存储引擎
概述
存储引擎 负责存储数据库的数据。Mito 是我们默认使用的存储引擎,基于 LSMT(Log-structured Merge-tree)。我们针对处理时间序列数据的场景做了很多优化,因此 mito 这个存储引擎并不适用于通用用途。
架构
下图展示了存储引擎的架构和处理数据的流程。
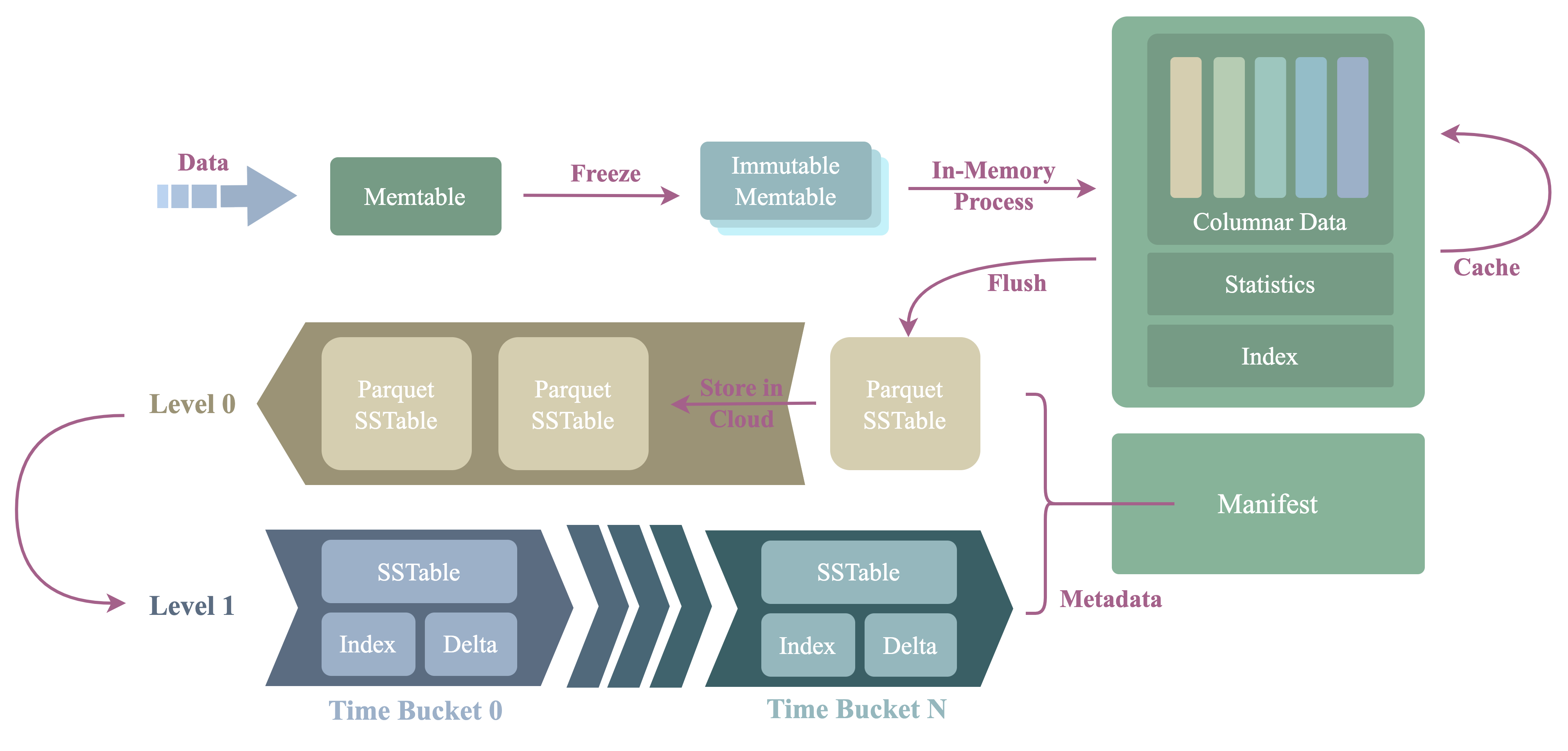
该架构与传统的 LSMT 引擎相同:
- WAL
- 为尚未刷盘的数据提供高持久性保证。
- 基于
LogStoreAPI 实现,不关心底层存储介质。 - WAL 的日志记录可以存储在本地磁盘上,也可以存储在实现了
LogStoreAPI 的远程日志服务中,例如 Kafka(remote WAL)。
- Memtable
- 数据首先写入
active memtable,又称mutable memtable。 - 当
mutable memtable已满时,它将变为只读的immutable memtable。
- 数据首先写入
- SST
- SST 的全名为有序字符串表(
Sorted String Table)。 immutable memtable刷到持久存储后形成一个 SST 文件。- SST 中的行按照主键和时间索引排序;详见 SST 文件中的数据布局。
- SST 的全名为有序字符串表(
- Compactor
Compactor通过 compaction 操作将小的 SST 合并为大的 SST。- 默认使用 TWCS 策略进行合并。Compaction 会按照时间窗口组织 SST 文件,并结合 TTL 清理过期数据。详见 Compaction。
- Manifest
Manifest存储引擎的元数据,例如 SST 的元数据。
- Cache
- 加速查询操作。
数据模型
存储引擎提供的数据模型介于 key-value 模型和表模型之间
tag-1, ..., tag-m, timestamp -> field-1, ..., field-n
每一行数据包含多个 tag 列,一个 timestamp 列和多个 field 列
0 ~ m个 tag 列- tag 列是可空的
- 在建表时通过
PRIMARY KEY指定
- 必须包含一个 timestamp 列
- timestamp 列非空
- 在建表时通过
TIME INDEX指定
0 ~ n个 field 列- field 列是可空的
- 数据按照 tag 列和 timestamp 列有序存储
Region
数据在存储引擎中以 region 的形式存储,region 是引擎中的一个逻辑隔离存储单元。region 中的行必须具有相同的 schema(模式),该 schema 定义了 region 中的 tag 列,timestamp 列和 field 列。数据库中表的数据存储在一到多个 region 中。
SST 文件中的数据布局
当 memtable 被 flush 时,Mito 会把其中的行写入不可变的 Apache Parquet SST 文件。关于 Parquet 文件格式本身以及 SST 文件如何建立索引,详见数据持久化和索引。
在一个 SST 文件内,行按照 (primary key, time index) 排序。具有相同 primary key(tag 列)的行属于同一条时间序列,会连续存储并按时间戳排序。这种局部性使得扫描单条时间序列的成本更低,也有助于提升压缩效果。对于没有 primary key 的 append-only 表,行仅按 time index 排序。
例如,考虑一个存储主机指标的表:
CREATE TABLE host_metrics (
host STRING,
region STRING,
ts TIMESTAMP TIME INDEX,
cpu DOUBLE,
memory DOUBLE,
PRIMARY KEY (host, region)
);
Mito 会按 primary key 对行分组,并按时间排序,因此 SST 中的数据在概念上类似于:
| host | region | ts | cpu | memory |
|---|---|---|---|---|
| host-a | us-east | 10:00 | 0.42 | 7.1 |
| host-a | us-east | 10:01 | 0.47 | 7.4 |
| host-a | us-west | 10:00 | 0.31 | 6.8 |
| host-b | us-east | 10:00 | 0.80 | 8.6 |
除了表中的列,Mito 还会在每个 SST 文件中存储三个内部列,以便在从多个 memtable 和 SST 文件读取时正确地合并、去重并应用删除操作:
__primary_key:行的编码后 primary key(tags)。__sequence:行的 sequence number。__op_type:行的操作类型(put 或 delete)。
每个 Parquet SST 都会被切分为 row group,row group 是 Parquet 可以独立读取或跳过的单位。每个 row group 都带有列统计信息,例如最小值、最大值和 null 数量。Mito 还会为每个 SST 记录文件级元数据,包括时间范围、行数、row group 数量、可用索引以及 primary key 范围。这些统计信息会驱动下面介绍的扫描裁剪。
Mito 支持两种 SST 格式:flat 和 primary_key。flat 是新表的默认格式,适用于各种 primary key 基数,包括高基数 key。primary_key 是为了兼容旧表而保留的遗留格式。更多详情请参考 SST format 和表设计指南。

扫描裁剪
Mito 会组合多个从粗到细的裁剪步骤,避免读取不可能匹配查询的数据:
- 时间范围裁剪。 如果文件和 memtable 的时间范围与查询时间范围不相交,就会在打开 reader 之前被跳过。对于时间序列查询,这通常是成本最低且最有效的步骤。
- Row group 统计信息。 如果 row group 的 min-max 统计信息能够证明没有任何行匹配谓词,则会跳过整个 row group。
- 索引。 倒排索引、跳数索引和全文索引可以针对统计信息无法处理的谓词提供更精细的裁剪。详见数据持久化和索引。
