Flownode 批处理模式开发者指南
本指南简要概述了 flownode 中的批处理模式。它旨在帮助希望了解此模式内部工作原理的开发人员。
概述
flownode 中的批处理模式专为持续数据聚合而设计。它在离散的、微小的时间窗口上周期性地执行用户定义的 SQL 查询。这与数据在到达时即被处理的流处理模式形成对比。
其核心思想是:
- 定义一个带有 SQL 查询的
flow,该查询将数据从源表聚合到目标表。 - 查询通常在时间戳列上包含一个时间窗口函数(例如
date_bin)。 - 当新数据插入源表时,系统会将相应的时间窗口标记为“脏”(dirty)。
- 一个后台任务会周期性地唤醒,识别这些脏窗口,并为那些特定的时间范围重新运行聚合查询。
- 然后将结果插入到目标表中,从而有效地更新聚合视图。
架构
批处理模式由几个协同工作的关键组件组成,以实现这种持续聚合。如下图所示:
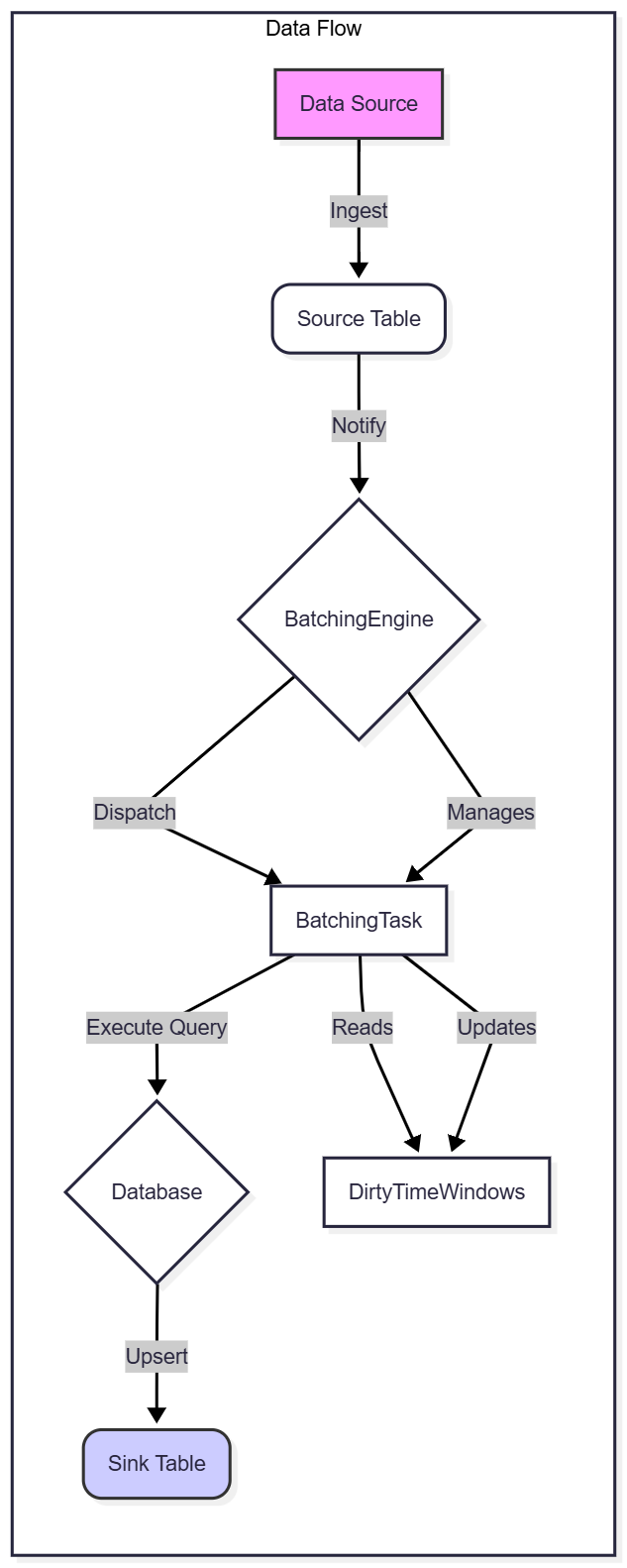
BatchingEngine
BatchingEngine 是批处理模式的核心。它是一个管理所有活动 flow 的中心组件。其主要职责是:
- 任务管理: 维护一个从
FlowId到BatchingTask的映射。它处理这些任务的创建、删除和检索。 - 事件分发: 当新数据到达(通过
handle_inserts_inner)或当时间窗口被显式标记为脏(handle_mark_dirty_time_window)时,BatchingEngine会识别受影响的 flow,并将信息转发给相应的BatchingTask。
BatchingTask
BatchingTask 代表一个独立的、单个的数据流。每个任务都与一个 flow 定义相关联,并在其自己的异步循环中运行。
- 配置 (
TaskConfig): 此结构体持有 flow 的不可变配置,例如 SQL 查询、源表和目标表名以及时间窗口表达式。 - 状态 (
TaskState): 包含任务的动态、可变状态,最重要的是DirtyTimeWindows。 - 执行循环: 任务运行一个无限循环 (
start_executing_loop),该循环:- 检查关闭信号。
- 等待一个预定的时间间隔或直到被唤醒。
- 基于当前的脏时间窗口集合生成一个新的查询计划 (
gen_insert_plan)。 - 对数据库执行查询 (
execute_logical_plan)。 - 清理已处理的脏窗口。
TaskState 和 DirtyTimeWindows
TaskState: 此结构体跟踪BatchingTask的运行时状态。它包括dirty_time_windows,这对于确定需要完成哪些操作至关重要。DirtyTimeWindows: 这是一个关键的数据结构,用于跟踪自上次查询执行以来哪些时间窗口接收到了新数据。它存储一组不重叠的时间范围。当任务的执行循环运行时,它会参考此结构来构建一个WHERE子句,该子句仅过滤源表中的脏时间窗口。
TimeWindowExpr
TimeWindowExpr 是一个用于处理像 TUMBLE 这样的时间窗口函数的辅助工具。
- 求值: 它可以接受一个时间戳并对时间窗口表达式求值,以确定该时间戳所属窗口的开始和结束。
- 窗口大小: 它还可以从表达式中确定时间窗口的大小(持续时间)。
这对于标记窗口为脏以及在查询源表时生成正确的过滤条件都至关重要。
查询执行流程
以下是批处理模式下查询执行的简化分步演练:
- 数据摄取: 新数据被写入源表。
- 标记为脏:
BatchingEngine收到有关新数据的通知。它使用与每个相关 flow 关联的TimeWindowExpr来确定哪些时间窗口受到新数据点的影响。然后将这些窗口添加到相应TaskState中的DirtyTimeWindows集合中。 - 任务唤醒:
BatchingTask的执行循环被唤醒,原因可能是其周期性调度,也可能是因为它被通知有大量积压的脏窗口。 - 计划生成: 任务调用
gen_insert_plan。此方法:- 检查
DirtyTimeWindows。 - 生成一系列
OR连接的WHERE子句(例如(ts >= 't1' AND ts < 't2') OR (ts >= 't3' AND ts < 't4') ...),覆盖所有脏窗口。 - 重写原始 SQL 查询以包含此新过滤器,确保只处理必要的数据。
- 检查
- 执行: 修改后的查询计划被发送到
Frontend执行。数据库处理已过滤数据的聚合。 - Upsert: 结果被插入到目标表中。目标表通常定义了一个包含时间窗口列的主键,因此现有窗口的新结果将覆盖(upsert)旧结果。
- 状态更新:
DirtyTimeWindows集合中刚刚处理过的窗口被清除。然后任务返回睡眠状态,直到下一个时间间隔。