT INDEX 选项进行全文索引。
更多信息请参见fulltext 列选项。
存储和查询结构化日志通常比带有全文索引的非结构化日志性能更好。 建议使用 Pipeline 将日志转换为结构化日志。
何时使用索引
GreptimeDB 中的索引十分灵活。 你可以为任何列创建索引,无论该列是 tag 还是 field。 为 time index 列创建额外索引没有意义。 另外,你一般不需要为所有列创建索引。 因为维护索引可能引入额外成本并阻塞 ingestion。 不良的索引可能会占用过多磁盘空间并使查询变慢。
你可以用没有额外索引的表作为 baseline。 如果查询性能已经可接受,就无需为表创建索引。 在以下情况可以为列创建索引:
- 该列在过滤条件中频繁出现。
- 没有索引的情况下过滤该列不够快。
- 该列有合适的索引类型。
下表列出了所有索引类型的适用场景。
| 倒排索引 | 全文索引 | 跳数索引 | |
|---|---|---|---|
| 适用场景 | - 过滤低基数列 | - 文本内容搜索 | - 精确过滤高基数列 |
| 创建方法 | - 使用 INVERTED INDEX 指定 | - 在列选项中使用 FULLTEXT INDEX 指定 | - 在列选项中使用 SKIPPING INDEX 指定 |
去重
如果需要去重,可以使用默认表选项,相当于将 append_mode 设为 false 并启用去重功能。
CREATE TABLE IF NOT EXISTS system_metrics (
host STRING,
cpu_util DOUBLE,
memory_util DOUBLE,
disk_util DOUBLE,
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY(host),
TIME INDEX(ts)
);
当表不是 append-only 的时候,GreptimeDB 会通过相同的主键和时间戳对行进行去重。
例如,system_metrics 表通过 host 和 ts 删除重复行。
数据更新和合并
GreptimeDB 支持两种不同的去重策略:last_row 和 last_non_null。
你可以通过 merge_mode 表选项来指定策略。
GreptimeDB 使用基于 LSM-Tree 的存储引擎,
不会就地覆盖旧数据,而是允许多个版本的数据共存。
这些版本在查询时再合并。
默认的合并行为是 last_row,意味着只保留最近插入的行。
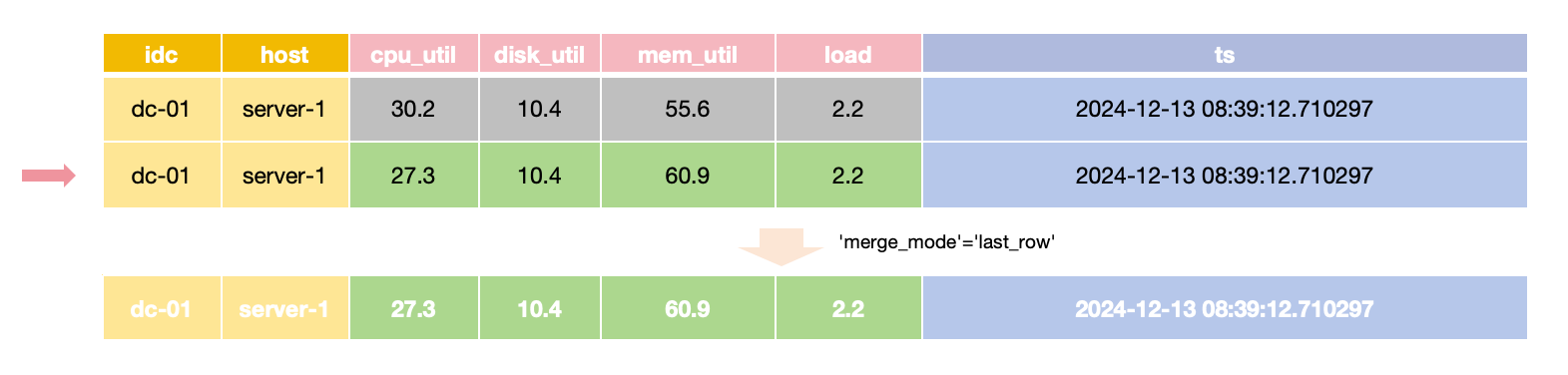
在 last_row 合并模式下,
对于相同主键和时间值,只返回最新的行,
所以更新一行时需要提供所有 field 的值。
对于只需要更新特定 field 值而其他 field 保持不变的场景,
可以将 merge_mode 选项设为 last_non_null。
该模式在查询时会选取每个字段的最新的非空值,
这样可以在更新时只提供需要更改的 field 的值。
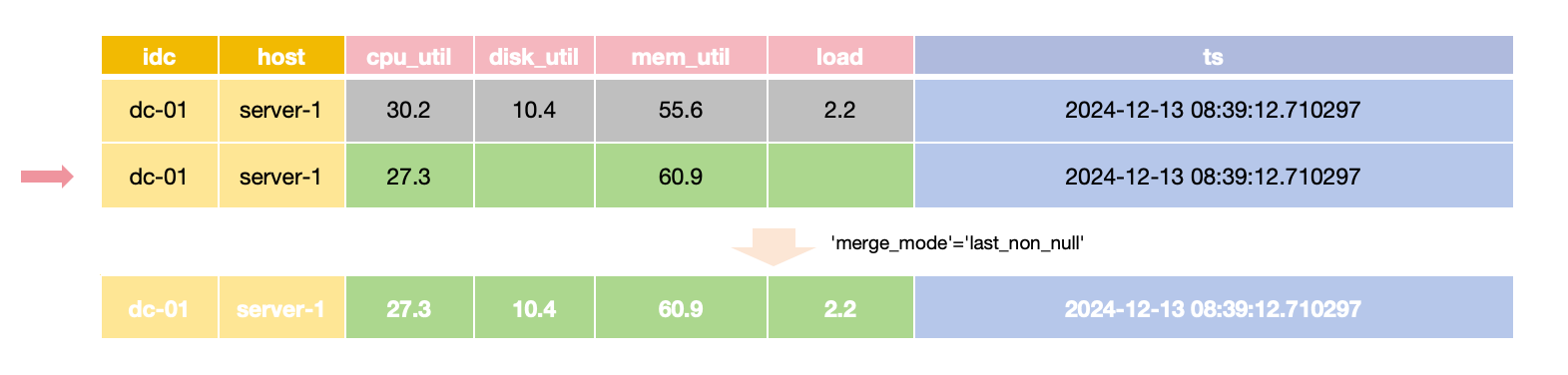
为了与 InfluxDB 的更新行为一致,通过 InfluxDB line protocol 自动创建的表默认启用 last_non_null 合并模式。
last_row 合并模式不需要检查每个单独的字段值,因此通常比 last_non_null 模式更快。
请注意,append-only 表不能设置 merge_mode,因为它们不执行合并。
何时使用 append-only 表
如果不需要以下功能,可以使用 append-only 表:
- 去重
- 删除
GreptimeDB 通过去重功能实现 DELETE,因此 append-only 表目前不支持删除。
去重需要更多的计算并限制了写入和查询的并行性,所以使用 append-only 表通常具有更好的性能。
宽表 vs. 多表
在监控或 IoT 场景中,通常同时收集多个指标。 我们建议将同时收集的指标放在单个表中,以提高读写吞吐量和数据压缩效率。
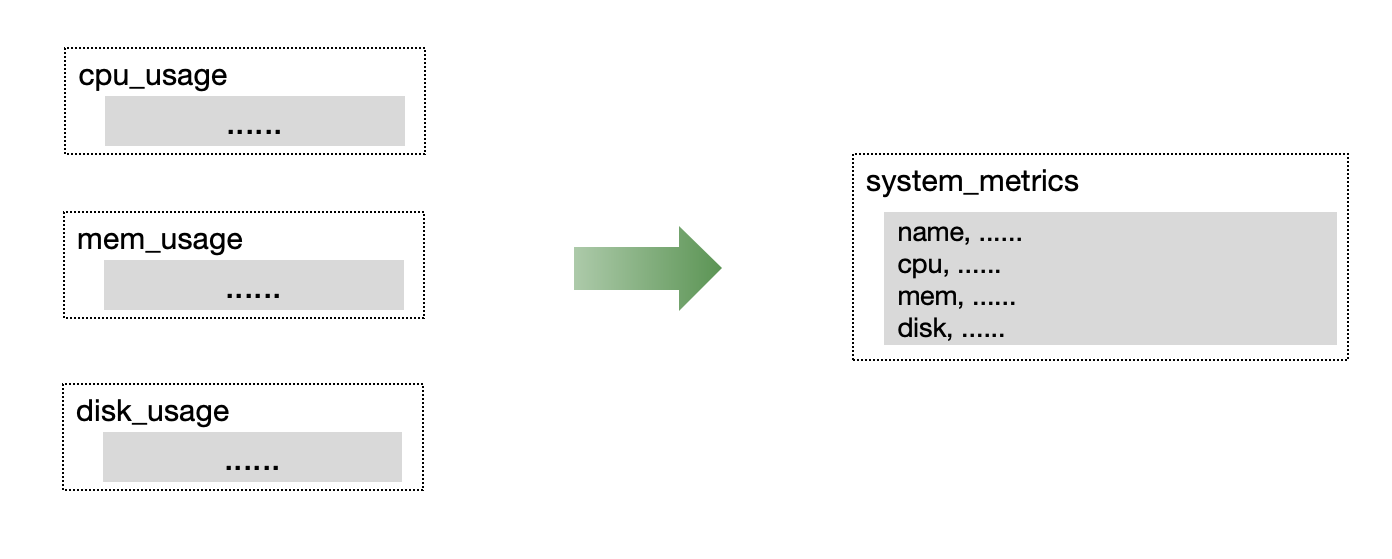
比较遗憾,Prometheus 的存储还是多表单值的方式,不过 GreptimeDB 的 Prometheus Remote Storage protocol 通过Metric Engine在底层使用宽表数据共享。
分布式表
GreptimeDB 支持对数据表进行分区,以分散读写热点并实现水平扩展。
关于分布式表的两个误解
作为时序数据库,GreptimeDB 在存储层自动基于 TIME INDEX 列对数据进行分区。 因此,你无需也不建议按时间分区数据 (例如,每天一个分区或每周一个表)。
此外,GreptimeDB 是列式存储数据库, 因此对表进行分区是指按行进行水平分区, 每个分区包含所有列。
何时分区以及确定分区数量
单个表能够利用机器中的所有资源,特别是在查询的时候。 分区表并不总是能提高性能:
- 分布式查询计划并不总是像本地查询计划那样高效。
- 分布式查询可能会引入网络间额外的数据传输。
因此,除非单台机器不足以服务表,否则无需分区表。 例如:
- 本地磁盘空间不足以存储数据或在使用对象存储时缓存数据。
- 你需要更多 CPU 来提高查询性能或更多内存用于高开销的查询。
- 磁盘吞吐量成为瓶颈。
- 写入速率大于单个节点的吞吐量。
GreptimeDB 在每次主要版本更新时都会发布benchmark report, 里面提供了单个分区的写入吞吐量作为参考。 你可以在你的的目标场景根据该报告来估计写入量是否接近单个分区的限制。
估计分区总数时,可以考虑写入吞吐量并额外预留 50% 的 CPU 资源,以确保查询性能和稳定性。也可以根据需要调整此比例。例如,如果查询较多,那么可以预留更多 CPU 资源。
分区方法
GreptimeDB 使用表达式定义分区规则。 为获得最佳性能,建议选择均匀分布、稳定且与查询条件一致的分区键。
例如:
- 按 trace id 的前缀分区。
- 按数据中心名称分区。
- 按业务名称分区。
分区键应该尽量贴合查询条件。 例如,如果大多数查询针对特定数据中心的数据,那么可以使用数据中心名称作为分区键。 如果不了解数据分布,可以对现有数据执行聚合查询以收集相关信息。 更多详情,请参考表分区指南