架构
GreptimeDB 采用计算存储分离架构,持久化数据保存在对象存储中,计算节点可以独立扩展。 相比以本地磁盘作为主存储的架构,这种方式更容易实现弹性扩展,也更有利于降低运维成本。
高层架构
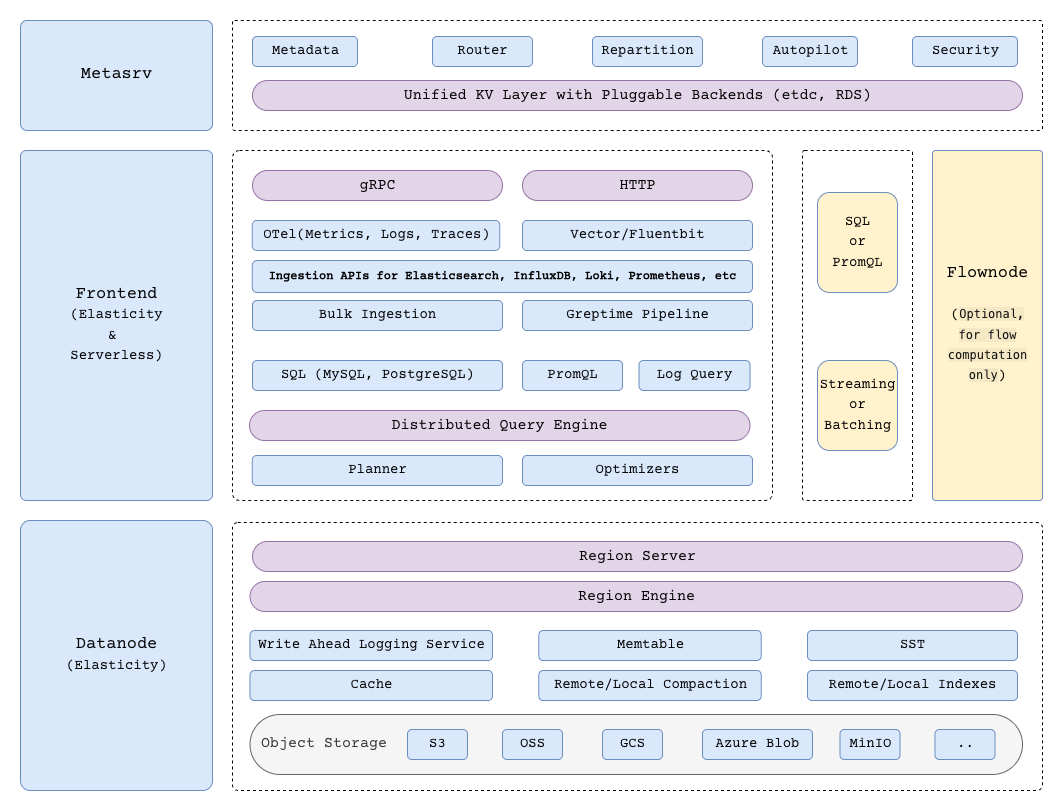
组件
GreptimeDB 在分布式模式下有三个核心组件,以及一个用于流计算的可选组件:
- Metasrv:元数据与路由控制平面。负责管理 catalog、schema、table、region 等元数据,协调调度,并为其他节点提供路由信息。
- Frontend:无状态接入层。接收客户端协议请求、执行鉴权、规划和分发查询,并根据 Metasrv 的元数据完成读写路由。
- Datanode:存储与执行层。负责存储表的 region,处理读写请求,持久化 WAL,并将数据文件刷入对象存储。
- Flownode(可选):流计算的流式/持续计算运行时。在分布式部署中,如果需要将 flow workload 独立为单独服务运行,就会使用 Flownode。
在 standalone 模式下,你运行的是一个 GreptimeDB 进程,而不是分别管理这些独立服务。
工作方式
写入路径
- 客户端通过支持的协议向 Frontend 发起写请求。
- Frontend 从 Metasrv 的元数据中解析表和 region 的路由信息,并在需要时刷新本地缓存。
- Frontend 将请求拆分并转发到目标 Datanode。
- Datanode 先将数据写入内存和 WAL,随后把不可变数据文件刷入对象存储。
查询路径
- 客户端通过 Frontend 发起 SQL、PromQL、日志或链路追踪查询。
- Frontend 生成分布式执行计划,并将子查询下发到相关的 Datanode。
- Datanode 在各自负责的 region 上执行子查询并返回部分结果。
- Frontend 汇总结果并返回给客户端。
Flow 路径(可选)
启用流计算后,Flownode 会持续读取源表的变化,并将计算结果写入目标表。 详细说明请参阅流计算。
如果你想了解实现层细节,请参阅 Contributor Guide。