为什么选择 GreptimeDB
问题:三种信号,三套系统
大多数团队的可观测性栈长这样:Prometheus(或 Thanos/Mimir)跑 metrics,Grafana Loki(或 ELK)跑日志,Elasticsearch(或 Tempo)跑 traces。每套系统各有一套查询语言、存储方案、扩展方式,运维各管各的。
"三支柱"架构在这些关注点各自独立时是合理的。但实际跑起来就是:
- 3 倍运维量 — 三套系统要分别部署、监控、升级、排障
- 数据孤岛 — 错误率飙升和日志里的异常模式要手动在系统间切换才能关联
- 成本失控 — 每套系统存一份冗余元数据,各自独立扩展导致资源浪费
GreptimeDB 的思路不同:一个引擎处理三种信号,数据放对象存储,计算存储分离。
统一处理可观测数据
GreptimeDB 通过以下方式统一处理 metrics、logs 和 traces:
一套系统替代原来的多组件栈。
具体来说:用一个数据库替代 Prometheus + Loki + Elasticsearch,用 SQL 在一条查询里关联 metrics 异常、日志模式和 trace 延迟——不用在系统间来回切换。

对象存储,成本低一个数量级
GreptimeDB 以云对象存储(S3、Azure Blob Storage 等)为主存储层,配合列式压缩,存储成本最高可降低 50 倍。支持灵活扩展到各类云存储,管理简单,无厂商锁定。
生产环境实测:
- Logs:OceanBase Cloud 生产环境存储成本下降 60%+(从 Loki 迁移到 GreptimeDB,80+ 集群、300TB 多云日志和 SQL 审计数据)
- Traces:存储成本降低 45 倍,查询快 3 倍(替换 Elasticsearch 作为 Jaeger 后端,一周完成迁移)
- Metrics:用原生计算存储分离替代 Thanos,运维复杂度大幅下降
高性能
写入端,GreptimeDB 用 LSM Tree、数据分片、灵活的 WAL 配置(本地盘或 Kafka)等手段处理大规模可观测数据的写入负载。
查询端,GreptimeDB 用纯 Rust 编写,查询引擎基于 Apache DataFusion 做向量化执行和分布式并行处理,结合多种索引(倒排索引、跳数索引、全文索引)做智能裁剪和过滤。
GreptimeDB 在 JSONBench 10 亿条记录冷查询中拿下第一! 更多性能测试报告。
基于 Kubernetes 的弹性扩展
GreptimeDB 从底层就为 Kubernetes 设计,采用计算存储分离架构,实现真正的弹性扩展:
- 存储和计算资源独立伸缩
- 通过 Kubernetes 水平扩展,无上限
- 写入、查询、压缩等不同负载之间做资源隔离
- 自动故障转移和高可用
Thanos 和 Mimir 要靠多个有状态组件(ingester 需要持久盘、store-gateway、compactor)才能扩展。GreptimeDB 从架构层面就是计算存储分离——数据持久化在对象存储,计算节点独立扩展,本地盘只做缓冲和缓存。扩容加节点,缩容不丢数据。
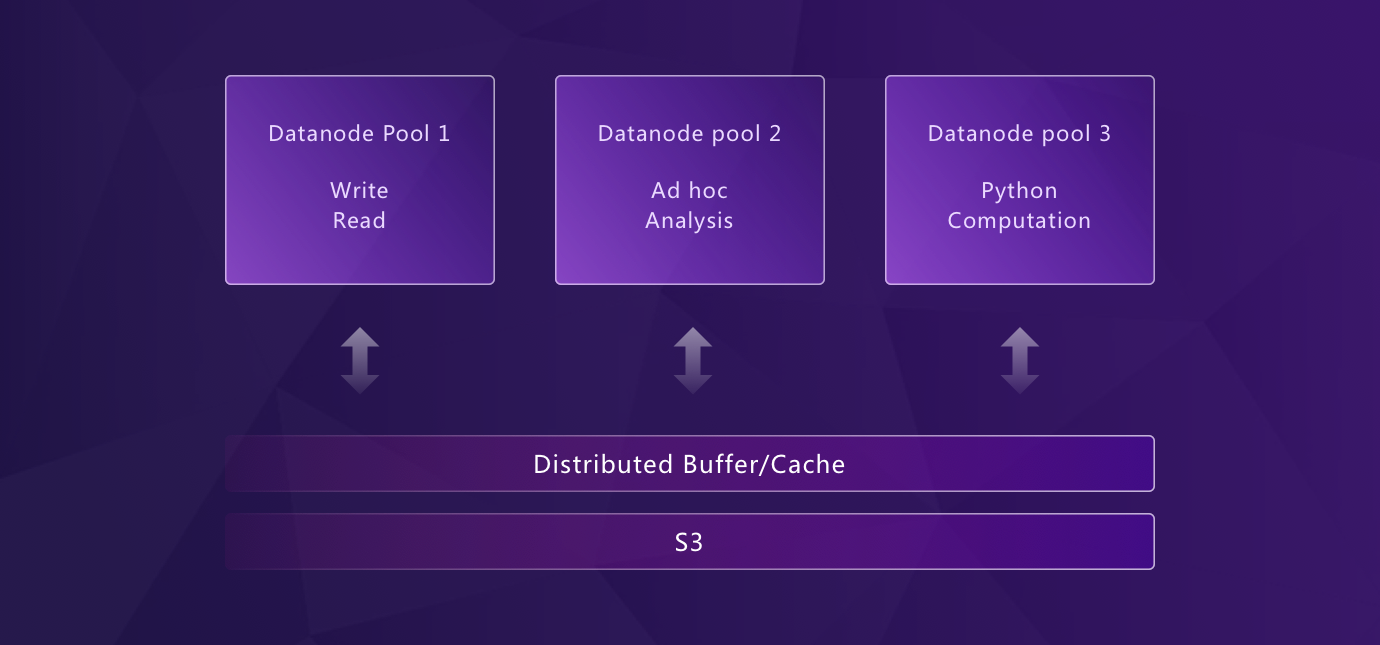
灵活部署:从边缘到云
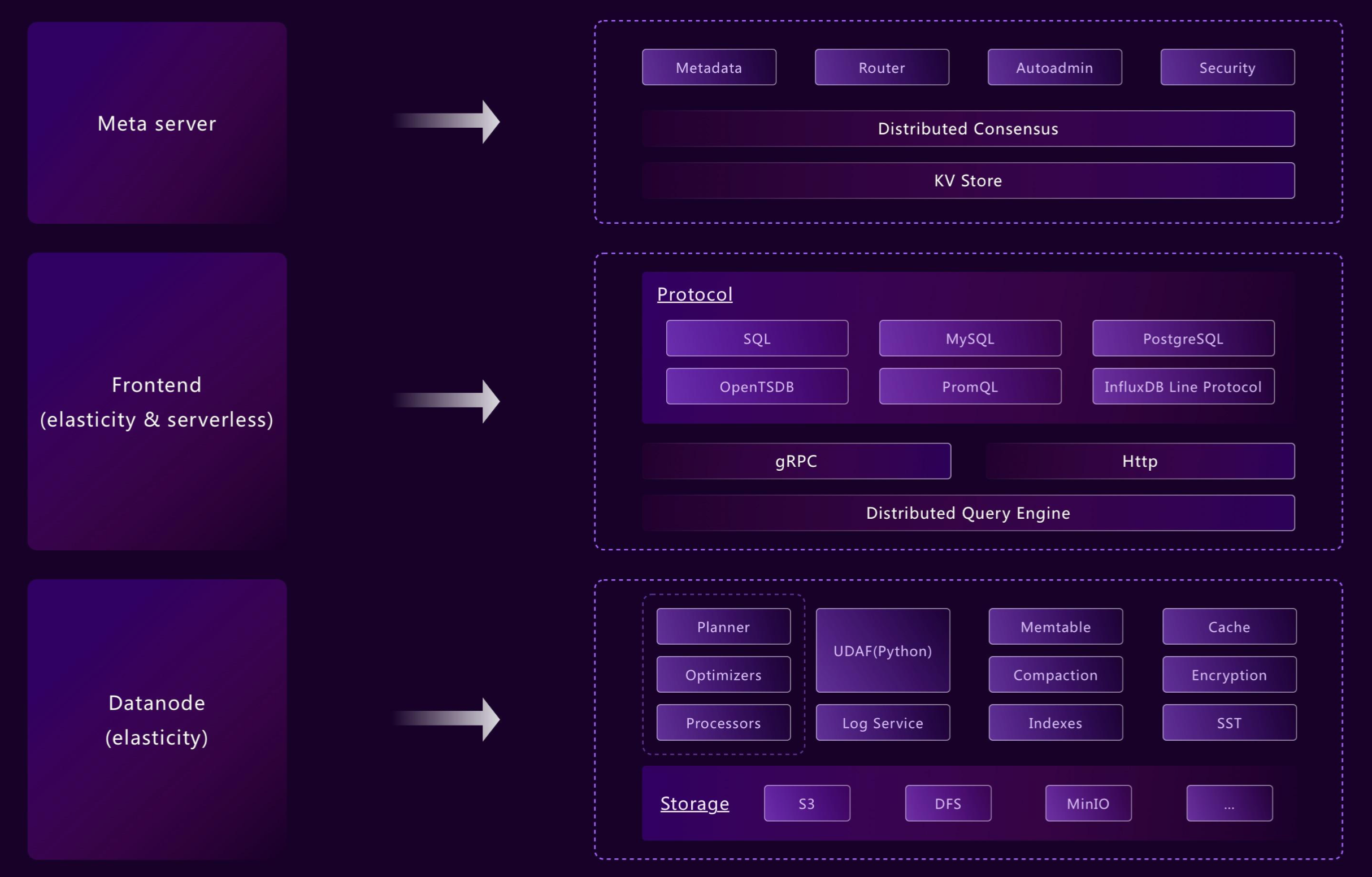
GreptimeDB 的模块化架构让各组件既能独立运行,也能协同部署。从边缘设备到云环境,都用同一套 API。比如:
- Frontend、Datanode 和 Metasrv 可以合并成单一二进制(standalone 模式)
- WAL、索引等组件可以按表级别启用或关闭
这种灵活性让 GreptimeDB 能覆盖从边缘到云的完整场景,比如边云一体化解决方案。
从嵌入式单机部署到云原生集群,GreptimeDB 都能适配。
易于集成
GreptimeDB 支持 PromQL、Prometheus remote write、OpenTelemetry、Jaeger、Loki、Elasticsearch、MySQL、PostgreSQL 协议——从现有栈迁移不用改查询、不用改 pipeline。查询用 SQL 或 PromQL,可视化接 Grafana。
SQL + PromQL 双引擎意味着 GreptimeDB 可以替代"Prometheus + 数据仓库"的经典组合——PromQL 做实时监控告警,SQL 做深度分析、JOIN、聚合,全在一个系统里。GreptimeDB 还支持多值模型,单行可以有多个字段列,比单值模型省流量、查询也更简洁。
SQL 不只是查询语言,也是 GreptimeDB 的管理入口——建表、管理 schema、设置 TTL 策略、配置索引,全部用标准 SQL 完成。不需要专有配置文件,不需要自定义 API,不需要 YAML 驱动的控制面。这是和 Prometheus(YAML 配置 + relabeling rules)、Loki(YAML 配置 + LogQL)、Elasticsearch(REST API + JSON mappings)在运维层面的关键区别。团队只要会 SQL,就能管理 GreptimeDB,不用学新工具。
GreptimeDB 对比
| GreptimeDB | Prometheus / Thanos / Mimir | Grafana Loki | Elasticsearch | |
|---|---|---|---|---|
| 数据类型 | Metrics、Logs、Traces | 仅 Metrics | 仅 Logs | Logs、Traces |
| 查询语言 | SQL + PromQL | PromQL | LogQL | Query DSL |
| 存储 | 原生对象存储(S3 等) | 本地盘 + 对象存储(Thanos/Mimir),ingester 需要持久盘 | 对象存储(chunks) | 本地盘 |
| 扩展 | 计算存储分离,计算节点独立扩展 | Federation / Thanos / Mimir — 多组件,运维重 | 无状态 + 对象存储 | 基于分片,运维重 |
| 成本 | 存储成本最高降低 50 倍 | 大规模下成本高 | 中等 | 高(倒排索引开销) |
| OpenTelemetry | 原生支持(Metrics + Logs + Traces) | 部分(仅 Metrics) | 部分(仅 Logs) | 通过 instrumentation |
| 管理方式 | 标准 SQL(DDL、TTL、索引) | YAML 配置 + relabeling rules | YAML 配置 + LogQL | REST API + JSON mappings |
了解更多:
- Observability 2.0 — 宽事件、统一数据模型,GreptimeDB 面向下一代可观测性的架构
- 可观测性统一存储 — GreptimeDB 的统一存储设计
- 替换 Loki!GreptimeDB 在 OB Cloud 的大规模日志存储实践