基于双活互备的 DR 解决方案
在 GreptimeDB 的“双活互备”架构中,通常部署两个节点(例如节点 A 与节点 B):
- 两个节点都对外提供完整服务能力。
- 两个节点互为主从,角色是对等的,不存在长期固定的单主节点。
- 写入采用双向异步复制,任一节点接收到写请求后都会异步复制到对端节点。
- GreptimeDB 的架构防止了循环复制的问题。
- 查询在各自节点本地执行,不需要跨节点合并查询结果。
该模式的目标是:在不引入第三个计算节点或管理节点的前提下,以较低架构复杂度获得跨节点容灾能力。
架构与读写路径
写入路径
- 客户端将写请求发送到节点 A(或节点 B)。
- 发起节点本地落盘,写请求视为成功(返回给客户端)。
- 发起节点将写请求异步复制到对端节点。
- 若累积的未复制成功的写请求过多(具体数值可配置),发起节点可暂停客户端写入,以达到 RPO 和 RTO 的目标。
查询路径
- 客户端连接哪个节点,就在该节点本地执行查询。
- 不依赖双节点实时查询合并。
- 只要任一节点可用,查询链路就可以继续提供服务。
- 由于异步复制的特性,我们在此架构中可获得数据的最终一致性(eventually consistency)。
RPO 与 RTO
RPO
RPO 可通过不同的配置来达到不同的效果。
核心的配置是节点预留给待复制的写入请求的空间大小。
若该空间大小为 0(字节),则异步复制退化为同步复制,RPO 为 0。
配置为其他值时,RPO 的值可根据写入请求的大小和速度动态计算。
RTO
RTO 的值和节点切换方式有关,不同的节点切换方法和配置可获得不同的 RTO 目标。 见下文“故障切换实现方式”部分。
故障切换实现方式
为了保持我们的双活互备架构的最低需求,我们没有要求第三个节点或第三个服务来处理 GreptimeDB 的故障转移。一般来说,有几种方法可以处理故障转移:
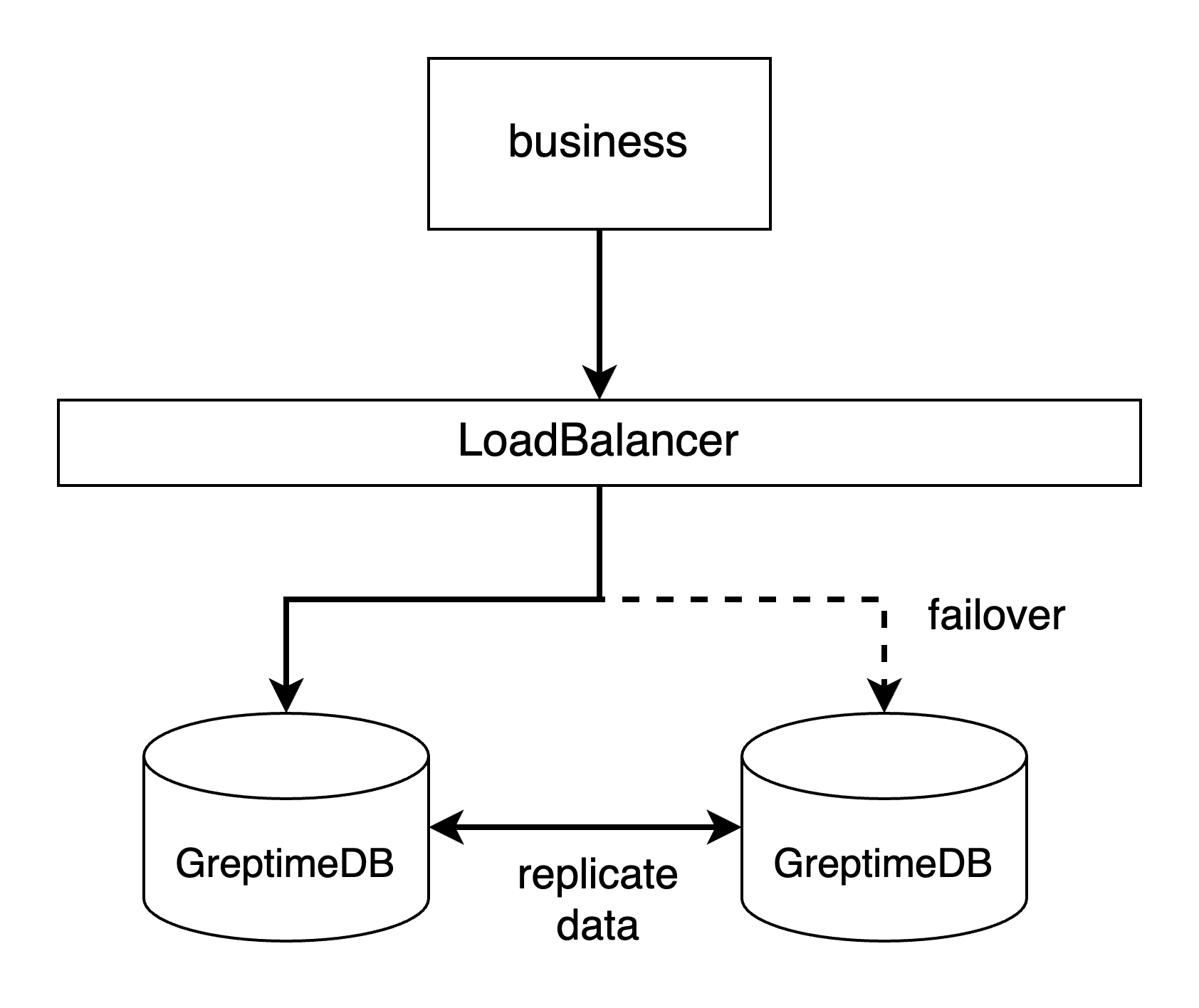
- 通过一个 LoadBalancer。如果你可以额外腾出另一个节点来部署一个 LoadBalancer
如 HAProxy,或者你有其他 LoadBalance
服务,我们推荐这种方式。
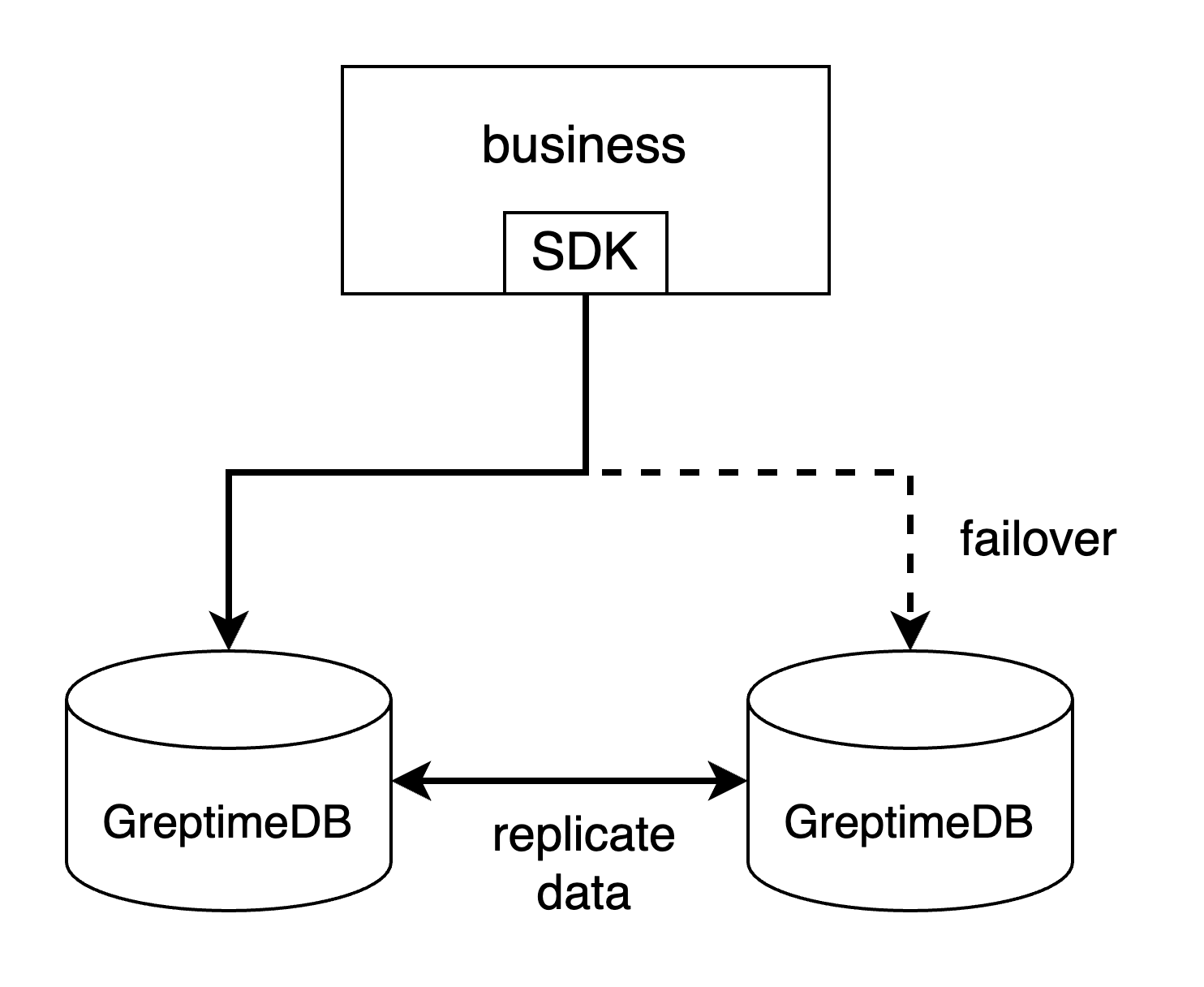
- 通过客户端 SDK 的故障转移机制。例如,如果你使用 MySQL Connector/j,你可以通过在连接 URL
中设置多个主机和端口来配置故障转移(参见其文档
)。PostgreSQL 的驱动程序也有相同的机制
。这是处理故障转移最简单的方法,但并不是每个客户端 SDK 都支持这种故障转移机制。
- 内部的 endpoint 更新机制。如果你可以检测到节点的故障,那么就可以在你的代码中更新 GreptimeDB 的 endpoint。
NOTE
请参考 "解决方案比较" 来比较不同灾难恢复解决方案的 RPO 和 RTO。
总结
GreptimeDB 双活互备 DR 方案的核心是:
- 两节点互为主从、双向异步复制写入。
- 查询在各自节点本地执行。
- 通过外部故障切换机制保障业务在单节点故障时快速恢复。
在该模式下,架构简单、RPO 和 RTO 目标明确且可配置。 该解决方案比较适合用在中小规模的业务场景中。