概述
读副本 (Read Replica) 是 GreptimeDB 企业集群版中的一项重要功能,旨在提升系统的整体读写性能与可扩展性。
在读副本机制中,客户端将数据写入写副本 (Leader Region),随后由 Leader Region 将数据同步到 Follower Region。Follower Region 作为 Leader Region 的只读副本。通过配置 Datanode 组,可以将 Leader Region 与 Follower Region 分别部署在不同的 Datanode 节点上,读写请求能够有效隔离,避免资源争用,从而获得更平滑的读写体验:
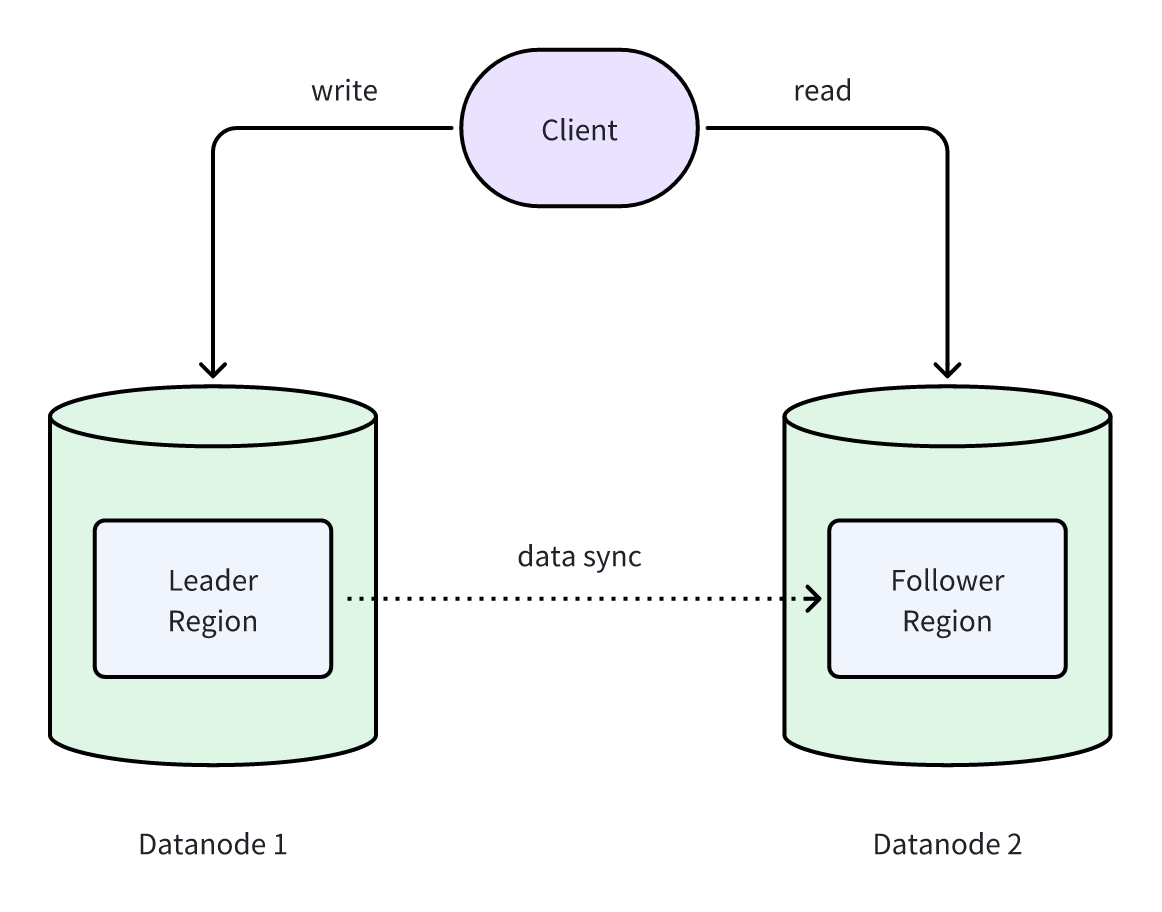
原理
GreptimeDB 企业集群版基于存算分离架构,使副本间的数据同步几乎零成本;同时,读副本也能以极低延迟读取到最新写入的数据。下面分别介绍数据同步与数据读取机制。
数据同步
在 GreptimeDB 中,计算与存储解耦,所有数据以 SST 文件的形式存放在对象存储中。因此,Leader Region 与 Follower Region 之间无需复制 SST 文件本体,只需同步其元信息即可。元信息相比 SST 文件体量小得多,因而同步开销极低。一旦元信息同步完成,读副本便“拥有”相同的 SST 文件,从而可以读取数据:
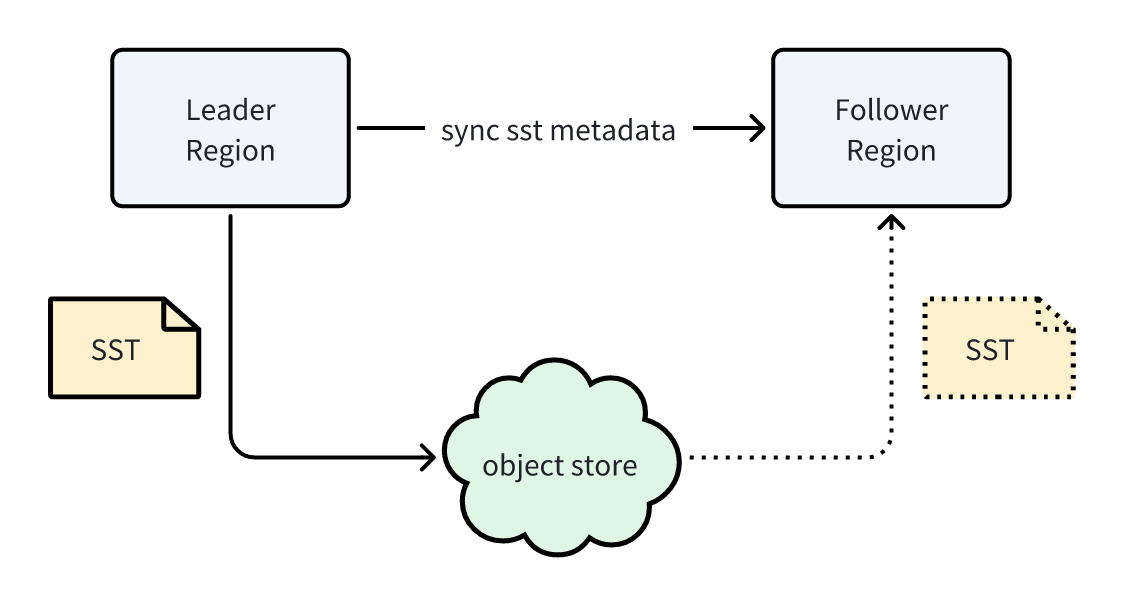
在实现上,SST 文件的元信息持久化在一个特殊的 manifest 文件中(同样位于对象存储)。每个 manifest 文件都有唯一的版本号。Leader Region 与 Follower Region 之间的同步,本质上就是同步这个版本号——一个简单的整数,开销极小。Follower Region 获得版本号后即可从对象存储拉取对应的 manifest 文件,从而获得 Leader Region 生成的 SST 元信息。
manifest 版本号通过 Region 与 Metasrv 之间的心跳进行同步:Leader Region 在发往 Metasrv 的心跳中携带版本号,Metasrv 在回复 Follower Region 的心跳中将其下发:
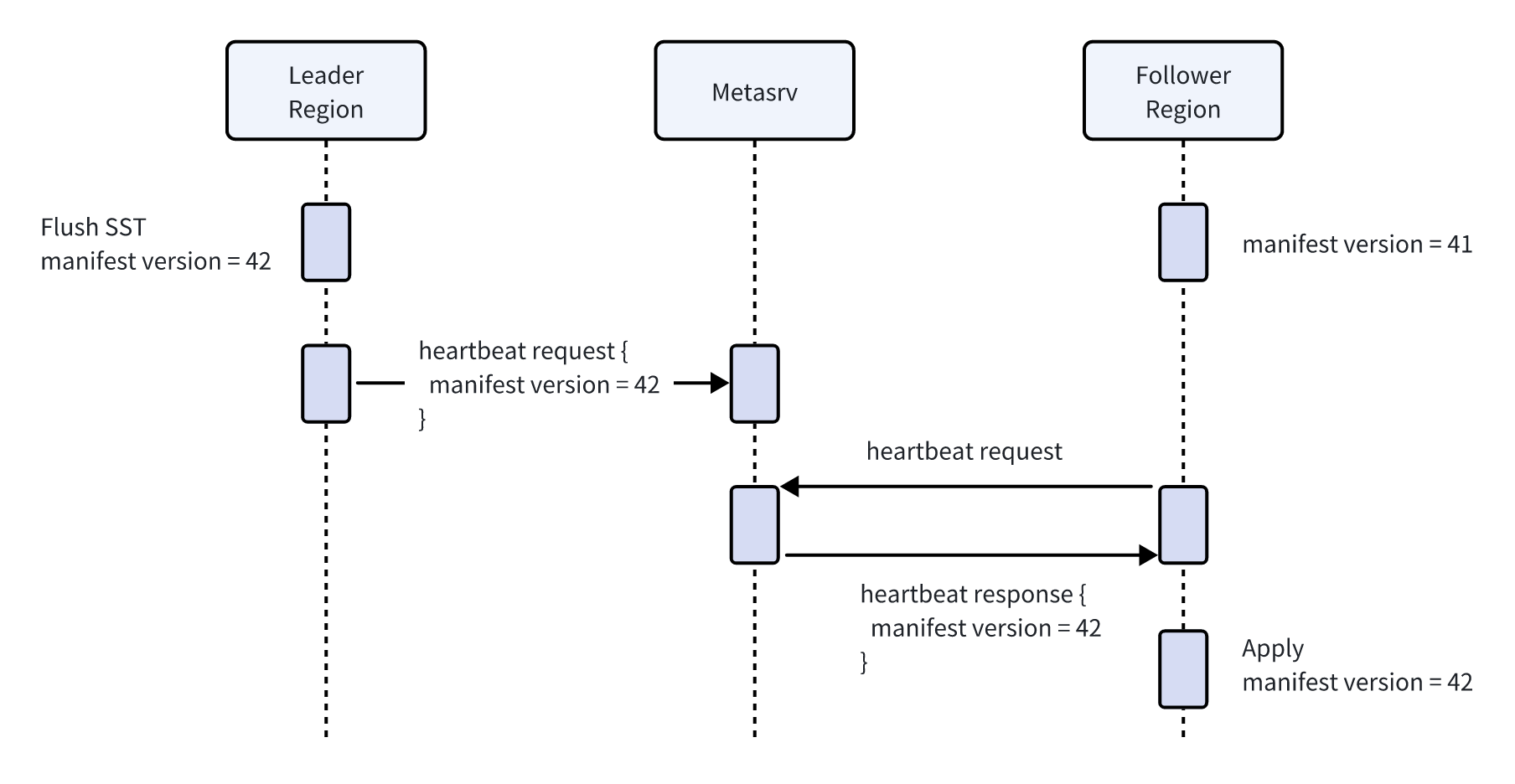
可以看出,若仅依赖 SST 文件层面的同步,读副本读到新写入数据的延迟约为 Leader Region 与 Follower Region 分别到 Metasrv 的心跳间隔之和。以默认 3 秒心跳为例,读副本通常只能读到 3–6 秒前已写入并 flush 至对象存储的数据。对于对数据“新鲜度”要求不高的场景已足够,但若需要近实时读取,还需配合下述机制。
数据读取
最新写入的数据首先保存在 Leader Region 的 memtable 中。为了读到这些最新数据,Follower Region 需要向 Leader Region 请求 memtable 数据,并与自身通过前述同步机制获得的 SST 数据合并,从而向客户端提供包含最新写入的完整结果集:
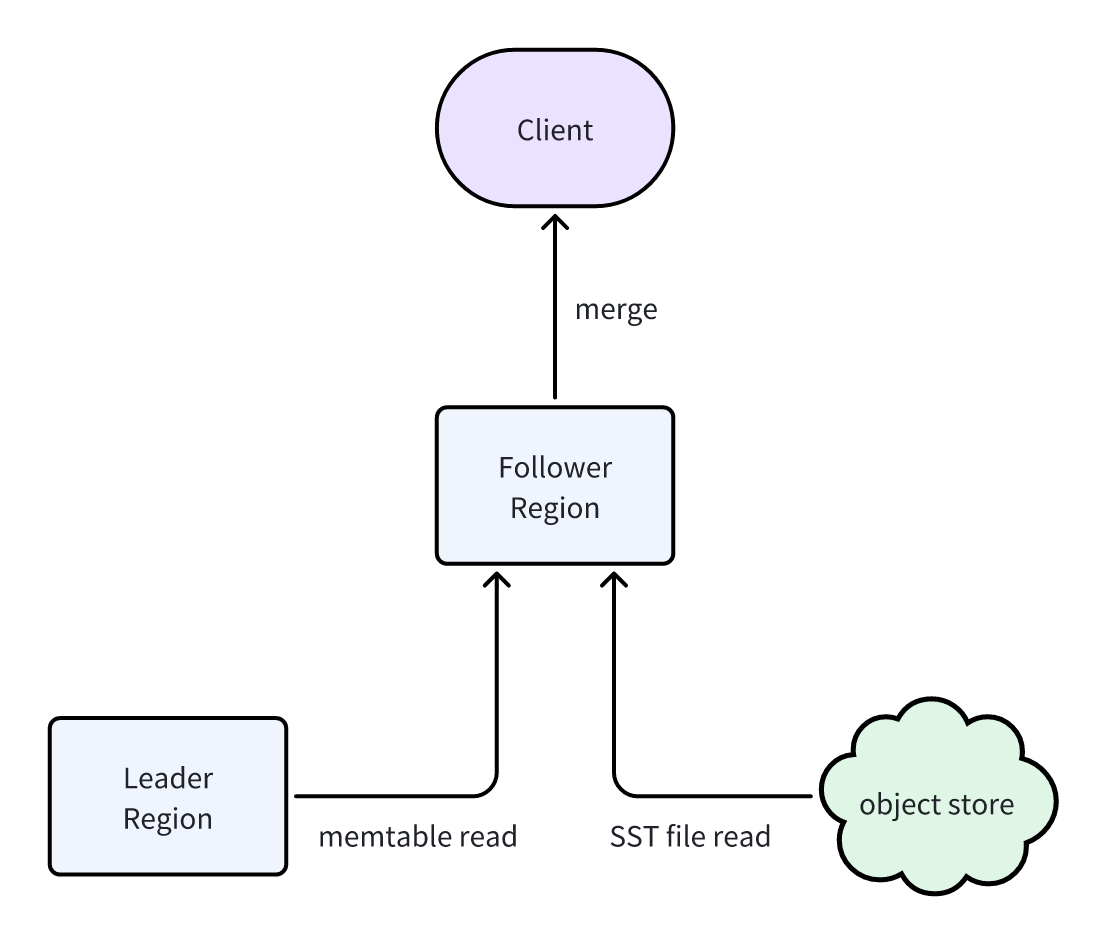
Follower Region 通过内部 gRPC 接口从 Leader Region 获取 memtable 数据。该过程会给 Leader Region 带来一定读负载,但由于 memtable 位于内存且大小受限,通常影响可控。