Why GreptimeDB
GreptimeDB is a cloud-native, distributed and open source Time Series Database (TSDB), it's designed to process, store and analyze vast amounts of time-series data. It's highly efficient at handling hybrid processing workloads which involve both time-series and real-time analysis, while providing users with great experience. To gain insight into the motivations that led to the development of GreptimeDB, we recommend reading our blog post titled "This Time, for Real". In this article, we delve into the reasons behind Greptime's high performance and some highlighted features.
Availability, Scalability, and Elasticity
From day 0, GreptimeDB was designed following the principles of cloud-native databases, which means that it runs and takes full advantage of the cloud. Some of the benefits include:
- highly available, on-demand computing resources with a goal to achieve availability and uptime rate of 99.999%, resulting in approximately five minutes and 15 seconds of downtime per year.
- Elasticity and scalability, allowing users to easily scale up or down, add or move resources according to usage.
- Highly reliable and fault tolerant, with the system having a 99.9999% availability rate as the goal to prevent data loss.
Together, these features ensure that GreptimeDB always provides optimal functionality. Below, we provide additional technical explanation on how these features are accomplished.
Resource Isolation for Elastic Scaling
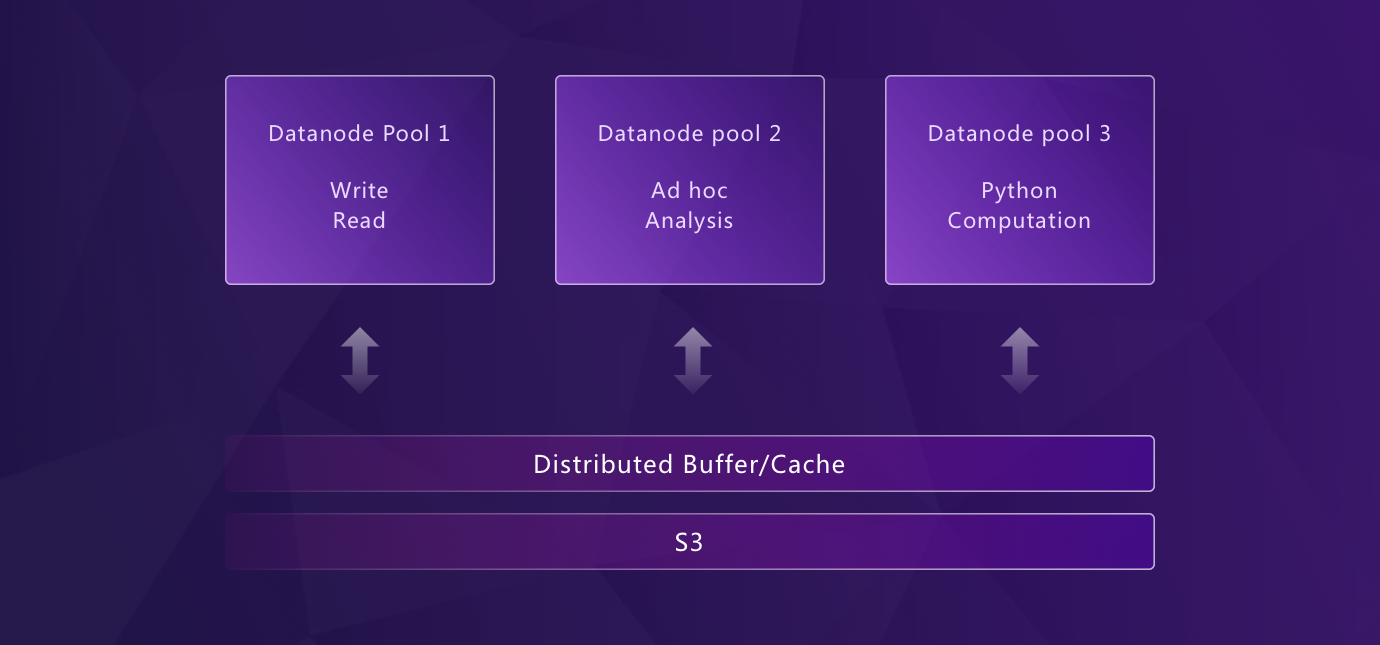
The storage and compute resources are separated, allowing each to be scaled, consumed and priced independently. This greatly increases utilization of computing resources, allows the "pay-as-you-go" pricing model and avoids waste of underutilized resources.
Besides storage and compute isolation, different compute resources are also isolated to offer new efficiencies for real-time analytics at scale with shared real-time data by avoiding contention for tasks such as data ingestion and queries, ad-hoc queries, and data compaction or rollup. Data can be shared among multiple applications without the need of competing for the same pool of resources which greatly improve efficiency, and unlimited concurrency scalability can be provided based on demand.
Flexible Architecture Supports Various Deployment Strategies
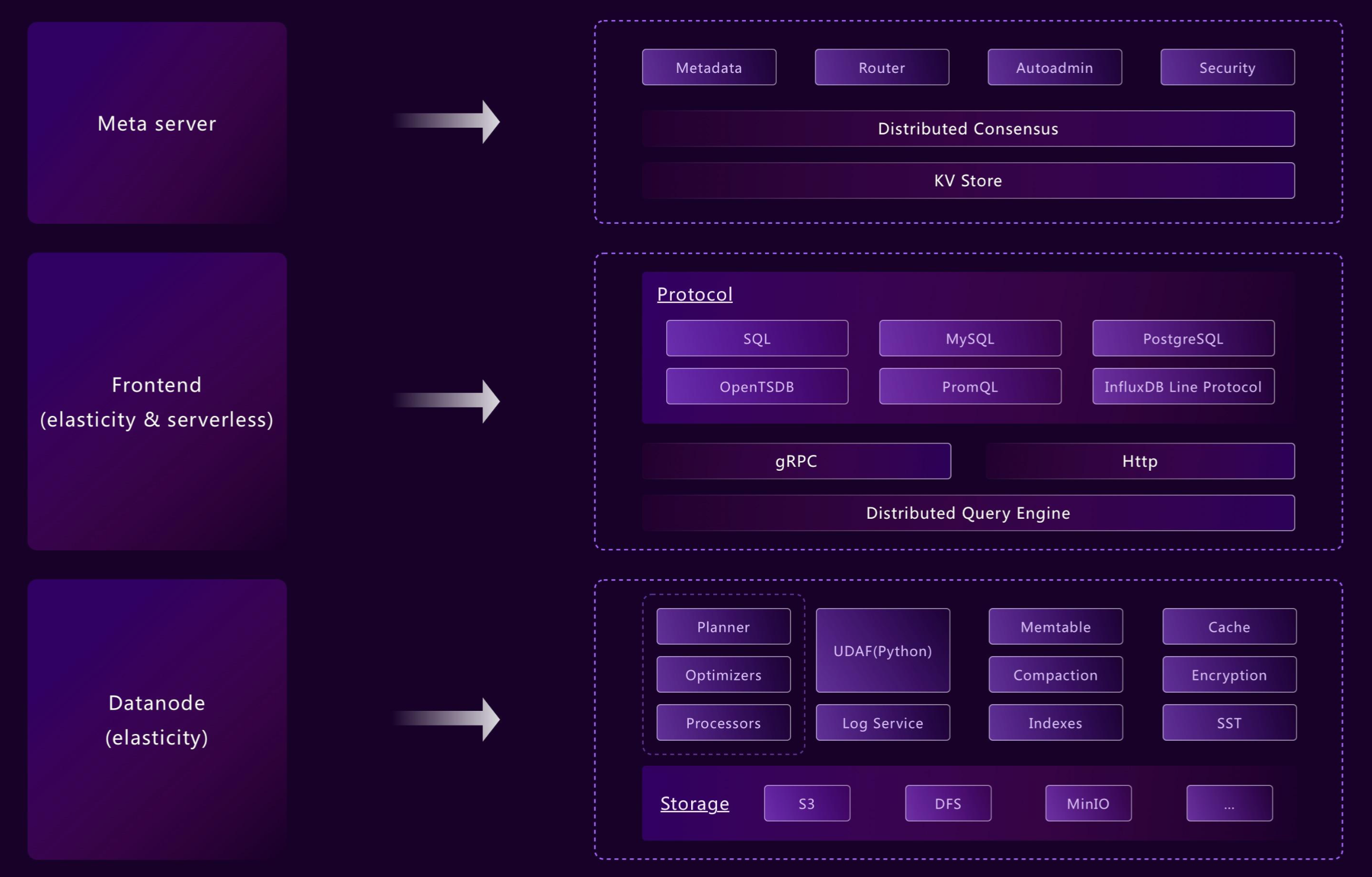
With flexible architecture design principles, different modules and components can be independently switched on, combined, or separated through modularization and layered design. For example, we can merge the frontend, datanode, and metasrv modules into a standalone binary, and we can also independently enable or disable the WAL for every table.
Flexible architecture allows GreptimeDB to meet deployment and usage requirements in scenarios from the edge to the cloud, while still using the same set of APIs and control panels. Through well-abstracted layering and encapsulation isolation, GreptimeDB's deployment form supports various environments from embedded, standalone, and traditional clusters to cloud-native.
Cost-Effective
GreptimeDB utilizes popular object storage solutions such as AWS S3 and Azure Blob Storage to store large amounts of time series data, allowing users to only pay for the amount of storage resources being used.
GreptimeDB uses adaptive compression algorithms to reduce the amount of data based on the type and cardinality of it to meet the temporal and spatial complexity constraints. For example, for string data type, GreptimeDB uses dictionary compression when the cardinality of a block exceeds a certain threshold; for float point numbers, GreptimeDB adopts the Chimp algorithm which enhances Gorrila's (Facebook's in-memory TSDB) algorithm by analyzing real-case time-series datasets, and offers a higher compression rate and spatial efficiency than traditional algorithms (such as zstd, Snappy, etc).
High Performance
As for performance optimization, GreptimeDB utilizes different techniques such as, LSM Tree, data sharding and quorum-based WAL design, to handle large workloads of time-series data ingestion.
The powerful and fast query engine is powered by vectorized execution and distributed parallel processing, and combined with indexing capabilities. GreptimeDB builds smart indexing and Massively Parallel Processing (MPP) to boost pruning and filtering. We use independent index files to record statistical information, like what Apache Parquet's row group metadata does. Built-in metrics are also used to record the workloads of different queries. Combining Cost-Based Optimization(CBO) with user-defined hints, we are able to build a smart index heuristically.
Easy to Use
Easy to Deploy and Maintain
To simplify deployment and maintenance processes, GreptimeDB provides K8s operator, command-line tool, embedded dashboard, and other useful tools for users to configure and manage their databases easily. Check GreptimeCloud on our official website for more information.
Easy to Integrate
Several protocols are supported for database connectivity, including MySQL, PostgreSQL, InfluxDB, OpenTSDB, Prometheus RemoteStorage, and high-performance gRPC. Additionally, SDKs are provided for various programming languages, such as Java, Go, Erlang, and more to come. We are continuously integrating and connecting with other open-source software in the ecosystem to enhance developer experience. In the following paragraphs, we will elaborate on three popular languages: PromQL, SQL and Python.
PromQL is a popular query language that allows users to select and aggregate real-time time series data provided by Prometheus. It is much simpler to use than SQL for visualization with Grafana and creating alert rules. GreptimeDB supports PromQL natively and effectively by transforming it into a query plan, which is then optimized and executed by the query engine.
SQL is a highly efficient tool for analyzing data that spans over a long time span or involves multiple tables, such as table joins. Additionally, it proves to be convenient for database management.
Python is very popular among data scientists and AI experts. GreptimeDB enables Python scripts to be run directly in the database. Developers can write UDF and DataFrame API to accelerate data processing by embedding the Python interpreter.
Simple Data Model with Automatic Schema
Combining the metrics (Measurement/Tag/Field/Timestamp) model and the relational data model (Table), GreptimeDB provides a new data model called a time-series table (see below), which presents data in the form of tables consisting of rows and columns, with tags and fields of the metrics mapped to columns, and an enforced time index constraint that represents the timestamp.
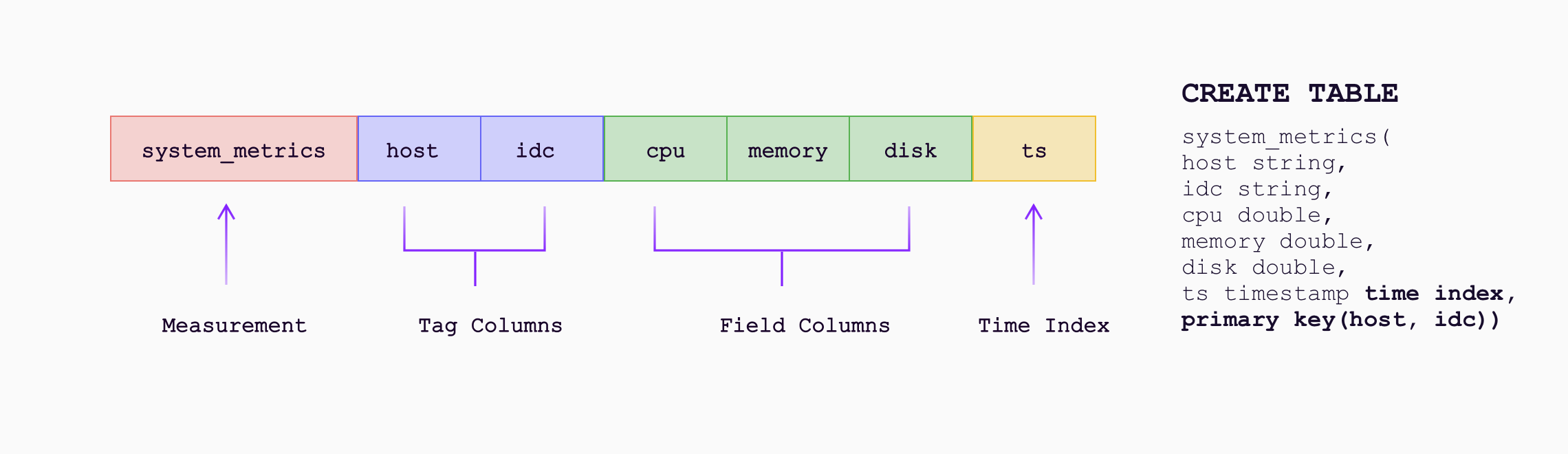
Nevertheless, our definition of a schema is not mandatory but leans more towards the schemaless approach of databases like MongoDB. The table will be created dynamically and automatically when data is ingested, and new columns (tags and fields) will be added as they appear.